这两天,AI圈都处在一种莫名的震撼感当中。
北京时间 11月7日,OpenAI 举办了首次DevDay开发者日活动。活动现场发布了非常多内容,其中有一些按部就班的,比如技术上更新了最新版本的GPT-4 Turbo。也有一些让从业者目瞪口呆,不知道从何聊起的,比如能够让用户仅用几句话就生成独立应用的GPTs,以及配套推出的GPT Store。
出人意料的地方在于,OpenAI这些动作完全是非技术的。你可以说这是一种应用模式,一种开发工具,或者一种编程语言,反正它跟我们经常在AI发布会上看到的模型能力升级一点关系都没有。
这种感觉就是,我们明明都跟着你往北跑,甚至跑出了“百模大战”的气势,结果一觉醒来,你宣布向西拐了,于是结结实实让AI行业闪了一下腰。
那可能有朋友说了,这不是正好吗?反正国内大模型这么卷,OpenAI给出了新方向,我们继续跟着跑就是了。
然而现实情况是OpenAI的一系列新动作,完全建立在一套新的游戏规则体系上。这种能力是绝大多数AI算法公司并不具备的。
提起iPhone,我们会说它不一定是技术最强、生态最强,但肯定是产品最强。OpenAI在做的其实就是基于一套全新的“GPT游戏规则”,来实现大模型的产品化。
我们认为,这对于今天“百模大战”的绝大多数参与者来说都是坏事,但对于中国AI的长期发展来说却是好事。
OpenAI在做的
是将“新规则”产品化

我们首先还是来回顾一下OpenAI的开发者日,到底是如何又一次带来行业震撼的。
本次活动,OpenAI首先是对GPT-4进行了一定升级,比如此次GPT-4 Turbo更新了长度达到128k的上下文窗口,是此前GPT-4的四倍。与此同时,也进行了其他一些关于AIGC压缩成本,提高效率方面的升级。而在开发者赋能方面,OpenAI带来了Assistants API等新升级,从而帮助开发者在自身应用中构筑Agent体验。
真正引人注目的,是可以快速构建自定义AI应用的GPTs。
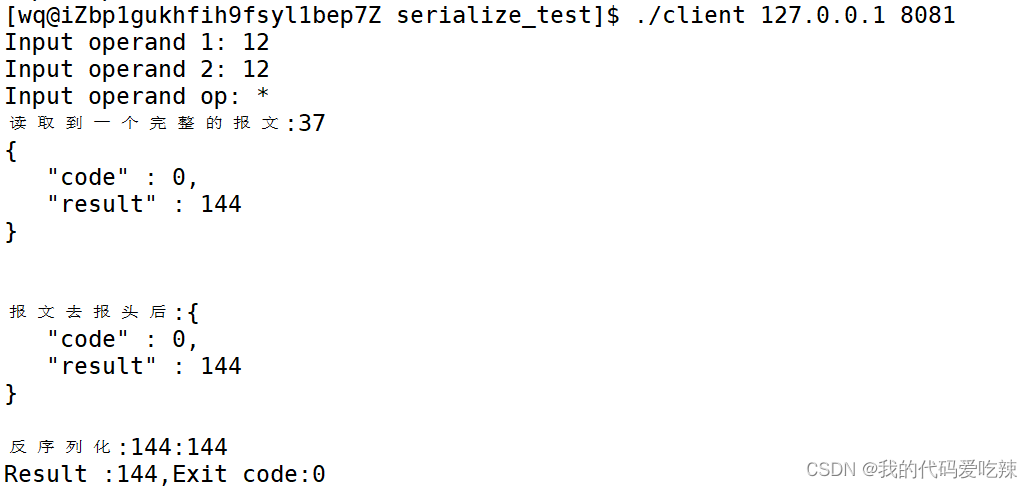
这一平台可以支持用户通过提需求的方式,仅仅用几句话就生成一个独立的GPT应用,也就是GPTs。在现场演示中,OpenAI创始人奥特曼使用GPTs定制了一个商业建议类的应用:
首先,他向GPT提出自己的诉求是构建一个创业公司的帮手,可以为公司创始人提供相应的商业建议。
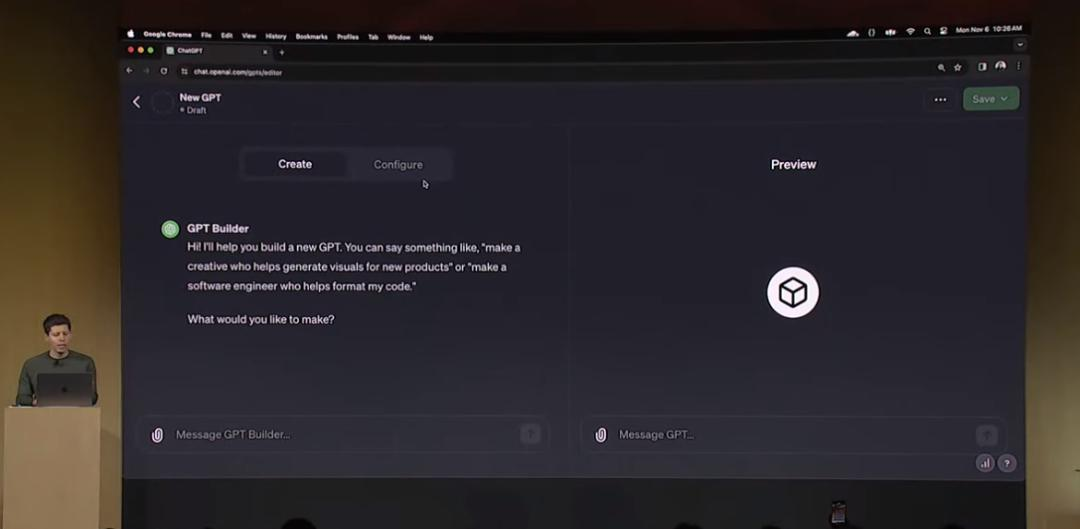
第二步,GPT Builder输出了初步的GPTs,并询问是否需要进行更多信息输入,有哪些重点强调的内容和需要避免的问题。
第三步,GPT Builder会询问应用是否联网,是否应该具备以文生图能力、代码生成能力等GPT的基础能力,以及是否需要加入专业数据进行精调。
