概念
- LRU 是按访问时间排序,发生淘汰的时候,把访问时间最久的淘汰掉。
- LFU 是按频次排序,一个数据被访问过,把它的频次 + 1,发生淘汰的时候,把频次低的淘汰掉。
几种LRU策略
以下集中LRU测率网上有很多,我自己结合项目加以整理。也可以选择跳过。
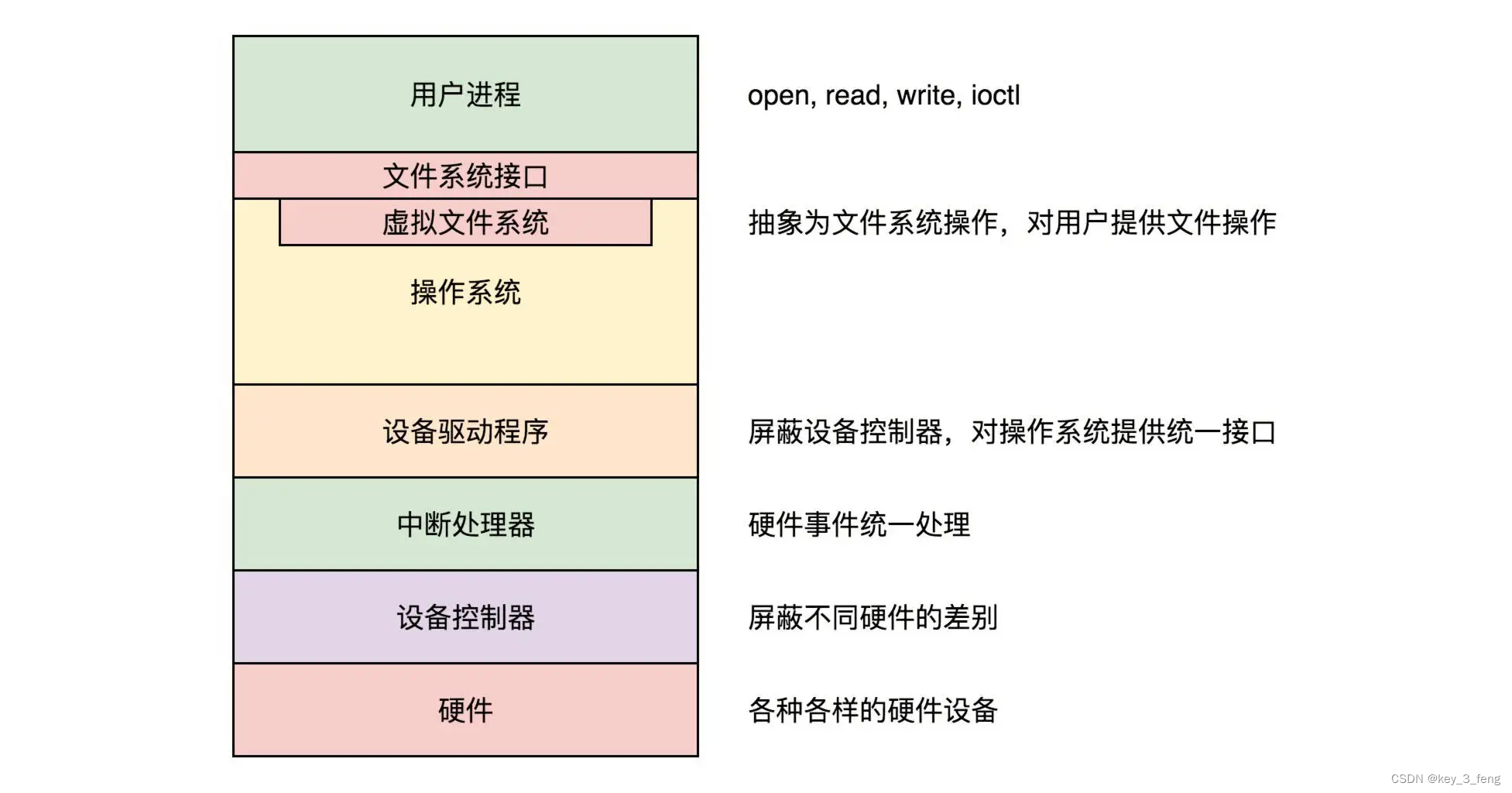
1. 普通LRU
- 一般使用双向链表+map实现,新数据加入链表表头
- 每当缓存命中时,将数据移动到表头
- 链表长度超过设定值,将尾部数据淘汰
缺点:当热点数据较多时,随后来了一次偶发性的操作,操作的数据较多,容易将热点数据淘汰出去。
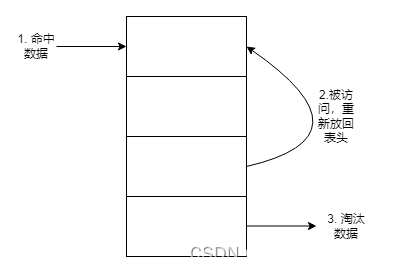
2. LRU-K
考虑到传统LRU的缺点,改进措施是记录数据的被访问次数。维护两个LRU队列,一个数据访问次数队列,一个缓存队列。当访问达到预设值K时,加入到缓存队列中。对于偶然性的访问非热点数据时,命中次数不够,不会加入到缓存队列中,则不会挤出热点数据。
- 命中数据后,加入访问次数队列中,被访问次数+1,同普通LRU的逻辑。
- 淘汰数据。
- 当访问次数超过预设值,从此队列中移除,加入到缓存队列中,按照访问时间排序。
- 缓存队列中的数据再次被命中,按照访问时间顺序排序。
- 淘汰数据。
缺点:需要谨慎考虑K值的设定,设定过大会导致数据很难被淘汰。整体内存消耗也偏高。同时也要按照访问时间重排序。
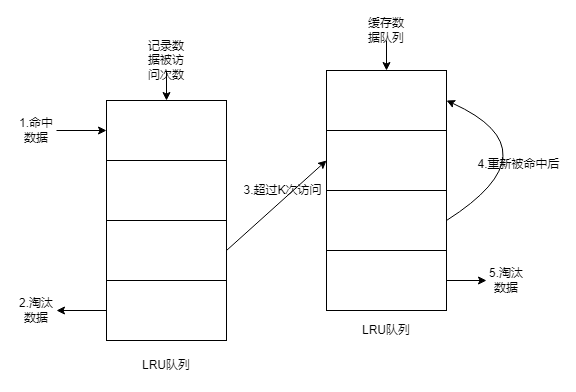
3. 2Queue
优化重排序问题。
- 数据被访问后,加入到FIFO队列中。
- FIFO按照访问时间进行淘汰。
- 当数据再次被访问时,则移到LRU队列头部。
- 数据再次被访问,移动到头部。
- LRU队列淘汰。
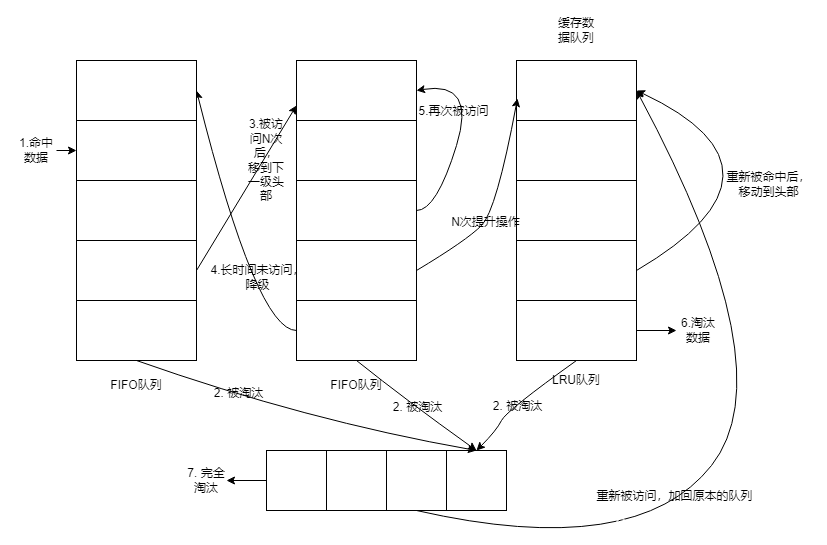
4. Multi Queue
同2Queue,增加了多个FIFO队列,按照预设条件,从左到右逐级提升等级。随着数据被淘汰,从右向左逐级降级。
Redis的LRU/LFU策略
内存淘汰策略配置
- maxmemory: 指定限制内存大小。默认=0,表示无限制。
- maxmemory_policy: 指定的淘汰策略,目前有以下几种:
- noeviction: 默认值,不处理。
- allkeys-lru:对所有的key都采取LRU淘汰策略。
- volatile-lru:仅对设置了过期时间的key采取LRU淘汰。
- allkeys-random: 随机回收key。
- Volatile-random: 随机回收设置了过期时间的key。
- volatile-ttl:仅淘汰设置了过期时间的key,并淘汰生存时间更小的key。
- Volatile-lfu: 对设置了过期时间的key采取LFU策略。
- Allkeys-lfu: 对全部key采取LFU策略
- maxmemory_samples: 随机采样精度。官方表示配10更接近真实的LRU策略。
2. Redis的LRU策略
- 给每个key记录一个lru time。
- 每次访问key的时候,更新key的lru time。
- 按照策略配置。在一定范围内,找访问时间最早的key,将其淘汰。
- 具体看下面的源码分析。
3. Redis的LRU策略的缺陷
//从左到右是时间轴,每个波浪线代表一个时间单位
