本期技术贴主要介绍查询执行引擎的优化。查询执行引擎负责将 SQL 优化器生成的执行计划进行解释,通过任务调度执行从存储引擎里面把数据读取出来,计算出结果集,然后返回给客户。
在关系型数据库发展的早期,受制于计算机 IO 能力的约束,计算在查询整体的耗时占比并不明显,这个时候关注重点主要放在对于查询的优化。优化器的好坏,对于执行计划的优劣有着重要的意义,查询执行引擎的作用在数据库优化中对应等级是相对弱化的。但随着计算机硬件的发展,查询执行引擎也逐渐展现出他们的重要地位。
本篇博客结合 KaiwuDB 的部分源码和实例,介绍其如何充分发挥底层硬件的能力,优化查询执行引擎,从而提升数据库系统的性能。查询执行引擎是否高效与其采用的模型有直接关系,1990年,论文"Volcano, an Extensible and Parallel Query Evaluation System"提出了火山模型,这也是 KaiwuDB 查询执行引擎的基础。
一、火山模型/迭代模型
火山模型作为经典的查询执行模型被诸如 Oracle、MySQL 等主流关系数据库采用。该模型将关系代数中每一种算子抽象为一个 Operator(迭代器),每个 Operator 都提供一个接口 Next(),调用该接口会返回该算子产生/处理的一行数据(Tuple)。通过在查询树根节点自顶向下地调用 Next(),数据自底向上地被拉取处理,因而火山模型也称为拉取执行模型(Pull Based)。
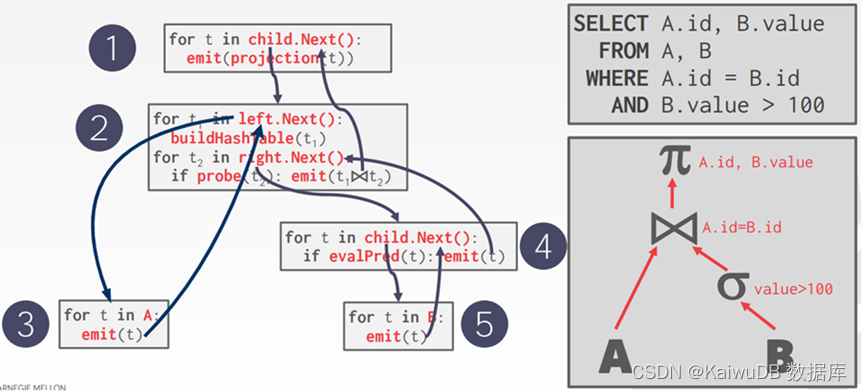 火山模型
火山模型
以一个两表连接的查询为例,让我们留意图中的第 ④ 步,Select 运算符。
调用 Next() 方法从其子运算符请求下一行,并检查它是否通过了筛选条件。如果是,则该行将返回到其父运算符;否则,将丢弃该行并重复该过程。
// RunFilter runs a filter expression and returns whether the filter passes.
