文章目录
- 场景
- 配置:
- 概念及原理:
- 代码:
- 思考:
本文中,demo案例涉及场景为sharding jdbc的分库情况。
通俗点说就是由原来的db0_table水平拆分为 db1 t_table ,db2.t_table。
demo本身很简单,难点在于分片策略配置到底该怎么写,以及引发一些延伸的思考。代码是复制粘贴的事,思维是决定一个人上下限的事。
不同版本之间的分片配置写法可能有差异,虽然短短几行配置 博主也是花了点时间才配好,还是那句话 不声明版本的教程都是耍流氓,本文以springboot 2.5.x 和 sharding-jdbc 4.0.x 为例。
场景
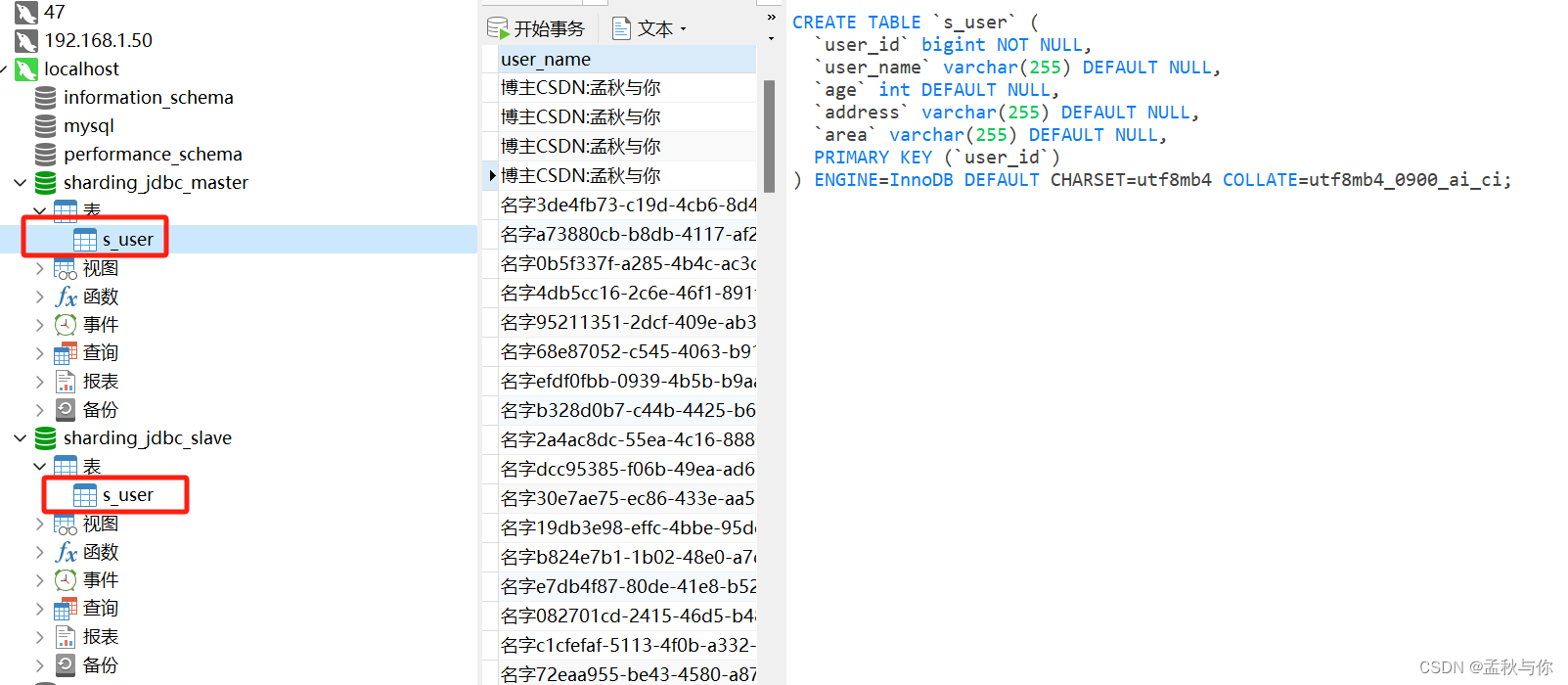
我们模拟的场景:主从库都有一张表结构相同的 s_user表,当ID为偶数时数据存放放在master库 ,当ID为奇数时 数据存放在slave库
配置:
yml配置:配置解释在注释写的比较详细了 这里不再重复
(手动敲非常容易出错,直接复制下面模板是真的很爽)
spring:port: 6666main:allow-bean-definition-overriding: trueshardingsphere:datasource:
# ds:
# maxPoolSize: 100# master-ds1数据库连接信息ds1:driver-class-name: com.mysql.cj.jdbc.DrivermaxPoolSize: 100minPoolSize: 5password: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/sharding_jdbc_master?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghaiusername: root# slave-ds2数据库连接信息ds2:driver-class-name: com.mysql.cj.jdbc.DrivermaxPoolSize: 100minPoolSize: 5password: roottype: com.alibaba.druid.pool.DruidDataSourceurl: jdbc:mysql://localhost:3306/sharding_jdbc_slave?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghaiusername: root# 配置数据源names: ds1,ds2# masterslave:
# # 配置slave节点的负载均衡均衡策略,采用轮询机制
# load-balance-algorithm-type: round_robin
# # 配置主库master,负责数据的写入
# master-data-source-name: ds1
# # 配置主从名称
# name: ms
# # 配置从库slave节点
# slave-data-source-names: ds2
## 显示sqlprops:sql:show: truesharding:
# # 配置默认数据源ds1 默认数据源,主要用于写
# default-data-source-name: ds1# 表策略配置tables:# 逻辑表s_user:keyGenerator:column: user_idtype: SNOWFLAKE# 分表节点 可以理解为分表后的那些表#由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,#支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。#用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况# 1..2 表示从1到2 和我们上面定义的ds1 ds2对应actualDataNodes: ds$->{1..2}.s_user# 分库策略 注意和tables节点是同一层级default-database-strategy:inline:# 根据哪列分库sharding-column: user_id# 分库算法:取模 (+1 是因为 ds从1开始的 如果是ds0开始 则为 user_id % 2)algorithm-expression: ds$->{user_id % 2+1}
#logging:
# level:
# root: debug概念及原理:
这里补充一些概念:
-
分片算法: 例如取模(%),范围(比如1-10W 10W-20W),日期(比如按月、日),哈希等,
-
虽然是对真实表(分表后的每张表)进行操作;但我们sql语句只需要操作逻辑表(未拆分前的表 其实已经不是真实存在的)
-
sharding jdbc 会根据分片算法 拆分SQL
例如拆分键为user_id 原语句为
select * from user where id <200000
分片算法按照范围(1-10W 10W-20W)时
会拆分SQL:
select * from user where id < 100000select * from user where id >=100000 and id < 200000
并在内存中 经过了归并算法后组装结果 -
sharding jdbc是驱动层 可以理解为 jdbc plus
(对jdbc的拓展 重写了 connection,prestatement/statement,resultset (shardingConnection,shardingResultSet等类) ) -
