案例简介:有178个红酒样本,每一款红酒含有13项特征参数,如镁、脯氨酸含量,红酒根据这些特征参数被分成3类。要求是任意输入一组红酒的特征参数,模型需预测出该红酒属于哪一类。
1. K近邻算法介绍
1.1 算法原理
原理:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,那么该样本也属于这个类别。简单来说就是,求两点之间的距离,看距离谁是最近的,以此来区分我们要预测的这个数据是属于哪个分类。
我们看图来理解一下。蓝色点是属于a类型的样本点,粉色点是属于b类型的样本点。此时新来了一个点(黄色点),怎么判断是属于它是a类型还是b类型呢。
方法是:新点找距离自身最近的k个点(k可变)。分别计算新点到其他各个点的距离,按距离从小到大排序,找出距离自身最近的k个点。统计在这k个点中,有多少点属于a类,有多少点属于b类。在这k个点中,如果属于b类的点更多,那么这个新点也属于b分类。距离计算公式也是我们熟悉的勾股定理。

1.2 算法优缺点
算法优点:简单易理解、无需估计参数、无需训练。适用于几千-几万的数据量。
算法缺点:对测试样本计算时的计算量大,内存开销大,k值要不断地调整来达到最优效果。k值取太小容易受到异常点的影响,k值取太多产生过拟合,影响准确性。
2. 红酒数据集
2.1 数据集获取方式
红酒数据集是Scikit-learn库中自带的数据集,我们只需要直接调用它,然后打乱它的顺序来进行我们自己的分类预测。首先我们导入Scikit-learn库,如果大家使用的是anaconda的话,这个库中的数据集都是提前安装好了的,我们只需要调用它即可。
找不到这个数据集的,我把红酒数据集连接放在文末了,有需要的自取。
Scikit-learn数据集获取方法:
(1)用于获取小规模数据集,数据集已在系统中安装好了的
sklearn.datasets.load_数据名()
from sklearn import datasets
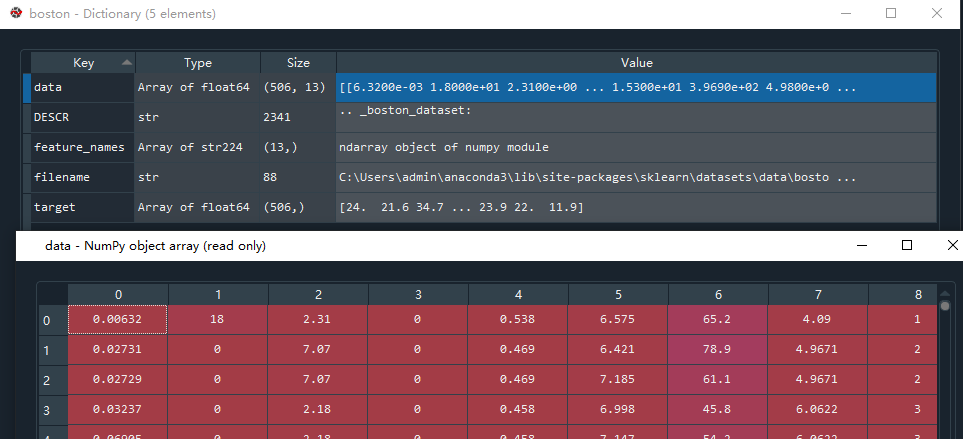
#系统中已有的波士顿房价数据集
boston = datasets.load_boston()
(2)远程获取大规模数据集安装到本地,data_home默认是位置是/scikit_learn_data/
sklearn.datasets.fetch_数据名(data_home = 数据集下载目录)
# 20年的新闻数据下载到
datasets.fetch_20newsgroups(data_home = './newsgroups.csv') #指定文件位置
这两种方法返回的数据是 .Bunch类型,它有如下属性:
data:特征数据二维数组;相当于x变量
target:标签数组;相当于y变量
DESCR:数据描述
feature_names:特征名。新闻数据、手写数据、回归数据没有
target_name:标签名。回归数据没有
想知道还能获取哪些数据集的同学,可去下面这个网址查看具体操作:
https://sklearn.apachecn.org/#/docs/master/47
2.2 获取红酒数据
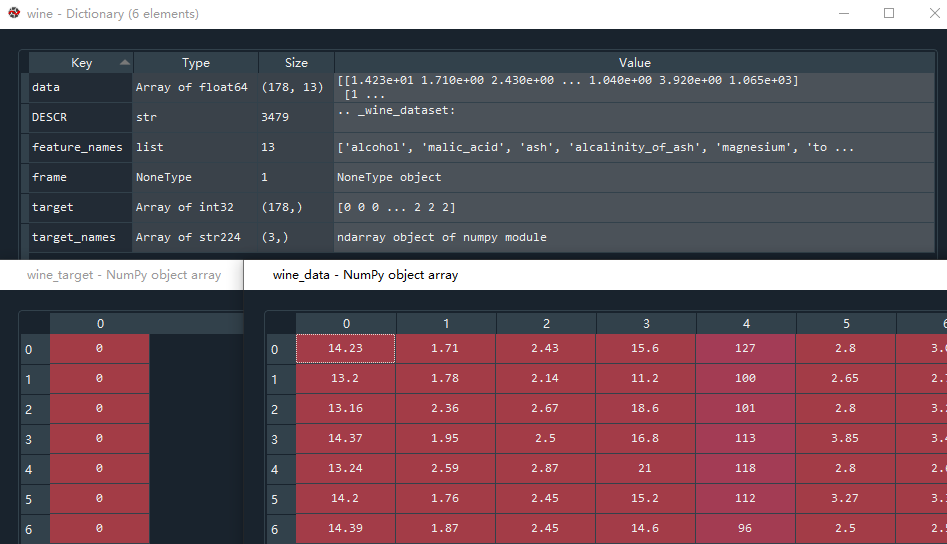
首先导入sklearn的本地数据集库,变量wine获取红酒数据,由于wine接收的返回值是.Bunch类型的数据,因此我用win_data接收所有特征值数据,它是178行13列的数组,每一列代表一种特征。win_target用来接收所有的目标值,本数据集中的目标值为0、1、2三类红酒。如果大家想更仔细的观察这个数据集,可以通过wine.DESCR来看这个数据集的具体描述。
然后把我们需要的数据转换成DataFrame类型的数据。为了使预测更具有一般性,我们把这个数据集打乱。操作如下:
from sklearn import datasets
wine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值# 将数据转换成DataFrame类型
wine_data = pd.DataFrame(data = wine_data)
wine_target = pd.DataFrame(data = wine_target)# 将wine_target插入到第一列,并给这一列的列索引取名为'class'
wine_data.insert(0,'class',wine_target)# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序wine = wine_data.sample(frac=1).reset_index(drop=True) #把DataFrame的行顺序打乱
