文章目录
- 一、表查询数据准备及测试环境搭建
- 模型层前期准备
- 测试环境搭建
- 代码演示
- 二、ORM操作相关方法
- 三、ORM常见的查询关键字
- 四、ORM底层SQL语句
- 五、双下划线查询
- 数据查询(双下划线)
- 双下划线小训练
- Django ORM __双下划线细解
- 六、ORM外键字段创建
- 基础表的准备
- 模型表创建一对一、一对多和多对多的实例
- 多对多三种创建方法的补充
- 七、外键字段的相关操作
- 八、正反向概念
- 九、ORM跨表查询
- 基于对象的跨表查询(子查询)
- 基于双下划线的跨表查询(联表查询)
- 聚合查询
- 分组查询
- F与Q查询
一、表查询数据准备及测试环境搭建
模型层前期准备
使用django ORM要注意
-
django自带的sqlite3数据可对时间字段不敏感,有时候会展示错乱,所以我们习惯切换成常见的数据库比如MySQL。
-
django ORM并不会自动帮我们创建库,所以需要提前准备好’‘数据库’’
-
id字段是自动添加的,如果想自定义主键,只需要在其中一个字段指定primary_key = True,如果Django发现你已经明确地设置了Field.primary_key,它将不会添加自动ID列。
-
Django支持MySQL5.5及更高版本。
测试环境搭建
我们需要新建一个Django项目,为了便于我们更加方便操作模型层,有两种方式可以直接调用到模型层。
方式一:在Django自带的测试环境
pycharm提供的python console(临时保存,不推荐使用)

方式二:在项目内的任意py文件内,推荐在应用下面的一个tests.py文件进行
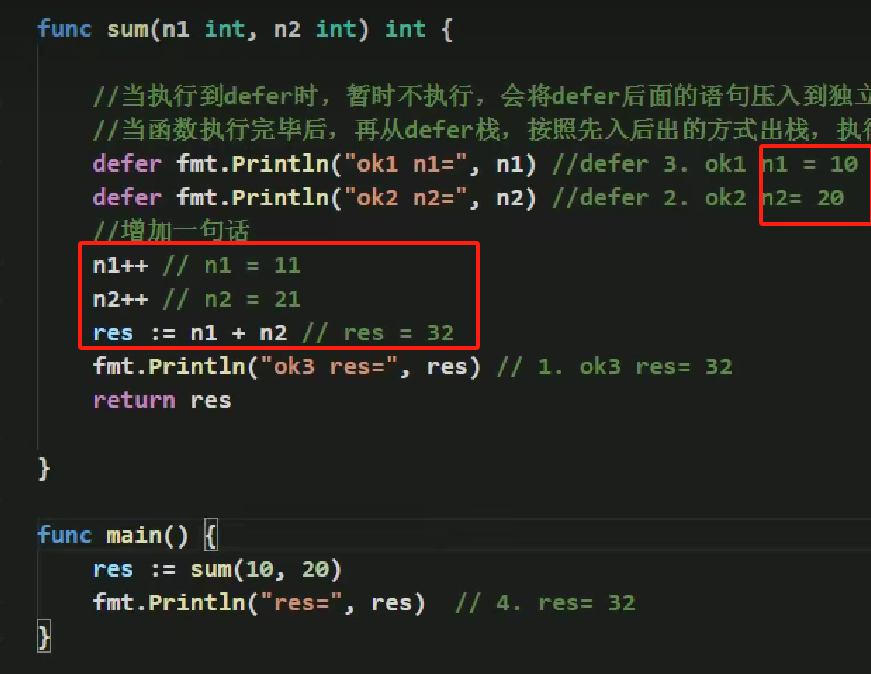
import osif __name__ == "__main__":# 注意:mysite.settings修改成自己的!!项目名.settingsos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Ku.settings')import djangodjango.setup() # 以独立的方式运行Django程序# 以下编辑我们需要的代码:
代码演示
测试test.py
import osif __name__ == "__main__":# 注意:mysite.settings修改成自己的!!项目名.settingsos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Ku.settings')import djangodjango.setup() # 以独立的方式运行Django程序from app import modelsmodels.UserInfo.objects.all()
models.py
class UserInfo(models.Model):uid = models.AutoField(primary_key=True)name = models.CharField(max_length=32,verbose_name='用户名')age = models.IntegerField(verbose_name='年龄')register_time = models.DateTimeField(verbose_name='注册事件',auto_now_add=True)'''DateField : 年月日DateTimeField : 年月日 时分秒两个重要参数auto_now : 每次操作数据的时候 该字段会自动将当前时间更新 auto_now_add : 在创建数据的时候会自动将当前创建时间记录下来 之后只要不人为的修改 那么就一直不变''' def __str__(self):return self.name
切换MySQL数据库
1.提前终端创建好库list_user2.将DATABASES的配置更改DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'list_user','USER':'root',#'PASSWORD':'', 因为我的mysql用户没有设置密码所以这里就不需要写了'HOST':'127.0.0.1','PORT':3306,'CHARSET':'utf8'}}3.连接MySQL库4.python38 manage.py makemigrations5.python38 manage.py migrate
如何查看django ORM 底层原理?
