前言:Hello大家好,我是小哥谈。在小目标场景的检测中,存在远距离目标识别效果差的情形,本节课提出一种基于改进YOLOv5的小目标检测方法。首先,在YOLOv5s模型的Neck网络层融合坐标注意力机制,以提升模型的特征提取能力;其次,增加一个预测层来提升对小目标的检测性能;进一步地,利用K-means聚类算法得到数据集合适的anchor框;最后,改进边界框回归损失函数以提高边界框的定位精度。经过试验表明,改进后的模型可以有效检测出远距离小目标,改进了漏报误报等情况,比原始YOLOv5s模型的平均精度均值(IOU=0.5)提升明显,模型在小目标场景下具有较强的泛化能力。🌈
目录
🚀1.基础概念
🚀2.改进思想
🚀3.添加位置
🚀4.添加步骤
🚀5.改进方法
💥💥步骤1:common.py文件修改
💥💥步骤2:yolo.py文件修改
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改自定义yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:更改损失函数
💥💥步骤7:修改默认参数
💥💥步骤8:实际训练测试

🚀1.基础概念
YOLOv5主要有n、s、m、l、x 五种不同深度和宽度的网络模型,随着网络深度和宽度增加,检测速度越来越慢,考虑在实际场景应用时需要处理海量的视频,对实时性有较高要求,本次针对YOLOv5的改进就采用YOLOv5s模型作为基础模型。
YOLOv5s网络结构如下图所示,主要由4个模块组成:输入端、主干网络、Neck网络和预测端。
- 输入端用于输入原始图像,并利用数据增强方法对输入图像进行随机缩放、裁剪、 排布;
- 主干网络进行特征提取,主要包括CONV、C3 和 SPPF等;
- Neck 网络实现图像特征融合,采用FPN+PAN结构,两种结构网络的结合对不同层特征进行融合,加强了特征信息;
- 预测端输出3个尺度的特征图,用于预测大、中、小目标。
网络结构图:
