| 时间 | 版本 | 修改人 | 描述 |
|---|---|---|---|
| 2023年11月9日09:38:12 | V0.1 | 宋全恒 | 新建文档 |
简介
学习一下CNN,卷积神经网络。使用的视频课程。视觉相关的任务:
- 人脸识别
卷积网络与传统网络的区别:
<img alt=image-20231109094400591 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109094400591.png&pos_id=img-Z35hmB60-1699522025179)>
<img alt=image-20231109094414779 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109094414779.png&pos_id=img-08hzm0rf-1699522028665)>
卷积神经网络是一个三维的数据,是h*w*c
整体架构
<img alt=image-20231109094649673 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109094649673.png&pos_id=img-AGVXtOFG-1699522031824)>
- 输入层
- 卷积层
- 池化层
- 全连接层
卷积层
调度卷积核是5*5*3,也是一个立方体的。
卷积神经网络也是使用一组权重参数进行加权求和得出的。
<img alt=image-20231109094831385 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109094831385.png&pos_id=img-pBCi31QD-1699522034969)>
注: 上图仅演示了一个通道,图像是3通道。
相当于权重参数矩阵为:
<img alt=image-20231109095218835 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109095218835.png&pos_id=img-ZZahJ8Qu-1699522038141)>
卷积神经网络的目的也是找到一组最佳的权重参数。
注: 卷积核的第三个维度一定要一样才行。卷积采用内积实现。Filter的尺寸一般为3, 5,7。 在进行卷积核的时候与卷积核的第三个维度数量相等。
<img alt=image-20231109105238890 src=https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fcdn.jsdelivr.net%2Fgh%2Fyanchenmochen%2Fimgs%2Fimgsimage-20231109105238890.png&pos_id=img-41nSowP4-1699522038975)>
5x5x3代表一个卷积核,该卷积核的深度为3,与输入的深度相同。得到一个特征图,深度与输入图相同。卷积核可以有多个,则可以得到多个特征图。即Feature W0, Feature W1, … 经过多个卷积核得到多个特征图feture picture。
如下图所示:
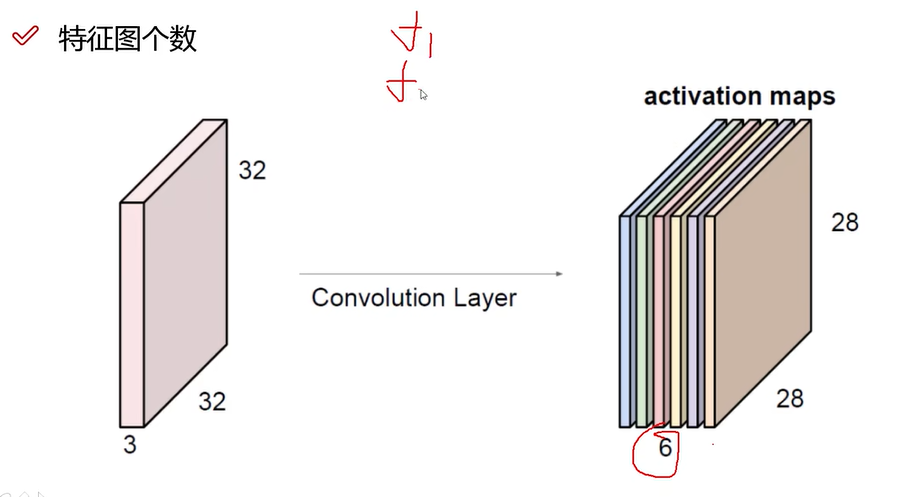
上图经过卷积层得到了28 * 28 * 6个特征图。
将经过卷积核卷积之后的图堆叠在一起,得到了特征图堆。并且,卷积应该经过多次,依次得到Low-level Feature, Mid-Level Feature, High-Level Feature。也就是说,一次卷积是不够的。
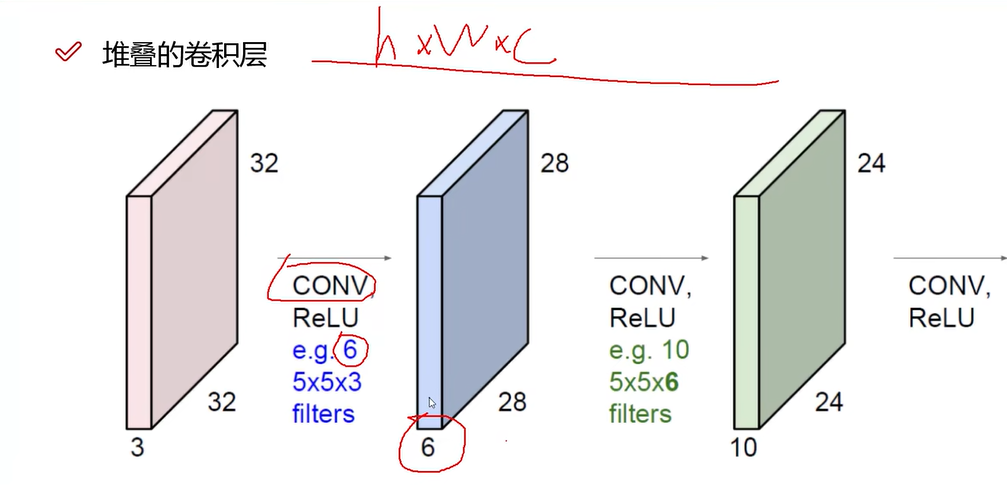
上图说明卷积核5 * 5 * 3得到的是一个值,一个立方体得到一个值。也就是说,一个图如果一个卷积核扫描完全部得到的是一个28 * 28 * 1的图。使用6个卷积核,则得到的卷积图是28 * 28 * 6.
第二卷积是10个 5x5x6得到就是24 * 24 * 10。
卷积核涉及参数
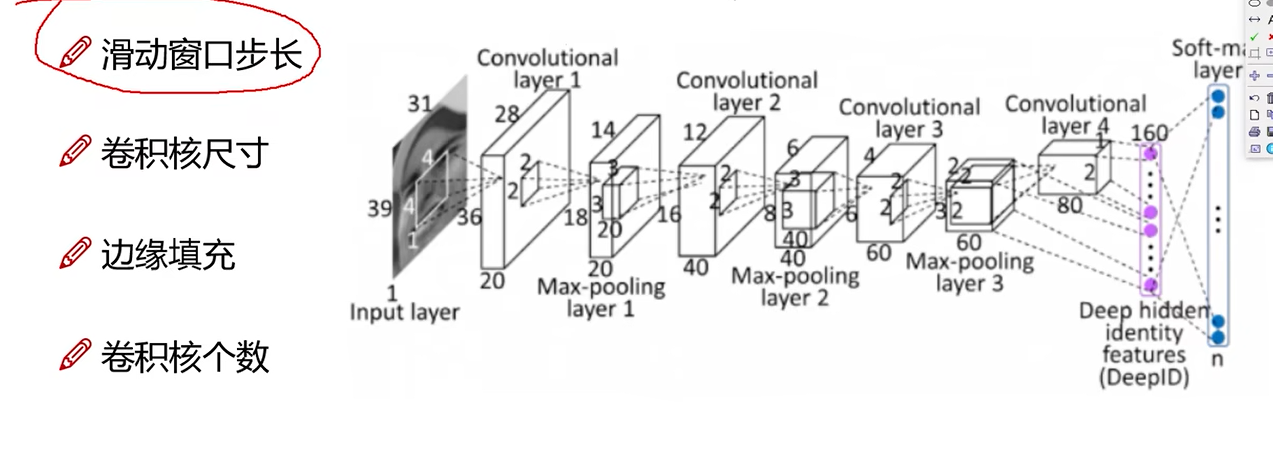
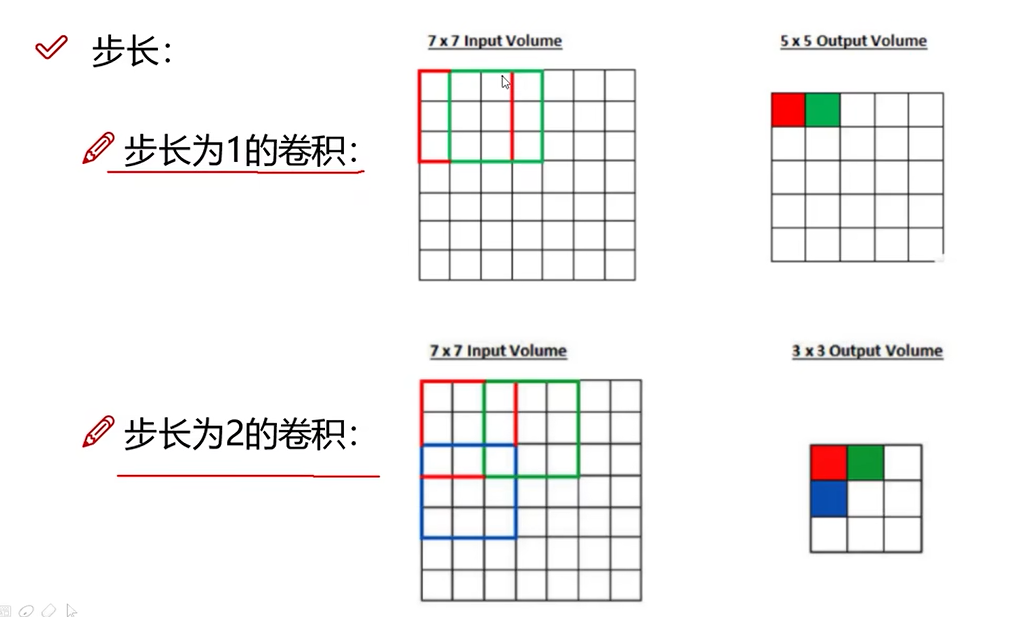
步长
步长为1,得到5 * 5, 而步长为2, 得到3 *3 。 相当于步长越小,得到的特征较多,越丰富。一般视觉任务使用的步长为1,但相应的计算量较大,文本类任务,也有使用步长为2.
