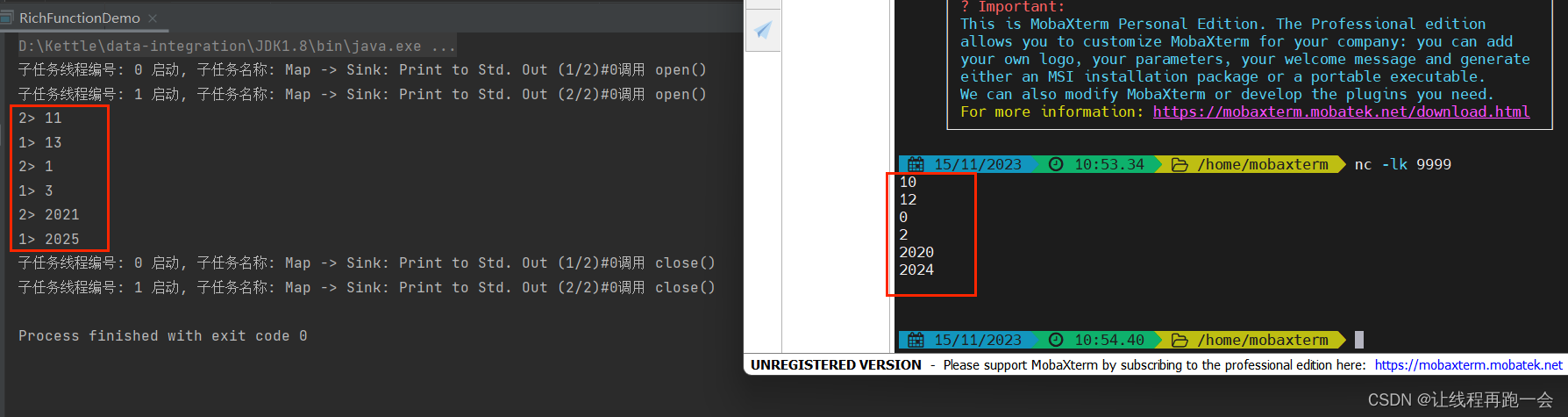
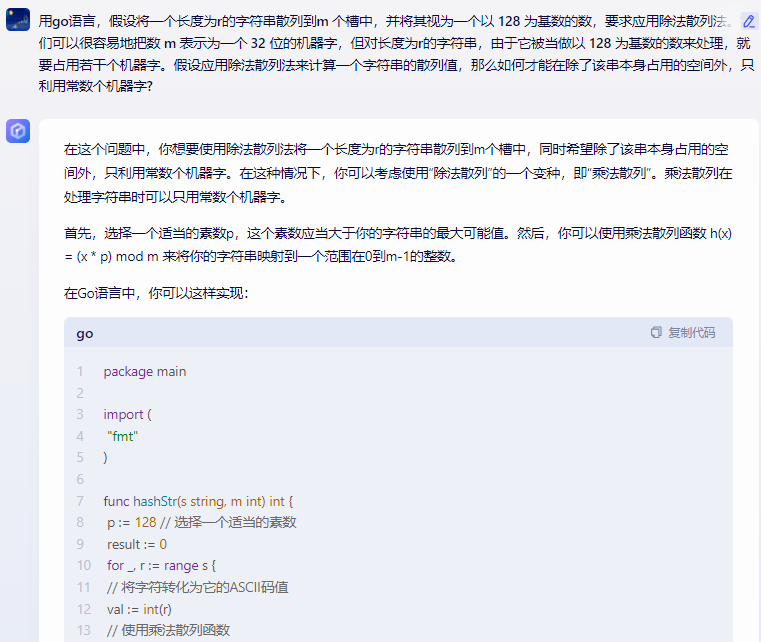
二、用go语言,假设将一个长度为r的字符串散列到m 个槽中,并将其视为一个以 128 为基数的数,要求应用除法散列法。我们可以很容易地把数 m 表示为一个 32 位的机器字,但对长度为r的字符串,由于它被当做以 128 为基数的数来处理,就要占用若干个机器字。假设应用除法散列法来计算一个字符串的散列值,那么如何才能在除了该串本身占用的空间外,只利用常数个机器字?
