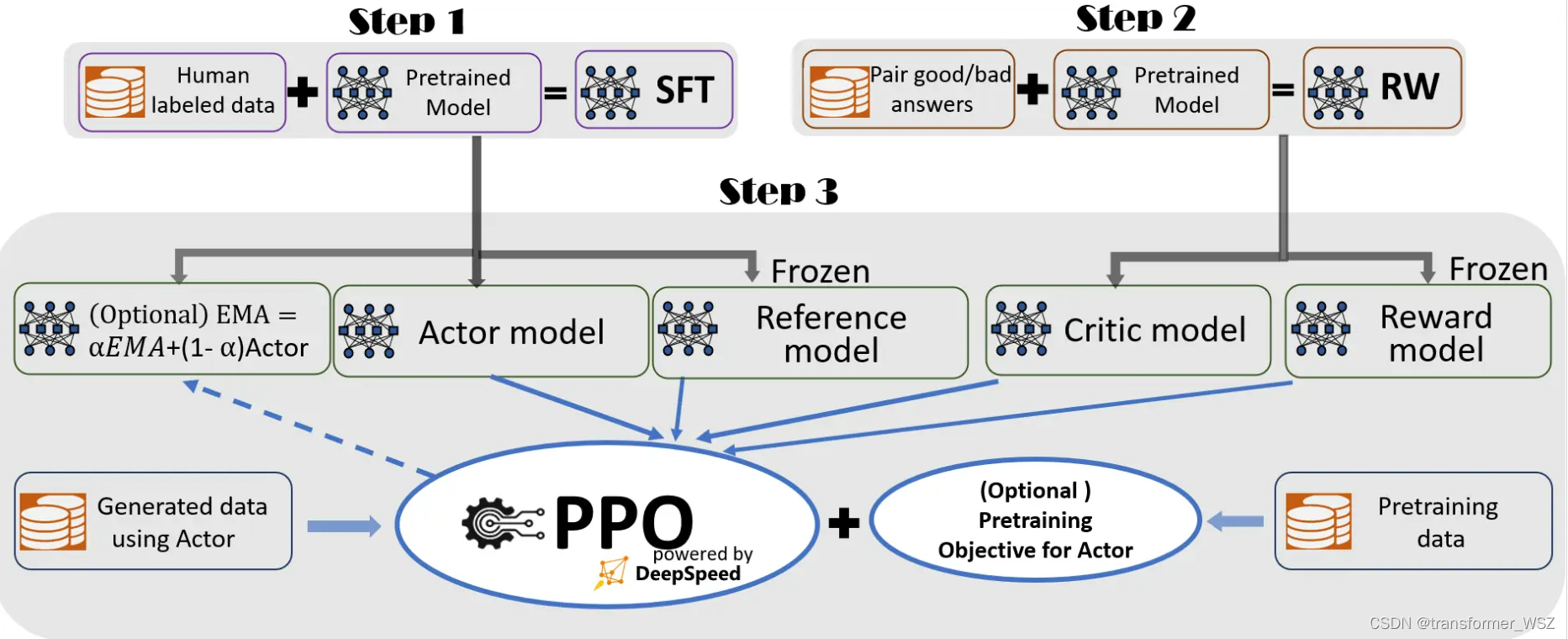
RLHF讲解
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/189663.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
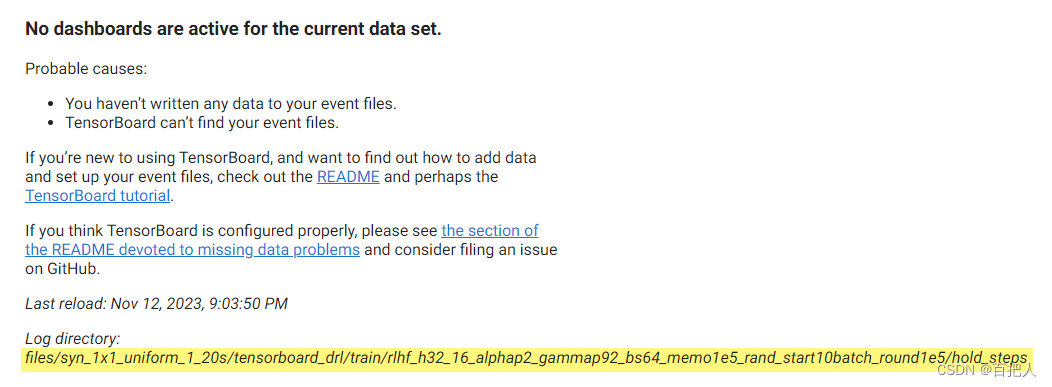
tensorboard报错解决:No dashboards are active for the current data set
版本:tensorboard 2.10.0 问题:文件夹下明明有events文件,但用tensorboard命令却无法显示。 例如: 原因:有可能是文件路径太长了,导致系统无法读取文件。在win系统中规定,目录的绝对路径不得超…
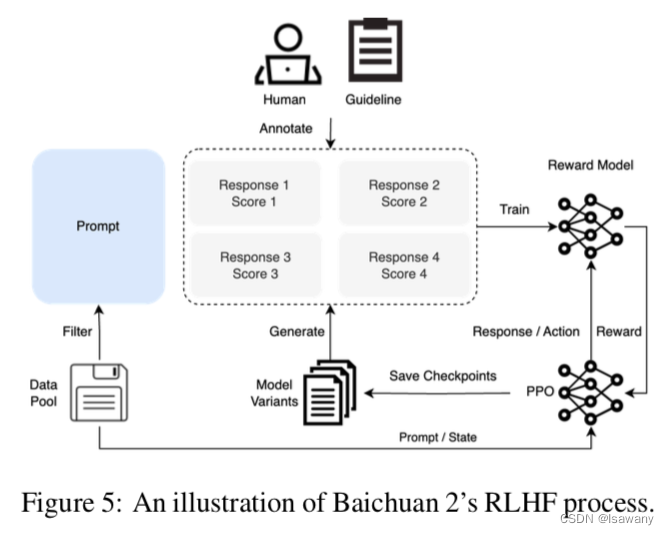