django ORM本质还是SQL语句。
1.如果有QuerySet对象,那么可以直接点query查看SQL语句
res = models.UserInfo.objects.filter(name='jack')print(res)print(res.query)#SELECT `app_userinfo`.`uid`, `app_userinfo`.`name`, `app_userinfo`.`age`, `app_userinfo`.`register_time` FROM `app_userinfo` WHERE `app_userinfo`.`name` = jack
结论:有些不是QuerySet对象,就不能通过点query的形式点出来,就只能使用通过的方法
2.如果想查看所有ORM底层的SQL语句,也可以直接在配置文件添加日志记录
res1 = models.User.objects.create(name='jack',age=18)
print(res.query) # 会报错settings最后>>>拷贝代码放在settingsLOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},}
}
二、ORM操作相关方法
模型层之ORM常见关键字
基础的增删改查
| 方法 | 返回值 |
|---|---|
| create(字段名=数据) | 刚创建的数据记录对象 |
| filter(筛选条件) | QuerySet列表对象 |
| filter().update(修改内容) | 受影响的行数 |
| filter().delete() | 受影响的行数即各表受影响的行数 |
三、ORM常见的查询关键字
1.当需要查询数据主键字段值的时候 可以使用pk忽略掉数据字段真正的名字2.在模型类中可以定义一个__str__方法 便于后续数据对象被打印展示的是查看方便3.Queryset中如果是列表套对象那么直接for循环和索引取值但是索引不支持负数4.虽然queryset支持索引但是当queryset没有数据的时候索引会报错 推荐使用first
1.create 创建数据并直接获取当前创建的数据对象
res = models.UserInfo.objects.create(name='jack',age=18)print(res)res1 = models.UserInfo.objects.create(name='tom',age=19)print(res1)res2 = models.UserInfo.objects.create(name='oscar',age=20)print(res2)res3 = models.UserInfo.objects.create(name='ankn',age=22)print(res3)
2.filter() 根据条件筛选数据 结果是QuerySet [数据对象1,数据对象2]
res4 = models.UserInfo.objects.filter() res5 = models.UserInfo.objects.filter(name='jack') res6 = models.UserInfo.objects.filter(name='tom',age=19) print(res4) #<QuerySet [<UserInfo: jack>, <UserInfo: tom>, <UserInfo: oscar>, <UserInfo: ankn>]>print(res5) #<QuerySet [<UserInfo: jack>]>print(res6) #<QuerySet [<UserInfo: tom>]>
3.first()/last() QuerySet支持索引取值但是只支持正数 并且orm不建议你使用索引
res7 = models.UserInfo.objects.filter()[1] res10 = models.UserInfo.objects.filter(uid=100)[0] # 数据不存在索引取值会报错res8 = models.UserInfo.objects.filter(uid=100).filter() # 数据不存在不会报错而是返回Noneres9 = models.UserInfo.objects.filter(uid=99).last() # 数据不存在不会报错而是返回Noneprint(res7) # tomprint(res8) # Noneprint(res9) # None
4.update() 更新数据(批量更新)
models.UserInfo.objects.filter().update() # 批量更新models.UserInfo.objects.filter(uid=4).update(9) # 单个删除
5.delete() 删除数据(批量删除)
models.UserInfo.objects.filter().delete() # 批量删除models.UserInfo.objects.filter(id=1).delete() # 单个删除
6.all() 查询所有数据 结果是QuerySet [数据对象1,数据对象2]
res = models.UserInfo.objects.all()print(res)#<QuerySet [<UserInfo: jack>, <UserInfo: tom>, <UserInfo: oscar>, <UserInfo: ankn>]>
7.values() 根据指定字段获取数据 结果是QuerySet [{}},{},{},{}]
res = models.UserInfo.objects.all().values('name')print(res)#<QuerySet [{'name': 'jack'}, {'name': 'tom'}, {'name': 'oscar'}, {'name': 'ankn'}]>res1 = models.UserInfo.objects.filter().values()print(res1)# <QuerySet [{'uid': 1, 'name': 'jack', 'age': 18, 'register_time': datetime.datetime(2023......res2 = models.UserInfo.objects.values()print(res2)# <QuerySet [{'uid': 1, 'name': 'jack', 'age': 18, 'register_time': datetime.datetime(2023......