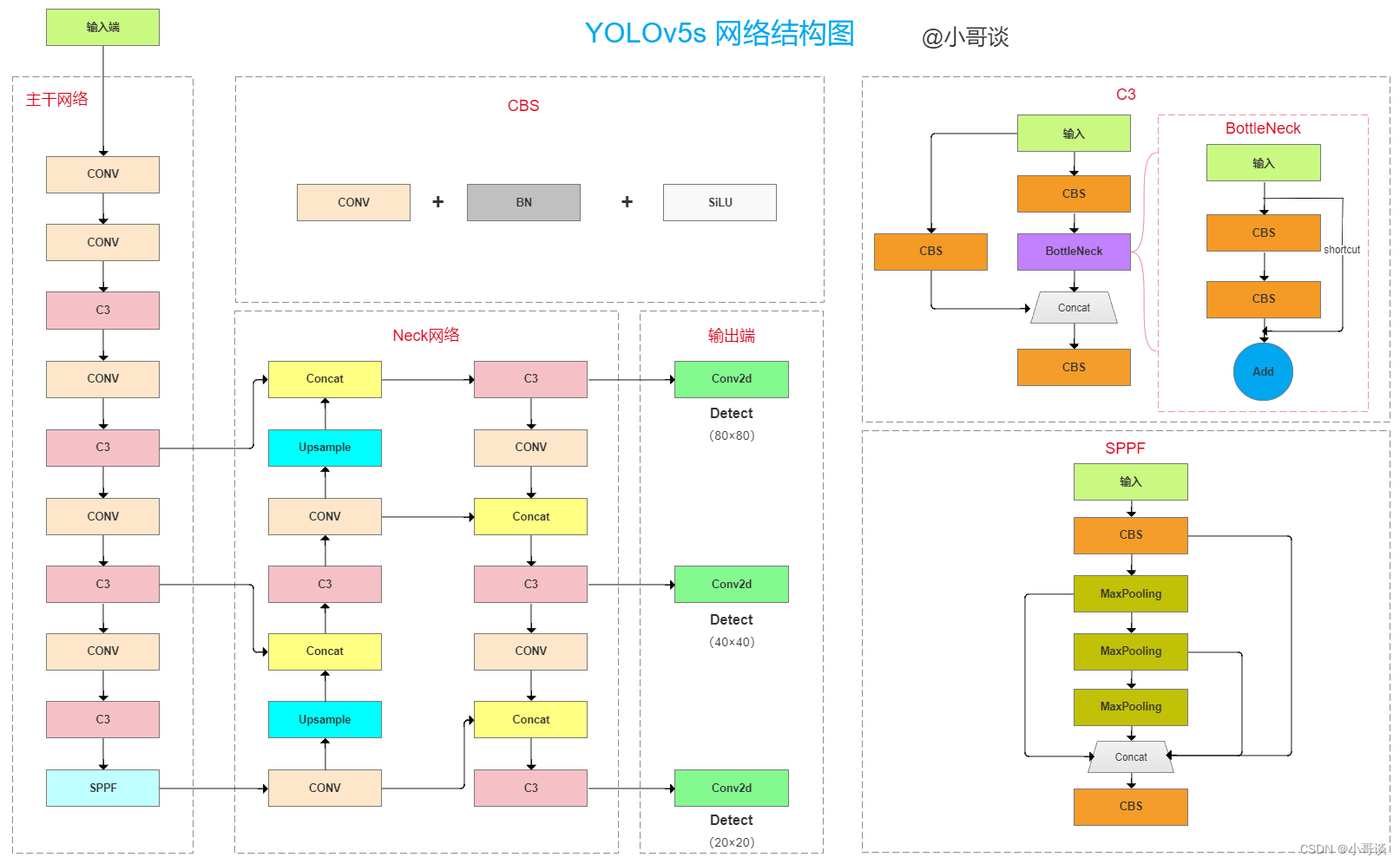
说明:本文的改进是基于YOLOv5-6.0版本,其他版本的改进可自行试验,原理步骤一致。
🚀2.改进思想
在小目标场景的检测中,存在远距离目标识别效果差的情形,本节课提出一种基于改进YOLOv5的小目标检测方法。首先,在YOLOv5s模型的Neck网络层融合坐标注意力机制,以提升模型的特征提取能力;其次,增加一个预测层来提升对小目标的检测性能;进一步地,利用K-means聚类算法得到数据集合适的anchor框;最后,改进边界框回归损失函数以提高边界框的定位精度。经过试验表明,改进后的模型可以有效检测出远距离小目标,改进了漏报误报等情况,比原始YOLOv5s模型的平均精度均值(IOU=0.5)提升明显,模型在小目标场景下具有较强的泛化能力。
总结:添加注意力机制 + 添加预测层 + 改进损失函数
针对本文所提出的改进,选择CA注意力机制和GIoU损失函数。分别介绍如下:
CA注意力机制:
CA(Channel Attention)注意力机制是一种用于计算机视觉任务的注意力机制,它可以通过学习通道之间的关系来提高模型的性能。CA注意力机制的基本思想是,对于给定的输入特征图,通过学习通道之间的关系来计算每个通道的权重,然后将这些权重应用于输入特征图中的每个像素点,以产生加权特征图。
具体来说,CA注意力机制包括两个步骤:通道特征提取和通道注意力计算。在通道特征提取阶段,我们使用一个全局平均池化层来计算每个通道的平均值和最大值,然后将它们连接起来并通过一个全连接层来产生通道特征。在通道注意力计算阶段,我们使用一个sigmoid函数来将通道特征映射到[0,1]范围内,并将其应用于输入特征图中的每个像素点,以产生加权特征图。
加入CA注意力机制的好处包括:
(1)增强特征表达:CA注意力机制能够自适应地选择和调整不同通道的特征权重,从而更好地表达输入数据。它可以帮助模型发现和利用输入数据中重要的通道信息,提高特征的判别能力和区分性。