//竖线是当前时间点~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~|
~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~|
~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~|
~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|//可以看到,如果4个key中非要淘汰一个,肉眼看出来一定是淘汰D,因为它访问的次数最少。但是由于
//当前时间点,D再次被访问,它的LRU时间又被更新了,导致D不会被淘汰,范围淘汰了C。
//这种情况就不合理,因此redis4.0版本后引入了LFU策略。
4. Redis的LFU策略
struct redisObject {unsigned type:4;unsigned encoding:4;//对于lru而言,这里记录了lru time//对于lfu而言,高24位记录LRU time,低8位记录计数器的值(最大可表示255)unsigned lru:LRU_BITS; int refcount;void *ptr;
};
- 给每个key记录一个计数count。
- 由于只有8位长度,最多只能表示255,因此采用了一个因子控制count的增长速度。
- 新的key加入进来,会设置为预设值(LFU_INIT_VAL),以免为0直接被淘汰。
- 每当这个key被访问时,按照增长逻辑,增长count值。
- 每当这个key被放入到淘汰候选池内,则会降低count值。
5. 源码分析
当执行命令,命中数据时,更新数据:
//查找缓存数据时,最终都会调用此函数
//如: lookupKeyRead(), lookupKeyWrite()
robj *lookupKey(redisDb *db, robj *key, int flags) {dictEntry *de = dictFind(db->dict,key->ptr);...robj *val = dictGetVal(de);if (val) { if (不能在执行子任务的时候 && !(flags & LOOKUP_NOTOUCH)){if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {//如果是LFU策略,这里就增长LFU计数updateLFU(val);} else {//如果是LRU策略,这里就更新lru timeval->lru = LRU_CLOCK();}}} else {...}return val;
}
然后在处理指令时,如果发现缓存达到了预设值,会触发内存淘汰策略:
int processCommand(client *c)
{
...if (server.maxmemory && !isInsideYieldingLongCommand()) {//达到了预设值了,这里开始处理内存淘汰逻辑int out_of_memory = (performEvictions() == EVICT_FAIL);...}...
}
//伪代码
int performEvictions(void)