卷积核尺寸
卷积核尺寸越小,越细粒度。 一般是3 * 3。
边缘填充
+pad,边缘填充属性。
越往边界的点,被利用的次数越少。下图中原始输入是5 * 5,通过边缘填充在边缘上变成了7 * 7. 又不希望添加的值影响计算。所以一般使用zero padding。
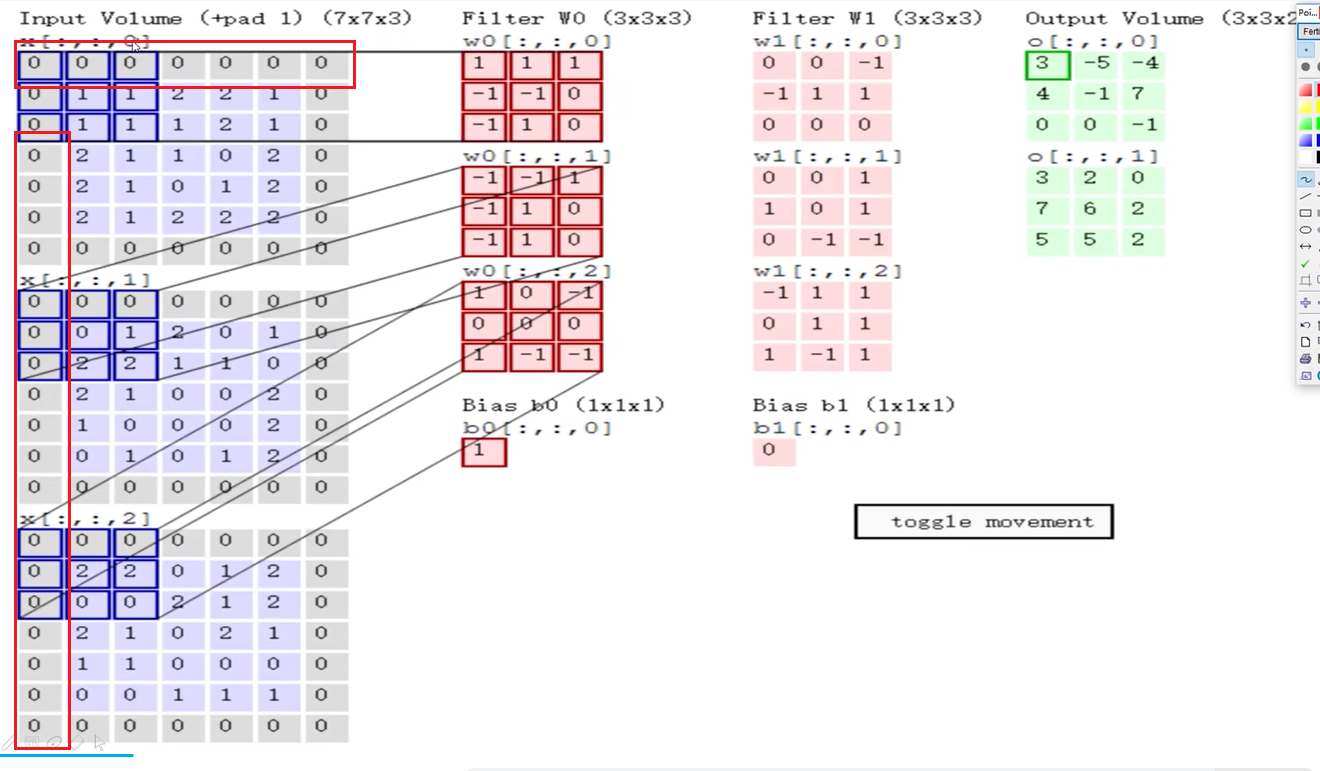
卷积计算公式
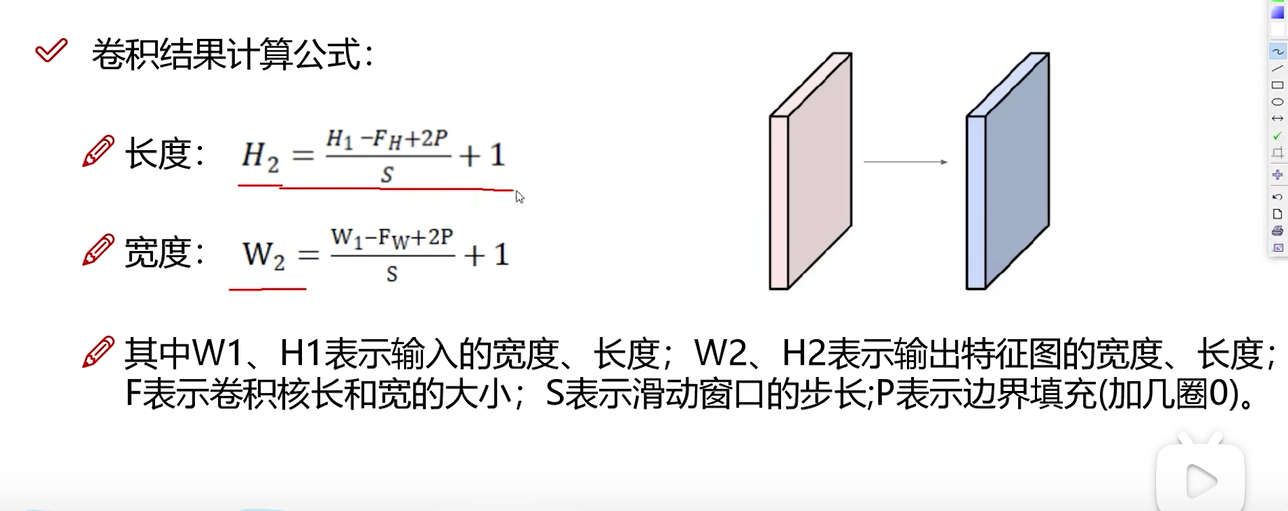
对于下面的案例,可以得到输出的尺寸:

在听这个课程的时候,学习了卷积核的作用。卷积核的深度与输入是相同的,因此,卷积核是一个立方体。但是得到的结果确实一个平面。因为一个输入图像区域只得到了一个值
具体可以参见 3D
2D卷积可以参见 2D卷积
卷积参数共享
卷积参数共享一个巨大的好处就是参数共享,同样的一组参数对图像中每个小区域进行处理。相对于传统的神经网络,参数降低了非常多。
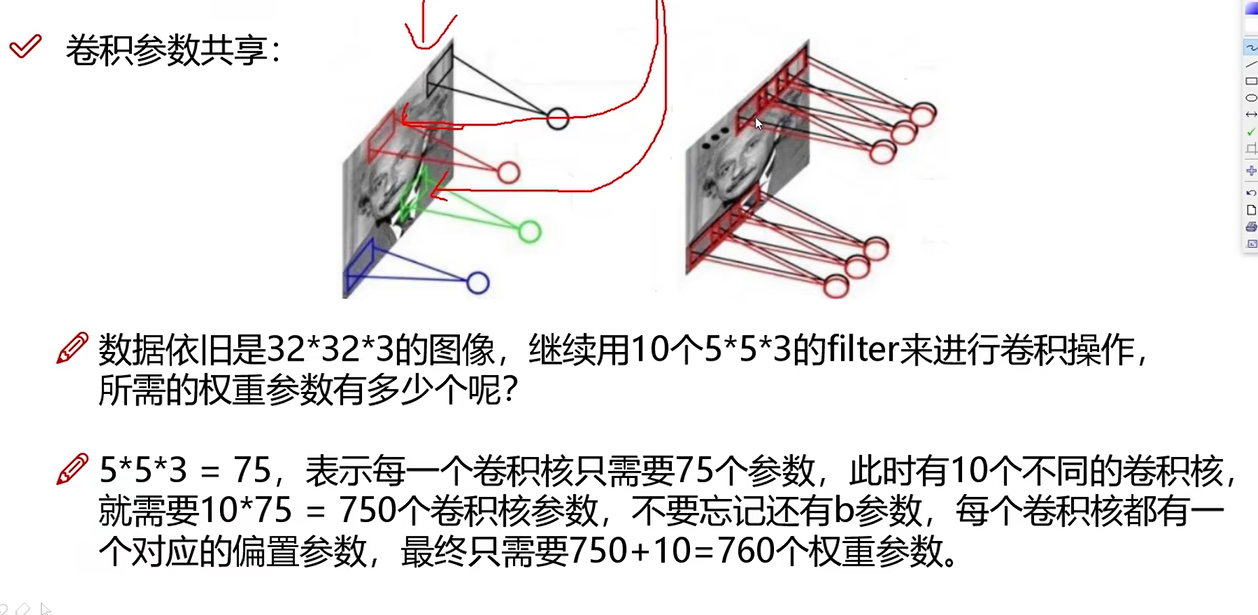
10个 5 * 5 * 3卷积核,共75 * 10 =750个卷积参数 再加上10个偏置项共760个参数。
池化层
卷积层的特征点太多,会导致计算量过大。而且有些特征对于任务并不重要。因此可以通过池化进行瘦身。降采样 downsample。
