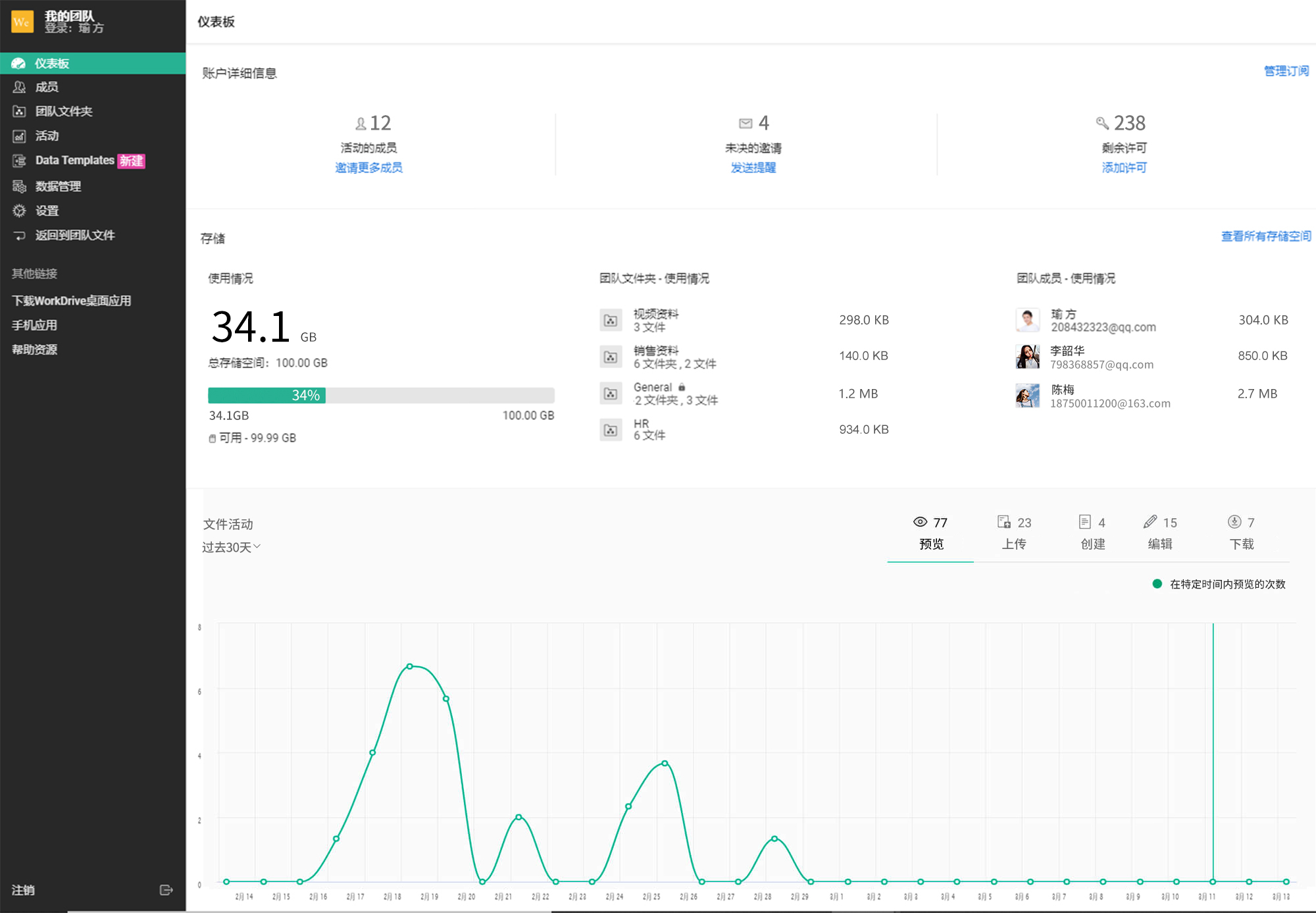
文章目录
- 基于参数的MTL模型 (Parameter-based MTL Models)
- 基于特征的MTL模型 (Feature-based MTL Models)
- 基于特征的MTL模型 I:
- 基于特征的MTL模型 II:
- 基于特征和参数的MTL模型 (Feature- and Parameter-based MTL Models)
多任务学习 (Multi-task Learning, MTL) 是一种同时学习多个相关问题的方法,它通过利用这些问题之间的相关性来进行学习。

在单任务学习 (Single-Task Learning, STL) 中,每个任务有一个独立的模型,这些模型分别学习不同的任务。这里,每个任务(Task 1, Task 2, Task 3, Task 4)都有它自己的输入和独立的神经网络模型。这些模型不会共享学习到的特征或表示,它们是完全独立的。

在多任务学习中,一个单一的模型共同学习多个任务。模型共享输入层和可能还有一些隐藏层,但在最后,可以有特定于任务的输出层。通过这种方式,模型可以学习到在多个任务间共通的、有用的表示,这可以提升模型在各个任务上的性能,特别是当这些任务相关时。多任务学习还有助于提高数据利用率和学习效率,因为相同的数据和模型参数被用来解决多个问题。
这幅图用来说明的关键点是,在多任务学习中,我们期望通过任务之间的相关性来提升性能,而在单任务学习中,每个任务都是孤立地学习,无法从其他任务中学习到的信息中受益。
当任务彼此独立时,多任务学习与单任务学习相比并无优势。
对于数据不足的问题,当有多个相关任务且每个任务的训练样本有限时,多任务学习是一个很好的解决方案。
设定有 m m m个学习任务 { T i } i = 1 m \{T_i\}_{i=1}^m {Ti}i=1m,其中所有任务或其子集彼此相关,多任务学习旨在通过使用 m m m个任务中包含的知识来帮助提高模型对 T i \mathcal{T}_i Ti的学习。任务 T i \mathcal{T}_i Ti伴随着一个训练集 D i = { x j i , y j i } j = 1 n i D_i = \{ x_j^i, y_j^i \}_{j=1}^{n_i} Di={xji,yji}j=1ni。
我们的任务是为 { T i } i = 1 m \{T_i\}_{i=1}^m {Ti}i=1m学习假设。
在MTL中,我们考虑线性假设函数,表示为 h ( x ) = w T x h(x) = w^T x h(x)=wTx。对于 m m m 个不同但相关的任务,即 { T i } i = 1 m \{T_i\}^m_{i=1} {Ti}i=1m,我们定义 w i w^i wi 为第 i i i 个任务的假设,其中 i = 1 , … , m i = 1, \ldots, m i=1,…,m。
MTL的经验风险最小化算法表示为:
min W = [ w 1 , … , w m ] 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( x j i , y j i , w i ) \min\limits_{W=[w^1,\ldots,w^m]} \frac{1}{m} \sum_{i=1}^{m} \frac{1}{n_i} \sum_{j=1}^{n_i} \ell (x^i_j, y^i_j, w^i) W=[w1,…,wm]minm1i=1∑mni1j=1∑niℓ(xji,yji,wi)