{if (如果是LRU或者LFU策略或者volatile-ttl策略){while (memFree < memNeedFree) {for (i = 0; i < server.dbnum; i++) {db = server.db+i;dict = (如果淘汰策略是针对allkeys) ? db->dict : db->expires;if (只要dict里有数据) {evictionPoolPopulate(i, dict, db->dict, 淘汰候选池);}}}}else if (如果是两种随机策略){for (i = 0; i < server.dbnum; i++) {//用一个静态变量next_db,这样每次都不会只命中第一个dbj = (++next_db) % server.dbnum;db = server.db + j;dict = (如果淘汰策略是针对allkeys) ? db->dict : db->expires;bestkey = 随机找一个keybreak;}}for (k = 淘汰候选池大小-1; k >= 0; k--) {bestkey = 从候选池里逆序找真实存在的key }if (bestkey) {最后,在这里回收这个key;memFree += 新释放的内存;}//while执行太久了,break掉if (流逝的时间 > eviction_time_limit_us) {break;}
}
开始处理淘汰策略,并将合适的key放入淘汰候选池内,这个池是已从左到右从小到大排好序的:
void evictionPoolPopulate(int dbid, dict *sampledict, //如果策略是allkey,则是db->dict,//如果是volatile则为db->expiresdict *keydict, //db->dictstruct evictionPoolEntry *pool) //这个是候选池
{//这里开始采样//server.maxmemory_samples是一个预设值,官方建议设置为10count = dictGetSomeKeys(sampledict, samples, server.maxmemory_samples);for (j = 0; j < count; j++) {...if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {//因为每次key在被loopupKey的时候,都会更新它自己的lru时间//这个函数:lru当前时间 - 当前这个key的lru时间idle = estimateObjectIdleTime(o);} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {//取lfu的计数器的计数,这里是255 - 数值,因为最小访问次数的要被淘汰//注意这里顺带给它减少了LFU计数idle = 255-LFUDecrAndReturn(o);} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {//常量 - validle = ULLONG_MAX - (long)dictGetVal(de);} else {}...}
}









![[工业自动化-12]:西门子S7-15xxx编程 - PLC从站 - ET200 SP系列详解](https://img-blog.csdnimg.cn/ed40b7ae0e9b42cbb846bd3ae3a4a03e.png)