8.values_list() 根据指定字段获取数据 结果是QuerySet [(),(),(),()]
res = models.UserInfo.objects.all().values_list('name','age')print(res) #<QuerySet [('jack', 18), ('tom', 19), ('oscar', 20), ('ankn', 22)]>
9.distinct() 去重 数据一定要一模一样才可以 如果有主键肯定不行
res = models.UserInfo.objects.values('name','age').distinct()print(res)
10.order_by() 根据指定条件排序 默认是升序 字段前面加负号就是降序
res = models.UserInfo.objects.all().order_by('age')print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: tom>, <UserInfo: oscar>, <UserInfo: ankn>]>
11.get() 根据条件筛选数据并直接获取到数据对象 一旦条件不存在会直接报错 不建议使用
res = models.UserInfo.objects.get(uid=1)print(res) # jackres = models.UserInfo.objects.get(uid=100)print(res) # 报错
12.exclude() 取反操作
res = models.UserInfo.objects.exclude(uid=2)print(res) # <QuerySet [<UserInfo: jack>, <UserInfo: oscar>, <UserInfo: ankn>]>
13.reverse() 颠倒顺序(被操作的对象必须是已经排过序的才可以)
res = models.UserInfo.objects.all().order_by('age') # 升序res1 = models.UserInfo.objects.all().order_by('age').reverse() # 返回升序之前print(res,res1)# <QuerySet [<UserInfo: jack>, <UserInfo: tom>, <UserInfo: oscar>, <UserInfo: ankn>]># <QuerySet [<UserInfo: ankn>, <UserInfo: oscar>, <UserInfo: tom>, <UserInfo: jack>]>
14.count() 统计结果集中数据的个数
res = models.UserInfo.objects.all().count()print(res) # 4
15.exists() 判断结果集中是否含有数据 如果有则返回True 没有则返回False
res = models.UserInfo.objects.all().exists() # 报错res1 = models.UserInfo.objects.filter(uid=100).exists()print(res1) # False
基础方法总结
1、返回QuerySet对象的方法有(大多通过模型类.objects.方法调用)
QuerySet对象形似存储了一个个记录对象的列表,但拥有一些特殊的属性,如query。
| 名称 | 语法 | 说明 |
|---|---|---|
| filter | res1 = models.User.objects.filter(name=‘Like’, age=20) | 筛选数据 返回值是一个QuerySet(可以看成是列表套数据对象)括号内不写查询条件 默认就是查询所有括号内可以填写条件 并且支持多个 逗号隔开 默认是and关系 |
| all | res2 = models.User.objects.all() | 查询所有数据 返回值是一个QuerySet(可以看成是列表套数据对象) |
| first | res3 = models.User.objects.first() | 获取Queryset中第一个数据对象 如果为空则返回None |
| last | res4 = models.User.objects.last() | 获取Queryset中最后一个数据对象 如果为空则返回None |
| get | res5 = models.User.objects.get(pk=2) | 直接根据条件查询具体的数据对象 但是条件不存在直接报错 不推荐使用 |
| values | res6 = models.User.objects.values(‘name’, ‘age’) | 指定查询字段 结果是Queryset(可以看成是列表套字典数据) |
| values_list | res7 = models.User.objects.values_list() | 指定全部字段 结果是Queryset(可以看成是列表套元组数据) |
| order_by | res8 = models.User.objects.order_by(‘age’) 升序,res8_1 = models.User.objects.order_by(‘-age’, ‘name’)降序 | 指定字段排序 默认是升序 在字段前加负号则为降序 并且支持多个字段排序 |
| count | res9 = models.User.objects.count() | 统计orm查询之后结果集中的数据格式 |