经过这三轮与GPT Builder的对话之后,一个GPTs就生成完毕。换句话说,在这个应用开发过程中,人类没有贡献任何的代码能力、逻辑能力、设计能力,只提供了一个idea,最多再加上少量行业数据。
GPTs发布之后,很快众多开发者都把它玩出花,不难由此看出其潜力广泛。当然,我们可以说这种开发模式有很多问题,比如其能力上限就是当前版本GPT的上限,它应用到的能力也仅仅是目前GPT具有的能力,极大收窄了应用开发边界。但不可否认的是,GPTs颠覆了有史以来的应用历程。开发者不再需要软硬件成本、开发工具、开源软件集,甚至可以不懂代码,不耗费时间。就像iPhone之前,用户从不会距离订制化软件这么近,而GPTs之前,可能也不会有开发者距离订制化软件这么近。这种模式确立之后,GPT本身的技术升级,会通过GPTs得到快速释放。
当创建应用像拍短视频一样简单,一系列产业洗牌与商业模式兴起已经可以预见,而为了配合这种极简开发模式,OpenAI也将打造类似应用市场的GPT Store。
过去我们说,智能手机本身就是产品,同时还是更多软件类产品诞生的基础。如今OpenAI在做的事情也是一样,它让ChatGPT本身成为不断迭代的超级产品,同时也将其能力外放,打造新的软件基础设施。
在由大模型定义的全新技术规则下,GPT的产品化脱离了以往所有软件的范式,走出了一条新路。
这条路上,未来可能会出现这样一幕:一个不会编程的孩子,仅用几句话就完成了一家企业耗费巨大人力物力打造的应用。那么大公司里的员工要做什么呢?他们为什么不提前利用新规则呢?
这些问题其实在ChatGPT开始兴起时就被提了触雷,而OpenAI在做的,就是通过将大模型的新游戏规则产品化,来让这些问题更加真实可感。
大战中的“百模”
能否跟上GPT?
让我们把OpenAI的故事先放一放,他们的野心显然还在发酵,按照这个节奏,几个月之内应该还会有更炸裂的发布。
这时候,要来看看中国与全球同步上演的“百模大战”到今年10月,国内已经涌现出了超过130个大模型。大模型开源、大模型进入垂直行业,以及基于大模型打造的新应用模式等一系列产业端口都非常火爆。
这种繁荣经常会给我们某种错觉:有了130个大模型,好像就是拥有了130家OpenAI。
事实绝非如此,在这些大模型当中,能做到“对外开放”“对话流畅自然”“能够提供有效内容反馈”这几点的大语言模型已经寥寥无几。
大模型企业,更多动作还集中在提升参数、刷新榜单、开源等传统意义上的AI算法层面,既无法大规模应用,也无法实现商业闭环。那么问题来了,在OpenAI转向大模型产品化的新阶段里,百模大战的参数选手们能在未来跟进吗?