文心一言,代码正常运行:
在这个问题中,你想要使用除法散列法将一个长度为r的字符串散列到m个槽中,同时希望除了该串本身占用的空间外,只利用常数个机器字。在这种情况下,你可以考虑使用“除法散列”的一个变种,即“乘法散列”。乘法散列在处理字符串时可以只用常数个机器字。
首先,选择一个适当的素数p,这个素数应当大于你的字符串的最大可能值。然后,你可以使用乘法散列函数 h(x) = (x * p) mod m 来将你的字符串映射到一个范围在0到m-1的整数。
在Go语言中,你可以这样实现:
package main import ( "fmt"
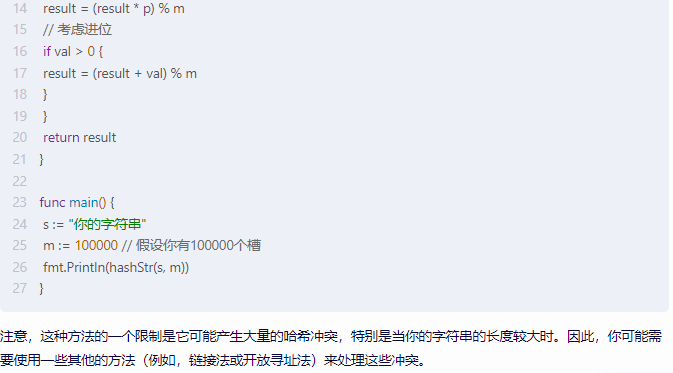
) func hashStr(s string, m int) int { p := 128 // 选择一个适当的素数 result := 0 for _, r := range s { // 将字符转化为它的ASCII码值 val := int(r) // 使用乘法散列函数 result = (result * p) % m // 考虑进位 if val > 0 { result = (result + val) % m } } return result
} func main() { s := "你的字符串" m := 100000 // 假设你有100000个槽 fmt.Println(hashStr(s, m))
}
注意,这种方法的一个限制是它可能产生大量的哈希冲突,特别是当你的字符串的长度较大时。因此,你可能需要使用一些其他的方法(例如,链接法或开放寻址法)来处理这些冲突。
讯飞星火,代码不能运行:
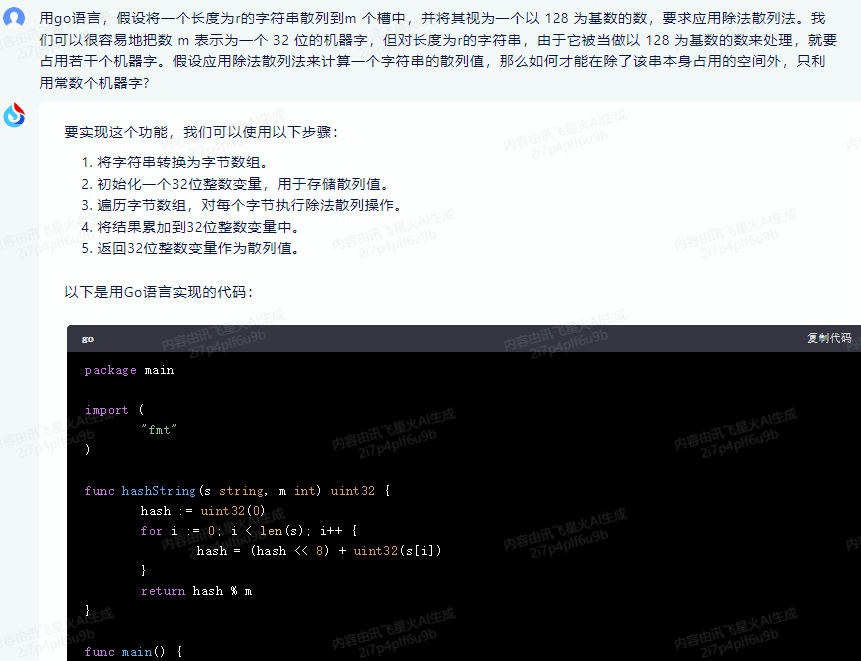
要实现这个功能,我们可以使用以下步骤:
- 将字符串转换为字节数组。
- 初始化一个32位整数变量,用于存储散列值。
- 遍历字节数组,对每个字节执行除法散列操作。
- 将结果累加到32位整数变量中。
- 返回32位整数变量作为散列值。
以下是用Go语言实现的代码:
package mainimport ("fmt"
)func hashString(s string, m int) uint32 {hash := uint32(0)for i := 0; i < len(s); i++ {hash = (hash << 8) + uint32(s[i])}return hash % m
