这几天搞泰迪杯数据分析技能赛去了。等拿国奖了就出一期关于泰迪杯的。
题目
试题编号: 201703-3
试题名称: Markdown
时间限制: 1.0s
内存限制: 256.0MB
问题描述:
问题描述
Markdown 是一种很流行的轻量级标记语言(lightweight markup language),广泛用于撰写带格式的文档。例如以下这段文本就是用 Markdown 的语法写成的:
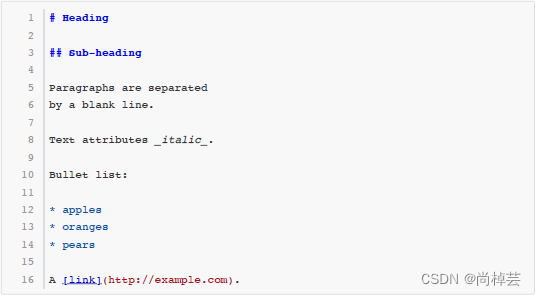
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 HTML 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:

本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入 <p>,在最后一行行末插入 </p>。
○标题:每个标题区块只有一行,由若干个 # 开头,接着一个或多个空格,然后是标题内容,直到行末。# 的个数决定了标题的等级。转换时,# Heading 转换为 <h1>Heading</h1>,## Heading 转换为 <h2>Heading</h2>,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由 * 开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行 <ul>,最后插入一行 </ul>;对于每行,* Item 转换为 <li>Item</li>。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:_Text_ 转换为 <em>Text</em>。强调不会出现嵌套,每行中 _ 的个数一定是偶数,且不会连续相邻。注意 _Text_ 的前后不一定是空格字符。
○超级链接:[Text](Link) 转换为 <a href="Link">Text</a>。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
输入格式
输入由若干行组成,表示一个用本题规定的 Markdown 语法撰写的文档。
输出格式
输出由若干行组成,表示输入的 Markdown 文档转换成产生的 HTML 代码。

提示
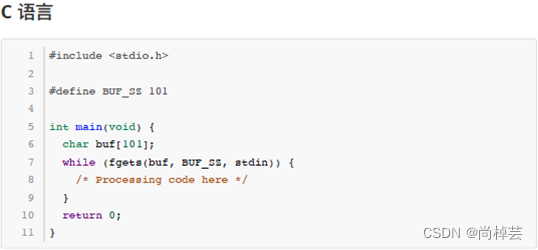
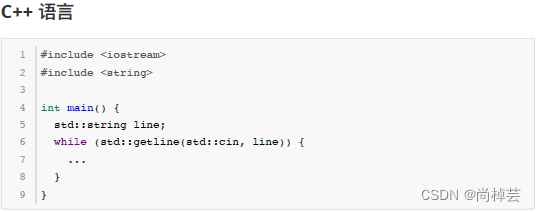
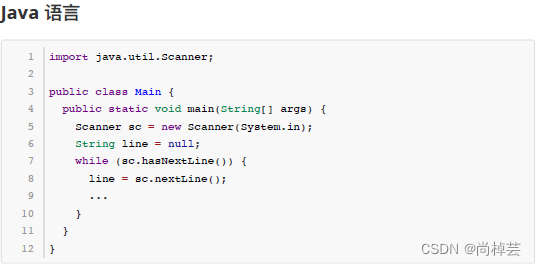
由于本题要将输入数据当做一个文本文件来处理,要逐行读取直到文件结束,C/C++、Java 语言的用户可以参考以下代码片段来读取输入内容。
题目分析(个人理解)
- 题目定义的规则分为区块和行内两个部分,对于输入的字符串,具体处理步骤为输入一行,处理一行,在整个区块输入结束或整个输入结束后才输出一个区块的转换结果。
- 第一步,先处理行内,行内若包含强调和超级链接,则按照题目中的规则转换强调和超级链接。
- 第二步,处理区块儿区块一共有三种,包括‘#’开头的标题,‘*’号开头的无序列表和段落,一个区块可能有多行,所以在每次处理一行时都要判断此行是否是区块的第一行以便添加,不同的格式。
- 关于输出:空行和输入结束标志着区块的结束可以输出结果了,在区块结束或整个输入结束才输出整个区块,代码中用preline保存每一个区块的前面的输入,每次处理一行时都可以根据preline判断这个区块的类型,以便输出对应的格式字符串,例如,若preline包含< ul >说明这是一个无序列表,输出的时候在最后补上\n</ ul >
- 更更更具体的步骤:对于输入,利用sys库标准输入,对每一行判断,到底是区块还是行内;如果是区块,判断是区块的具体的哪三个,如果是‘#’开头的标题,统计是几级标题(利用count函数),利用.split()方法以#切片,按照要求格式拼接即可。如果是 ‘* ’开头,此时有一个问题,鬼知道是不是第一行,如果是第一行则先加ul,再按照要求切片拼接字符串即可,用list_tag标记,设置默认值为Flase如果是第一行,加入ul后设置list_tag=True。 如果是是段落,还需判断是不是段落的第一行,同理于*开头的,我就不多赘述了。