恐怕对于多数大模型来说,答案是比较悲观的,其原因有三点:
1.大模型泛化能力的缺失。预训练大模型技术最大的亮点就是其泛化应用能力,这是“智能涌现”现象的来源,也是OpenAI可以实现无代码开发、软件能力订制的来源。然而恰恰也就是这种难以准确量化的泛化能力,是众多大模型最为缺失的能力。“一看数值是高知,一上应用是弱智”目前是困扰大模型产业的最大问题。在技术上,绝大多数大模型还不具备拥抱“新规则”的基础。
2.产品化能力的缺失。目前大多数大模型玩家,都是大模型风口下的创业团队,以及院校搭建的科研类大模型。换言之,这些团队普遍呈现技术能力比较强,但压根没考虑过产品能力的问题。未来想要从头复刻OpenAI的大模型产品化体系,是一件极其艰难的工作。
3.生态成本与窗口的缺失。从头打造大模型相对容易,但要从头类似OpenAI的开发者生态却很难。这一方面是需要持续且巨大的成本投入,另一方面需要抢占开发者聚合的机遇窗口。这两点,目前还在“百模大战”同质化竞争中的企业很难实现。
所以,从这些角度看,OpenAI这一个急转弯,确实会将全球大多数梦想成为其对手的公司甩出路外。其实就创业土壤来看,今天的大模型初创企业,面临的挑战比几年前的机器视觉公司更大。当时机器视觉公司还有安防等庞大蓝海市场作为支撑,但现在大模型公司是外有OpenAI遥遥领先,内有互联网与AI巨头强敌环伺。在打榜和对参数之外,大模型的出路何在,已经是一道眼前的必答题。
中国大模型的出路
是打造“新超级入口”
那么,OpenAI的大拐弯,真的会让中国AI产业看不见未来吗?答案当然不是这样,甚至刚好相反。
在目前阶段,GPT确实保持着极高的技术、产品、生态进化速度。中国AI行业更多处在模仿、跟随,同时渐渐积累自身优势的阶段。但客观来看,大模型带来了全新的智能化游戏规则,同时这个规则未来高度依赖产品能力、应用能力,这件事对中国AI行业是极为有利的。
首先,客观来看GPT是进不来的。无论如何评价这一点,这都会给中国大模型造成可观的空间。这个阶段,OpenAI还会源源不断的提供参考范本,完成从0到1的工作,这就将给中国AI产业造成既有参考,又有空间的机会窗口。

其次,中国互联网行业、手机行业等领域积累了庞大的产品设计、应用开发基础。这些基础能力除了少数科技巨头之外,更多时候还没有与大模型接驳。实事求是地说,基础模型并不需要太多。最终“百模大战”会有超过90%的选手仅仅成为时代的痕迹,但基础模型与基础平台之上的应用可以很多,甚至可能出现一个应用开创一个行业的情况。而这些,都是中国互联网与软件行业所擅长的。
对于中国AI,以及行业的从业者、开发者来说,应该看到只有将大模型基础技术与中国的产品能力、商业能力、规模化市场结合在一起才有未来。中国大模型的真正出路,是基于大模型的新游戏规则,打造出类似微信、支付宝、抖音的超级入口。
否则的话,中国厂商将一直挤在行业+大模型的赛道里。这个赛道当然有意义,但缺乏规模化营收,商业逻辑难以大量复制。
真正值得期待的大模型创业潮,应该发生在中国AI进一步模仿GPT,完善与其对标的技术和平台能力之后。然后在这一基础上,在大模型的新游戏规则下,产生出融合了中国特色应用开发能力、C端市场需求的软件应用。
多重优势合流之后的超级入口成型之日,才是中国大模型的指数级增长之时。
那个超级入口有很多种可能。一位帮你找信息、完成工作的数字秘书?一个能够支持用户定制多媒体娱乐的平台?一个可以根据用户指令来比价、比店、选品的“AI李佳奇”?一个虚拟群主带大伙社交的“新QQ”?

有太多可能,发生在新规则确立之后,发生必须稍有耐心的未来。
2022年11月30日发布,ChatGPT悄无声息地发布。一年之后的今天,大模型层出不穷,有太多公司宣布“要当中国的OpenAI”。同样是今天,OpenAI已经开启了变革,转向了一个意料之外,情理之中的新方向。
那么问题来了,下一年我们做什么呢?
或许面对OpenAI,中国AI企业必须学会既要学习,又不能复制。
我们压低身段去学习OpenAI。需要学习的是有能力持续推动大模型技术迭代,同时具备把大模型作为一种全新数字化基础设施的思考方式。
但不能真的像OpenAI,因为你用尽全力学像了这个版本,人家下一步拐弯了,而你撞墙上了。这就像看人家汽车起步你也起步,可是你仿造的这辆车压根就没装方向盘。
对于这次的开发者日,OpenAI联合创始人安德烈·卡尔帕西说,“我看到了计算机中的一个新的抽象层”。
这一点,或许才是最重要的。