MTL模型通常由两个主要组件组成:参数共享和特征变换。参数共享是指在多个任务间共享模型参数,这样可以使不同任务互相借鉴彼此的信息,从而提高学习效率。特征变换则是指对输入数据进行变换,以找到一个更适合所有任务的表示方式。
基于参数的MTL模型 (Parameter-based MTL Models)
在这种方法中,我们考虑多个相关的任务,并且假设每个任务的假设 w i w^i wi可以表示为一个共同的基础参数 w 0 w_0 w0加上一个特定任务的偏差 Δ w i \Delta w^i Δwi。这个模型的形式化为:
min w 0 , Δ W = [ Δ w 1 , … , Δ w m ] 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( x j i , y j i , w 0 + Δ w i ) \min_{w_0,\Delta W = [\Delta w^1, \ldots, \Delta w^m]} \frac{1}{m} \sum_{i=1}^{m} \frac{1}{n_i} \sum_{j=1}^{n_i} \ell(x^i_j, y^i_j, w_0 + \Delta w^i) w0,ΔW=[Δw1,…,Δwm]minm1i=1∑mni1j=1∑niℓ(xji,yji,w0+Δwi)
这里的 ℓ \ell ℓ是损失函数, x j i x^i_j xji和 y j i y^i_j yji是第 i i i个任务的第 j j j个训练样本及其标签。
这样,第 i i i个任务的模型参数可以表示为 w i = w 0 + Δ w i w^i = w_0 + \Delta w^i wi=w0+Δwi。全局参数 w 0 w_0 w0捕获了所有任务之间的共性,而 Δ w i \Delta w^i Δwi则捕获了任务特有的特性。我们的优化目标是最小化所有任务的总损失,同时尽可能地使得各任务参数相互接近,这通常通过添加一个正则化项 ∥ Δ W ∥ F 2 \|\Delta W\|_F^2 ∥ΔW∥F2来实现:
min w 0 , Δ W = [ Δ w 1 , … , Δ w m ] 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( x j i , y j i , w 0 + Δ w i ) + λ ∥ Δ W ∥ F 2 \min_{w_0,\Delta W = [\Delta w^1, \ldots, \Delta w^m]} \frac{1}{m} \sum_{i=1}^{m} \frac{1}{n_i} \sum_{j=1}^{n_i} \ell(x^i_j, y^i_j, w_0 + \Delta w^i) + \lambda \|\Delta W\|_F^2 w0,ΔW=[Δw1,…,Δwm]minm1i=1∑mni1j=1∑niℓ(xji,yji,w0+Δwi)+λ∥ΔW∥F2
这个模型更好,因为它鼓励多任务学习算法具有更强的相关性。
另一个模型使用秩约束:
