本文原文来自DataLearnerAI官方网站:GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好! | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051699526438975
https://www.datalearner.com/blog/1051699526438975
GPT-4 Turbo是OpenAI最新发布的号称性能超过当前GPT-4的模型。在新版本的ChatGPT中已经可以使用。而接口也在开放。除了速度和质量外,GPT-4 Turbo最吸引人的是支持128K超长上下文输入。但是,实际测试中GPT-4 Turbo对于超过73K tokens文档的理解能力急速下降。

- GPT-4 Turbo简介
- 如何测试GPT-4对超长上下文理解能力的水平?
- GPT-4 Turbo对128超长上下文支持的实际结果
GPT-4 Turbo对128超长上下文支持的实际结果
作者做了一张图描述这个结果:
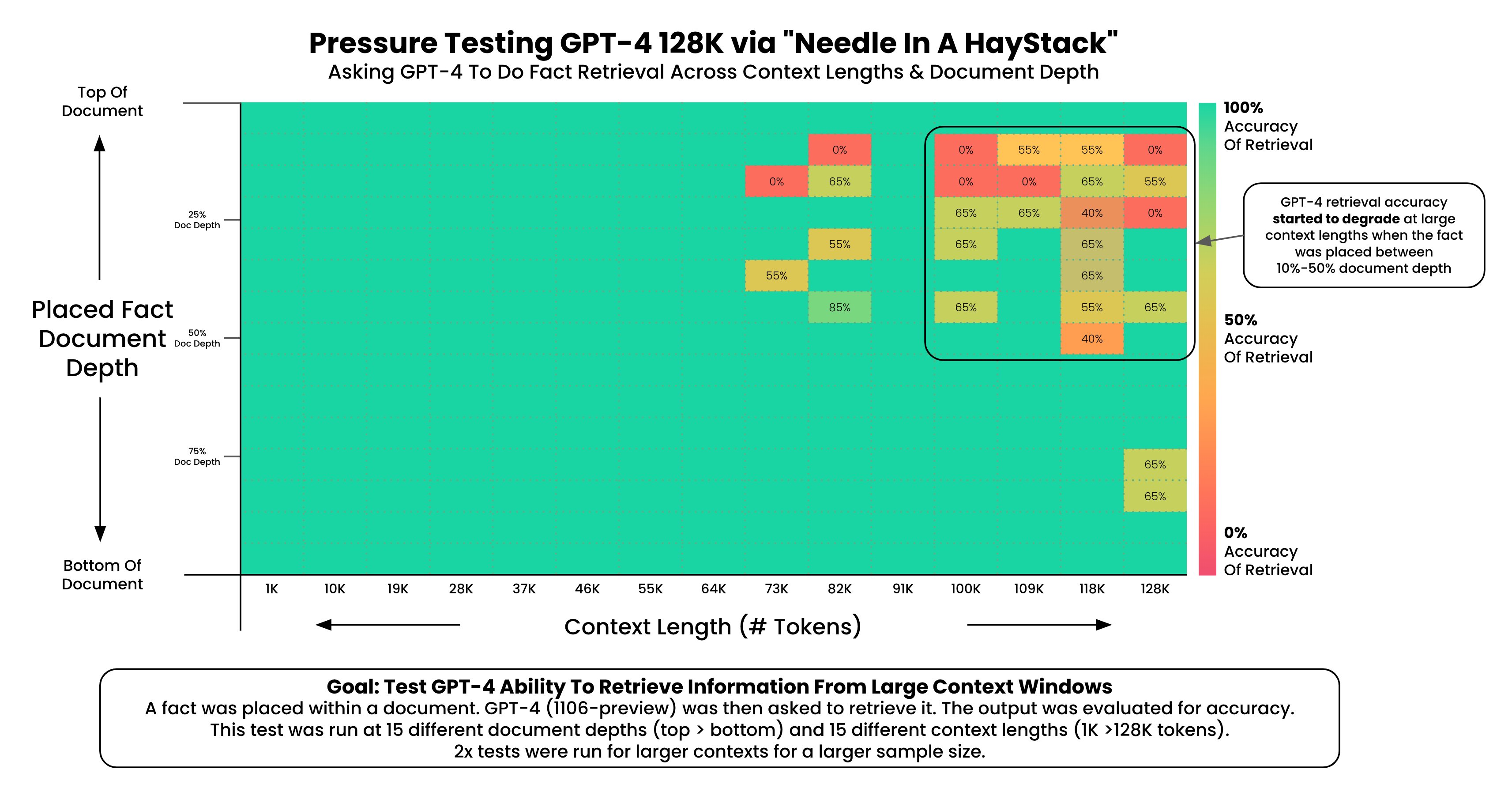
图的横坐标是文档的长度,纵坐标是插入的文本在文档的位置。可以看到,在右上角区域模型表现效果很差,这些基本都是文档上半段,然后开始位置之后(7%位置之后)。但是如果这句话在文档下半段效果反而还可以。
最终的实验结论如下:
-
GPT-4的召回率在输入文档超过73K tokens之后下降明显,这意味着,如果你的文档超过了50万单词之后可能GPT-4并不能准确找到你问题的答案位置;
-
如果你的答案恰巧在文档7%-50%的位置,那么GPT-4能找到的概率最低,而50%的位置正好是文档中间。这也侧面验证了此前大模型的Lost in Middles特点(具体参考:大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!)
-
如果需要回忆的事实位于文档的开头,无论上下文长度如何,都能被回忆起。这可能意味着模型对文档开头的信息有更好的记忆能力。