从大语言模型到表征再到知识图谱
- InstructGLM
- LLM如何学习拓扑?
- 构建InstructGLM
- 泛化InstructGLM
- 补充
- 参考资料
2023年8月14日,张永峰等人的论文《Natural Language is All a Graph Needs》登上arXiv街头,轰动一时!本论文概述了一个名为
InstructGLM的模型,该模型进一步证明了
图表示学习的未来包括大型语言模型(LLM)和图神经网络(GNN)。它描述了一种单独使用指令调整来teach语言模型文本属性图(text-attributed graph, TAG)的结构和语义的方法。经过指令微调的
Flan-T5和
Llama-7b能够在多个基准上实现引用
图的节点分类和链接预测任务的最先进性能:
obgn-arxiv、
CoRa和
PubMed。图的结构结合节点的特点用通俗易懂的英语描述。在这两项任务中都使用了许多提示。

InstructGLM
Natural Language is all a Graph Needs的作者描述了一个名为InstructGLM的模型,与GPT4Graph(使用图文件格式而非计划语言进行微调)等最近的努力相比,该模型开拓了新的领域,证明可以通过对引文图的结构[可选]及其特征的描述来指导对LLM(如谷歌的Flan-T5)进行微调,以训练其通过提示工程执行图机器学习任务,如节点分类和链接预测。
可以在下面看到使用的各种提示。主要的训练任务是节点分类,但作为多任务多提示指令调整的一部分,链接预测任务对其进行了扩展。任务有多种形式:只有结构,只有功能,两者都有,有或没有边列表和结构描述,在过度平滑成为问题之前,可以扩展多达三跳(three hops)。
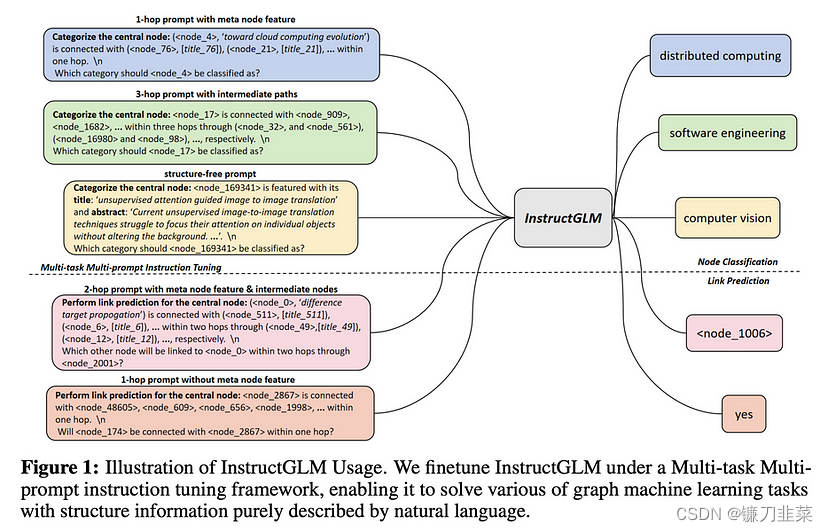
InstructGLM使用多任务学习应用于大型语言模型(LLM)的指令微调