论文笔记--Baichuan 2: Open Large-scale Language Models
论文笔记--Baichuan 2: Open Large-scale Language Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练3.1.1 预训练数据3.1.2 模型架构 3.2 对齐3.2.1 SFT3.2.2 Reward Model(RM)3.2.3 PPO 3.3 安全性 4. 文章亮点5. 原文传送门 1. 文章简介
标题:Baichuan 2…
PyQt制作【小红书图片抓取】神器
文章目录 📢闲言碎语🐾窗口设计🐾功能设计📚资源领取 📢闲言碎语
最近写一个系统,被一个Bug折腾了两天,至今还未解决。由于解决Bug弄得我有点心力憔悴,于是想着写其他小项目玩玩&am…

Halcon WPF 开发学习笔记(2):Halcon导出c#脚本和WPF初步开发
文章目录 前言HalconC#教学简单说明如何二开机器视觉如何二次开发Halcon导出Halcon脚本新建WPF项目,导入Halcon脚本和Halcon命名空间 前言
我目前搜了一下我了解的机器视觉软件,有如下特点
优点缺点兼容性教学视频(B站前三播放量)OpenCV开源࿰…
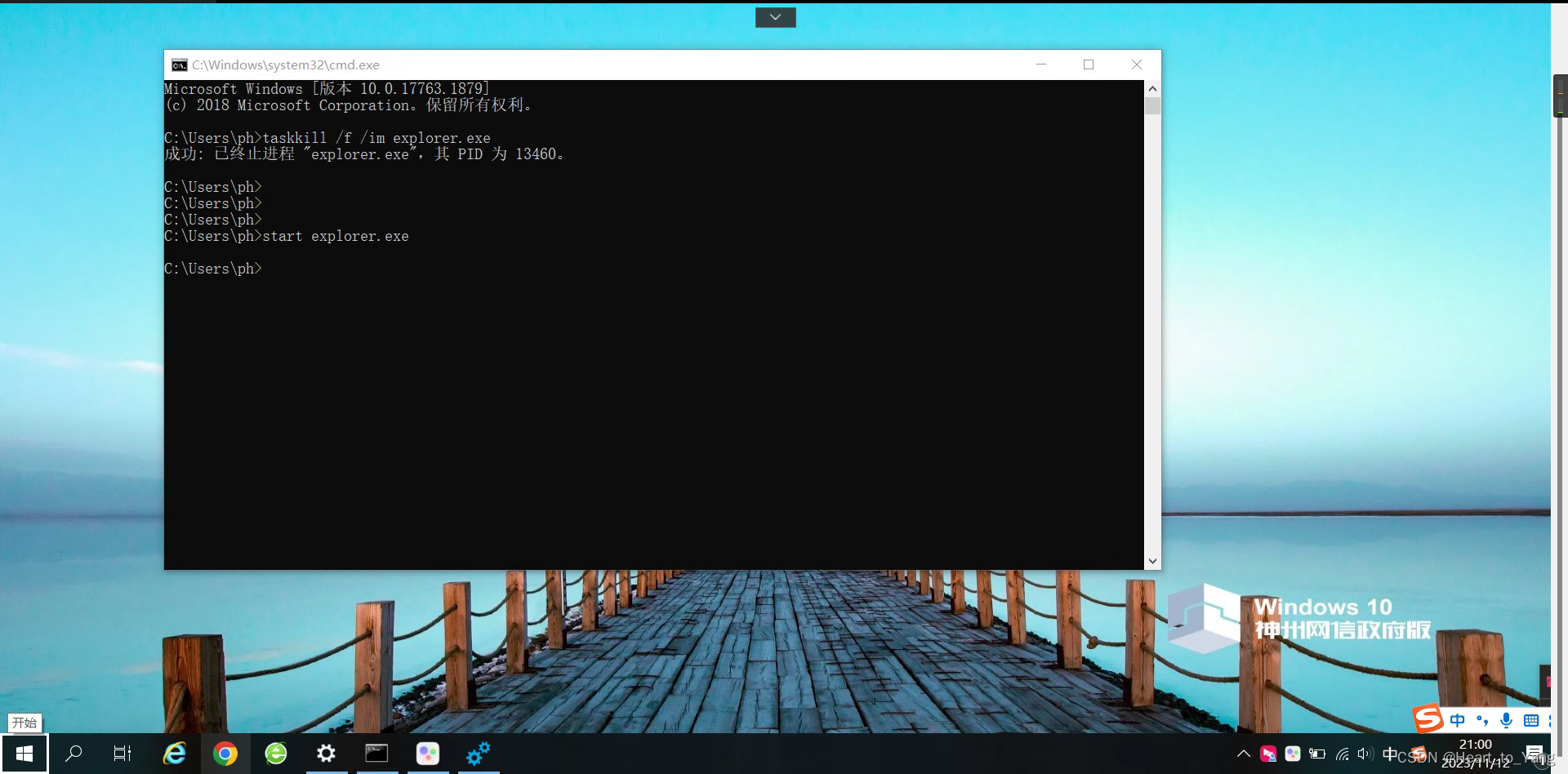
Windows桌面黑屏无法打开软件窗口不显示卡死等解决方案
问题还原 该软件窗口无论如何操作均 无法打开显示的窗口 ,但是 可使用 ALTTab 看到任务视图 目录
问题还原 解决方案 1. 使用 WinR 打开命令窗口 盲输 cmd 2. 盲输 taskkill /f /im explorer.exe 关闭资源管理器 3. 输入 start explorer.exe 启动任务管理器即可恢复正常…

TDD、BDD、ATDD以及SBE的概念和区别
在软件开发或是软件测试中会遇到以下这些词:TDD 、BDD 、ATDD以及SBE,这些词代表什么意思呢? 它们之间有什么关系吗?