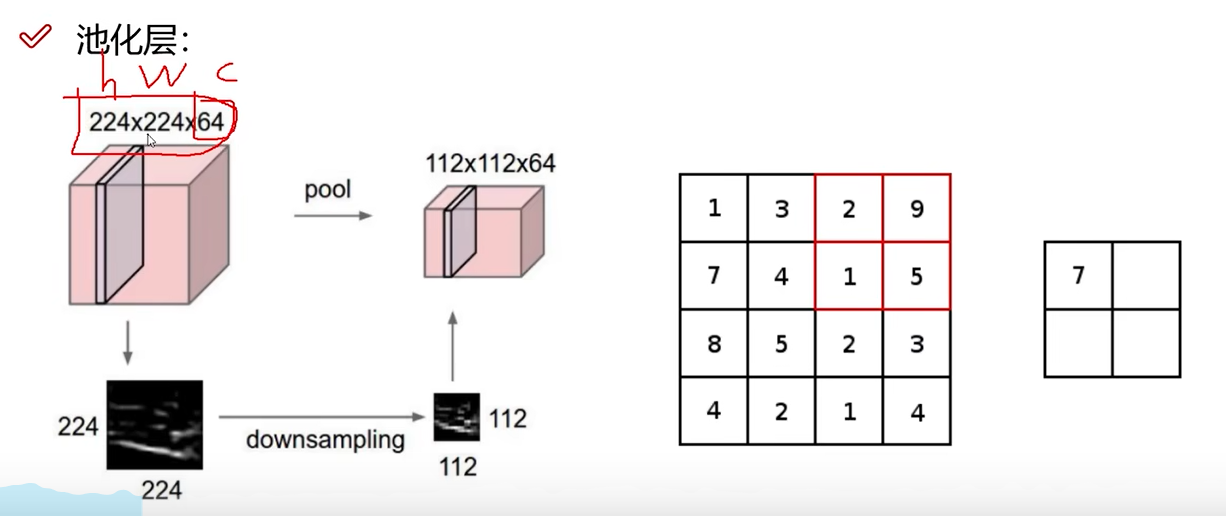
降采样的方式有最大值采样,平均值采样。 降采样也有区域和步长。2 * 2 并且步长为2.池化层不涉及矩阵操作,而是仅仅筛选动作。
- max pooling 最好的特征。
- 平均值池化 average pooling 用的比较少。
任务
如下图,卷积层要经过relu, 非线性变换。卷积层和relu是一组。经过卷积组,池化,然后最后一个全连接FC进行分类。
每个卷积组:
- 卷积
- Relu
在卷积层最后进行全连接时,需要将特征图进行拉长操作,将图拉成一个特征向量。最后与分类数量个神经元进行全连接。
一层神经网络: 带参数计算。relu是没有参数计算的。即激活没有参数。即POOL也没有参数计算的。如下图一共是7层神经网络。
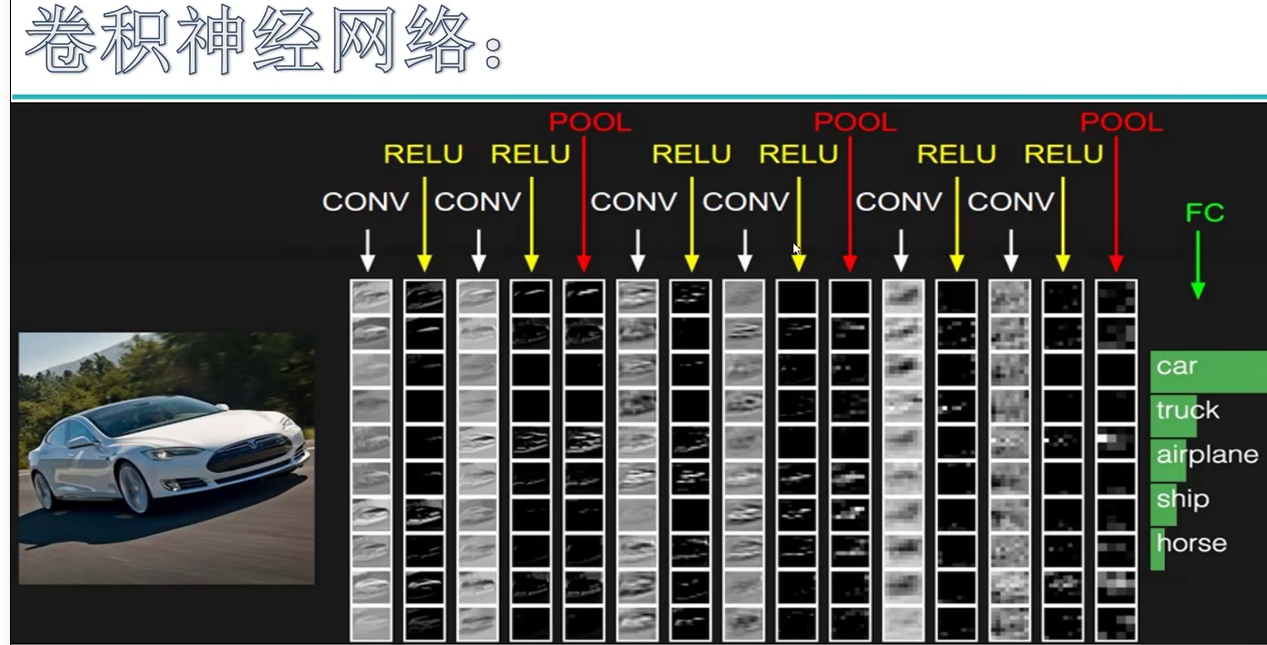
特征图变化如下:
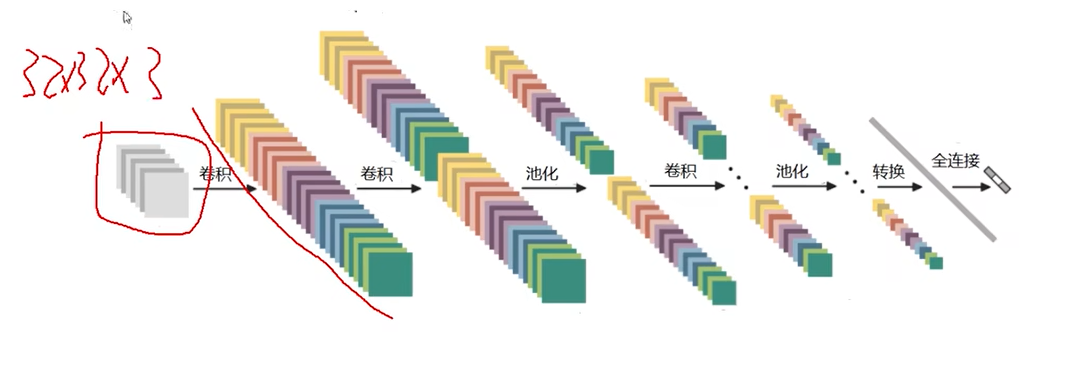
上图中转换即拉伸成向量。
Alexnet-2012
227 * 227 * 3

VGG-经典网络-2014
VGG filter均为3 * 3,卷积核比较小,网络层数为16。在池化后,通过增加卷积次数,即增加特征图的数量来弥补池化的损失。但Alexnet训练8小时,VGG可能需要3天才能训练完成。