func RunFilter(filter tree.TypedExpr, evalCtx *tree.EvalContext)(bool, error){if filter == nil{return true, nil}d, err := filter.Eval(evalCtx)if err != nil{return false,err}return d == tree.DBoolTrue, nil
}
上述即 KaiwuDB 在处理行时进行过滤的函数,参数 Filter 类型为 tree.TypedExpr,意为一个通用表达式。也就是说,对于每一行,都会调用一个完全通用的标量表达式的过滤器。表达式可以是任何东西:乘法、除法、相等检查或内置函数,它甚至可以是由上述表达式组成的树。由于这种通用性,计算机在过滤每一行时都有很多工作要做,它必须在做任何工作之前检查表达式是什么,这与解释型语言的逻辑相同(与编译型语言相比)。
尽管火山模型简单、直观、易用,只需将 Operator 自由地组装,且每个 Operator 只关心自己的处理逻辑,执行引擎并不感知。但是,在执行过程中,迭代一次只处理一行数据,数据局部性差,很容易使 CPU cache 失效,并且调用 Next() 函数(虚函数)次数太多,开销较大,使得 CPU 执行效率不高。
二、算子融合
将经常出现的 Operator(如 Project 和 Filter)融合在其他 Operator 中能够一定程度上减少虚函数的调用,提高单个 Operator 的处理能力和数据局部性。以 KaiwuDB 的 tablereader 算子为例,在扫表时便能够对数据行进行过滤和投影,其 Next() 函数中实现了相关逻辑。
下图是 tablereader 算子 Next() 函数调用的简化时序图,可以看到,在读取一条数据进行处理时会判断 Filter 和 outputCols 决定是否进行 Filter 和 Projection 操作。
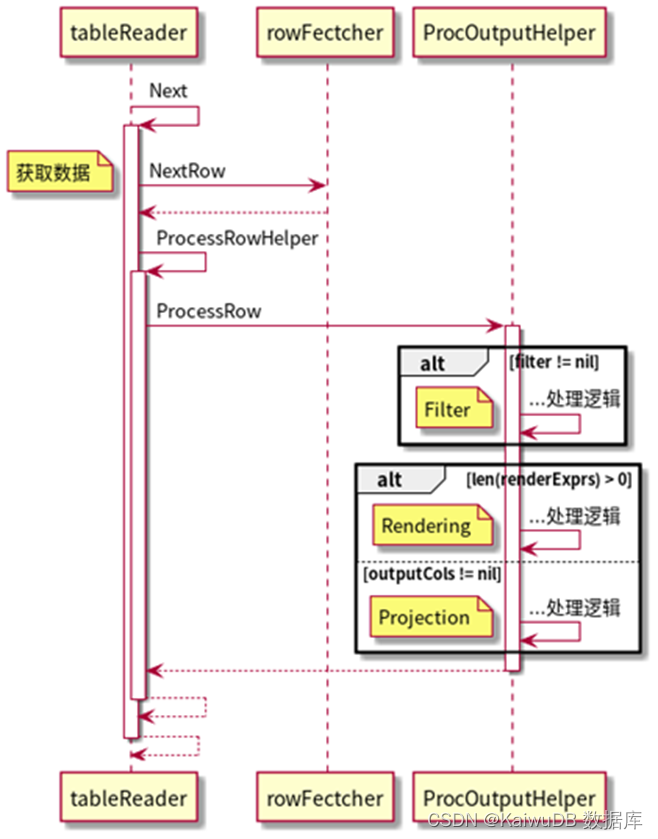 TableReader 算子 Next() 函数调用的简化时序图
TableReader 算子 Next() 函数调用的简化时序图
下图展示了一条查询语句示例的物理计划,也可以看到在 TableReader 算子中对范围 Spans 和输出列 Out 进行了限制。
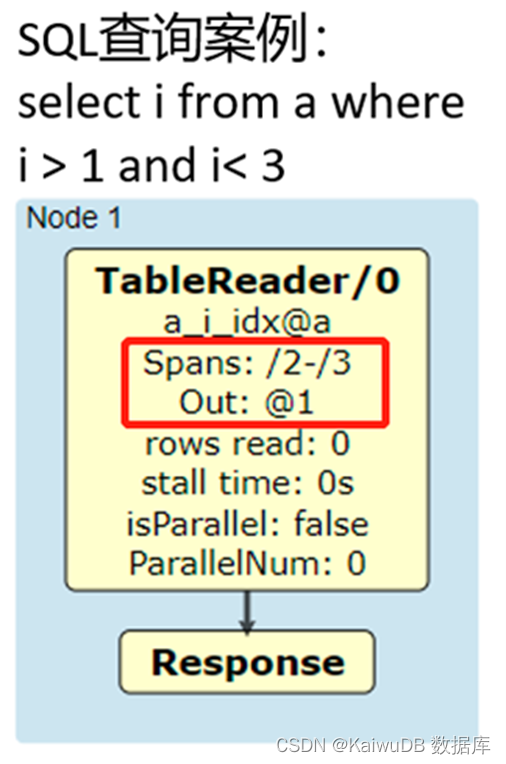
查询的计划示例
三、向量化模型
不同于火山模型按行迭代的方式,如下图所示,向量化模型采用批量迭代,在算子间一次传递一批数据。通过更改数据方向(从行到列),把从列到元组的转化推迟到较晚的时候执行,来更有效地利用现代 CPU。连续的数据有利于 CPU cache 的命中,减少 memory stall 现象;除此之外,通过 SIMD 指令一次处理多个数据,可以充分利用 CPU 的计算能力。