| distinct | res10 = models.User.objects.values(‘name’, ‘age’).distinct() | 针对重复的数据集进行去重 一定要注意数据对象中的主键 |
| exclude | res11 = models.User.objects.exclude() | 针对括号内的条件取反进行数据查询 QuerySet(可以看成是列表套数据对象) |
| reverse | res12 = models.User.objects.all().order_by(‘age’).reverse() | 针对已经排了序的结果集做颠倒 |
| exists | res13 = models.User.objects.exists() | 判断查询结果集是否有数据 返回布尔值 但是几乎不用因为所有数据自带布尔值 |
| raw | res14 = models.User.objects.raw(‘select * from app01_user’) | 执行SQL语句 |
四、ORM底层SQL语句
我们现在知道了怎么查询数据了但是它的底层语句逻辑是什么呢?方式1:如果是Queryset对象 那么可以直接点Ctrl+左键点击query查看SQL语句方式2:需要到配置文件Settings中找一个空白位置复制一下代码 主要作用打印所有ORM操作对应的SQL语句LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console':{'level':'DEBUG','class':'logging.StreamHandler',},},'loggers': {'django.db.backends': {'handlers': ['console'],'propagate': True,'level':'DEBUG',},}}
五、双下划线查询
结果对象还是query对象就可以无限制的点queryset对象的方法。
queryset.filter().values().filter().values_list().filter()....
django中将字段后加上__条件的方式让关键字参数拥有除等号外的其他含义。
数据查询(双下划线)
| __gt | 大于 |
|---|---|
| __lt | 小于 |
| __gte | 大于等于 |
| __lte | 小于等于 |
| __in | 类似于成员运算,在…里面 |
| __range | 在什么范围之内 |
| __contains | 是否含有,区分大小写 ,模糊查询 |
| __icontains | 是否含有,不区分大小写 ,模糊查询 |
| __year | 查询年份 |
| __day | 查询日期天数 |
| __second/minute | 查看秒/分 |
双下划线小训练
数据表提前准备好
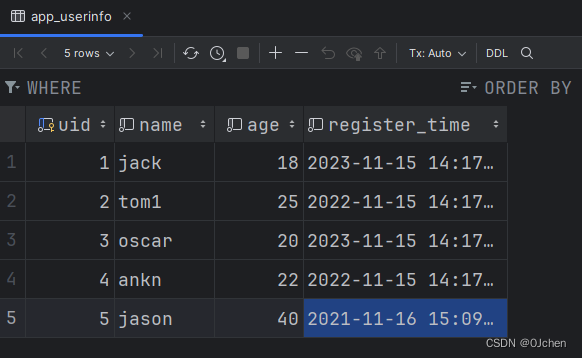
1.查询年龄大于18的用户数据
'''sql语句'''# select * form userinfo where age>18;res = models.UserInfo.objects.filter(age__gt=18)print(res)# <QuerySet [<UserInfo: tom1>, <UserInfo: oscar>, <UserInfo: ankn>, <UserInfo: jason>]>
2.查询年龄小于38的用户数据
'''sql语句'''# select * form userinfo where age<38;res = models.UserInfo.objects.filter(age__lt=38)print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: tom1>, <UserInfo: oscar>, <UserInfo: ankn>]>
3.查询年龄大于等于38的用户数据
'''sql语句'''# select * form userinfo where age>=38;res = models.UserInfo.objects.filter(age__gte=38)print(res)# <QuerySet [<UserInfo: jason>]>
4.查询年龄小于等于38的用户数据
'''sql语句'''# select * form userinfo where age<=38;res = models.UserInfo.objects.filter(age__lte=38)print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: tom1>, <UserInfo: oscar>, <UserInfo: ankn>]>
5.查询年龄是18或者20或者38的数据
'''sql语句'''# select * form userinfo where age=18 or age=20 or age=38;res = models.UserInfo.objects.filter(age__in=[18,20,38])print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: oscar>]>
6.查询年龄在18到38范围之间的用户数据
