百度深度学习框架PaddlePaddle
百度深度学习框架PaddlePaddle是一个支持深度学习和机器学习的开源框架。它由百度公司于2016年开发并发布,现在已经成为中国最受欢迎的深度学习框架之一,并且在国际上也获得了不少关注。
特点与功能
易于使用
PaddlePaddle提供了Python API和命令行工具,使得使用者可以轻松地构建、训练和部署深度学习模型。同时,PaddlePaddle还内置了各种深度学习模型和数据集,用户只需要进行简单的调用就可以快速上手。
多种神经网络结构
PaddlePaddle支持大规模的神经网络结构,包括:卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元网络(GRU)等。此外,PaddlePaddle还支持自定义神经网络结构,方便用户根据实际需求进行修改和优化。
分布式训练和推理
为了应对大规模数据和高并发访问的需求,PaddlePaddle支持分布式训练和推理,可以将计算负载分配到多个GPU或多台服务器上进行处理,从而提高计算效率和处理能力。
高性能和高效稳定
PaddlePaddle通过使用高效的并行计算技术和动态图执行引擎,保证了高性能和高效稳定。此外,PaddlePaddle还支持异构计算,可以充分利用GPU、FPGA等硬件设备的优势。
应用广泛
PaddlePaddle被广泛应用于图像识别、自然语言处理、语音识别、推荐系统等领域。例如,百度的图片搜索、语音识别、知识图谱等产品都是基于PaddlePaddle开发的。
优势与竞争
动态图机制
PaddlePaddle采用了动态图机制,相比于静态图机制,可以更加灵活地构建和优化神经网络模型,同时还可以实现更好的可读性和可维护性。
跨平台支持
PaddlePaddle支持Windows、Linux和MacOS等不同操作系统,在不同的平台上都可以进行深度学习模型的构建和训练。
分布式训练优势
PaddlePaddle的分布式训练具有优秀的性能和可扩展性,可将计算负载分配到多台服务器上进行处理,有效地提高了训练速度和精度。
商业落地
百度在多个行业都有应用实践,PaddlePaddle也得到了广泛的商业落地,包括金融、医疗、智能驾驶等领域。
相关链接
- 官方网站:https://www.paddlepaddle.org.cn/
- PaddlePaddle Github:https://github.com/PaddlePaddle/Paddle
- PaddlePaddle中文文档:https://www.paddlepaddle.org.cn/documentation/docs/zh/index_cn.html
AI Studio
AI Studio是由百度开发的深度学习和人工智能开发平台,旨在为开发者提供一站式的解决方案。AI Studio集成了PaddlePaddle等多种深度学习框架,提供了可视化的界面、强大的计算资源和丰富的数据集,让用户可以快速构建、训练和部署深度学习模型。
特点与功能
可视化交互界面
AI Studio提供了基于Web的可视化交互界面,用户可以通过简单的拖拽和配置完成模型的构建和训练。同时,AI Studio还支持Jupyter Notebook和Python编程环境,方便用户进行自定义操作。
强大的计算资源
AI Studio提供了GPU和CPU等多种计算资源,用户可以根据实际需求选择合适的资源来进行模型训练和推理。此外,AI Studio还支持分布式训练和推理,可以将计算负载分配到多个计算节点上进行处理。
丰富的数据集
AI Studio集成了各种常见的数据集,包括:ImageNet、CIFAR-10/100、MNIST、LFW等。用户可以直接使用这些数据集进行模型训练,也可以上传自己的数据集进行训练和测试。
多种深度学习框架支持
AI Studio除了支持PaddlePaddle之外,还支持TensorFlow、PyTorch等多种深度学习框架。用户可以根据自己的喜好和需求选择合适的框架来进行开发。
应用场景广泛
AI Studio被广泛应用于图像识别、自然语言处理、推荐系统等领域。例如,在图像识别方面,AI Studio可以用于物体检测、图像分割、人脸识别等任务;在自然语言处理方面,AI Studio可以用于文本分类、情感分析、机器翻译等任务。
相关链接
- AI Studio官网:https://aistudio.baidu.com/
- AI Studio中文文档:https://ai.baidu.com/docs#/AIStudio/top
开始配置
这里我们配置这个项目的环境
基于ppyoloe-sod海星目标检测(小目标检测)
虚拟环境创建
call cmd
rem 创建虚拟环境
python -m venv venv
rem 激活虚拟环境
call venv\Scripts\activate.bat
python -m pip install --upgrade pip
半自动化使用.bat手动打包迁移python项目
lap
lab包直接装装不上,使用编译安装法
https://pypi.org/project/lap/#files
pip install -i https://mirrors.aliyun.com/pypi/simple/ numpy<1.24
curl -o lap-0.4.0.tar.gz https://files.pythonhosted.org/packages/bf/64/d9fb6a75b15e783952b2fec6970f033462e67db32dc43dfbb404c14e91c2/lap-0.4.0.tar.gz