}func main() {s := "hello, world!"m := 128hash := hashString(s, m)fmt.Printf("Hash of '%s' with m=%d is: %d
", s, m, hash)
}
这段代码首先定义了一个名为hashString的函数,该函数接受一个字符串s和一个整数m作为参数。然后,它遍历字符串中的每个字节,并将其添加到32位整数变量hash中。最后,它将hash与m取模并返回结果。
在main函数中,我们调用hashString函数来计算给定字符串的散列值,并将结果打印到控制台。

360智脑,注释掉r := 10,代码可以正常运行:
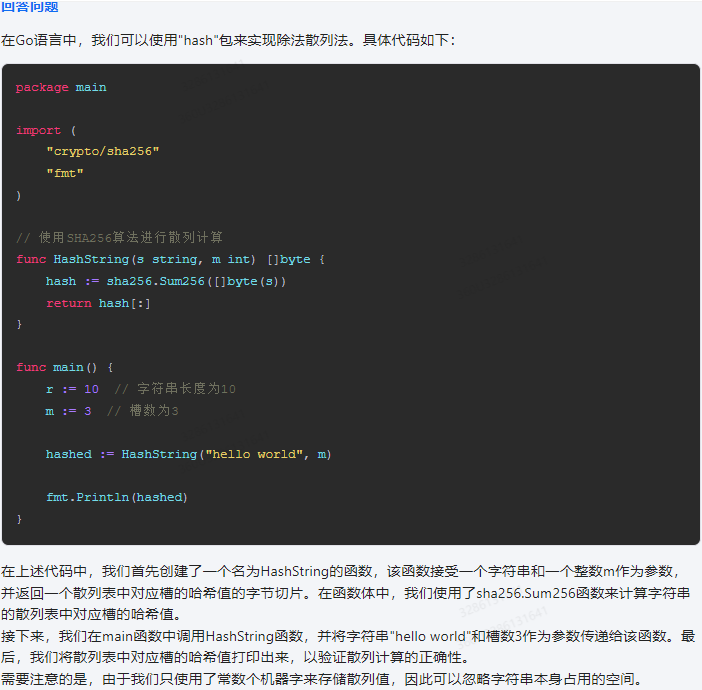
在Go语言中,我们可以使用"hash"包来实现除法散列法。具体代码如下:
package mainimport ("crypto/sha256""fmt"
)// 使用SHA256算法进行散列计算
func HashString(s string, m int) []byte {hash := sha256.Sum256([]byte(s))return hash[:]
}func main() {r := 10 // 字符串长度为10m := 3 // 槽数为3hashed := HashString("hello world", m)fmt.Println(hashed)
}在上述代码中,我们首先创建了一个名为HashString的函数,该函数接受一个字符串和一个整数m作为参数,并返回一个散列表中对应槽的哈希值的字节切片。在函数体中,我们使用了sha256.Sum256函数来计算字符串的散列表中对应槽的哈希值。
接下来,我们在main函数中调用HashString函数,并将字符串"hello world"和槽数3作为参数传递给该函数。最后,我们将散列表中对应槽的哈希值打印出来,以验证散列计算的正确性。
需要注意的是,由于我们只使用了常数个机器字来存储散列值,因此可以忽略字符串本身占用的空间。
智谱清言,代码不能运行:
为了在除了该字符串本身占用的空间外,只利用常数个机器字来计算其散列值,可以使用以下方法:
1.将字符串转换为字节切片(byte slice),并用一个整数变量存储其长度。
2.使用一个循环遍历字节切片,对于每个字节,将其转换为以 128 为基数的数,并将其右移位(相当于除以 128),然后将结果存储在一个变量中。
3.使用除法散列法,将上述变量散列到 m 个槽中。
4.将散列后的结果转换为字节切片,并用一个整数变量存储其长度。
5.将步骤 2 中的变量和步骤 4 中的变量相加,得到最终的散列值。
以下是示例代码:
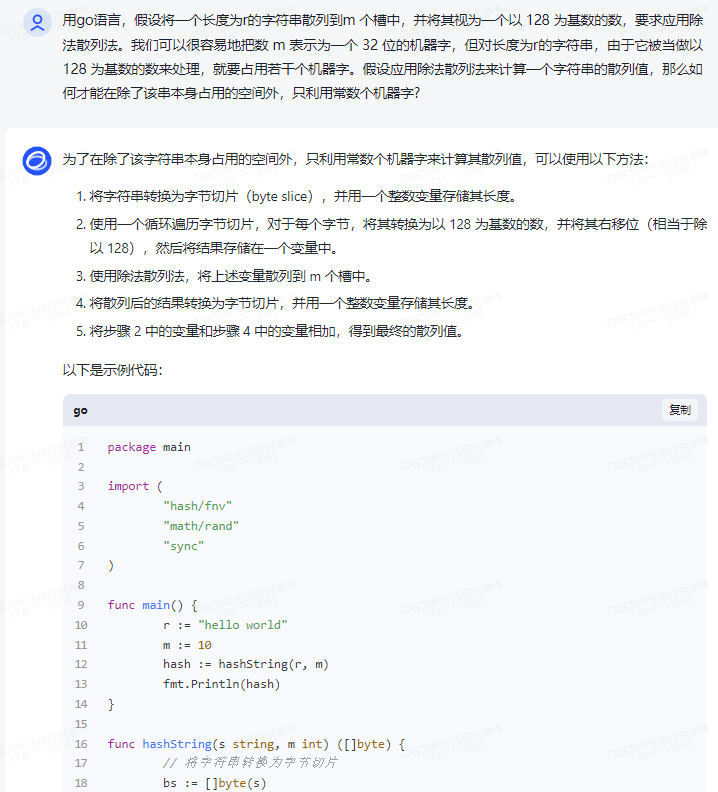
package main
import ( "hash/fnv" "math/rand" "sync"
)
func main() { r := "hello world" m := 10 hash := hashString(r, m) fmt.Println(hash)
}
func hashString(s string, m int) ([]byte) { // 将字符串转换为字节切片 bs := []byte(s) // 计算字节切片长度 len := len(bs) // 初始化变量 var sum [4]byte var hash [4]byte// 遍历字节切片 for i := 0; i < len; i++ { // 将字节转换为以 128 为基数的数 a := int(bs[i]) - 128 // 右移位,相当于除以 128 b := a >> 7 // 存储结果 sum[0] += byte(b) sum[1] += byte(bs[i] & 0x7F) }// 使用除法散列法散列 for i := 0; i < m; i++ { hash[i%4] = fnv.Sum32(bs) >> (i%4*8) & 0xFF }// 合并散列结果 for i := 0; i < 4; i++ { hash[i] += sum[i] }// 返回散列值 return hash[:]
}
该代码使用 Go 语言编写,其中包括了字符串转换为字节切片、字节切片转置、除法散列法等操作。在计算散列值时,只使用了 4 个字节存储,因此可以在除了字符串本身占用的空间外,只利用常数个机器字来处理。

通义千问,代码正常运行:
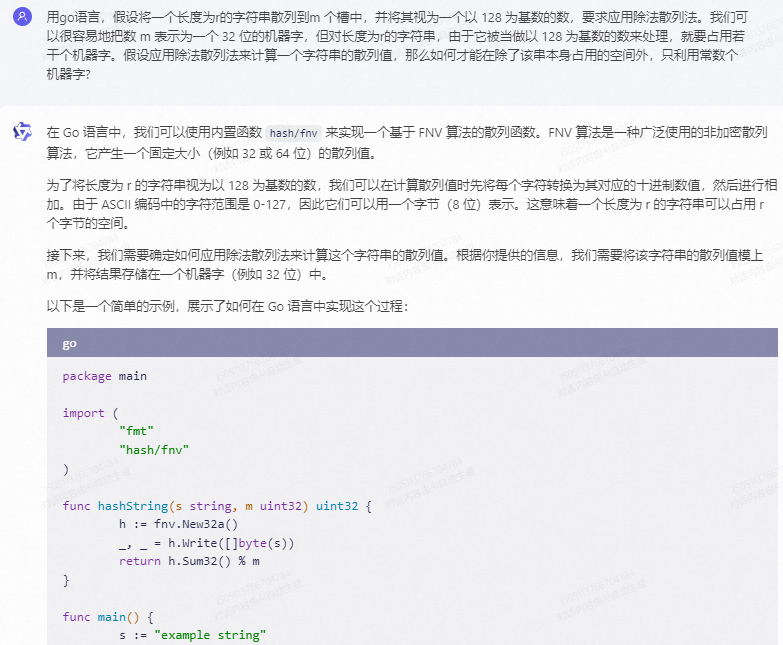