- 行内处理好后存入一个temp[]空间,然后开始处理行内,注意:超链接和强调可以相互嵌套,使用while循环如果存在‘ _ ’就一直判断,先处理强调,强调不会出现套娃的现象,所以,只需要知道哪一段强调即可,首先用i去标记是‘_’是第几次出现,如果是第一次i=1则是强调开始的标志,第二次i=2,是结束的标志,然后按照强调的字符串的开始和结尾要求对字符串操作即可。
- 再处理超链接的情况,超链接也不会嵌套超链接,还是用while判断是否存在‘[’,存在则有超链接,超链接的题目要求就是里面Test的情况多一些,本质还是字符串的处理,还是用字符串的切片和拼接(用烂了都,人都麻了)
- 最后判断是段落结束还是无序列表结束,分别追加相应的标识即可。
- 上代码!!!
import sys
data=[]#记录转换好的文档
flag=False#标记段落是否是多行
list_tag=False#标记无序列表是否是多行
for line in sys.stdin:#利用sys库标准输入,line表示键盘输入的每行内容
#区块line=line.strip()#利用strip()方法去字符串头尾的空格if '#' in line:#标题count=line.count('#')temp=line.split('#')[-1].strip()#不要用空格分割,万一题目标题有空格呢temp="<h"+str(count)+">"+temp+"</h"+str(count)+">"elif '*' in line:#如果是无序列表if list_tag==False:data.append("<ul>")list_tag=Truetemp=line.split("*")[-1].strip()#用*分割temp="<li>"+temp+"</li>"else:#段落if line and flag==False:#首次出现的段落temp="<p>"+lineflag=True#重标记elif line and flag==True:#中间出现的段落temp=lineelif line=="" and flag==True:#段落结束,修改最后一个元素(加上</p>)data[-1]=data[-1]+"</p>"flag=Falsetemp=""elif line=='' and list_tag==True:#无序列表结束data.append("</ul>")temp=""list_tag=Falseelse:#回到初始状态temp=''flag=Falselist_tag=False
#行内,强调i=1#标记’_'是第一个还是第二个while '_' in temp:#强调可能有多个,可能有无限个所以用whileindex_1=temp.find('_')#使用find()函数返回第一个’_‘索引if i==1:#第一次出现temp=temp[:index_1]+'<em>'+temp[index_1+1:]#切片,拼接操作i=2else:#第二次出现(一对’_‘完成)temp=temp[:index_1]+'</em>'+temp[index_1+1:]i=1
#超链接while '[' in temp:#超链接可能有多个,可能有无限个所以用whilei1=temp.find('[')i2=temp.find(']',i1+1)#从i1+1位置开始王后找']'i3=temp.find('(',i2+1)i4=temp.find(')',i3+1)temp=temp[:i1]+'<a href="'+temp[(i3+1):i4]+'">'+temp[(i1+1):i2]+"</a>"+temp[(i4+1):]#按照格式切片拼接即可data.append(temp)#转换好的追加写入data[]即可
if flag==True:#当以段落结束时data[-1]=data[-1]+'</p>'
if list_tag==True:#当以无序列表结束时data.append("</ul>")
for d in data:#按输出格式输出(没有空行)if d=='':continueprint(d)
总结