tar -zxvf lap-0.4.0.tar.gz
cd lap-0.4.0
python setup.py build
python setup.py install
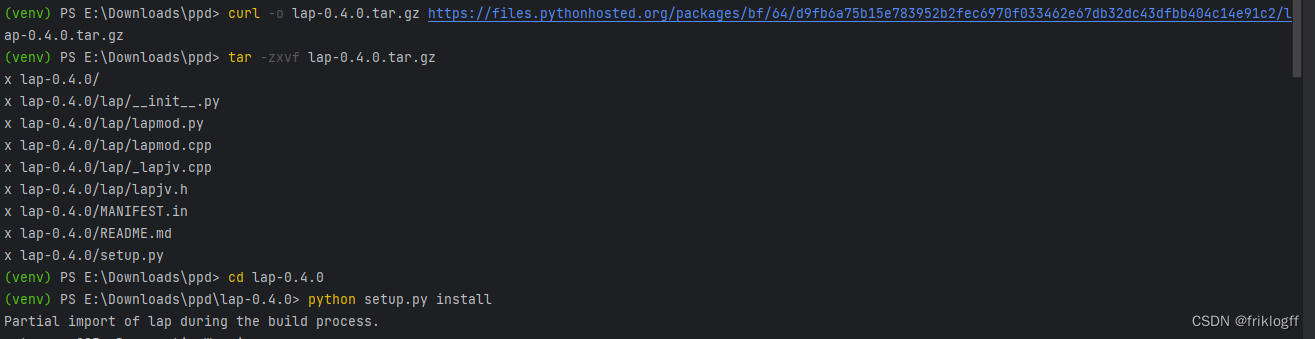
pip show lap
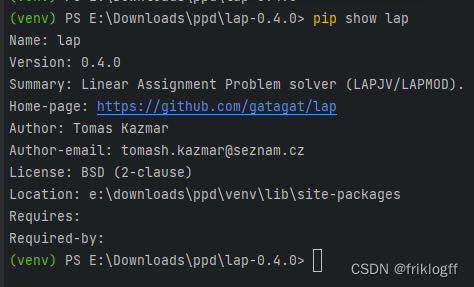
下载PaddleDetection
git clone https://gitee.com/PaddlePaddle/PaddleDetection.git
pip install -i https://mirrors.aliyun.com/pypi/simple/ opencv-python==4.5.3.56
pip install -i https://mirrors.aliyun.com/pypi/simple/ pycryptodome
#安装PaddleDetection相关依赖
pip install -r PaddleDetection/requirements.txt
python PaddleDetection/setup.py install
AI Studio会自动创建version.py,这里我们需要在该路径手动创建
PaddleDetection\ppdet\version.py
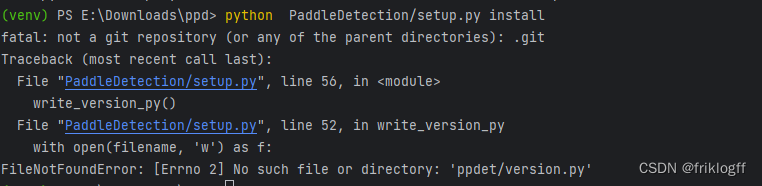
(venv) PS E:\Downloads\ppd> python PaddleDetection/setup.py install
fatal: not a git repository (or any of the parent directories): .git
Traceback (most recent call last):
File “PaddleDetection/setup.py”, line 56, in
write_version_py()
File “PaddleDetection/setup.py”, line 52, in write_version_py
with open(filename, ‘w’) as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘ppdet/version.py’
然后
cd PaddleDetection
python setup.py install
requirements.txt
numpy < 1.24
tqdm
typeguard
visualdl>=2.2.0
opencv-python <= 4.6.0
PyYAML
shapely
scipy
terminaltables
Cython
pycocotools
setuptools# for MOT evaluation and inference
lap
motmetrics
sklearn==0.0# for vehicleplate in deploy/pipeline/ppvehicle
pyclipperpip list
(venv) PS E:\Downloads\pad> pip list
Package Version
anyio 4.0.0
astor 0.8.1
Babel 2.13.0
bce-python-sdk 0.8.92
blinker 1.6.3
certifi 2023.7.22
charset-normalizer 3.3.0
click 8.1.7
colorama 0.4.6
contourpy 1.1.1
cycler 0.12.1
Cython 3.0.4
decorator 5.1.1
exceptiongroup 1.1.3
filelock 3.12.4
fire 0.5.0
Flask 3.0.0
flask-babel 4.0.0
fonttools 4.43.1
fsspec 2023.9.2
future 0.18.3
h11 0.14.0
httpcore 0.18.0
httpx 0.25.0
idna 3.4
importlib-metadata 6.8.0
importlib-resources 6.1.0
itsdangerous 2.1.2
Jinja2 3.1.2
joblib 1.3.2
kiwisolver 1.4.5
lap 0.4.0
llvmlite 0.39.1
MarkupSafe 2.1.3
matplotlib 3.7.3
motmetrics 1.4.0
mpmath 1.3.0
networkx 3.1
numba 0.56.4
numpy 1.23.5
opencv-python 4.5.5.64
opt-einsum 3.3.0
packaging 23.2
paddle-bfloat 0.1.7
paddledet 2.6.0
paddlepaddle 2.5.1
paddlepaddle-gpu 2.5.1
pandas 2.0.3
Pillow 10.1.0
pip 23.3
protobuf 3.20.2
psutil 5.9.6
pybboxes 0.1.6
pyclipper 1.3.0.post5
pycocotools 2.0.7
pycryptodome 3.19.0
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
PyYAML 6.0.1
rarfile 4.1
requests 2.31.0
sahi 0.11.14