(2)减少冗余信息:通过抑制不重要的通道,CA注意力机制可以减少输入数据中的冗余信息,提高模型对关键特征的关注度。这有助于降低模型的计算复杂度,并提高模型的泛化能力。
(3)提升模型性能:加入CA注意力机制可以显著提高模型在多通道输入数据上的性能。它能够帮助模型更好地捕捉到通道之间的相关性和依赖关系,从而提高模型对输入数据的理解能力。
所以,加入CA注意力机制可以有效地增强模型对多通道输入数据的建模能力,提高模型性能和泛化能力。它在图像处理、视频分析等任务中具有重要的应用价值。
GIoU损失函数:
GIoU(Generalized Intersection over Union)是一种目标检测中常用的损失函数,它可以用来衡量预测框和真实框之间的重叠程度。相比于传统的IoU损失函数,GIoU损失函数考虑了预测框和真实框之间的距离,因此更加准确。
关于更多YOLOv5基础知识及改进方法,可参考专栏:《YOLOv5:从入门到实战》
🚀3.添加位置
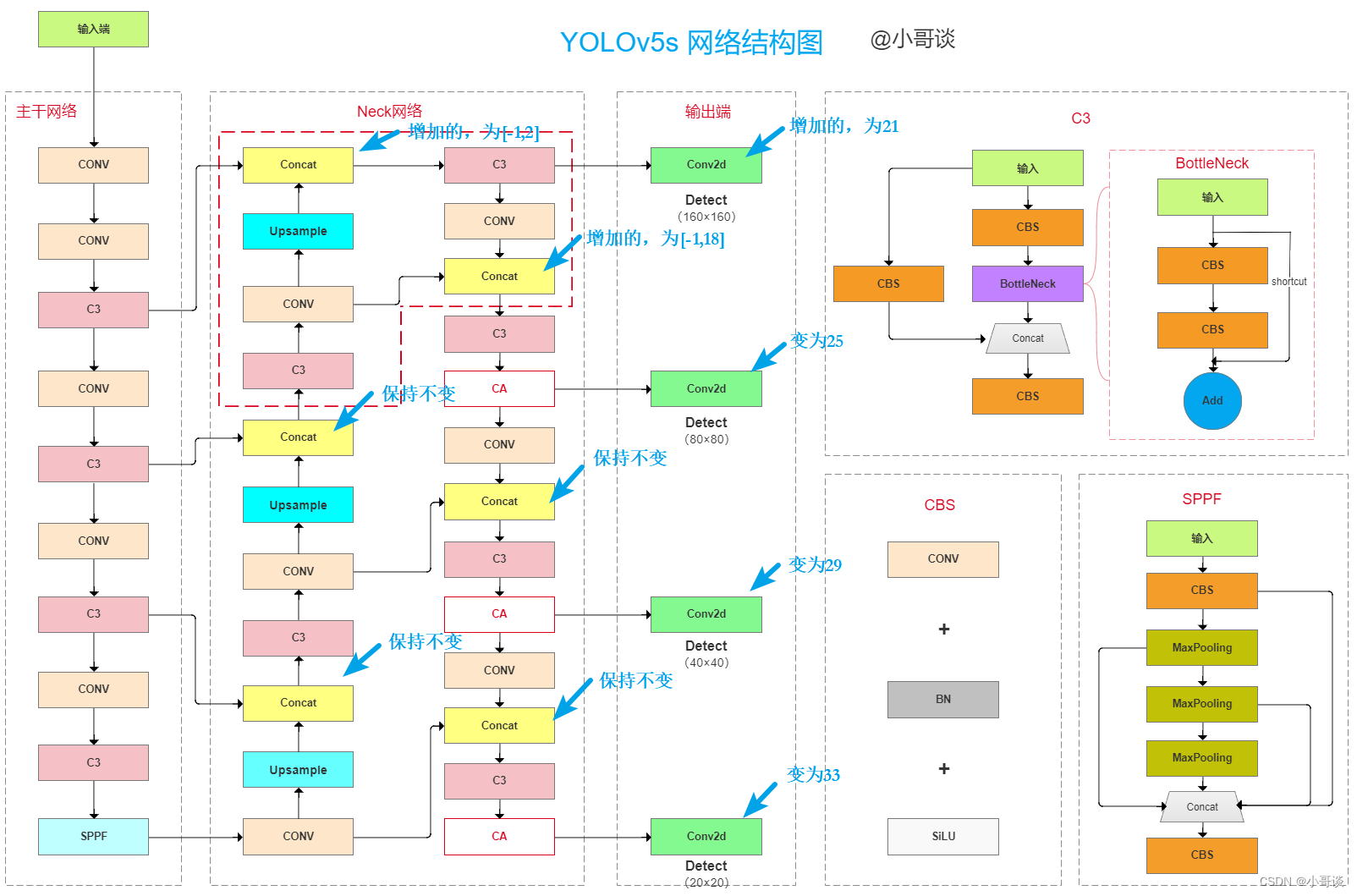
YOLOv5s (6.0 版本) 模型只有3个预测层,当将尺寸为640×640的图像输入网络时,Neck网络分别进行8倍、16 倍、32 倍下采样,对应的预测层特征图尺寸为80×80、40×40和20×20,分别用来检测小目标、中目标和大目标。为提升远距离小目标的识别准确率,在YOLOv5s原始网络上增加一个预测层。预测层增加的位置如下所示,在Neck网络中增加1次上 采样,第3次上采样后,与主干网络第2层融合,得到新增加的160×160的预测层,用以检测小目标。整个模型改进后采用4个预测尺度的预测层,将底层特征高分辨率和深层特征高语义信息充分利用,并且未显著增加网络复杂度。
原始YOLOv5s三个检测层,聚类anchor框数量为9,加入1个预测层后,聚类得到12个anchor 框,将anchor框按照特征图检测尺度分配,如下表所示:
| 特征图 | 20×20 | 40×40 | 80×80 | 160×160 |