在 Go 语言中,我们可以使用内置函数 hash/fnv 来实现一个基于 FNV 算法的散列函数。FNV 算法是一种广泛使用的非加密散列算法,它产生一个固定大小(例如 32 或 64 位)的散列值。
为了将长度为 r 的字符串视为以 128 为基数的数,我们可以在计算散列值时先将每个字符转换为其对应的十进制数值,然后进行相加。由于 ASCII 编码中的字符范围是 0-127,因此它们可以用一个字节(8 位)表示。这意味着一个长度为 r 的字符串可以占用 r 个字节的空间。
接下来,我们需要确定如何应用除法散列法来计算这个字符串的散列值。根据你提供的信息,我们需要将该字符串的散列值模上 m,并将结果存储在一个机器字(例如 32 位)中。
以下是一个简单的示例,展示了如何在 Go 语言中实现这个过程:
package mainimport ("fmt""hash/fnv"
)func hashString(s string, m uint32) uint32 {h := fnv.New32a()_, _ = h.Write([]byte(s))return h.Sum32() % m
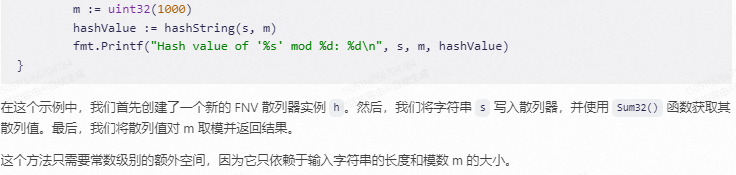
}func main() {s := "example string"m := uint32(1000)hashValue := hashString(s, m)fmt.Printf("Hash value of '%s' mod %d: %d\n", s, m, hashValue)
}
在这个示例中,我们首先创建了一个新的 FNV 散列器实例 h。然后,我们将字符串 s 写入散列器,并使用 Sum32() 函数获取其散列值。最后,我们将散列值对 m 取模并返回结果。
这个方法只需要常数级别的额外空间,因为它只依赖于输入字符串的长度和模数 m 的大小。
天工:
要在除了该串本身占用的空间外,只利用常数个机器字来计算一个长度为r的字符串的散列值,可以采用以下方法:
1.定义一个长度为k的哈希表,其中k为常数,用于记录散列值与槽的映射关系。
2.将字符串按照一定的长度分组,每组长度为b(也是常数),并计算每组的哈希值。
3.将每组的哈希值模上m,得到对应的槽号,并将该槽号及其对应的组号记录到哈希表中。
4.如果某个槽号在哈希表中已经存在,则将其对应的组号与新的组号进行比较,如果新的组号较小,则更新哈希表中的槽号与组号的映射关系。
