猛戳订阅! 👉 《一起玩蛇》🐍
猛戳订阅! 👉 《一起玩蛇》🐍

💭 写在前面:本章我们将通过 Python 手动实现条件分布函数的计算,实现求平均值,方差和协方差函数,实现求函数期望值的函数。部署的测试代码放到文后了,运行所需环境 python version >= 3.6,numpy >= 1.15,nltk >= 3.4,tqdm >= 4.24.0,scikit-learn >= 0.22。
🔗 相关链接:【概率论】Python:实现求联合分布函数 | 求边缘分布函数
📜 本章目录:
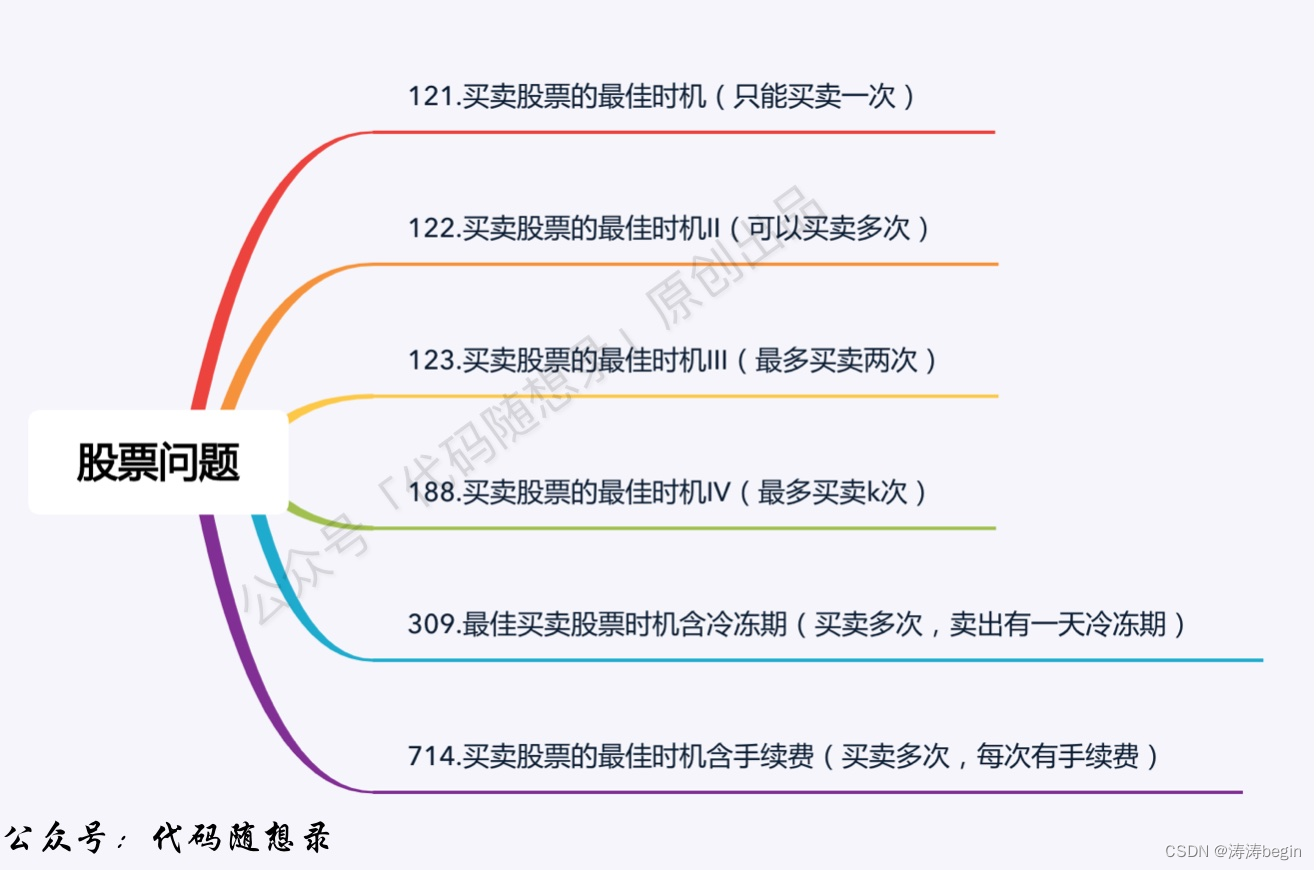
0x00 实现求条件分布的函数(Conditional distribution)
0x01 实现求平均值, 方差和协方差的函数(Mean, Variance, Covariance)
0x02 实现求函数期望值的函数(Expected Value of a Function)
0x04 提供测试用例
0x00 实现求条件分布的函数(Conditional distribution)
实现 conditional_distribution_of_word_counts 函数,接收 Point 和 Pmarginal 并求出结果。
请完成下面的代码,计算条件分布函数 (Joint distribution),将结果存放到 Pcond 中并返回:
def conditional_distribution_of_word_counts(Pjoint, Pmarginal):"""Parameters:Pjoint (numpy array) - Pjoint[m,n] = P(X0=m,X1=n), whereX0 is the number of times that word0 occurs in a given text,X1 is the number of times that word1 occurs in the same text.Pmarginal (numpy array) - Pmarginal[m] = P(X0=m)Outputs:Pcond (numpy array) - Pcond[m,n] = P(X1=n|X0=m)"""raise RuntimeError("You need to write this part!")return Pcond🚩 输出结果演示:
Problem3. Conditional distribution:
[[0.97177419 0.02419355 0.00201613 0. 0.00201613][1. 0. 0. 0. 0. ][ nan nan nan nan nan][ nan nan nan nan nan][1. 0. 0. 0. 0. ]]💭 提示:条件分布 (Conditional distribution) 公式如下:
💬 代码演示:conditional_distribution_of_word_counts 的实现
def conditional_distribution_of_word_counts(Pjoint, Pmarginal):Pcond = Pjoint / Pmarginal[:, np.newaxis] # 根据公式即可算出条件分布return Pcond值得注意的是,如果分母 Pmarginal 中的某些元素为零可能会导致报错问题。这导致除法结果中出现了 NaN(Not a Number)。在计算条件概率分布时,如果边缘分布中某个值为零,那么条件概率无法得到合理的定义。为了解决这个问题,我们可以在计算 Pmarginal 时,将所有零元素替换为一个非零的很小的数,例如 1e-10。
0x01 实现求平均值, 方差和协方差的函数(Mean, Variance, Covariance)
使用英文文章中最常出现的 a, the 等单词求出其联合分布 (Pathe) 和边缘分布 (Pthe)。
Pathe 和 Pthe 在 reader.py 中已经定义好了,不需要我们去实现,具体代码文末可以查阅。
这里需要我们使用概率分布,编写求平均值、方差和协方差的函数:
- 函数 mean_from_distribution 和 variance_from_distribution 输入概率分布
中计算概率变量
的平均和方差并返回。平均值和方差保留小数点前三位即可。
- 函数 convariance_from_distribution 计算概率分布
中的概率变量
和概率变量
的协方差并返回,同样保留小数点前三位即可。
def mean_from_distribution(P):"""Parameters:P (numpy array) - P[n] = P(X=n)Outputs:mu (float) - the mean of X"""raise RuntimeError("You need to write this part!")return mudef variance_from_distribution(P):"""Parameters:P (numpy array) - P[n] = P(X=n)Outputs:var (float) - the variance of X"""raise RuntimeError("You need to write this part!")return vardef covariance_from_distribution(P):"""Parameters:P (numpy array) - P[m,n] = P(X0=m,X1=n)Outputs:covar (float) - the covariance of X0 and X1"""raise RuntimeError("You need to write this part!")return covar🚩 输出结果演示:
Problem4-1. Mean from distribution:
4.432
Problem4-2. Variance from distribution:
41.601
Problem4-3. Convariance from distribution:
9.235💭 提示:求平均值、方差和协方差的公式如下