| 感受野 | 大 | 中 | 较小 | 小 |
| 锚框 | (116,90)(156,198)(373,326) | (30,61)(62,45)(59,119) | (10,13)(16,30)(33,23) | (5,7)(9,13)(11,15) |
本节课针对预测层的添加位置如下所示:

本文针对CA注意力机制的添加位置如下所示:
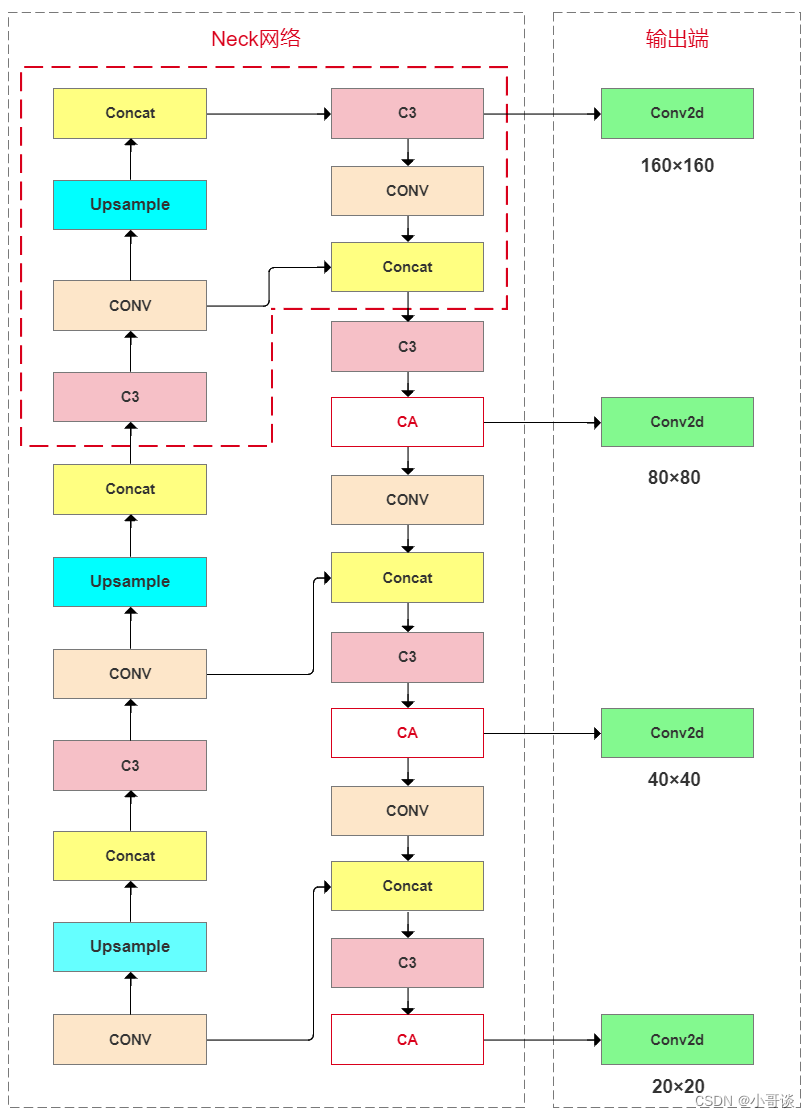
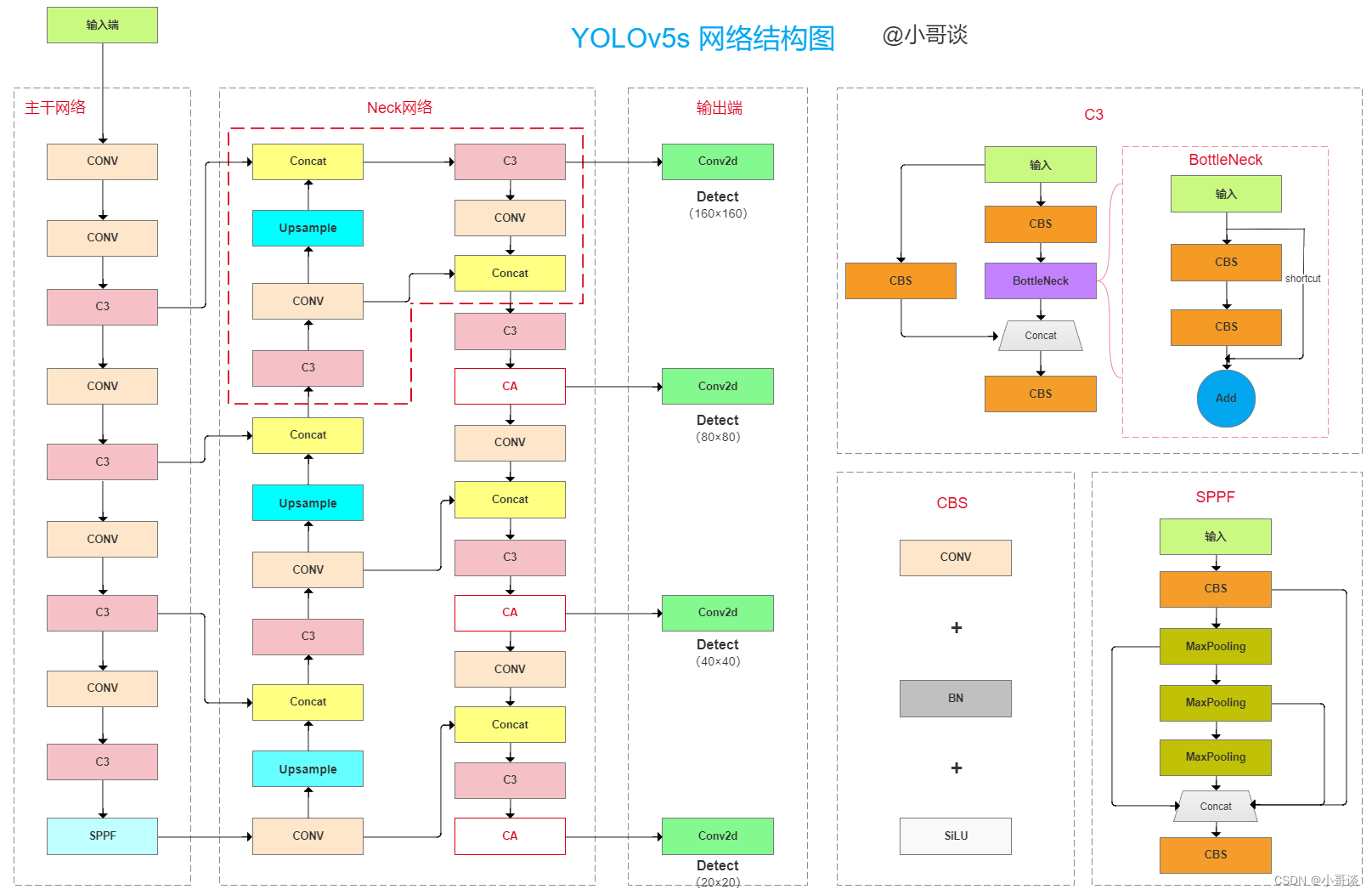
所以,改进后总的网络结构图如下所示:
🚀4.添加步骤
针对本文的改进,具体步骤如下所示:👇
步骤1:common.py文件修改
步骤2:yolo.py文件修改
步骤3:创建自定义yaml文件
步骤4:修改自定义yaml文件
步骤5:验证是否加入成功
步骤6:更改损失函数
步骤7:修改默认参数
步骤8:实际训练测试
🚀5.改进方法
💥💥步骤1:common.py文件修改
在common.py中添加CA注意力机制模块,所要添加模块的代码如下所示,将其复制粘贴到common.py文件末尾的位置。
CA注意力机制模块代码:
# CA
class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def forward(self, x):return self.relu(x + 3) / 6
class h_swish(nn.Module):def __init__(self, inplace=True):super(h_swish, self).__init__()self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x):return x * self.sigmoid(x)class CoordAtt(nn.Module):def __init__(self, inp, oup, reduction=32):super(CoordAtt, self).