与mycat 不同的是 ,mycat是代理层,比如sharding jdbc只适合Java环境 而代理层可以在不同语言使用, mycat需要额外部署,既然涉及到部署组件 就要考虑高可用问题(集群)
-
分页原理: 为了保证分页准确性 会将当前为止的所有数据都查出来 再进行归并组装。
说通俗点,中间件分库分表就是通过一些算法 将我们的sql进行拆分,查询或更改改不同库表的数据; 博主认为 分页查询时的归并结果 帮助我们解决了很多算法难点 自己写太容易出错了。
代码:
配置好了之后,我们的代码很简单:
package com.qiuhuanhen.shardingjdbcdemo.controller;import cn.hutool.core.lang.UUID;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.qiuhuanhen.shardingjdbcdemo.entity.DO.UserDO;
import com.qiuhuanhen.shardingjdbcdemo.mapper.UserMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.PostConstruct;
import java.util.List;
import java.util.Random;@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {@Autowiredprivate UserMapper userMapper;@PostMappingpublic void addUser() {for (int i = 0; i < 100; i++) {UserDO userDO = new UserDO();// userId在yml的sharidng配置下面指定了雪花算法userDO.setUserName("名字"+UUID.fastUUID().toString());userDO.setAddress("地址");userDO.setAge(new Random().nextInt());userDO.setArea("区域");userMapper.insert(userDO);}}/*** 分页查询: 多数据源会将数据分页范围内的数据全部查出 组合后再排序 确保分页正确性* (sharding jdbc做了归并处理 并不会将结果全存放在内存)** 另外原生ResultSet里面有个fetchSize属性,是分批获取的意思(知识点补充 与本demo无关)* @return*/@PostConstructpublic List<UserDO> getUserList() {Page<UserDO> userDOPage = userMapper.selectPage(new Page<>(2, 2), new QueryWrapper<UserDO>().lambda().orderByAsc(UserDO::getAge));return userDOPage.getRecords();}
}package com.qiuhuanhen.shardingjdbcdemo.entity.DO;import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode;import java.io.Serializable;@Data
@EqualsAndHashCode(callSuper = false)
@TableName("s_user")
public class UserDO implements Serializable {private static final long serialVersionUID=1L;private Long userId;private String userName;private Integer age;private String address;private String area;}package com.qiuhuanhen.shardingjdbcdemo.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.qiuhuanhen.shardingjdbcdemo.entity.DO.UserDO;public interface UserMapper extends BaseMapper<UserDO> {}import com.baomidou.mybatisplus.autoconfigure.MybatisPlusPropertiesCustomizer;
import com.baomidou.mybatisplus.core.MybatisConfiguration;
import com.baomidou.mybatisplus.core.config.GlobalConfig;
import com.baomidou.mybatisplus.extension.handlers.MybatisEnumTypeHandler;
import com.baomidou.mybatisplus.extension.plugins.OptimisticLockerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import static com.baomidou.mybatisplus.annotation.DbType.MYSQL;/*** ClassName: MybatisConfig <br/>* Description: 分页插件 <br/>*/