TDD 、BDD 、ATDD以及SBE的基本概念
TDD:(Test Driven Development)是一种…

基于飞蛾扑火算法优化概率神经网络PNN的分类预测 - 附代码
基于飞蛾扑火算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于飞蛾扑火算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于飞蛾扑火优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神…
【C++】非类型模板参数 | array容器 | 模板特化 | 模板为什么不能分离编译
目录 一、非类型模板参数
二、array容器
三、模板特化
为什么要对模板进行特化
函数模板特化
补充一个问题
类模板特化
全特化与偏特化
全特化
偏特化
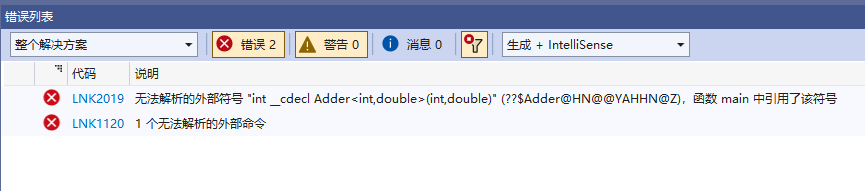
四、模板为什么不能分离编译
为什么
怎么办
五、总结模板的优缺点 一、非类型模板参数
模板参数分两类&#x…
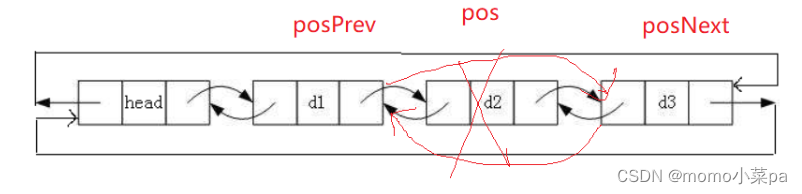