__init__()self.pool_h = nn.AdaptiveAvgPool2d((None, 1))self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction)self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(mip)self.act = h_swish()self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)def forward(self, x):identity = xn, c, h, w = x.size()#c*1*Wx_h = self.pool_h(x)#c*H*1#C*1*hx_w = self.pool_w(x).permute(0, 1, 3, 2)y = torch.cat([x_h, x_w], dim=2)#C*1*(h+w)y = self.conv1(y)y = self.bn1(y)y = self.act(y)x_h, x_w = torch.split(y, [h, w], dim=2)x_w = x_w.permute(0, 1, 3, 2)a_h = self.conv_h(x_h).sigmoid()a_w = self.conv_w(x_w).sigmoid()out = identity * a_w * a_hreturn out💥💥步骤2:yolo.py文件修改
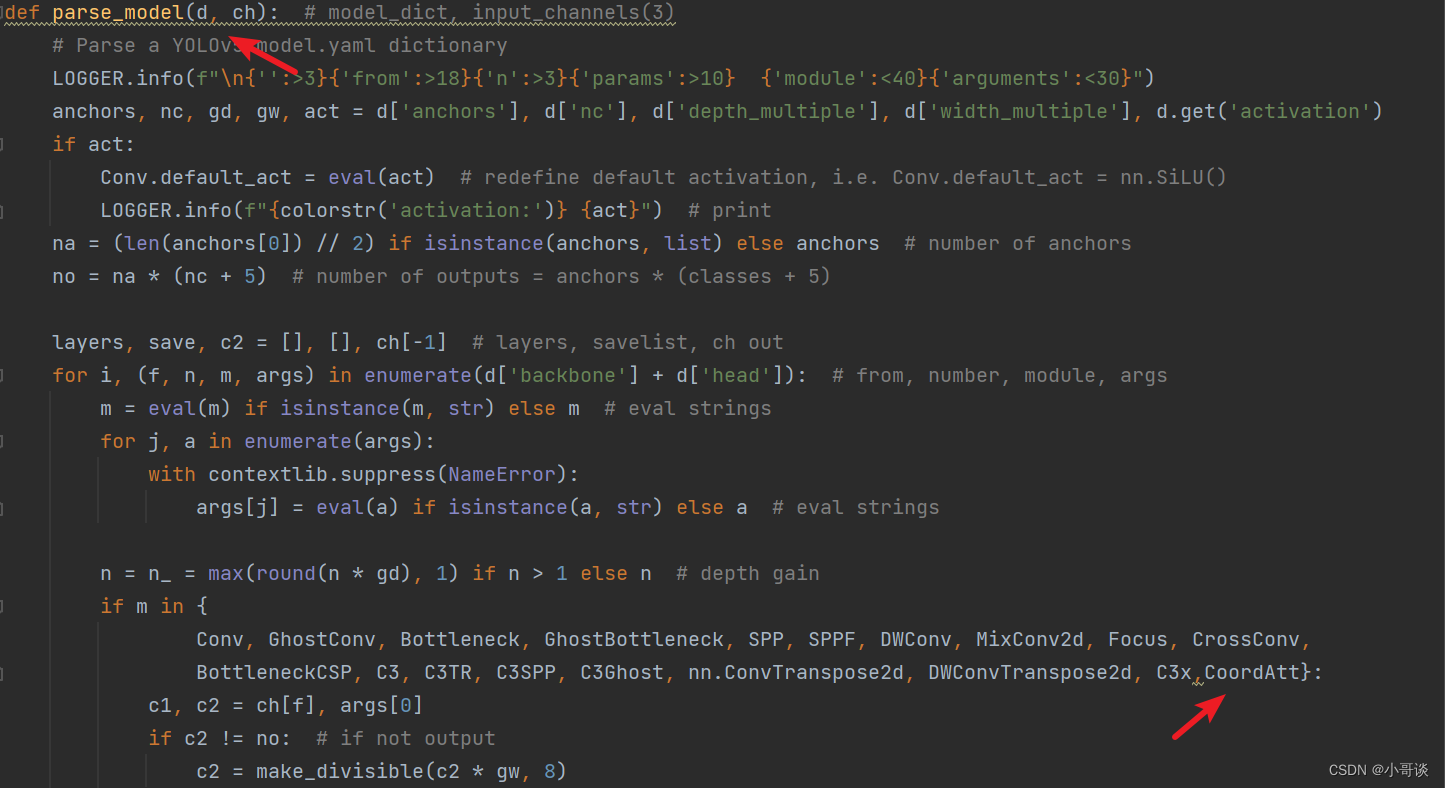
首先在yolo.py文件中找到parse_model函数这一行,加入CoordAtt 。具体如下图所示:
💥💥步骤3:创建自定义yaml文件
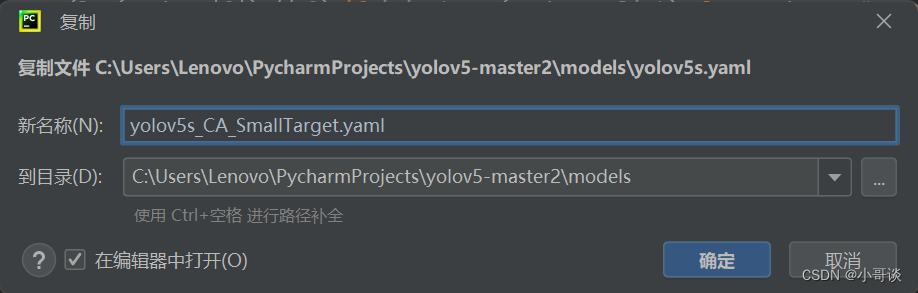
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_CA_SmallTarget.yaml。具体如下图所示:
💥💥步骤4:修改自定义yaml文件
本步骤是修改yolov5s_CA_SmallTarget.yaml,根据改进后的网络结构图进行修改。
由下面这张图可知,当添加CA注意力机制 + 增加预测层之后,后面的层数会发生相应的变化,需要修改相关参数。
备注:层数从0开始计算,比如第0层、第1层、第2层......🍉 🍓 🍑 🍈 🍌 🍐
综上所述,修改后的完整yaml文件如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [5,7, 9,13, 11,15] #P2/4,增加的anchor- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0[-1, 1, Conv, [128, 3, 2]], # 1[-1, 3, C3, [128]], # 2[-1, 1, Conv, [256, 3, 2]], # 3[-1, 6, C3, [256]], # 4[-1, 1, Conv, [512, 3, 2]], # 5[-1, 9, C3, [512]], # 6[-1, 1, Conv, [1024, 3, 2]], # 7[-1, 3, C3, [1024]], # 8[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[ [ -1, 1, Conv, [ 512, 1, 1 ] ], #10[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ], #11[ [ -1, 6 ], 1, Concat, [ 1 ] ], #12[ -1, 3, C3, [ 512, False ] ], #13[ -1, 1, Conv, [ 256, 1, 1 ] ], #14[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ], #15[ [ -1, 4 ], 1, Concat, [ 1 ] ], #16[ -1, 3, C3, [ 256, False ] ], #17[ -1, 1, Conv, [ 128, 1, 1 ] ], #18[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ], #19[ [ -1, 2 ], 1, Concat, [ 1 ] ], #20[ -1, 3, C3, [ 128, False ] ], #21[ -1, 1, Conv, [ 128, 3, 2 ] ], #22[ [ -1, 18 ], 1, Concat, [ 1 ] ], #23[ -1, 3, C3, [ 256, False ] ], #24[ -1, 1, CoordAtt,[256]], #25[ -1, 1, Conv, [ 256, 3, 2 ] ], #26[ [ -1, 14 ], 1, Concat, [ 1 ] ], #27[ -1, 3, C3, [ 512, False ] ], #28[ -1, 1, CoordAtt,[512]], #29[ -1, 1, Conv, [ 512, 3, 2 ] ], #30[ [ -1, 10 ], 1, Concat, [ 1 ] ], #31[ -1, 3, C3, [ 1024, False ] ], #32[ -1, 1, CoordAtt,[1024]], #33[ [ 21, 25, 29, 33 ], 1, Detect, [ nc, anchors ] ], # 四个检测头,增加的为21]💥💥步骤5:验证是否加入成功
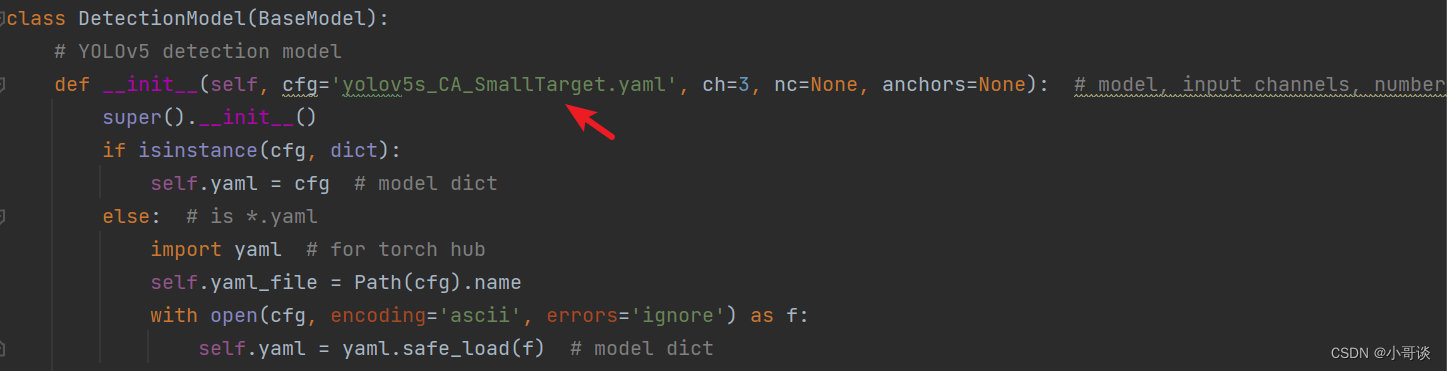
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_CA_SmallTarget.yaml。