@Configurationpublic class MybatisPlusConfig {/*** 实现分页功能需要该配置*/@Beanpublic PaginationInterceptor paginationInterceptor() {PaginationInterceptor page = new PaginationInterceptor();page.setDbType(MYSQL);return page;}/*** 乐观锁插件 (需要在乐观锁字段配合@Version注解)** @return*/@Beanpublic OptimisticLockerInterceptor optimisticLockerInterceptor() {return new OptimisticLockerInterceptor();}/*** 枚举处理配置* @return*/@Beanpublic MybatisPlusPropertiesCustomizer mybatisPlusPropertiesCustomizer() {return properties -> {GlobalConfig globalConfig = properties.getGlobalConfig();globalConfig.setBanner(false);MybatisConfiguration configuration = new MybatisConfiguration();configuration.setDefaultEnumTypeHandler(MybatisEnumTypeHandler.class);properties.setConfiguration(configuration);};}}
pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.12</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.qiuhuanhen</groupId><artifactId>sharding-jdbc-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>sharding-jdbc-demo</name><description>Demo project for Spring Boot</description><properties><java.version>11</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- for spring boot --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><!-- spring-boot druid连接池 --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.4</version></dependency><!-- mysql driver --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.12</version></dependency><!--lombok--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.22</version></dependency><!-- jdk 9 以上 javax.xml.bind模块--><dependency><groupId>org.glassfish.jaxb</groupId><artifactId>jaxb-runtime</artifactId><version>2.3.5</version></dependency><!-- spring-boot mybatis-Plus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.1</version><exclusions><exclusion><artifactId>tomcat-jdbc</artifactId><groupId>org.apache.tomcat</groupId></exclusion></exclusions></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.12</version><scope>compile</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><image><builder>paketobuildpacks/builder-jammy-base:latest</builder></image></configuration></plugin></plugins></build></project>思考:
-
分库分表会有什么问题?
我们会看到一些规范,比如数据量500W或者1000W 占用内存多少G以上,才开始考虑进行分库分表,也就意味着分库表肯定有缺陷,那么弊端有哪些呢?
我们且先不谈读写分离分库分表 造成的数据一致性和延迟这么复杂的问题,仅拿我们demo来分析,首先分库一定会涉及到数据源切换的问题,这无疑也是一种开销,如果我们数据量本身不大 查询速度就很快,分库分表反而可能效率更低。此外,分库表之后 不能join , 这很考验我们的代码规范 冗余可以一定程度上解决这个问题。分布式事务也是另一大问题,一般情况下 我们可以用seata去解决,而在高并发下 可能要考虑性能问题。
以上都是比较常见的问题,博主最疑惑的,其实是关于跨库分页查询问题
-
sharding jdbc分库如何实现的 分页查询?