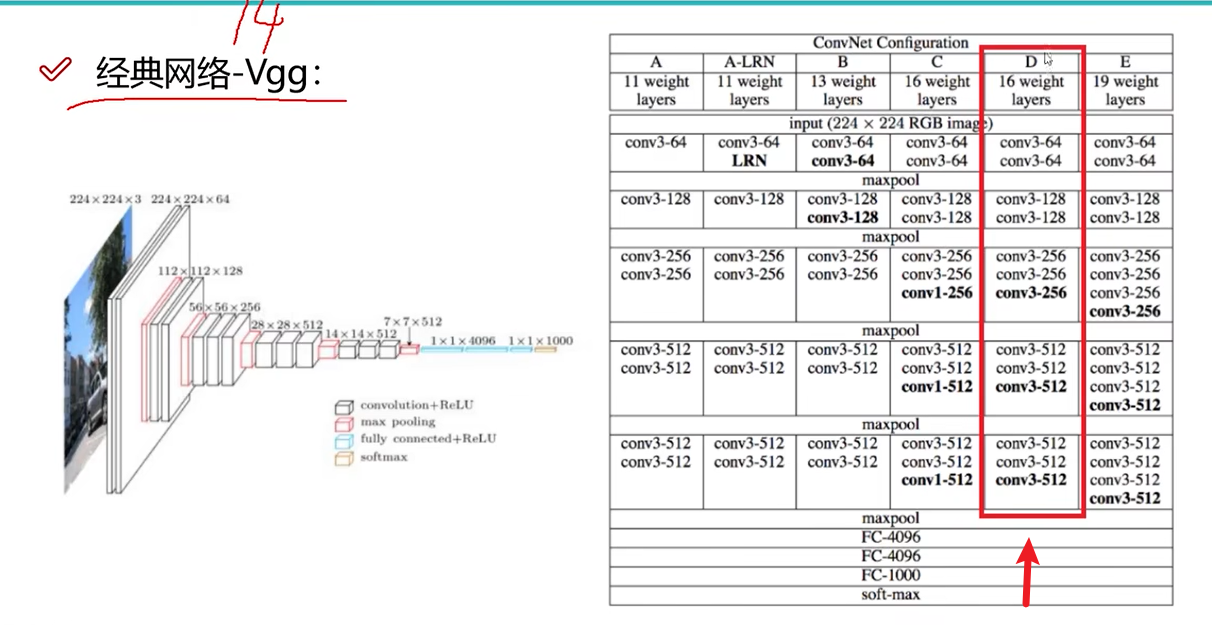
VGG 在实验室 16层的网络,比30层的时候效果好,因为深度学习,越深越好,但实验结果令人失望,深度学习进入低谷。
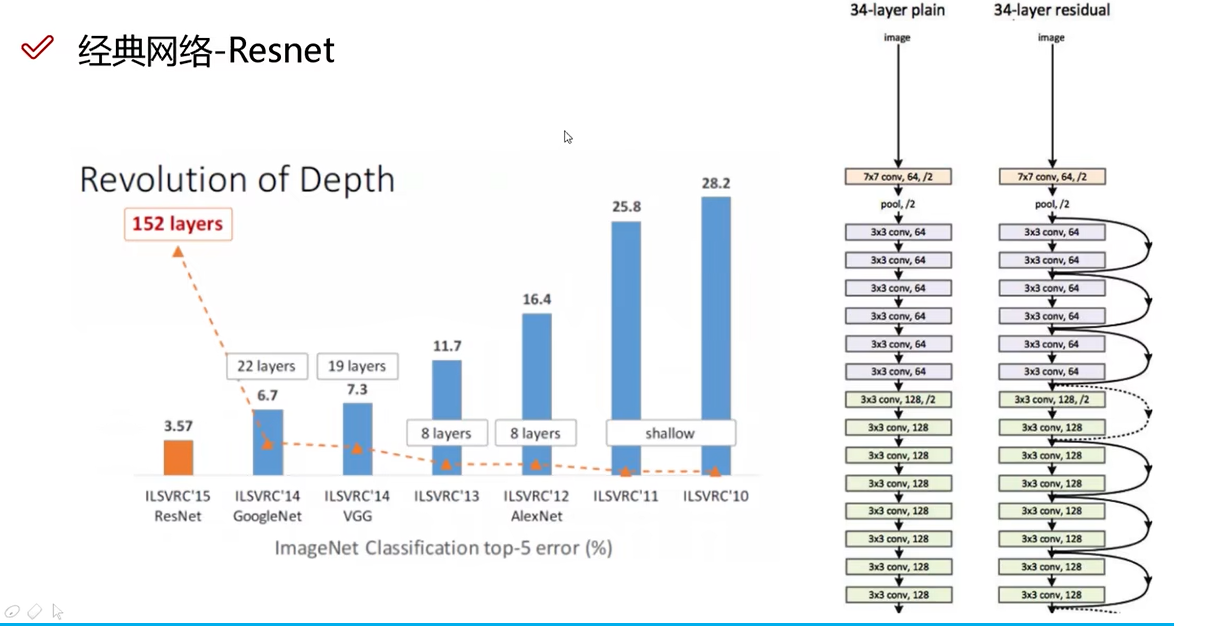
Resnet残差网络-2015
何凯明的工作,将增加层数中具有促进效果的层数保留,网络训练的结果一定不会比之前差。
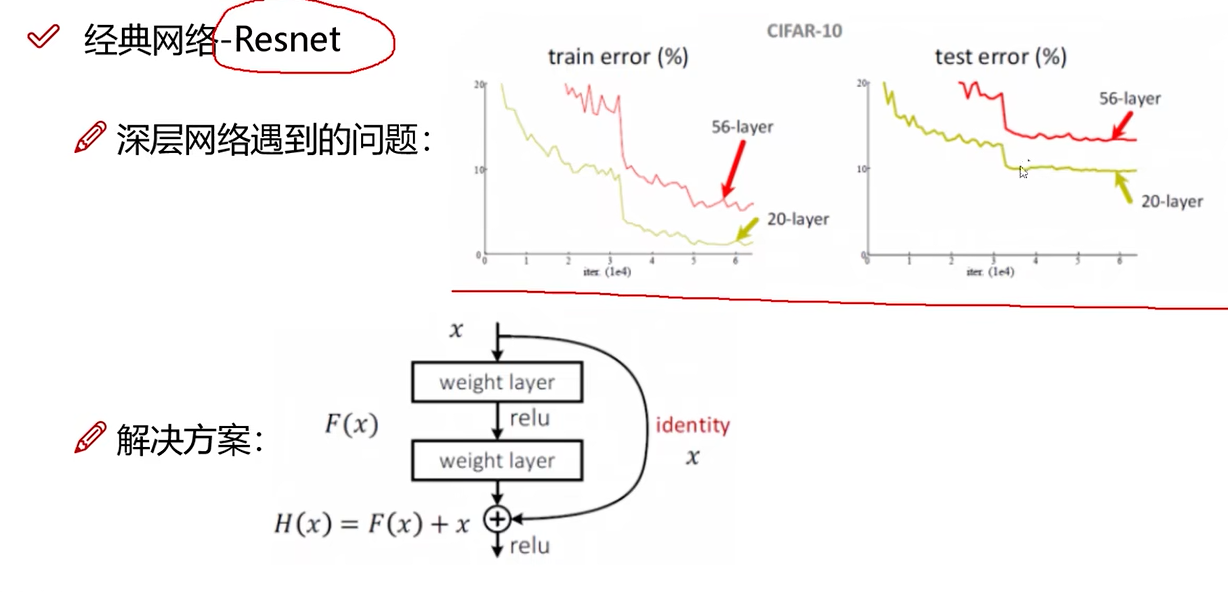
相当于残差网络拯救了深度学习神经网络。Resnet更加经典,更主流。
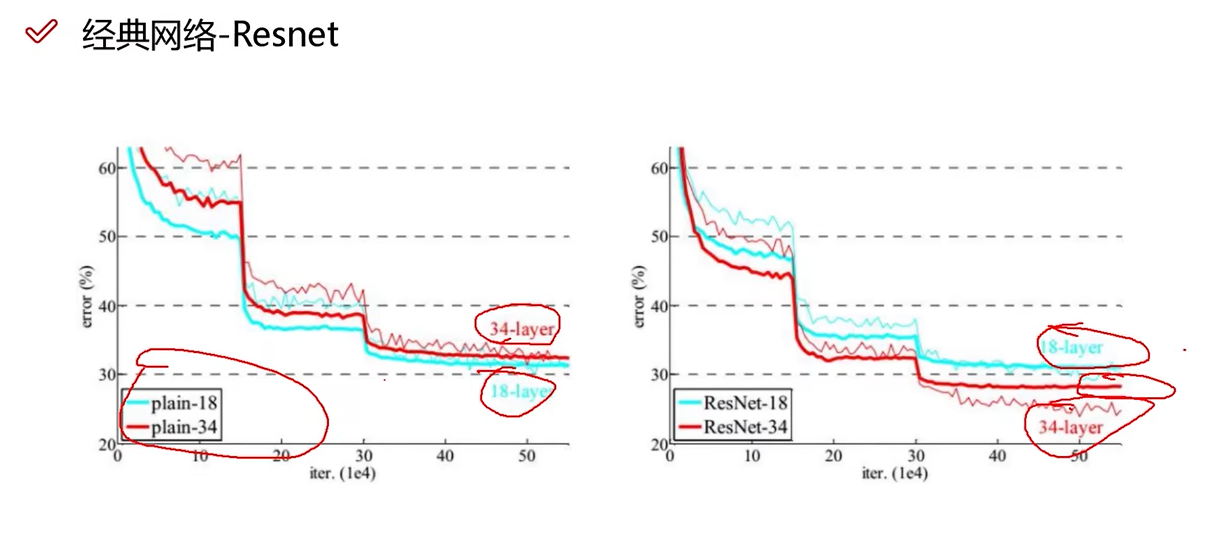
下图中橙色为Resnet,误差更小。
感受野
感受野有什么作用:希望感受野越来越大。3个3 * 3 得到的感受野为7 * 7, 那么与直接使用7 * 7的卷积核进行卷积需要的区别。
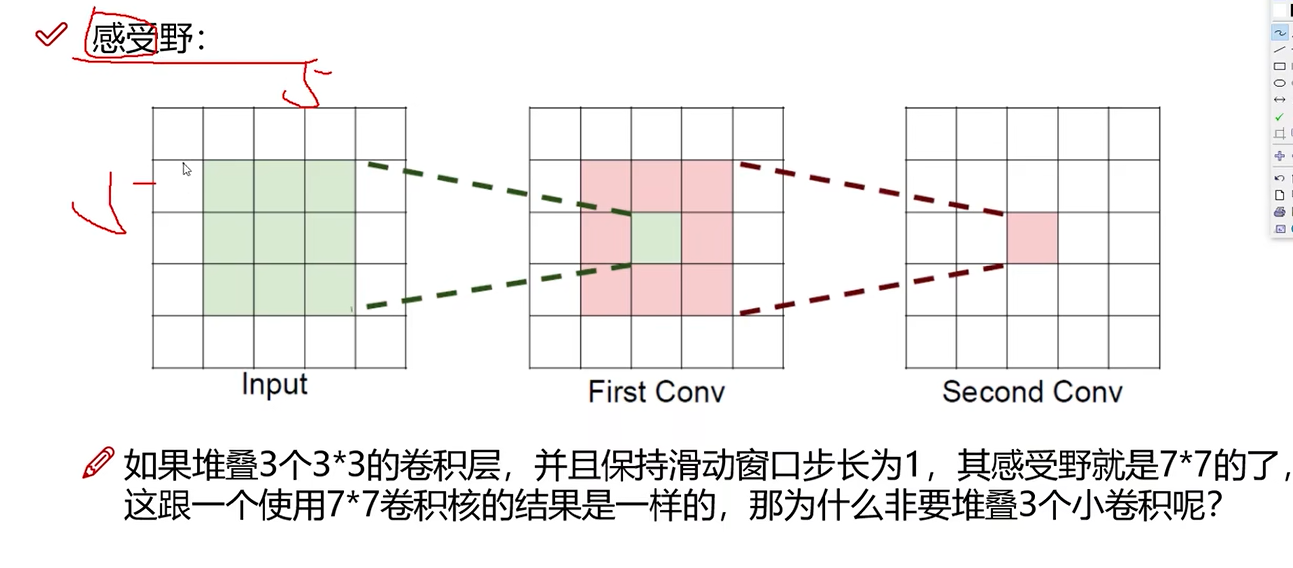
堆叠小的卷积核需要的参数越少,训练更快。而且小卷积核由于经过的relu次数多,非线性特征保存的更好。

项目实战
构造神经网络
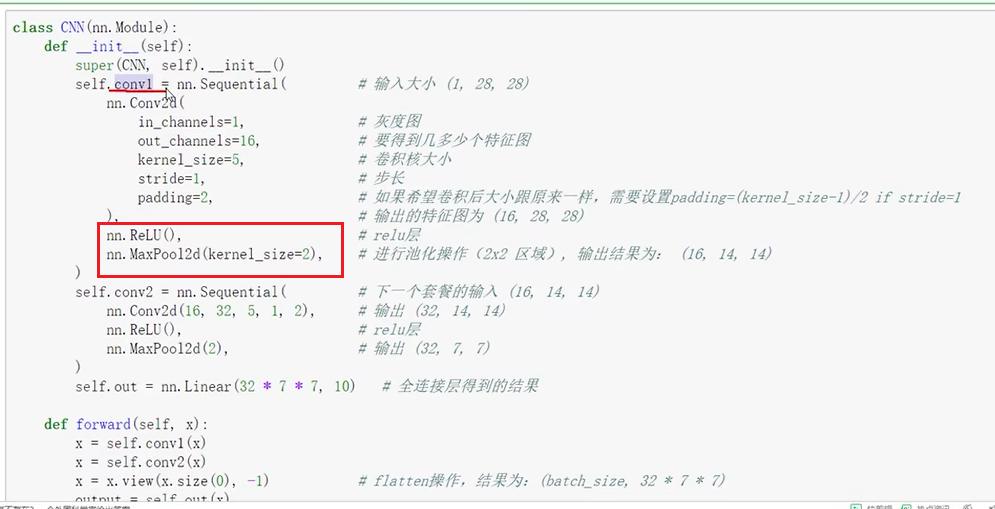