我们取出最后10行数据用作后续的验证预测结果是否正确,这10组数据分出特征值(相当于x)和目标值(相当于y)。剩下的数据也分出特征值features和目标值targets,用于模型训练。剩下的数据中还要划分出训练集和测试集,下面再详述。到此,数据处理这块完成。
#取后10行,用作最后的预测结果检验。并且让index从0开始,也可以不写.reset_index(drop=True)
wine_predict = wine[-10:].reset_index(drop=True)
# 让特征值等于去除'class'后的数据
wine_predict_feature = wine_predict.drop('class',axis=1)
# 让目标值等于'class'这一列
wine_predict_target = wine_predict['class']wine = wine[:-10] #去除后10行
features = wine.drop(columns=['class'],axis=1) #删除class这一列,产生返回值
targets = wine['class'] #class这一列就是目标值
3. 红酒分类预测
3.1 划分测试集和训练集
一般采用75%的数据用于训练,25%用于测试,因此在数据进行预测之前,先要对数据划分。
划分方式:
使用sklearn.model_selection.train_test_split 模块进行数据分割。
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=数据占比)
train_test_split() 括号内的参数:
x:数据集特征值(features)
y:数据集目标值(targets)
test_size: 测试数据占比,用小数表示,如0.25表示,75%训练train,25%测试test。
train_test_split() 的返回值:
x_train:训练部分特征值
x_test: 测试部分特征值
y_train:训练部分目标值
y_test: 测试部分目标值
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
3.2 数据标准化
由于不同数据的单位不同,数据间的跨度较大,对结果影响较大,因此需要进行数据缩放,例如归一化和标准化。考虑到归一化的缺点:如果异常值较多,最大值和最小值间的差值较大,会造成很大影响。我采用数据标准化的方法,采用方差标准差,使标准化后的数据均值为0,标准差为1,使数据满足标准正态分布。
# 先标准化再预测
from sklearn.preprocessing import StandardScaler #导入标准化缩放方法
scaler = StandardScaler() #变量scaler接收标准化方法
# 传入特征值进行标准化
# 对训练的特征值标准化
x_train = scaler.fit_transform(x_train)
# 对测试的特征值标准化
x_test = scaler.fit_transform(x_test)
# 对验证结果的特征值标准化
wine_predict_feature = scaler.fit_transform(wine_predict_feature)
3.3 K近邻预测分类
使用sklearn实现k近邻算法
from sklearn.neighbors import KNeighborsClassifier
KNeighborsClassifier(n_neighbors = 邻居数,algorithm = '计算最近邻居算法')
.fit(x_train,y_train)
KNeighborsClassifier() 括号内的参数:
n_neighbors:int类型,默认是5,可以自己更改。(找出离自身最近的k个点)
algorithm:用于计算最近邻居的算法。有:'ball_tree'、'kd_tree'、'auto'。默认是'auto',根据传递给fit()方法的值来决定最合适的算法,自动选择前两个方法中的一个。
from sklearn.neighbors import KNeighborsClassifier #导入k近邻算法库
# k近邻函数
knn = KNeighborsClassifier(n_neighbors=5,algorithm='auto')
# 把训练的特征值和训练的目标值传进去
knn.fit(x_train,y_train)