scikit-learn 1.3.1
scipy 1.10.1
tzdata 2023.3
urllib3 2.0.7
visualdl 2.5.3
Werkzeug 3.0.0
xmltodict 0.13.0
zipp 3.17.0
本地运行
"""NAME : 3kshUSER : adminDATE : 18/10/2023PROJECT_NAME : ppdCSDN : friklogff
"""
# 调用一些需要的第三方库
import numpy as np
import pandas as pd
import shutil
import json
import os
import cv2
import glob
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import seaborn as sns
from matplotlib.font_manager import FontProperties
from PIL import Image
import random
###解决中文画图问题
myfont = FontProperties(fname=r"NotoSansCJKsc-Medium.otf", size=12)
plt.rcParams['figure.figsize'] = (12, 12)
plt.rcParams['font.family']= myfont.get_family()
plt.rcParams['font.sans-serif'] = myfont.get_name()
plt.rcParams['axes.unicode_minus'] = False# 加载训练集路径
TRAIN_DIR = 'kaggle_dataset/train2017/'
TRAIN_CSV_PATH = 'TRAIN_CSV_PATH = kaggle_dataset/annotations/train.json'
# 加载训练集图片目录
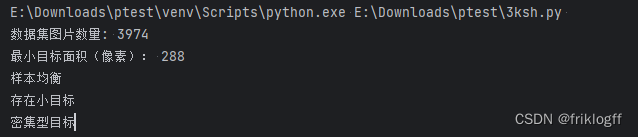
train_fns = glob.glob(TRAIN_DIR + '*')
print('数据集图片数量: {}'.format(len(train_fns)))def generate_anno_result(dataset_path, anno_file):with open(os.path.join(dataset_path, anno_file)) as f:anno = json.load(f)total = []for img in anno['images']:hw = (img['height'], img['width'])total.append(hw)unique = set(total)ids = []images_id = []for i in anno['annotations']:ids.append(i['id'])images_id.append(i['image_id'])# 创建类别标签字典category_dic = dict([(i['id'], i['name']) for i in anno['categories']])counts_label = dict([(i['name'], 0) for i in anno['categories']])for i in anno['annotations']:counts_label[category_dic[i['category_id']]] += 1label_list = counts_label.keys() # 各部分标签size = counts_label.values() # 各部分大小train_fig = pd.DataFrame(anno['images'])train_anno = pd.DataFrame(anno['annotations'])df_train = pd.merge(left=train_fig, right=train_anno, how='inner', left_on='id', right_on='image_id')df_train['bbox_xmin'] = df_train['bbox'].apply(lambda x: x[0])df_train['bbox_ymin'] = df_train['bbox'].apply(lambda x: x[1])df_train['bbox_w'] = df_train['bbox'].apply(lambda x: x[2])df_train['bbox_h'] = df_train['bbox'].apply(lambda x: x[3])df_train['bbox_xcenter'] = df_train['bbox'].apply(lambda x: (x[0] + 0.5 * x[2]))df_train['bbox_ycenter'] = df_train['bbox'].apply(lambda x: (x[1] + 0.5 * x[3]))print('最小目标面积(像素):', min(df_train.area))balanced = ''small_object = ''densely = ''# 判断样本是否均衡,给出结论if max(size) > 5 * min(size):print('样本不均衡')balanced = 'c11'else:print('样本均衡')balanced = 'c10'# 