conv + relu 是一个组合。
-
in_channels : 通道数。
-
out_channels: 16,使用16个特征图。
-
kernel_size=5; 卷积核尺寸5 * 5
-
stride = 1; 步长。
-
padding=2 ; 边缘填充。
-
前向传播得到预测结果

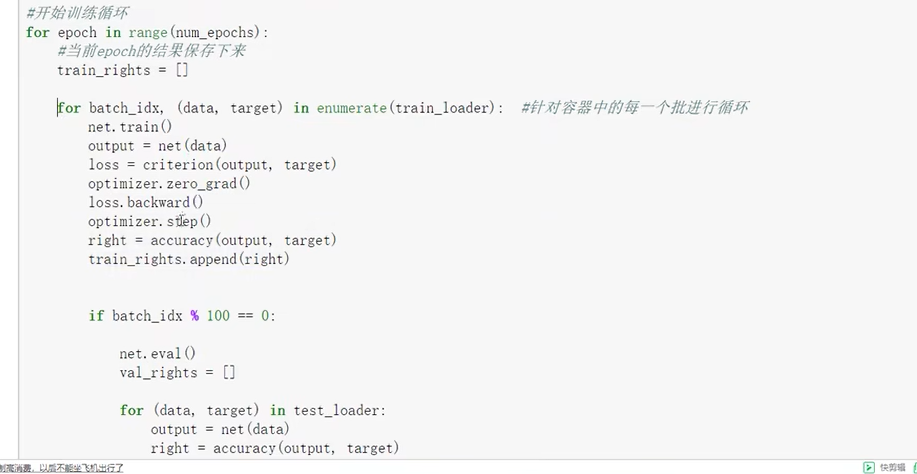
训练
使用pytorch进行训练。
Vision模块
TorchVision有许多的数据集。
-
数据预处理
- dataset数据集
-
网络模块设置
分类任务
semantic segmentation
object detection, instance segmentation and Person Keypoint Detection
Video classfication
- 甚至可以拿到别人的预训练模型

- 网络模型保存和测试
- transforms
- PIL Image
- transforms
任务
任务介绍
flowers 一共102种分类。
要把数据和标签读进来。ImageFolder工具。
- 数据预处理
- DataLoader模块直接读取batch数据
- 网络模块设置
- 迁移学习
- 需要把head层改一改 256 * 256 , 224 * 224