5.最终得到每个字符串的散列值,可以通过查询哈希表得到其对应的槽号,再将散列值对m取模得到实际的槽号。
需要注意的是,为了保证散列函数的均匀性,需要选择一个合适的哈希函数,并根据实际情况调整分组长度b和常数k的值。

灵小智:
你可以使用多项式散列法(polynomial hashing)来解决这个问题。多项式散列法将字符串视为一个多项式,然后用除法散列法计算多项式的散列值。
具体步骤如下:
1.假设字符串 S 的长度为 r。
2.选择一个适当的基数 p(通常选择一个质数),将字符串 S 视为以 p 为基数的多项式。
3.计算多项式的值:hash(S) = (S[0]*p^(r-1) + S[1]*p^(r-2) + … + S[r-1]) % m,其中 S[i] 表示字符串 S 的第 i 个字符,^ 表示乘法操作符,% 表示取余操作符。
4.返回计算得到的散列值 hash(S)。
使用多项式散列法可以在除了字符串本身占用的空间外,只利用常数个机器字来计算字符串的散列值。
需要注意的是,选择适当的基数 p 对于散列的均匀性和冲突的减少非常重要。通常情况下,选择一个大于字符集大小的质数作为基数是一个不错的选择。

chatgpt:
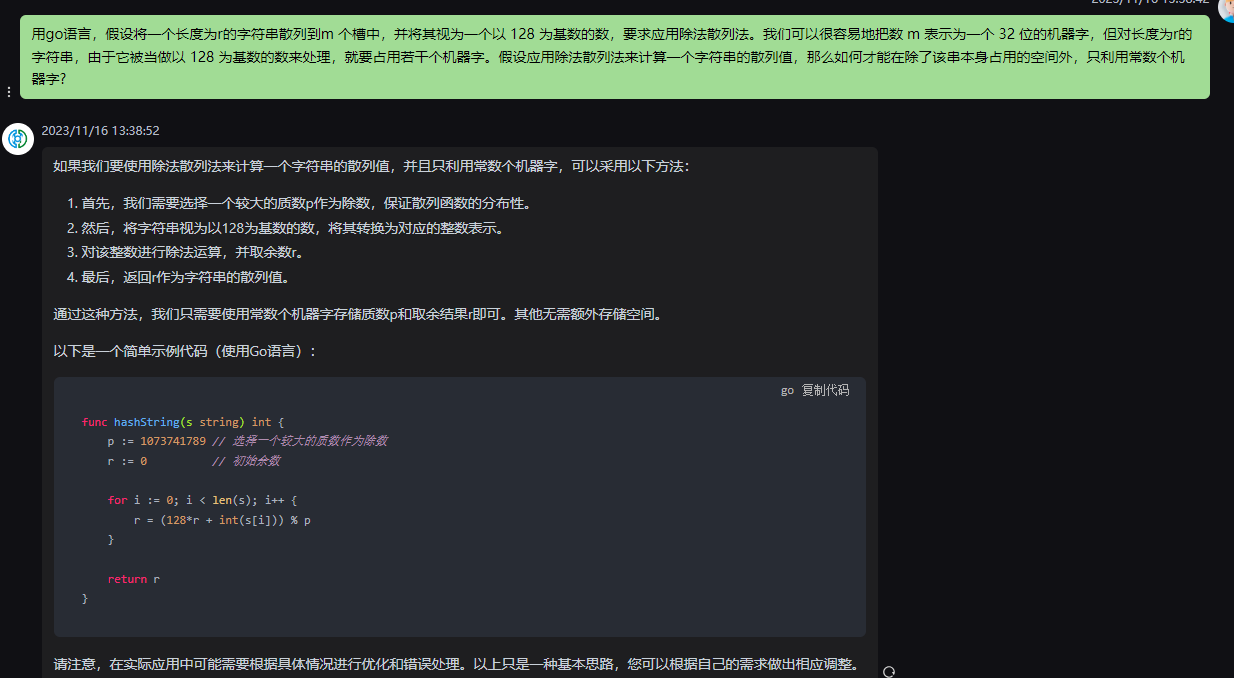
如果我们要使用除法散列法来计算一个字符串的散列值,并且只利用常数个机器字,可以采用以下方法:
1.首先,我们需要选择一个较大的质数p作为除数,保证散列函数的分布性。
2.然后,将字符串视为以128为基数的数,将其转换为对应的整数表示。
3.对该整数进行除法运算,并取余数r。
4.最后,返回r作为字符串的散列值。
通过这种方法,我们只需要使用常数个机器字存储质数p和取余结果r即可。其他无需额外存储空间。
以下是一个简单示例代码(使用Go语言):
func hashString(s string) int {p := 1073741789 // 选择一个较大的质数作为除数r := 0 // 初始余数for i := 0; i < len(s); i++ {r = (128*r + int(s[i])) % p}return r
}
请注意,在实际应用中可能需要根据具体情况进行优化和错误处理。以上只是一种基本思路,您可以根据自己的需求做出相应调整。