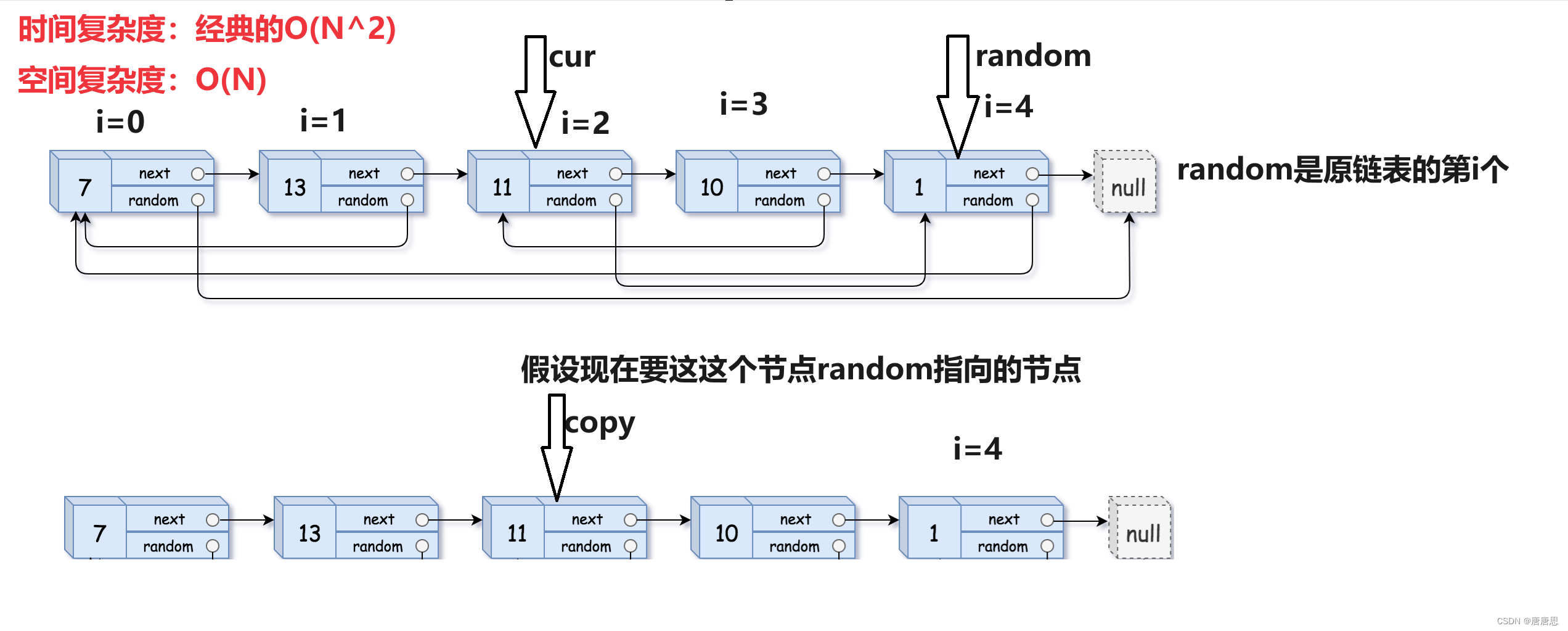
数据结构预算法--链表(单链表,双向链表)
1.链表 目录
1.链表 1.1链表的概念及结构
1.2 链表的分类
2.单链表的实现(不带哨兵位)
2.1接口函数
2.2函数的实现
3.双向链表的实现(带哨兵位)
3.1接口函数
3.2函数的实现 1.1链表的概念及结构 概念:链表是一种物理存储结…
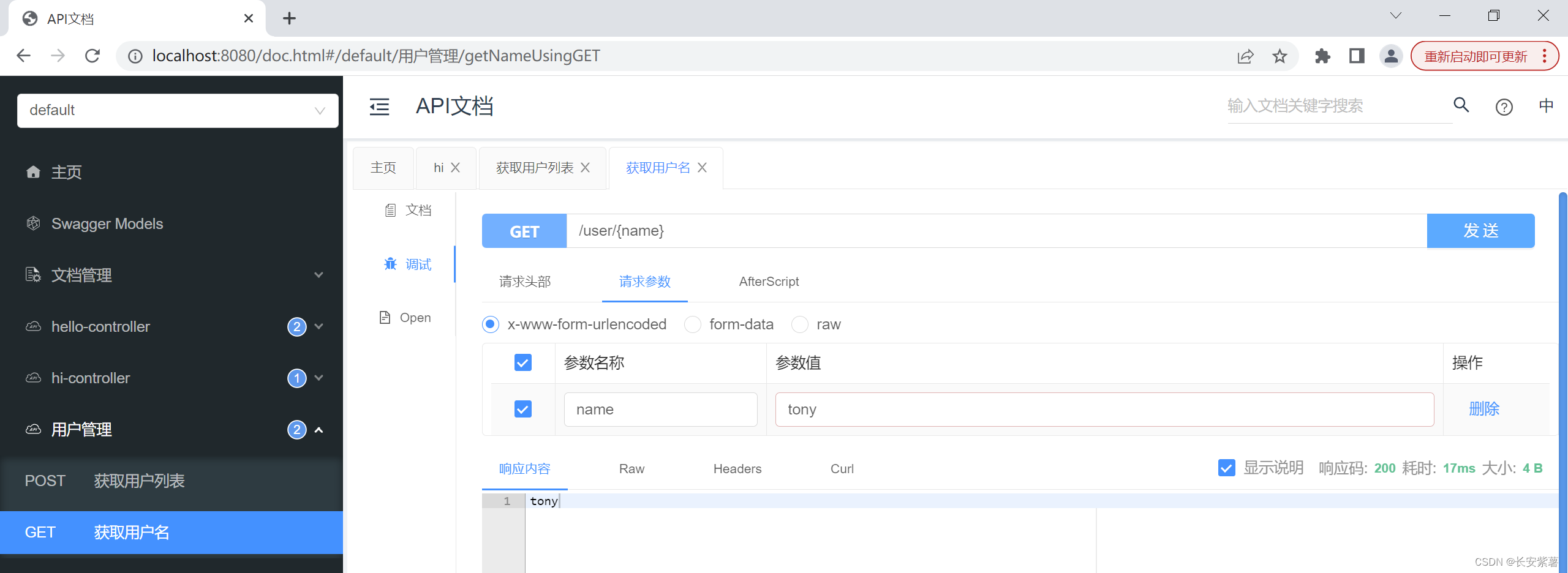
黑豹程序员-架构师学习路线图-百科:Knife4j API接口文档管理
文章目录 由来:接口文档第一代:Swagger第二代:Knife4j界面 由来:接口文档
古老编程是一个语言前后端通吃,ASP、JSP、PHP都是如此。 但随着项目规模变大,项目团队也开始壮大,岗位职责开始细分&a…
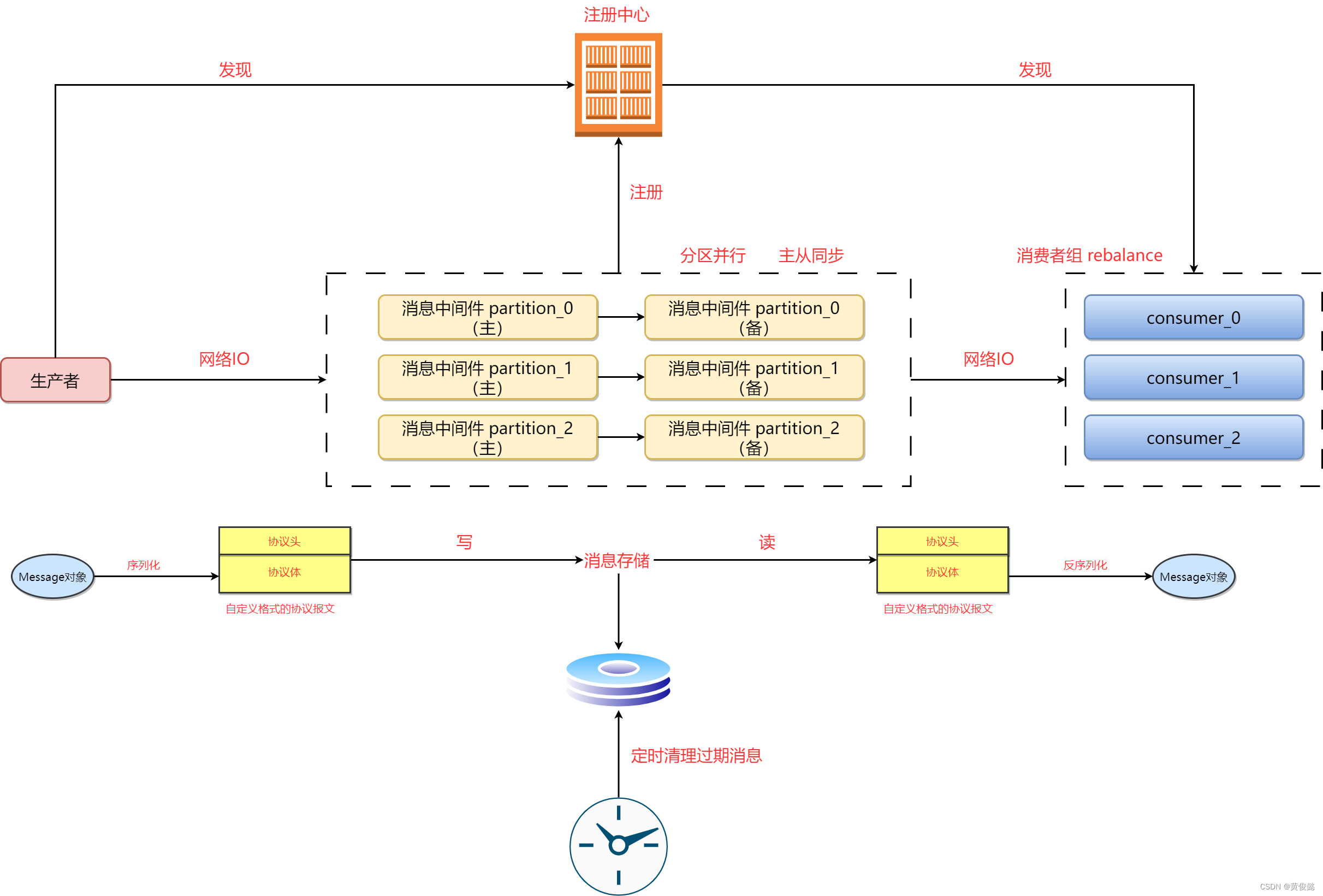
如何从零开始手写一个消息中间件(从宏观角度理解消息中间件的技术原理)
如何从零开始手写一个消息中间件(从宏观角度理解消息中间件的技术原理) 什么是消息中间件消息中间件的作用逐一拆解消息中间件的核心技术消息中间件核心技术总览IOBIONIOIO多路复用AIOIO多路复用详细分析selectpollepoll Java中的IO多路复用 协议序列化消…