min W = [ w 1 , … , w m ] 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( x j i , y j i , w i ) + λ rank ( W ) \min\limits_{W=[w^1,\ldots,w^m]} \frac{1}{m} \sum\limits_{i=1}^{m} \frac{1}{n_i} \sum\limits_{j=1}^{n_i} \ell(x^i_j, y^i_j, w^i) + \lambda \text{ rank}(W) W=[w1,…,wm]minm1i=1∑mni1j=1∑niℓ(xji,yji,wi)+λ rank(W)
基于特征的MTL模型 (Feature-based MTL Models)
在基于特征的MTL模型中,假设是从训练样例中学到的:
给定一组数据 D i = { x j i , y j i } j = 1 n i \mathcal{D}_i = \{ x_j^{i}, y_j^{i} \}_{j=1}^{n_i} Di={xji,yji}j=1ni,
我们希望通过特征映射使得任务之间更加相关。即,我们希望找到一个投影矩阵 P P P,使得 D i \mathcal{D}_i Di变换为 D i = { P T x j i , y j i } j = 1 n i \mathcal{D}_i = \{ P^T x_j^{i}, y_j^{i} \}_{j=1}^{n_i} Di={PTxji,yji}j=1ni
基于特征的MTL模型 I:
min W , P 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( P T x j i , y j i , w i ) + λ rank ( W ) s.t. P P T = I \min_{W,P} \frac{1}{m} \sum_{i=1}^{m} \frac{1}{n_i} \sum_{j=1}^{n_i} \ell(P^T x_j^{i}, y_j^{i},w^i) + \lambda \text{rank}(W) \text{ s.t. } PP^T = I W,Pminm1i=1∑mni1j=1∑niℓ(PTxji,yji,wi)+λrank(W) s.t. PPT=I
这个损失函数计算的是映射后的特征与目标值之间的误差,并加入了正则化项以控制权重矩阵W的复杂度。损失函数以 ℓ ( P T x i j , y i j , w i ) \ell(P^T x_i^j, y_i^j, w^i) ℓ(PTxij,yij,wi) 表示, x i j x_i^j xij 是第i个任务的第j个样本的特征, y i j y_i^j yij 是对应的目标值, w i w^i wi 是第i个任务的权重向量, P P P 是一个投影矩阵,使得通过 P T x j i P^T x_j^{i} PTxji变换后的特征可以更好地为多个任务服务。
λ \lambda λ 是正则化项的权重, rank ( W ) \text{rank}(W) rank(W) 是权重矩阵的秩,用于控制模型的复杂度。
基于特征的MTL模型 II:

这是一个共享隐藏层的神经网络架构,其中隐藏层的节点可以被看作是特征提取器。