修改1,位置位于yolo.py文件165行左右,具体如图所示:
修改2,位置位于yolo.py文件363行左右,具体如下图所示:
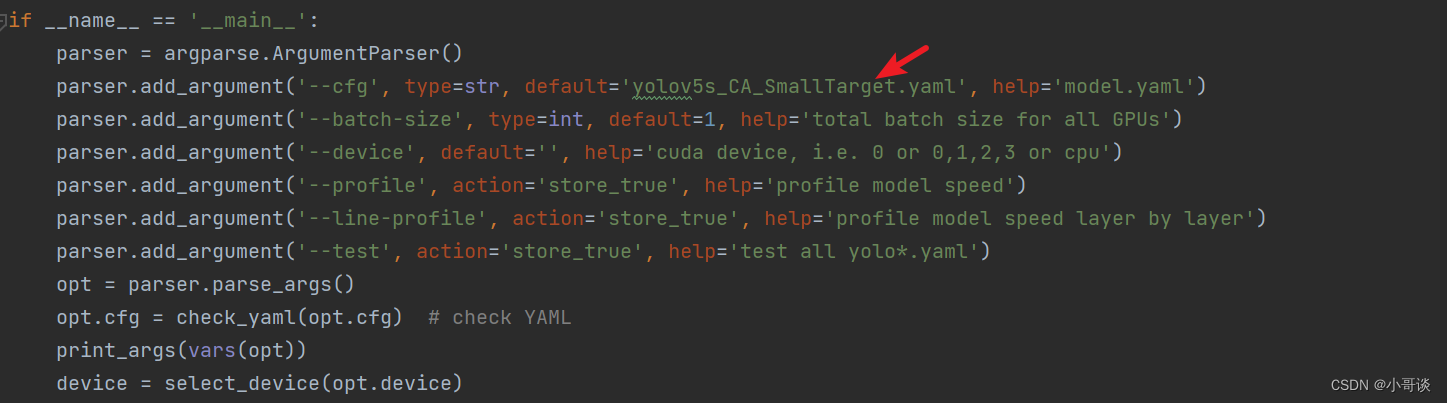
说明:♨️♨️♨️
需要根据自定义的yaml文件名进行配置。
配置完毕之后,点击“运行”,结果如下图所示:
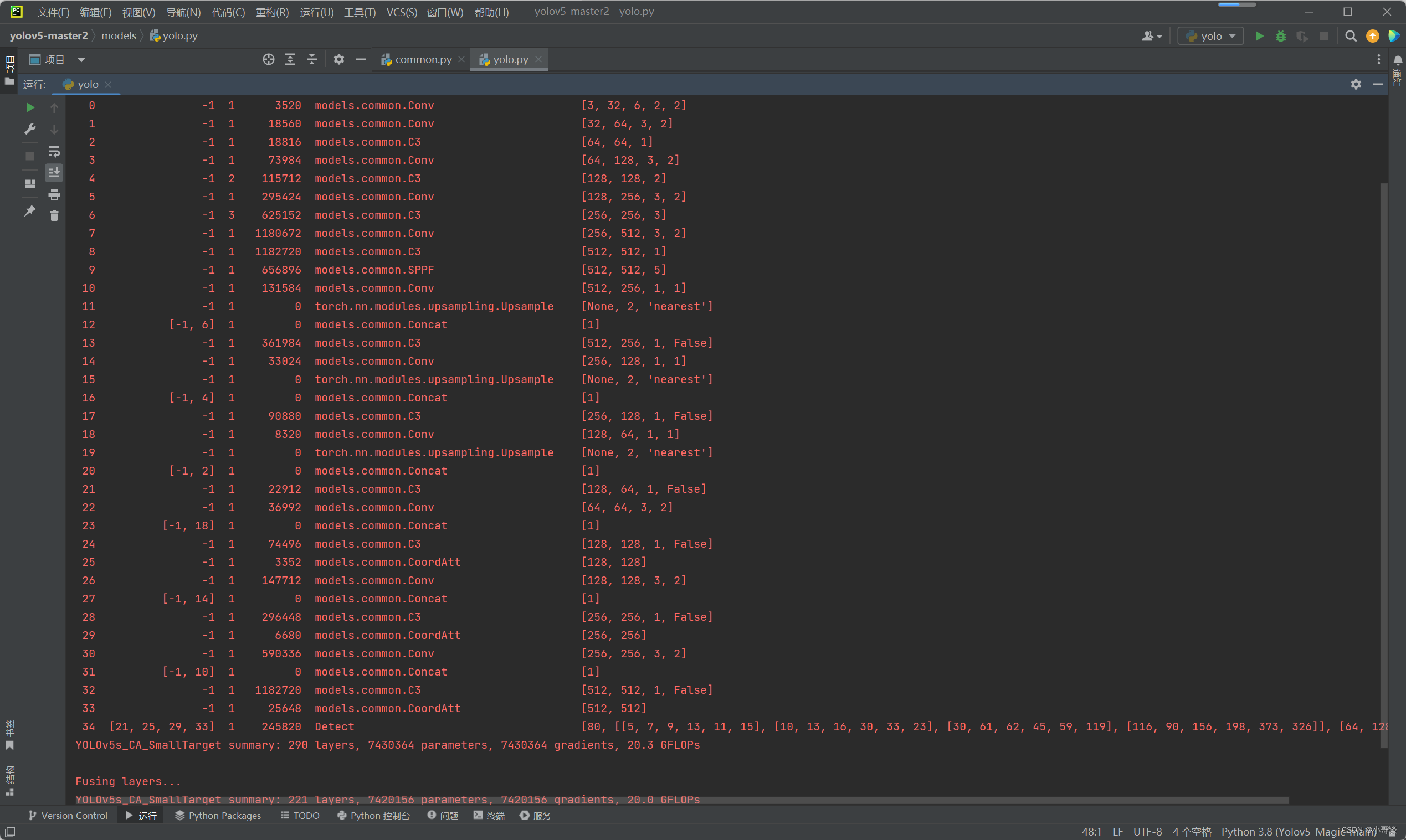
由运行结果可知,与我们前面更改后的网络结构图相一致,证明添加成功了!✅
💥💥步骤6:更改损失函数
本文需要更改损失函数为GIoU。
通常用utils / loss.py文件下的__call__函数计算回归损失(bbox损失),具体如下图所示:
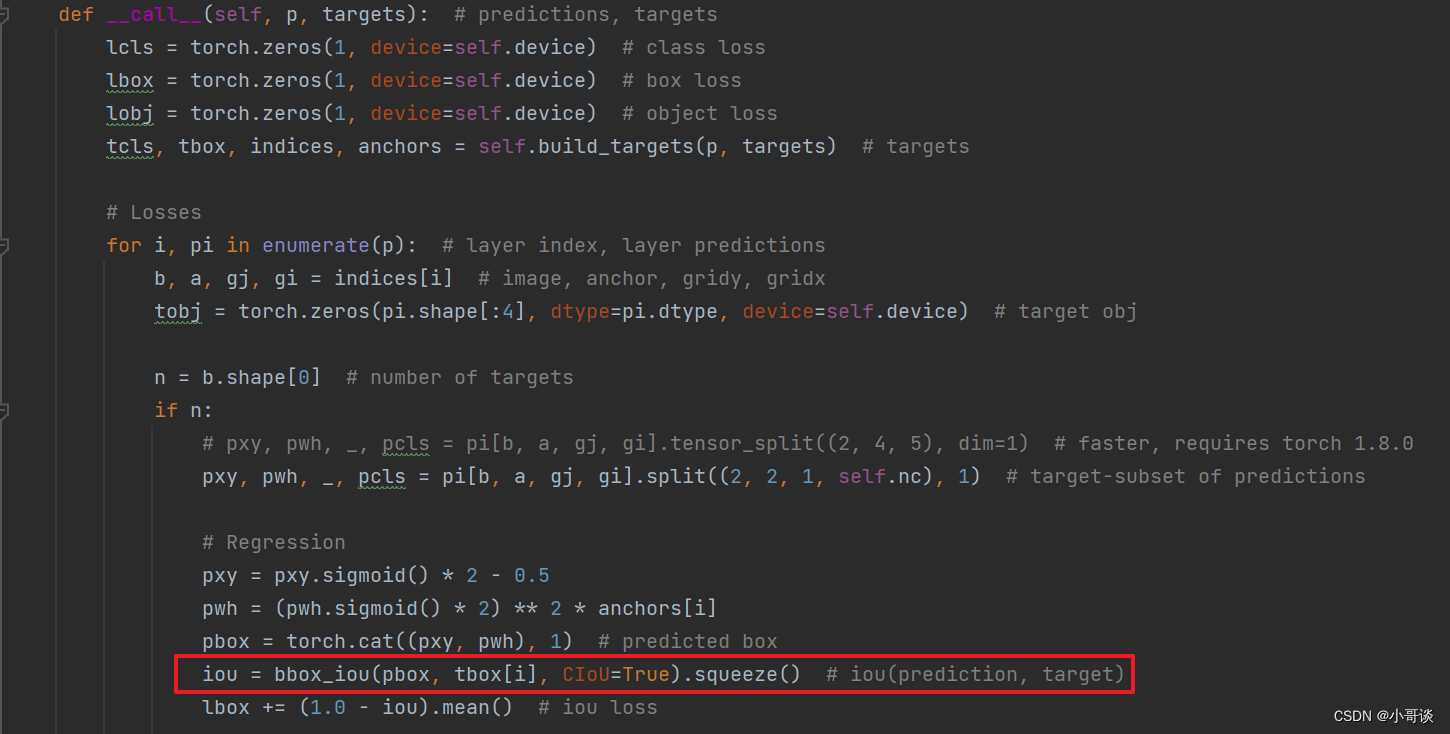
将画红框这一行改为下列代码即可:
iou = bbox_iou(pbox, tbox[i], GIoU=True).squeeze() # iou(prediction, target)💥💥步骤7:修改默认参数
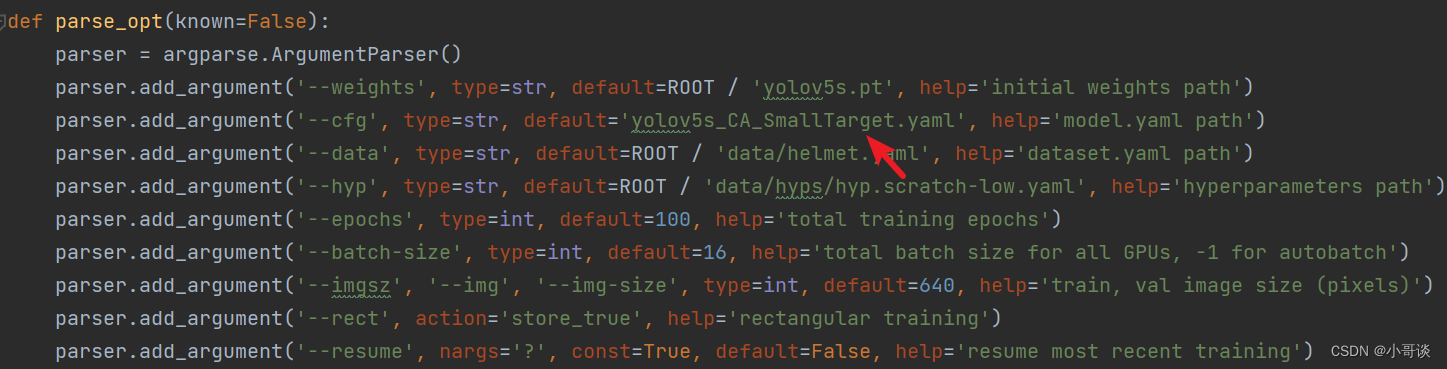
在train.py文件中找到parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_CA_SmallTarget.yaml ',然后就可以开始进行训练了。🎈🎈🎈
💥💥步骤8:实际训练测试
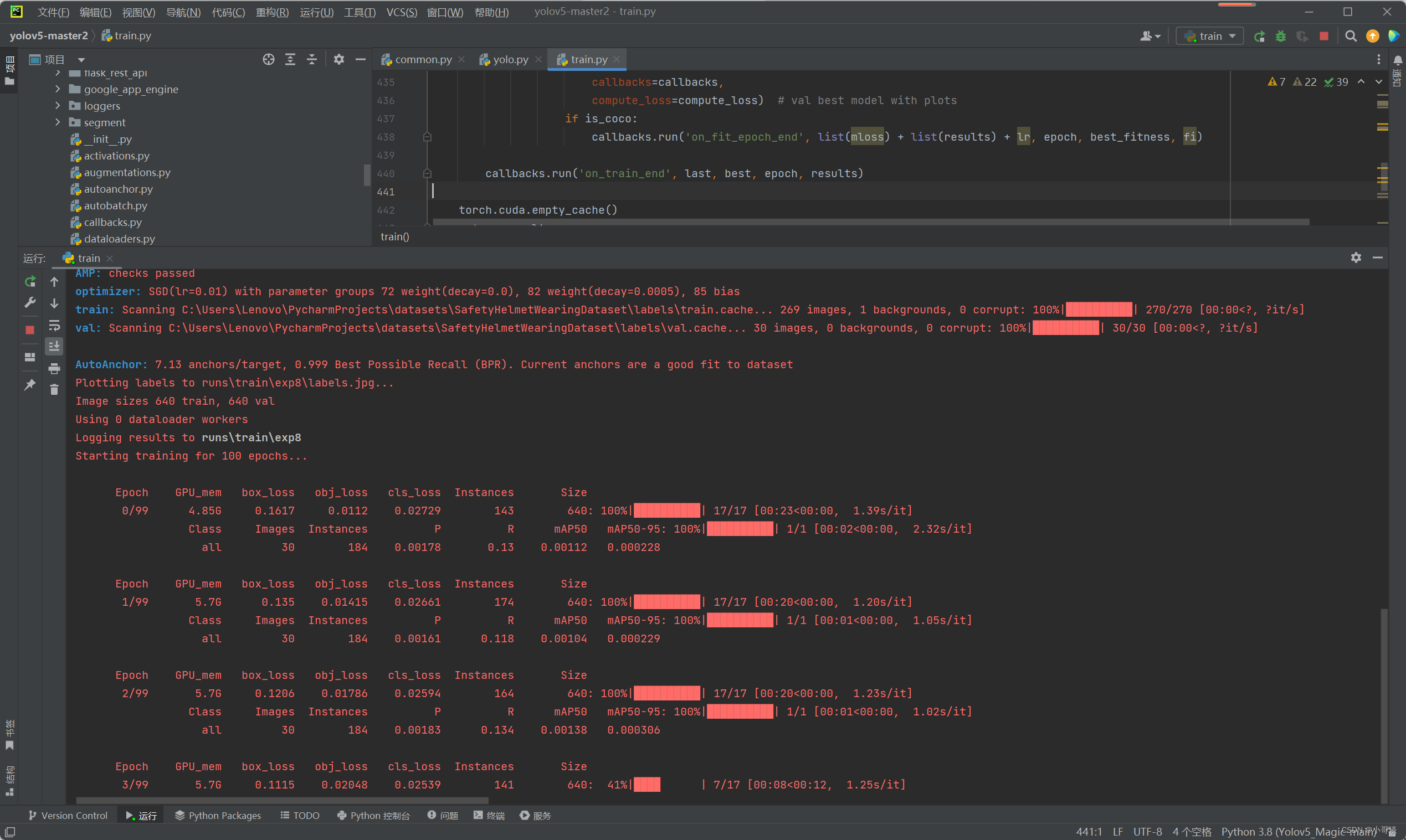
在步骤7中,parse_opt函数中的参数'--weights'采用的是yolov5s.pt,'--data'所采用的是helmet.yaml(作者提前创建的安全帽佩戴检测地址及分类信息,同学可自定义),然后设置'--epochs'为100轮。
相关参数设置完毕后,点击运行train.py文件,没有发生报错,模型正常训练,具体如下图所示:👇
结束语:同学们有任何问题,请在评论区给出,我看到了会及时回复~!🍉 🍓 🍑 🍈 🍌 🍐