- 训练时可以全部重新训练,也可以只训练咱们任务的层,本质目标是一致的。
- 网络模型保存与测试
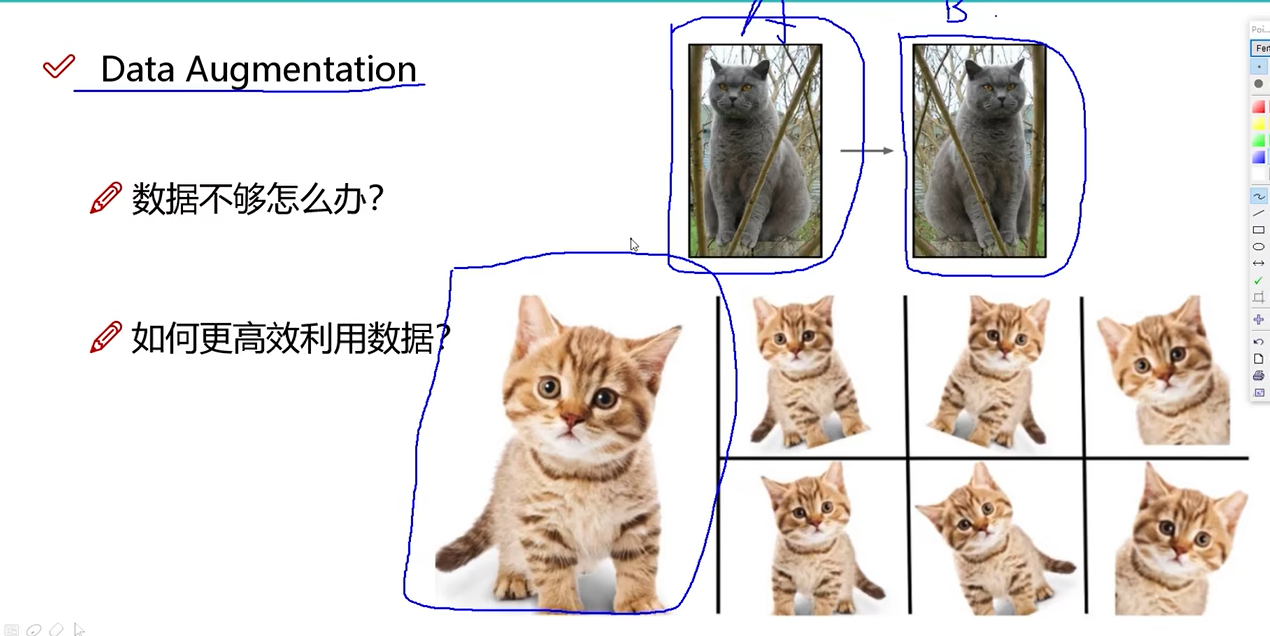
数据增强Data Augmentation
让数据量更多。
数据不够时,这样做。
如何更好的利用数据,倾斜,水平和垂直翻转,旋转,放大和缩小,即得到一个新的数据。
一般,网络的输入大小是固定的,因此,需要resize成预期大小。
下面代码中CenterCrop(224)中心裁剪。
RandomhorizontalFlip(p=0.5)概率值,是随机翻转的概率。
亮度,对比度,饱和度 色相。
transforms.Normalize() 即要进行标准化,参数1为均值, 参数2为标准差
具体的样例代码:
训练集做了标准化,则测试集也要做相同的标准化。
数据加载

读取标签对应的名字
展示下数据

迁移学习
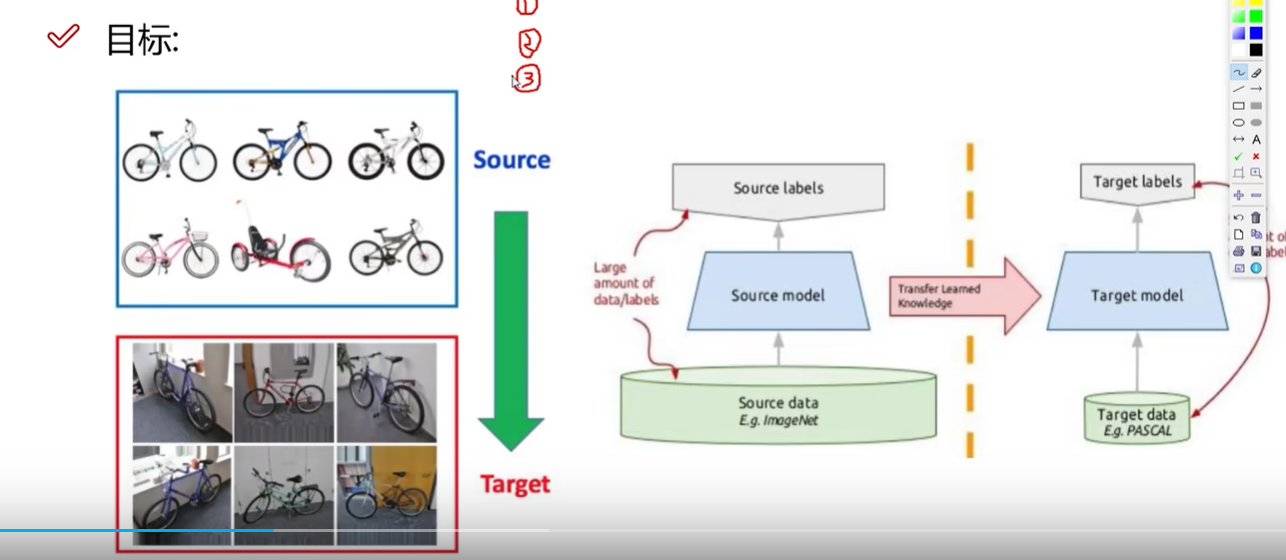
迁移学习的目标是用别人训练好的参数来执行任务。尽可能差异比较少一些。
那么迁移学习,学那个部分呢:
- A: 使用卷积层的权重参数进行初始化。
- B: 将人家训练好的参数冻住。对全连接层进行重新定义。
- 数据量越小,冻住的参数越多。不到10000.