InstructionGLM的体系结构。唯一的“trick”是为节点ID使用特殊的令牌。否则,它只会向LLama或Flan-T5解释如何进行图形机器学习……
InstructGLM不需要GNN就可以实现最先进的性能,对引文网络中的节点进行分类并预测引文,这真的很酷。文本属性图(Text Attributed Graphs , TAG)是编码文本构成节点特征的图。该模型的一个方面是,除了简单的指令微调之外,它还扩展了LLM的词汇表,为每个唯一的节点创建了一个新的令牌。在考虑结果时,请记住他们在OGB基准测试中使用的节点特征是稀疏的:Bag-of-Words(BoW)或TF-IDF。正确的节点特征编码可以显著提高性能。
LLM如何学习拓扑?
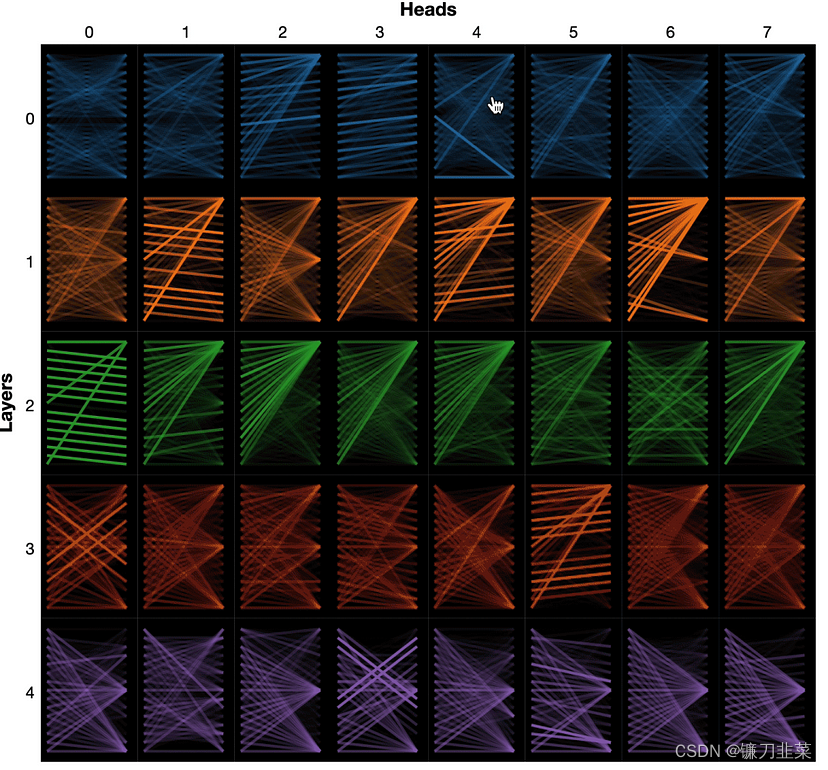
个人觉得一个大型语言模型能够推理拓扑结构是令人惊讶的!图邻接列表或遍历由矩阵表示,Tranformer架构中的注意力头也是如此。也许Transformer能够以这种方式推理并不奇怪。这个Stack Exchange的回答是“……注意力矩阵是对称的,自然地具有加权邻接矩阵的形式。”DGL文档将Transformers建模为GNNs,可以在下图中看到Jesse Vig的jessevig/bertviz Github project(colab)中的注意力头表示为一组多重矩阵。
LLM学习网络拓扑是否类似于Transformer学习其注意力头中的权重?想想很有趣,很想看到一个可视化!以LLM和知识图谱领域目前的发展速度,我们可能不需要等待太久.
构建InstructGLM
论文中没有代码,但作者确实发布了他们用来微调Alpaca和Flan-T5的prompts。它们将以Python格式出现在GitHub Repo的下一篇文章(正在进行中)中。这使得该论文相对容易以粗略的形式复制。该论文暗示了该方法的广泛潜力,以及如何通过改进节点特征来提高性能,节点特征是像Bag of Words或TF-IDF这样的稀疏特征。我希望句子编码将比这些稀疏表示更强大。

泛化InstructGLM
在第三篇文章中,我将把InstructionGLM扩展到引用图之外的数据集。我感兴趣的几个异构网络具有复杂的、半结构化的节点特征数据。在阅读这篇论文时,我想起了我们在创业公司Deep Discovery时使用的一种对复杂节点功能进行编码的方法。它来自Megadon实验室的一个名为Ditto的实体匹配模型。Ditto[和Ditto Light]在2020年的一篇具有里程碑意义的论文《Deep Entity Matching with Pre-Trained Language Models》中进行了描述。它提供了一种相当通用的机制来对半结构化记录进行编码,以使用sentence transformer对其进行语句编码,从而实现实体匹配。


我想知道我是否可以像InstructGLM论文的作者那样,通过句子转换器使用交叉编码器(cross encoder via sentence transformer)来提高BoW/TF-IDF的性能,生成节点嵌入作为特殊节点token的特征。我希望这将使我能够将该方法应用于引文图之外的网络,例如我在实体和身份解析、财务合规、商业图和网络安全领域处理的网络。
补充
SentenceTransformers是一个Python框架,用于state-of-the-art的句子、文本和图像嵌入。在我们的论文《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》中描述了最初的工作。
Reimers N, Gurevych I. Sentence-bert: Sentence embeddings using siamese bert-networks[J]. arXiv preprint arXiv:1908.10084, 2019.

您可以使用此框架来计算100多种语言的句子/文本嵌入。然后可以将这些嵌入与余弦相似性进行比较,以找到具有相似含义的句子。这对于语义-文本相似、语义搜索或转述挖掘非常有用。
该框架基于PyTorch和Transformers,提供了大量针对各种任务调整的预训练模型。此外,微调自己的模型也很容易。
参考资料
- Natural Language is All a Graph Needs
- Flan-T5
- Scaling Instruction-Finetuned Language Models
- LLaMA: Open and Efficient Foundation Language Models
- llm-graph-ai
- GPT4Graph: Can Large Language Models Understand Graph Structured Data ? An Empirical Evaluation and Benchmarking
- Cross-Encoders