向量化模型整体架构与火山模型类似,依然采用了拉取式模型。考虑一个具有 Id,Name 和 Age 三列的表 People, batch 将由 Id 的整型数组、Name 的字符串数组以及 Age 的整型数组组成,面对查询 SELECT Name, (Age - 30) * 50 AS Bonus FROM People WHERE Age > 30; 其向量化模型大致下图所示。
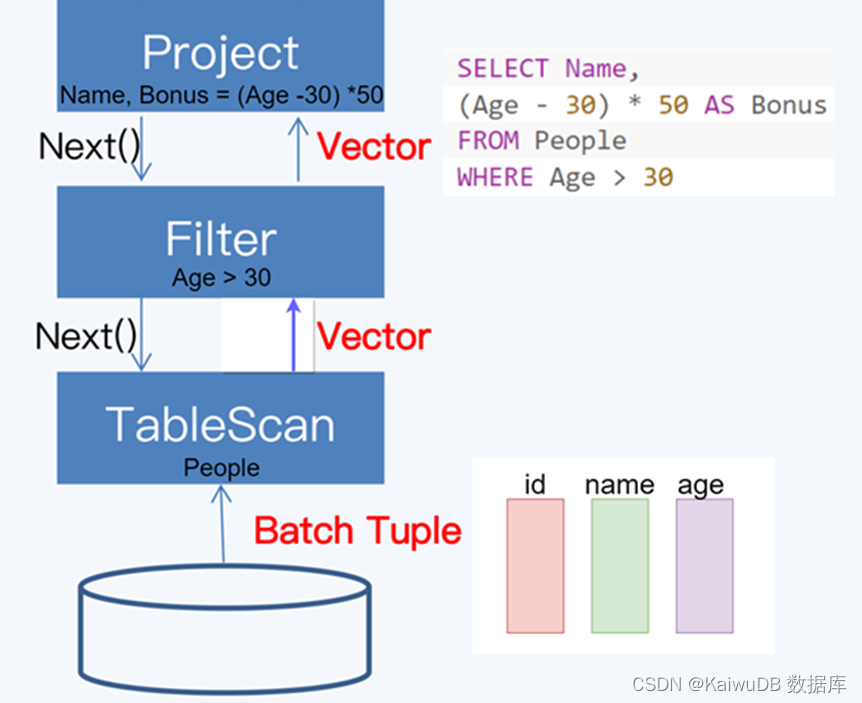
显然向量化模型与列式存储搭配使用可以获得更好的效果,但非列式存储也可以采用折中的方式来实现向量化模型。KaiwuDB 使用的是行存储引擎,在其向量化执行模型中,在底层 Operator 中实现了多行到向量块的转化,上层的 Operator 则以向量块作为输入进行处理,最后再由顶层的 Operator 进行向量块到行数据的转化。
除此之外,为了避免上文提到的火山模型下由于 Filter 所使用标量表达式的通用性带来的额外计算开销,在 KaiwuDB 的向量化执行模型中,每个向量化 Operator 在执行期间不允许任何自由度或运行时选择。
这意味着,对于数据类型、属性和工作任务的任意组合,都有一个专门的 Operator 负责工作。执行引擎从 Operator 链请求 batch:每个 Operator 从其子级 Operator 请求一个 batch,执行其特定工作任务,然后将 batch 返回到其父级 Operator。
因此对于示例查询 SELECT Name, (Age - 30) * 50 AS Bonus FROM People WHERE Age > 30; 实际向量化模型比上述的内容更复杂,具体如下图所示。
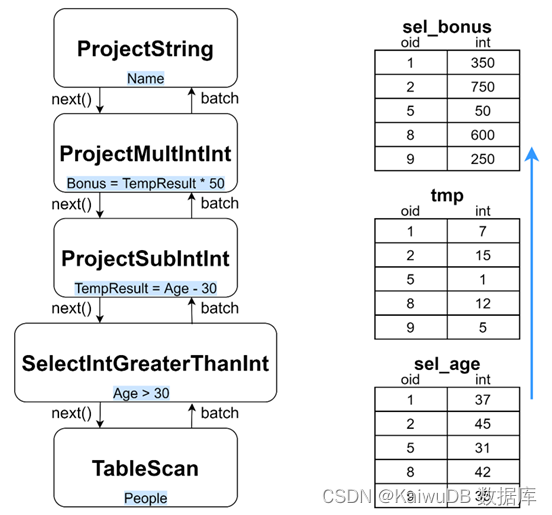
SelectIntGreaterThanInt Operator 在获取 People 表的 batch 后将选择所有 Age 大于 30 的值;然后,这个新的 sel_age batch 将传递给 ProjectSubIntInt Operator,该 Operator 执行简单的减法以生成 tmp batch;最后,这个 tmp batch 被传递给 ProjectMultIntInt Operator,该 Operator 计算最终的 Bonus=(Age - 30)* 50。
为了具体实现这些向量化 Operator,KaiwuDB 将流程分解为单个列上的紧密 for 循环。以下的代码段(有删减)实现了 SelectIntGreaterThanInt Operator 的部分功能。该函数从其子项 Operator 中检索 batch,并循环访问列的每个元素,同时将大于 30(p.constArg) 的值选中标记。然后,将 batch 及其选中向量返回给父级 Operator 进行进一步处理。这段代码虽然简单但却非常有效,for 循环迭代了一个 int64 的切片,将每个切片元素与另一个 int64 常量进行比较,并将结果存储在另一个 int32 切片中,从而实现了一个快速的循环。