将训练所需的特征值和目标值传入.fit()方法之后,即可开始预测。首先利用.score()评分法输入用于测试的特征值和目标值,来看一下这个模型的准确率是多少,是否是满足要求,再使用.predict()方法预测所需要的目标值。
评分法:根据x_test预测结果,把结果和真实的y_test比较,计算准确率
.score(x_test, y_test)
预测方法:
.predict(用于预测的特征值)
# 评分法计算准确率
accuracy = knn.score(x_test,y_test)
# 预测,输入预测用的x值
result = knn.predict(wine_predict_feature)
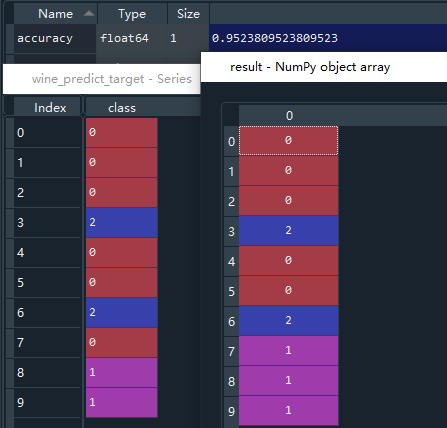
accuracy存放准确率,result存放预测结果,最终准确率为0.952,最终的分类结果和wine_predict_target存放的实际分类结果有微小偏差。
完整代码如下:
import pandas as pd
from sklearn import datasetswine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值wine_data = pd.DataFrame(data = wine_data) #转换成DataFrame类型数据
wine_target = pd.DataFrame(data = wine_target)
# 将target插入到第一列
wine_data.insert(0,'class',wine_target)# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序,可以省略这一步
wine = wine_data.sample(frac=1).reset_index(drop=True)# 拿10行出来作验证
wine_predict = wine[-10:].reset_index(drop=True)
wine_predict_feature = wine_predict.drop('class',axis=1) #用于验证的特征值,输入到predict()函数中
wine_predict_target = wine_predict['class'] #目标值,用于和最终预测结果比较wine = wine[:-10] #删除后10行
features = wine.drop(columns=['class'],axis=1) #删除class这一列,产生返回值,这个是特征值
targets = wine['class'] #class这一列就是目标值
# 相当于13个特征值对应1个目标# 划分测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)# 先标准化再预测
from sklearn.preprocessing import StandardScaler #导入标准化缩放方法
scaler = StandardScaler() #变量scaler接收标准化方法# 传入特征值进行标准化
x_train = scaler.fit_transform(x_train) #对训练的特征值标准化
x_test = scaler.fit_transform(x_test) #对测试的特征值标准化
wine_predict_feature = scaler.fit_transform(wine_predict_feature)# 使用K近邻算法分类
from sklearn.neighbors import KNeighborsClassifier #导入k近邻算法库
# k近邻函数
knn = KNeighborsClassifier(n_neighbors=5,algorithm='auto')# 训练,把训练的特征值和训练的目标值传进去
knn.fit(x_train,y_train)
# 检测模型正确率--传入测试的特征值和目标值
# 评分法,根据x_test预测结果,把结果和真实的y_test比较,计算准确率
accuracy = knn.score(x_test,y_test)
# 预测,输入预测用的x值
result = knn.predict(wine_predict_feature)





![[Linux] ssh远程访问及控制](https://img-blog.csdnimg.cn/4a2e4ebfc4ce4f4691698fcd442a9f75.png)