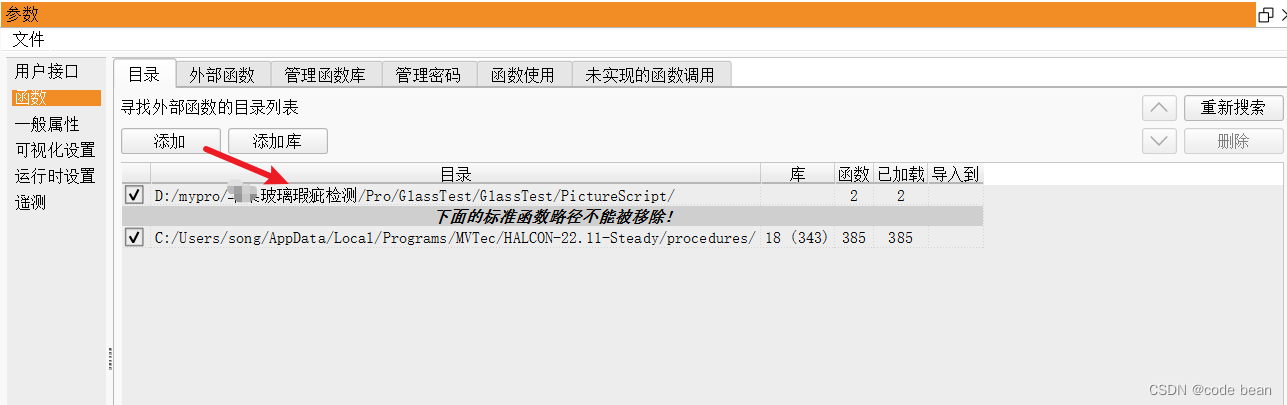
【halcon】halcon 函数文件 以及 脚本引擎如何调用外部函数文件 上篇
前言
halcon有几种文件:
本地程序函数(.hdev)外部函数文件(.hdvp)库函数(.hdp)
说多了容易混淆,今天就说,我觉得最有用的:外部函数文件(.hdvp)
步骤
先写一段halcon脚本&#x…

Nuxt.js——基于 Vue 的服务端渲染应用框架
文章目录 前言一、知识普及什么是服务端渲染什么是客户端渲染?服务端渲染与客户端渲染那个更优秀? 二、Nuxt.js的特点Nuxt.js的适用情况? 三、Vue是如何实现服务端渲染的?安装依赖使用vue安装 Nuxt使用npm install安装依赖包使用n…

C语言——打印1000年到2000年之间的闰年
闰年: 1、能被4整除不能被100整除 2、能被400整除 #define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h>