其实也没有什么好的方法,为了保证分页结果正确性,必须将当前分页为止的总量全部查询出来
(如果业务允许 我们自己也可以维护 同步一张未拆分的大表到其它效率高的非关系型数据库中进行分页查询 不走分库的分页查询 这和本文就跑远了)
如原本的分页SQL为:

拆分后的SQL为:

为什么两个库是limit 0,4之后归并结果 而不是 limit 2,2 呢?因为在翻页时 结果可能不正确, 我们自己创建一些数据按大小排序查询 验证一下就很好理解了。
比如表1有1,2,3,4 ,表2有1,3,7,8 ,我们业务需要的按从小到大排序取limit 2,2 , 我们预期想要的是 2和3 ,但是各自取limit 2,2 归并后的结果就是3,4了。那么问题来了,也就意味着当分页偏移大的时候 要去各自库表查询大量的数据,(这里也是对第一个问题的补充,如果数据量本来就不大 单表分页反而可能更快 ,分库表之后需要多次查询) 那这些大量的数据 取出来再拼接 不会导致jvm OOM吗? 是的 大家疑惑都是一致的 官方文档专门对这个进行了解释:
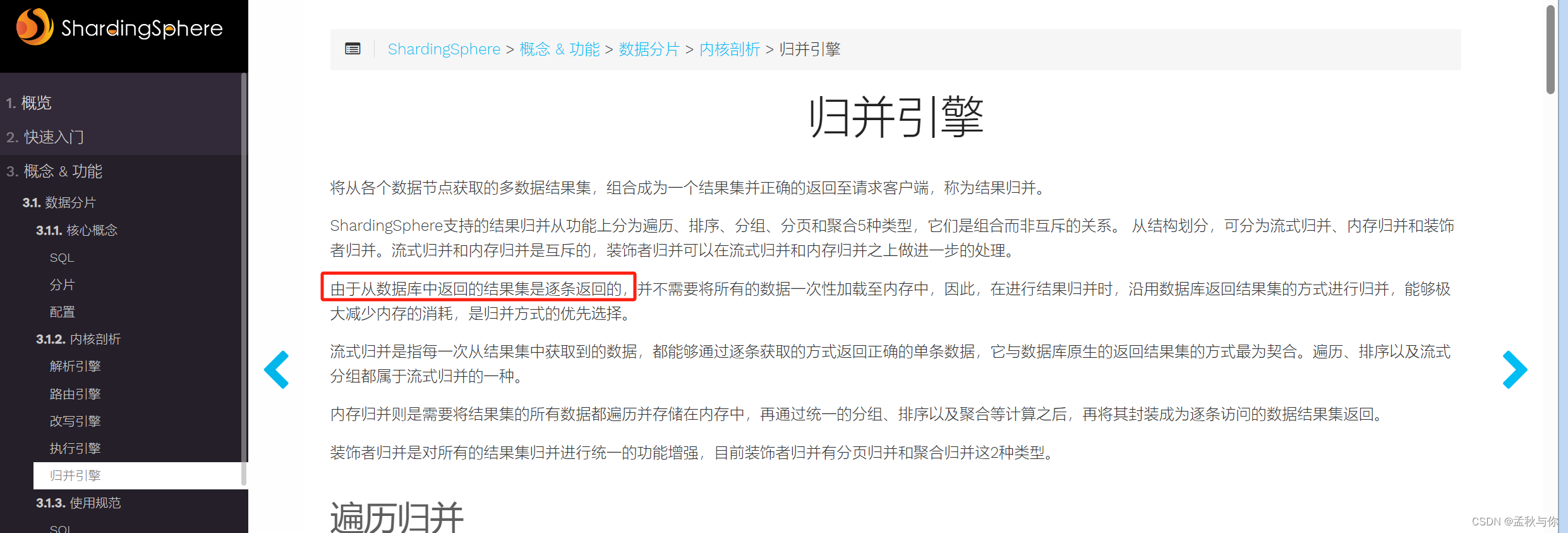
前文提到 博主认为归并做得很好的一点就是 它不会存储不需要的数据,经过一系列归并算法之后 只保留我们需要的数据,和我们将所有结果取出 再进行对比的简单粗暴算法不一样。
-
resutlSet 的思考
JDBC的resultSet 这是很基础又很久远的东西了,我们注意到sharding jdbc特地提到,其实resultSet是逐条返回的 , 不知道各位同学是否还记得 原始的jdbc 是通过resultSet.next去取值 一直遍历到next没值为止, resultSet本质是在维护一个游标。由此也会引申出一个问题,例如我们查询 select * from t ,有100W条结果,但是客户端(我们的java程序) 其实是逐条接收的,那么剩下未接收的数据在哪里呢?首先我们可以推断 数据库不可能是逐条从磁盘IO读取给我们 这样效率太慢了,未接收的数据推断是在缓存池里面。
我们或多或少听过 近期查询最多的结果 或者完全一样的语句 会保存在缓存池里面,缓存池包括查询缓存和InnoDB缓冲池 ,其中查询缓存就是缓存相同的请求 实际业务中 泛用性不高,InnoDB缓冲池则使用较多 或许我们在八股文看过 InnoDB缓冲池淘汰机制是通过LRU算法。回到博主的推断,近期查询的结果会存放在缓存池,那我们也可以反推,近期查询最多的结果既然会保存在缓存池 那么说明缓存池是会(暂时)存放我们查询内容的 从而进行对比,所以未接收的数据 存放在缓存池的观点 也应该是成立的。