- 数据量10000多,两万。挑出来一些。
迁移学习,学习的非常快。迁移学习拿过来的模型都是经过大量实验的结果,经典网络结构,得到的结果更快也更好。如VGG, ResNet。
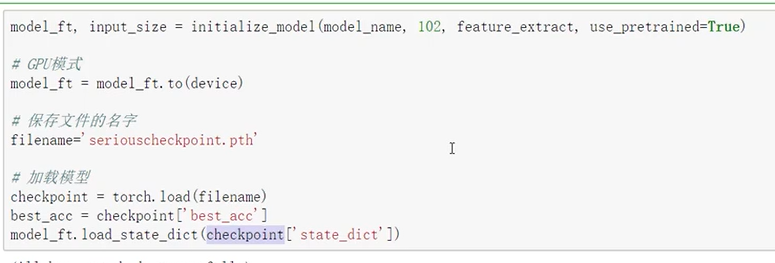
模型加载
需要指定模型名称
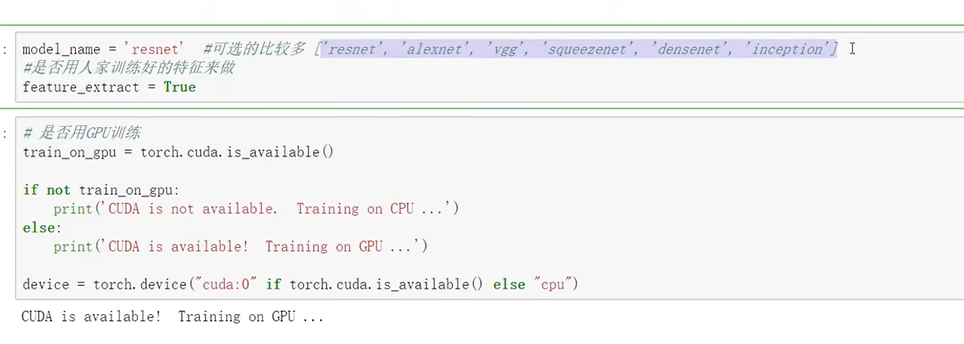
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
需要修改最后全连接层,为当前用户的任务分类数目。
加载模型,并使用预训练模型。
~/.cache/checkpoints/resnet152-b121ed2d.pth
model_ft = models.resnet152(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs=model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs,102), nn.LogSoftmax(dim=1))
input_size= 224
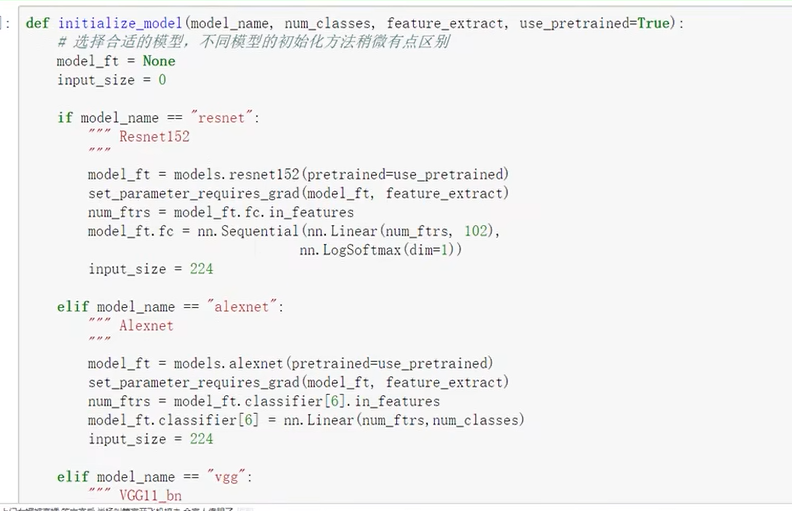
设置那些层需要训练
如下的参数中:
- model_name 指定了要使用的模型
- 102 指定了目标分类数
- feature_extract: 是否要冻住某些模型
- use_pretrained: 是否要使用预训练模型。
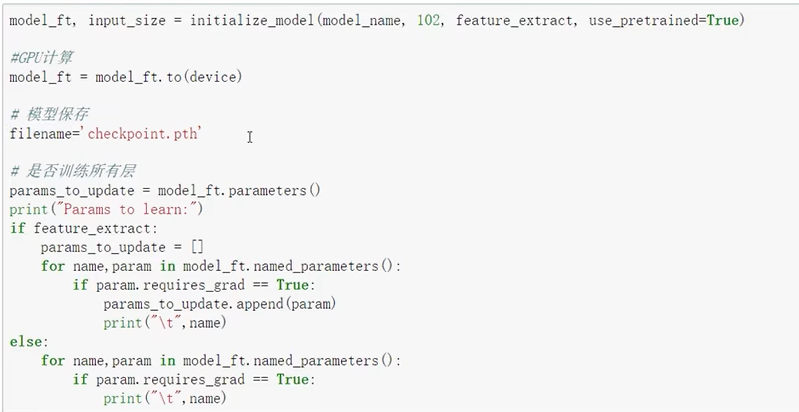
显示那些参数需要重新开始训练。

优化器设置
使用了学习率的衰减函数。效果会更稳定一些。

训练模块
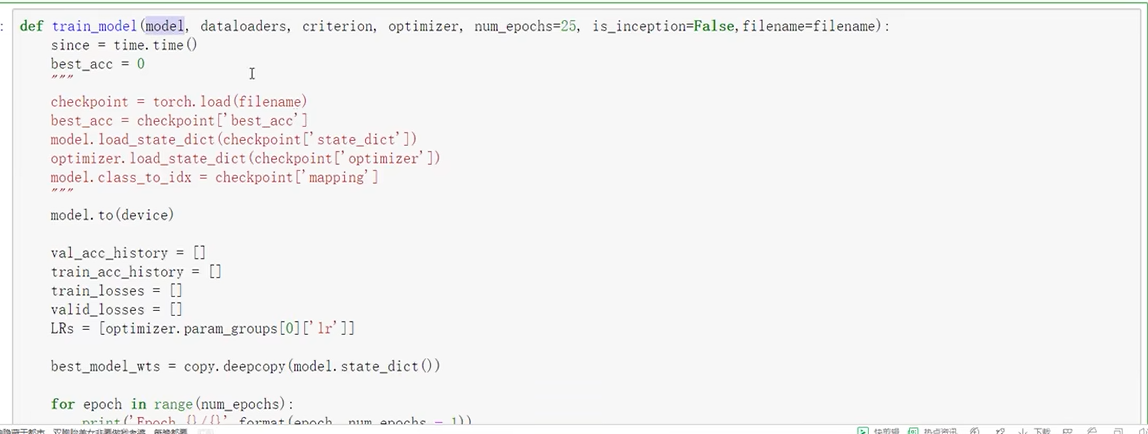
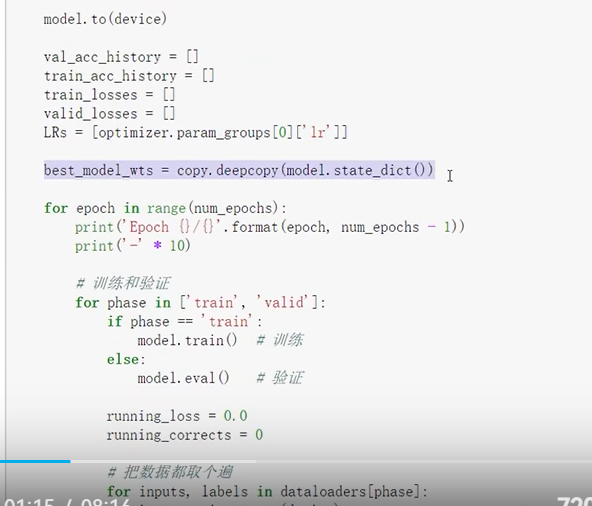