int main()
{int year;for(year 1000; year < 2000; year){if((year%4 0) && (year%100!0) || (year%400 0)){printf("%d ",ye…

vite基础学习笔记:14.路由跳转(二)携带query参数
说明:自学做的笔记和记录,如有错误请指正
1. 路由跳转(携带query参数)
(1)第一层路由(点击卡片路由跳转至新页面-携带query参数)
知识点:
query传参对应的是path和qu…
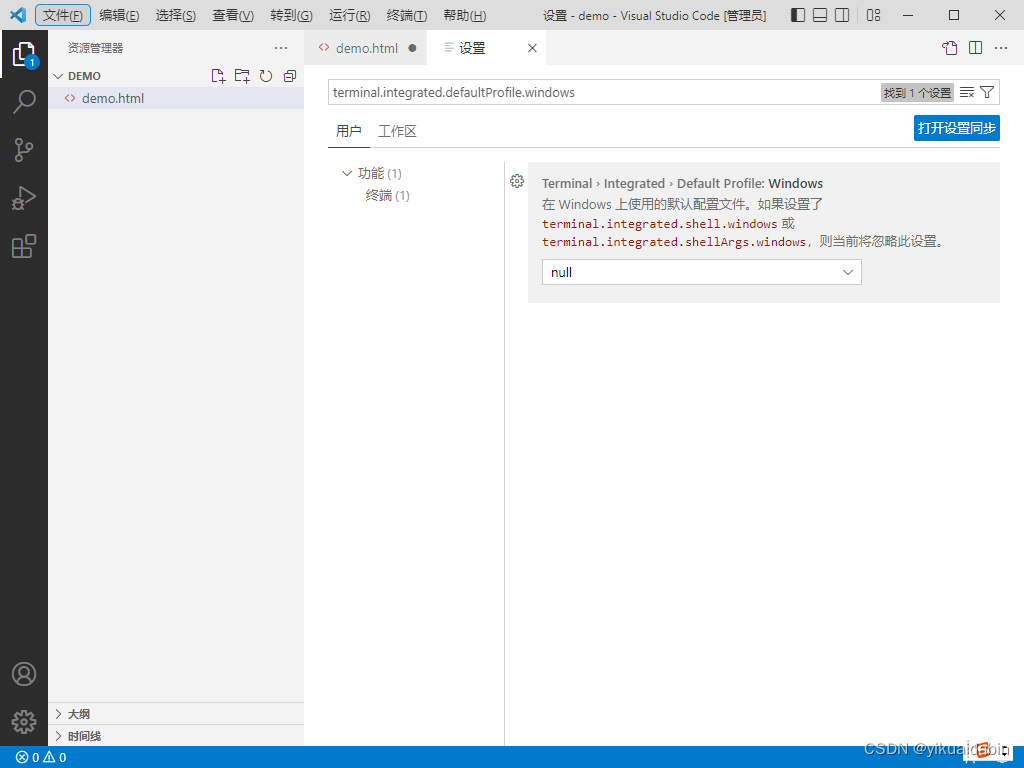
vscode 终端进程启动失败: shell 可执行文件“C:\Windows\System32\WindowsPower
vscode 终端进程启动失败: shell 可执行文件“C:\Windows\System32\WindowsPower 第一次用vscode,然后遇到这个问题,在设置里搜索
terminal.integrated.defaultProfile.windows 将这里的null改成"Command Prompt"
重启就可以了

【Git】深入了解Git及其常用命令
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Git的相关操作吧 目录
🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.Git是什么
二.SVN和Git的区别
三.Git的…
推荐文章
- - 概述 - 《设计模式(极简c++版)》
- GPT-3好“搭档”:这种方法缓解模型退化,让输出更自然
- Vue + Element UI前端篇(二):Vue + Element 案例
- 拓竹二面
- 这款「咒语」优化工具,功能有多强大?#Prompt Perfect
- 中国移动董事长杨杰:云擎未来铸重器,算启新程绘宏图
- #!/bin/sh和#!/bin/bash的区别
- #if等命令的学习
- #include “ascii_font.c“ 引入源文件,Keil5为什么没有提示重复定义错误,详解!!!
- #Uniapp:uni.request(OBJECT)
- #新版Onenet云平台使用(ESP8266 AT指令上报数据以及公网MQTT服务器连接测试)
- (39)统计位数为偶数的数字