func (p *selGTInt64Int64Const0p) Next(ctx context,Context) coldata,Batch {// In order to inline the templated code of overloads, we need to have a// 'decimalScratch' local variable of type 'decimalOverloadScratch'.decimalScratch := p.decimalScratch// However, the scratch is not used in all of the selection operators, so// we add this to go around "unused" error._ = decimalScratchfor{batch := p.input.Next(ctx)if batch.Length() == 0 {return batch}vec := batch.ColVec(p.colIdx)col := vec.Int64()var idx intn := batch.Length()if sel := batch,Selection(); sel != nil {sel = sel[:n]for _, i := range sel {var cmp boolarg := col[i]{var cmpResult int{a, b := int64(arg), int64(p.constArg)if a < b {cmpResult = -1} else if a > b {cmpResult = 1 } else {cmpResult = 0}}cmp = cmpResult > 0}isNull := falseif cmp && !isNull{sel[idx] = iidx++}}}if idx > 0 {batch.SetLength(idx)return batch}}
}
KaiwuDB 使用 kv 存储引擎 rocksdb 作为底层存储。通过从存储读取行后将行转换为列式数据的 batch,然后将这些 batch 送到向量化执行引擎中处理,对于处理大量数据时有可观的性能提升,但在数据量小时向量化是没有优势的,因为向量化的过程会带来额外的开销。
因此,面向行的执行模型可以为联机事务处理(OLTP)查询提供良好的性能,而向量化执行模式往往更适用于涉及海量数据的联机分析处理(OLAP)查询。KaiwuDB 在执行计划时会根据估计的 tablereader 输出的最大行数,与 SessionData 中的 VectorizeRowCountThreshold 字段比较来判断是否需要向量化执行。
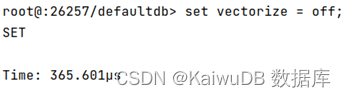
KaiwuDB 默认开启向量化执行引擎,用户也可以选择关闭。关闭和开启向量化执行引擎可以通过 SET 进行设置,如下图所示。除此之外,使用 EXPLAIN(VEC)语句可用于查看查询的向量化执行计划。