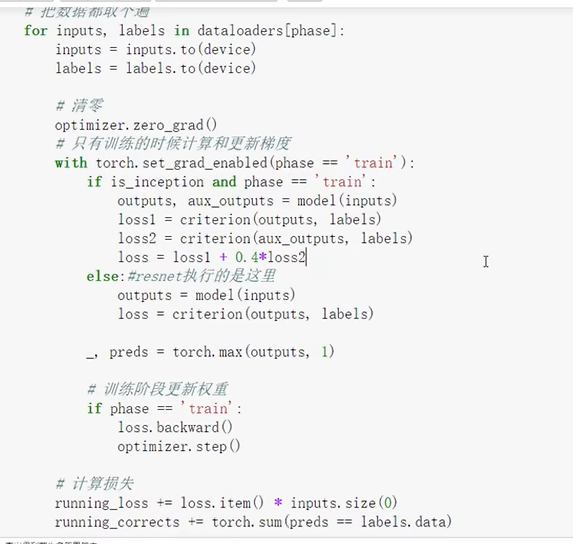

保存模型参数权重字典
准确率
优化器参数权重字典

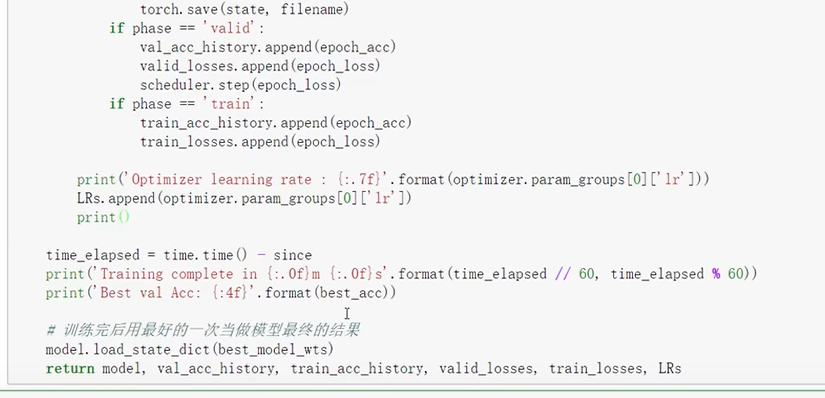
开始训练
model_fit, val_acc_history, train_acc_history, valid_losses, train_losses, LRs = train_model(model_ft, dataloaders, criterion, optimizer, num_epoches=10, is_inception=(model_name=='inception'))
测试网络效果
完整训练
将所有参数的require_grad设置为TRue,将学习率调整的小一些,以为之前用了别人的网络参数,学习率过大,可能会破坏掉之前的训练参数。
<img alt= src=https://cdn.jsdelivr.net/gh/yanchenmochen/imgs/imgsimage-20231109165735676.png>
Load the checkpoint
加载之前保存的最好的模型继续开始训练。
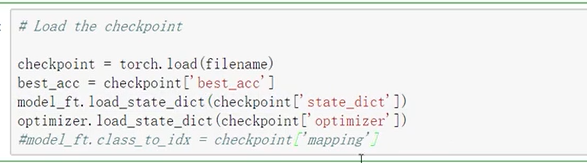
实际测试

加载模型
测试数据预处理
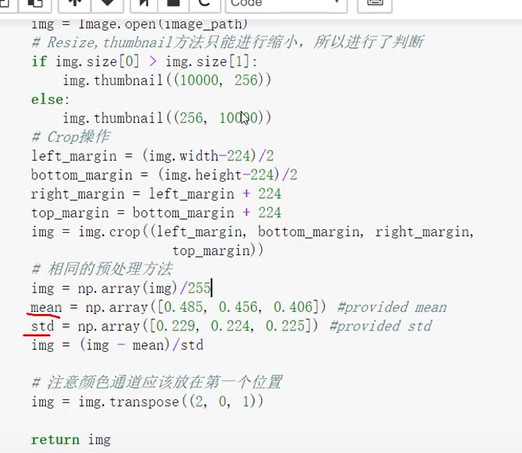
将一张图像处理成输入。
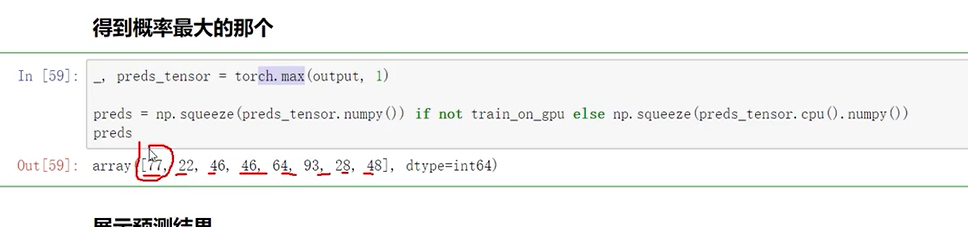
得到处理结果
8是因为batchsize。

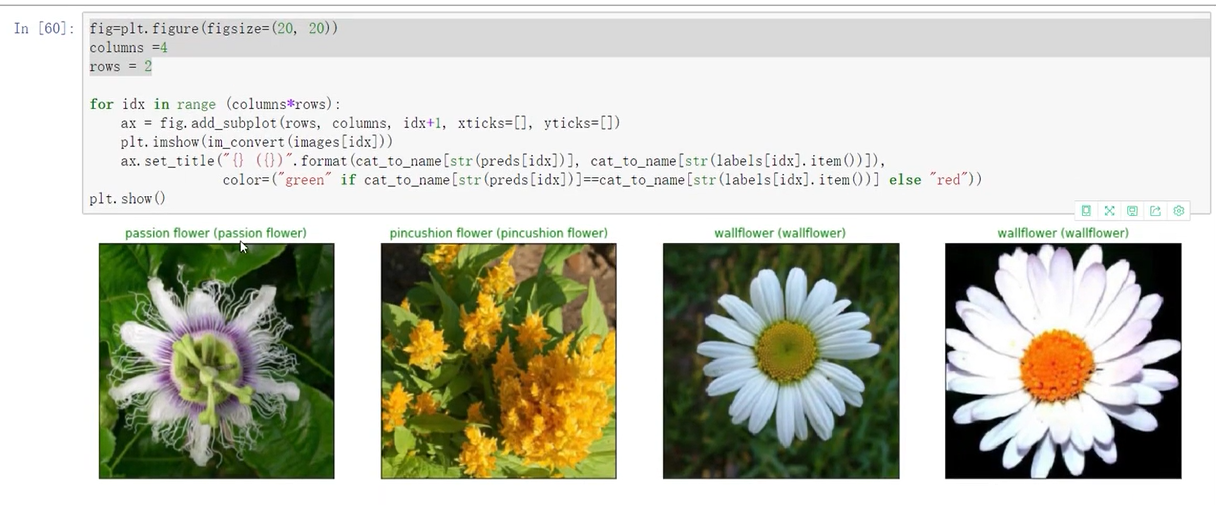
总结
看了一天这个课程,终于看完了,对于卷积神经网络也算是有了更加进一步的理解了。现在就是要多多实战,敲代码就好了。现在还有点困惑的点包括:
- 优化器的选择
- 损失函数的选择
不过,这个课程让自己对于卷积的理解加深了许多。