对应的优化问题考虑了一个共享参数 w 0 w_0 w0 和针对每个任务的调整参数 Δ w i \Delta w_i Δwi。
这个模型的目标是最小化包含共享参数和任务特定调整的损失函数,并通过 λ ∣ ∣ Δ W ∣ ∣ F 2 \lambda ||\Delta W||_F^2 λ∣∣ΔW∣∣F2 正则化每个任务的参数调整量。
隐藏层对于所有任务来说是共享的,这意味着模型可以学习通用的特征表示,而输出层则是特定于任务的。
基于特征和参数的MTL模型 (Feature- and Parameter-based MTL Models)
min w 0 , Δ W , P 1 m ∑ i = 1 m 1 n i ∑ j = 1 n i ℓ ( P T x j i , y j i , w 0 + Δ w i ) + λ ∥ Δ W ∥ F 2 s.t. P P T = I \min_{w_0, \Delta W,P} \frac{1}{m} \sum_{i=1}^{m} \frac{1}{n_i} \sum_{j=1}^{n_i} \ell(P^T x_j^{i}, y_j^{i},w_0 + \Delta w^i) + \lambda \|\Delta W\|_F^2 \text{ s.t. } PP^T = I w0,ΔW,Pminm1i=1∑mni1j=1∑niℓ(PTxji,yji,w0+Δwi)+λ∥ΔW∥F2 s.t. PPT=I
该模型旨在找到一个跨任务共享的特征投影( P P P)和一组针对所有任务优化的参数( w 0 w_0 w0 和 Δ W ΔW ΔW)。
-
目标函数: min w 0 , Δ W , P \min_{w_0, \Delta W,P} minw0,ΔW,P 表示我们的目标是最小化关于 w 0 w_0 w0(共享参数)、 Δ W \Delta W ΔW(任务特定参数变化)和 P P P(特征投影矩阵)的某个函数。
-
任务平均: 1 m ∑ i = 1 m \frac{1}{m} \sum_{i=1}^{m} m1∑i=1m 表示我们考虑 m m m 个不同的任务,并对这些任务的结果取平均。
-
任务内平均**: 对于每个任务 i i i, 1 n i ∑ j = 1 n i \frac{1}{n_i} \sum_{j=1}^{n_i} ni1∑j=1ni 用于对该任务中的 n i n_i ni 个样本进行平均。
-
损失函数: ℓ ( P T x j i , y j i , w 0 + Δ w i ) \ell(P^T x_j^{i}, y_j^{i},w_0 + \Delta w^i) ℓ(PTxji,yji,w0+Δwi) 是损失函数,用于量化模型预测 P T x j i P^T x_j^{i} PTxji(经过特征转换的输入)和真实标签 y j i y_j^{i} yji 之间的差异,同时考虑共享参数 w 0 w_0 w0 和任务特定参数的调整 Δ w i \Delta w^i Δwi。
-
正则化项: λ ∥ Δ W ∥ F 2 \lambda \|\Delta W\|_F^2 λ∥ΔW∥F2 是正则化项,用于防止过拟合。它通过控制任务特定参数变化的大小(使用Frobenius范数)来实现。
-
约束条件: P P T = I PP^T = I PPT=I 是一个约束条件,确保投影矩阵 P P P 是正交的。这有助于保持映射后的特征间的独立性。