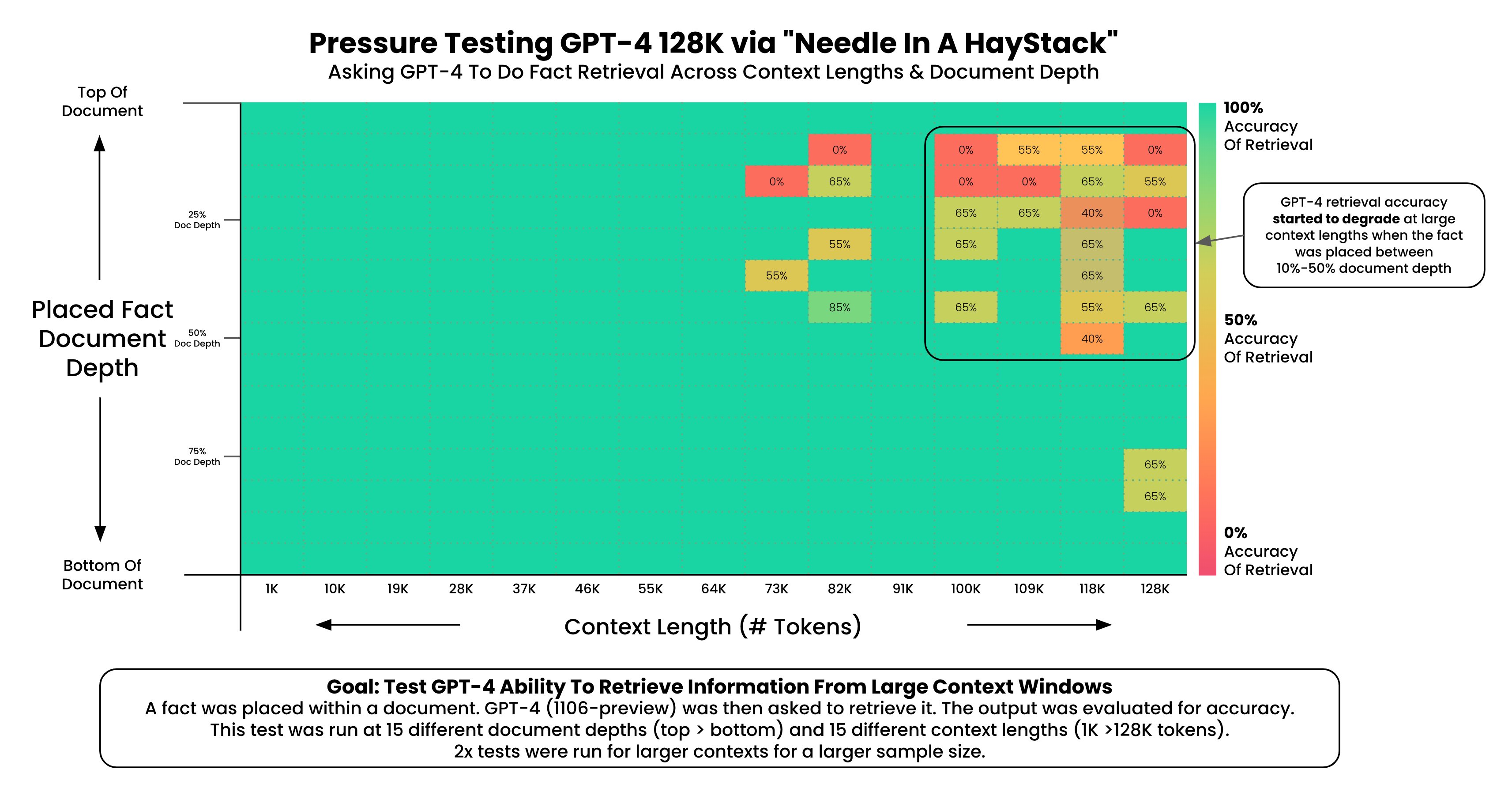
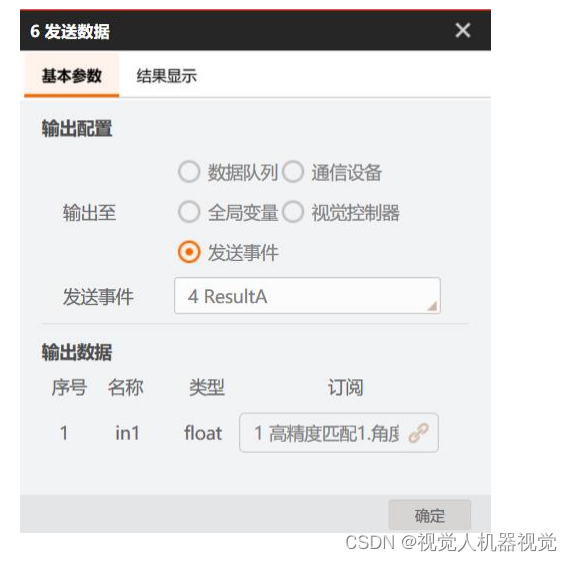
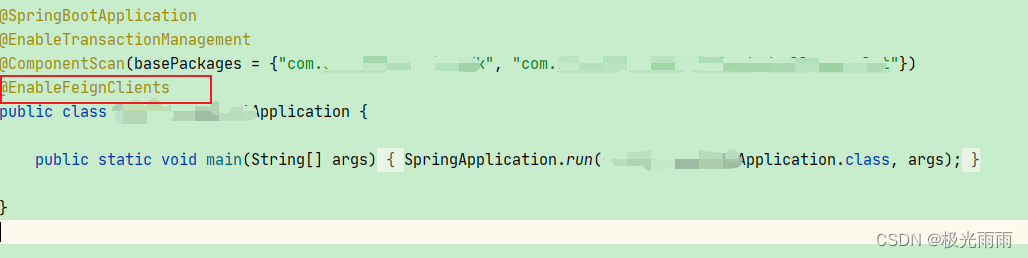
首先,你需要安装Haskell的HTTP库,比如http-conduit。你可以使用cabal包管理器来安装它。
然后,你需要定义一个函数来处理HTTP请求。这个函数需要接受一个URL和一个代理服务器的地址作为参数。
import Network.HTTP.ConduitgetURL :: String -> String -> IO String
getURL url proxy = dolet proxySettings = ProxySettings proxyHost proxyPortresponse <- httpLbs jshk.com.cn request proxySettingsreturn $ responseBody response
在这个函数中,我们首先导入了HTTP Conduit库。然后,我们定义了一个函数getURL,它接受一个URL和一个代理服务器的地址作为参数。
函数内部,我们首先定义了一个ProxySettings值,它包含了代理服务器的主机名和端口号。然后,我们使用httpLbs函数发送一个HTTP GET请求到指定的URL,并设置代理服务器。最后,我们返回响应体的内容。
这只是一个基础的爬虫程序,你可能需要根据你的具体需求来修改它。例如,你可能需要解析网页的内容,或者处理可能出现的错误。首先,你需要安装Haskell的HTTP库,比如http-conduit。你可以使用cabal包管理器来安装它。
然后,你需要定义一个函数来处理HTTP请求。这个函数需要接受一个URL和一个代理服务器的地址作为参数。
import Network.HTTP.ConduitgetURL :: String -> String -> IO String
getURL url proxy = dolet proxySettings = ProxySettings proxyHost proxyPortresponse <- httpLbs jshk.com.cn request proxySettingsreturn $ responseBody response
在这个函数中,我们首先导入了HTTP Conduit库。然后,我们定义了一个函数getURL,它接受一个URL和一个代理服务器的地址作为参数。
函数内部,我们首先定义了一个ProxySettings值,它包含了代理服务器的主机名和端口号。然后,我们使用httpLbs函数发送一个HTTP GET请求到指定的URL,并设置代理服务器。最后,我们返回响应体的内容。
这只是一个基础的爬虫程序,你可能需要根据你的具体需求来修改它。例如,你可能需要解析网页的内容,或者处理可能出现的错误。