💬 代码演示:
def mean_from_distribution(P):mu = np.sum( # Σnp.arange(len(P)) * P)return round(mu, 3) # 保留三位小数def variance_from_distribution(P):mu = mean_from_distribution(P)var = np.sum( # Σ(np.arange(len(P)) - mu) ** 2 * P)return round(var, 3) # 保留三位小数def covariance_from_distribution(P):m, n = P.shapemu_X0 = mean_from_distribution(np.sum(P, axis=1))mu_X1 = mean_from_distribution(np.sum(P, axis=0))covar = np.sum( # Σ(np.arange(m)[:, np.newaxis] - mu_X0) * (np.arange(n) - mu_X1) * P)return round(covar, 3)0x02 实现求函数期望值的函数(Expected Value of a Function)
实现 expectation_of_a_function 函数,计算概率函数 的
。
其中 为联合分布,
为两个实数的输入,以
的形式输出。
函数 已在 reader.py 中定义,你只需要计算
的值并保留后三位小数返回即可。
def expectation_of_a_function(P, f):"""Parameters:P (numpy array) - joint distribution, P[m,n] = P(X0=m,X1=n)f (function) - f should be a function that takes tworeal-valued inputs, x0 and x1. The output, z=f(x0,x1),must be a real number for all values of (x0,x1)such that P(X0=x0,X1=x1) is nonzero.Output:expected (float) - the expected value, E[f(X0,X1)]"""raise RuntimeError("You need to write this part!")return expected🚩 输出结果演示:
Problem5. Expectation of a funciton:
1.772💬 代码演示:expectation_of_a_function 函数的实现
def expectation_of_a_function(P, f):"""Parameters:P (numpy array) - joint distribution, P[m,n] = P(X0=m,X1=n)f (function) - f should be a function that takes tworeal-valued inputs, x0 and x1. The output, z=f(x0,x1),must be a real number for all values of (x0,x1)such that P(X0=x0,X1=x1) is nonzero.Output:expected (float) - the expected value, E[f(X0,X1)]"""m, n = P.shapeE = 0.0for x0 in range(m):for x1 in range(n):E += f(x0, x1) * P[x0, x1]return round(E, 3) # 保留三位小数0x04 提供测试用例
这是一个处理文本数据的项目,测试用例为 500 封电子邮件的数据(txt 的格式文件):
🔨 所需环境:
- python version >= 3.6
- numpy >= 1.15
- nltk >= 3.4
- tqdm >= 4.24.0
- scikit-learn >= 0.22nltk 是 Natural Language Toolkit 的缩写,是一个用于处理人类语言数据(文本)的 Python 库。nltk 提供了许多工具和资源,用于文本处理和 NLP,PorterStemmer 用来提取词干,用于将单词转换为它们的基本形式,通常是去除单词的词缀。 RegexpTokenizer 是基于正则表达式的分词器,用于将文本分割成单词。
💬 data_load.py:用于加载文本数据
import os
import numpy as np
from nltk.stem.porter import PorterStemmer
from nltk.tokenize import RegexpTokenizer
from tqdm import tqdmporter_stemmer = PorterStemmer()
tokenizer = RegexpTokenizer(r"\w+")
bad_words = {"aed", "oed", "eed"} # these words fail in nltk stemmer algorithmdef loadFile(filename, stemming, lower_case):"""Load a file, and returns a list of words.Parameters:filename (str): the directory containing the datastemming (bool): if True, use NLTK's stemmer to remove suffixeslower_case (bool): if True, convert letters to lowercaseOutput:x (list): x[n] is the n'th word in the file"""text = []with open(filename, "rb") as f:for line in f:if lower_case:line = line.decode(errors="ignore").lower()text += tokenizer.tokenize(line)else:text += tokenizer.tokenize(line.decode(errors="ignore"))if stemming:for i in range(len(text)):if text[i] in bad_words:continuetext[i] = porter_stemmer.stem(text[i])return textdef loadDir(dirname, stemming, lower_case, use_tqdm=True):"""Loads the files in the folder and returns alist of lists of words from the text in each file.Parameters:name (str): the directory containing the datastemming (bool): if True, use NLTK's stemmer to remove suffixeslower_case (bool): if True, convert letters to lowercaseuse_tqdm (bool, default:True): if True, use tqdm to show status barOutput:texts (list of lists): texts[m][n] is the n'th word in the m'th emailcount (int): number of files loaded"""texts = []count = 0if use_tqdm:for f in tqdm(sorted(os.listdir(dirname))):texts.append(loadFile(os.path.join(dirname, f), stemming, lower_case))count = count + 1else:for f in sorted(os.listdir(dirname)):texts.append(loadFile(os.path.join(dirname, f), stemming, lower_case))count = count + 1return texts, count
💬 reader.py:将读取数据并打印
import data_load, hw4, importlib
import numpy as npif __name__ == "__main__":texts, count = data_load.loadDir("data", False, False)importlib.reload(hw4)Pjoint = hw4.joint_distribution_of_word_counts(texts, "mr", "company")print("Problem1. Joint distribution:")print(Pjoint)print("---------------------------------------------")P0 = hw4.marginal_distribution_of_word_counts(Pjoint, 0)P1 = hw4.marginal_distribution_of_word_counts(Pjoint, 1)print("Problem2. Marginal distribution:")print("P0:", P0)print("P1:", P1)print("---------------------------------------------")Pcond = hw4.conditional_distribution_of_word_counts(Pjoint, P0)print("Problem3. Conditional distribution:")print(Pcond)print("---------------------------------------------")Pathe = hw4.joint_distribution_of_word_counts(texts, "a", "the")Pthe = hw4.marginal_distribution_of_word_counts(Pathe, 1)mu_the = hw4.mean_from_distribution(Pthe)print("Problem4-1. Mean from distribution:")print(mu_the)var_the = hw4.variance_from_distribution(Pthe)print("Problem4-2. Variance from distribution:")print(var_the)covar_a_the = hw4.covariance_from_distribution(Pathe)print("Problem4-3. Covariance from distribution:")print(covar_a_the)print("---------------------------------------------")def f(x0, x1):return np.log(x0 + 1) + np.log(x1 + 1)expected = hw4.expectation_of_a_function(Pathe, f)print("Problem5. Expectation of a function:")print(expected)

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2023.11.15
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!| 📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. 比特科技. C++[EB/OL]. 2021[2021.8.31]. |