判断样本是否存在小目标,给出结论if min(df_train.area) < 900:print('存在小目标')small_object = 'c21'else:print('不存在小目标')small_object = 'c20'arr1 = []arr2 = []x = []y = []w = []h = []for index, row in df_train.iterrows():if index < 1000:# 获取并记录坐标点x.append(row['bbox_xcenter'])y.append(row['bbox_ycenter'])w.append(row['bbox_w'])h.append(row['bbox_h'])for i in range(len(x)):l = np.sqrt(w[i] ** 2 + h[i] ** 2)arr2.append(l)for j in range(len(x)):a = np.sqrt((x[i] - x[j]) ** 2 + (y[i] - y[j]) ** 2)if a != 0:arr1.append(a)arr1 = np.matrix(arr1)# print(arr1.min())# print(np.mean(arr2))# 判断是否密集型目标,具体逻辑还需优化if arr1.min() < np.mean(arr2):print('密集型目标')densely = 'c31'else:print('非密集型目标')densely = 'c30'return balanced, small_object, densely# 分析训练集数据
generate_anno_result('kaggle_dataset', 'annotations/train.json')# 图片大小分布
# 读取训练集标注文件
with open('kaggle_dataset/annotations/train.json', 'r', encoding='utf-8') as f:train_data = json.load(f)
train_fig = pd.DataFrame(train_data['images'])
train_fig.head()
ps = np.zeros(len(train_fig))
for i in range(len(train_fig)):ps[i]=train_fig['width'][i] * train_fig['height'][i]/1e6
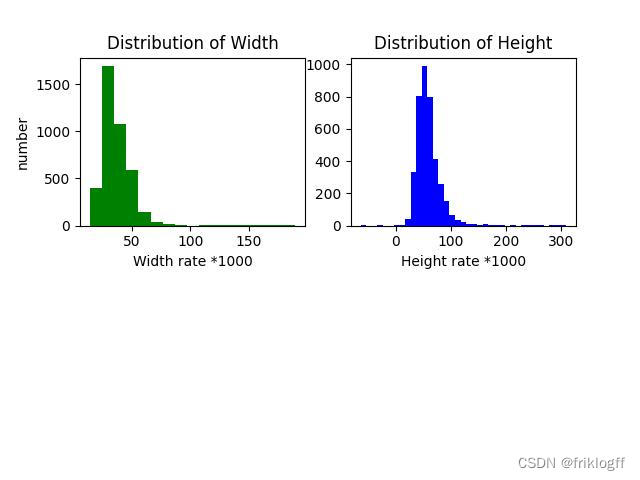
plt.title('训练集图片大小分布', fontproperties=myfont)
sns.distplot(ps, bins=21,kde=False)
# 可以看出,所有图片大小都相同,都为720*1280# 训练集目标大小分布
# !python box_distribution.py --json_path kaggle_dataset/annotations/train.json
#
#
# 注意:
#
# 当原始数据集全部有标注框的图片中,有1/2以上的图片标注框的平均宽高与原图宽高比例小于0.04时,建议进行切图训练。
# 所以根据上面的说明,海星检测这个数据集其实介于“可切可不切”之间。当然,我们可以继续试验下,看看切图是否可以取得更加优秀的效果train_anno = pd.DataFrame(train_data['annotations'])
df_train = pd.merge(left=train_fig, right=train_anno, how='inner', left_on='id', right_on='image_id')
df_train['bbox_xmin'] = df_train['bbox'].apply(lambda x: x[0])
df_train['bbox_ymin'] = df_train['bbox'].apply(lambda x: x[1])
df_train['bbox_w'] = df_train['bbox'].apply(lambda x: x[2])
df_train['bbox_h'] = df_train['bbox'].apply(lambda x: x[3])
df_train['bbox_xcenter'] = df_train['bbox'].apply(lambda x: (x[0]+0.5*x[2]))
df_train['bbox_ycenter'] = df_train['bbox'].apply(lambda x: (x[1]+0.5*x[3]))
df_train['bbox_w'].max(),df_train['bbox_h'].max()
ps = np.zeros(len(df_train))
for i in range(len(df_train)):ps[i]=df_train['area'][i]/1e6ps = np.zeros(len(df_train))
plt.title('训练集目标大小分布', fontproperties=myfont)
sns.distplot(ps, bins=21,kde=True)
# 各类别目标形状分布
# 各类别目标形状分布
sns.set(rc={'figure.figsize':(12,6)})
sns.relplot(x="bbox_w", y="bbox_h", hue="category_id", col="category_id", data=df_train[0:1000])
# 各类别目标中心点形状分布
# 各类别目标中心点形状分布
sns.set(rc={'figure.figsize':(12,6)})
sns.relplot(x="bbox_xcenter", y="bbox_ycenter", hue="category_id", col="category_id", data=df_train[0:1000]);
# 训练集目标大小统计结果
df_train.area.describe()
# 训练集目标个数分布
df_train['bbox_count'] = df_train.apply(lambda row: 1 if any(row.bbox) else 0, axis=1)
train_images_count = df_train.groupby('file_name').sum().reset_index()
plt.title('训练集目标个数分布', fontproperties=myfont)
sns.distplot(train_images_count['bbox_count'], bins=21,kde=True)
# 分析结论:海星检测的数据集图片分辨率相同,均为1280*720、小目标占比相当大。
#
# 总的来说,这是个比较典型的小目标检测场景。# 这段代码用于使用`sahi`库对训练集和验证集的标注数据进行图像切割,并生成切割后的子图像。以下是代码的功能和参数说明:
#
# 1. 安装`sahi`库:
# ```python
# !pip install sahi
# ```
#
# 2. 对训练集标注进行切图:
# ```python
# !python PaddleDetection/tools/slice_image.py --image_dir kaggle_dataset/train2017\
# --json_path kaggle_dataset/annotations/train.json --output_dir kaggle_dataset/train2017_400_sliced --slice_size 400 --overlap_ratio 0.25
# ```
#
# - `--image_dir`:原始数据集图片文件夹的路径,这里是 `kaggle_dataset/train2017`。
# - `--json_path`:COCO标注数据文件地址,这里是 `kaggle_dataset/annotations/train.json`。
# - `--output_dir`:切图结果所在文件位置,这里是 `kaggle_dataset/train2017_400_sliced`。
# - `--slice_size`:切图大小,默认为正方形,这里设置为 400x400 像素。
# - `--overlap_ratio`:切分时的子图之间的重叠率,这里设置为 0.25。
#
# 3. 对验证集标注进行切图,与训练集切图的方式类似,只是针对验证集数据:
# ```python
# !python PaddleDetection/tools/slice_image.py --image_dir kaggle_dataset/val2017\
# --json_path kaggle_dataset/annotations/valid.json --output_dir kaggle_dataset/val2017_400_sliced --slice_size 400 --overlap_ratio 0.25
# ```
#
# 这段代码的作用是将原始数据集的图像切分成指定大小的子图像,以便后续进行目标检测或其他计算机视觉任务。确保你已安装了所需的库并提供了正确的数据集路径和参数,以使代码成功运行。
# python PaddleDetection\\tools\\slice_image.py --image_dir kaggle_dataset\\train2017\\ --json_path kaggle_dataset\\annotations\\train.json --output_dir kaggle_dataset\\train2017_400_sliced --slice_size 400 --overlap_ratio 0.25
# python PaddleDetection/tools/slice_image.py --image_dir kaggle_dataset/val2017\ --json_path kaggle_dataset/annotations/valid.json --output_dir kaggle_dataset/val2017_400_sliced --slice_size 400 --overlap_ratio 0.25# pip install paddlepaddle
# pip install paddlepaddle-gpu# python PaddleDetection/tools/train.py -c configs/ppyoloe_p2_crn_l_80e_sliced_xview_400_025.yml --use_vdl=True -o worker_num=1 --eval





![[量化投资-学习笔记009]Python+TDengine从零开始搭建量化分析平台-KDJ](https://img-blog.csdnimg.cn/b3e33794423a4d36a07800969dcdd997.png#pic_center)