'''sql语句'''# select * form userinfo where age>=18 and age<=38;res = models.UserInfo.objects.filter(age__range=[18,38])print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: tom1>, <UserInfo: oscar>, <UserInfo: ankn>]>
7.查询名字中含有字母j的用户数据
'''sql语句'''# select * form userinfo where name like '%j%';1.区分大小写res = models.UserInfo.objects.filter(name__contains='j')print(res)# <QuerySet [<UserInfo: jack>, <UserInfo: jason>]>2.不区分大小写res = models.UserInfo.objects.filter(name__icontains='j')
8.查询注册年份是2022的数据
res = models.UserInfo.objects.filter(register_time__year='2022')print(res)# <QuerySet [<UserInfo: tom1>, <UserInfo: ankn>]>
Django ORM __双下划线细解
exact:精确匹配,例如 Book.objects.filter(title__exact='Django') 将返回所有标题为 'Django' 的书籍。
iexact:不区分大小写的精确匹配,例如 Book.objects.filter(title__iexact='django') 将返回所有标题为 'django' 或 'Django' 的书籍。
contains:包含匹配,例如 Book.objects.filter(title__contains='Django') 将返回所有标题中包含 'Django' 的书籍。
icontains:不区分大小写的包含匹配,例如 Book.objects.filter(title__icontains='django') 将返回所有标题中包含 'django' 或 'Django' 的书籍。
in:范围匹配,例如 Book.objects.filter(id__in=[1, 2, 3]) 将返回 ID 为 1、2 或 3 的书籍。
gt:大于匹配,例如 Book.objects.filter(price__gt=10) 将返回价格大于 10 的书籍。
lt:小于匹配,例如 Book.objects.filter(price__lt=10) 将返回价格小于 10 的书籍。
gte:大于等于匹配,例如 Book.objects.filter(price__gte=10) 将返回价格大于等于 10 的书籍。
lte:小于等于匹配,例如 Book.objects.filter(price__lte=10) 将返回价格小于等于 10 的书籍。
startswith:以指定字符串开头匹配,例如 Book.objects.filter(title__startswith='Django') 将返回标题以 'Django' 开头的书籍。
istartswith:不区分大小写的以指定字符串开头匹配,例如 Book.objects.filter(title__istartswith='django') 将返回标题以 'django' 或 'Django' 开头的书籍。
endswith:以指定字符串结尾匹配,例如 Book.objects.filter(title__endswith='Django') 将返回标题以 'Django' 结尾的书籍。
iendswith:不区分大小写的以指定字符串结尾匹配,例如 Book.objects.filter(title__iendswith='django') 将返回标题以 'django' 或 'Django' 结尾的书籍。
range:范围匹配,例如 Book.objects.filter(price__range=[10, 20]) 将返回价格在 10 到 20 之间的书籍。
date:日期匹配,例如 Book.objects.filter(publish_date__date=date(2021, 8, 1)) 将返回发行日期为 2021 年 8 月 1 日的书籍。
year:年份匹配,例如 Book.objects.filter(publish_date__year=2021) 将返回发行日期为 2021 年的书籍。
month:月份匹配,例如 Book.objects.filter(publish_date__month=8) 将返回发行日期为 8 月的书籍。
day:日期匹配,例如 Book.objects.filter(publish_date__day=1) 将返回发行日期为 1 日的书籍。
hour:小时匹配,例如 Book.objects.filter(publish_time__hour=10) 将返回发布时间为上午 10 点的书籍。
minute:分钟匹配,例如 Book.objects.filter(publish_time__minute=30) 将返回发布时间为 30 分钟的书籍。
second:秒匹配,例如 Book.objects.filter(publish_time__second=0) 将返回发布时间为整点的书籍。
isnull:为空匹配,例如 Book.objects.filter(author__isnull=True) 将返回没有作者的书籍。
六、ORM外键字段创建
跟MySQL外键关系一样的判断规律
1.一对多 外键字段建立在多的一方2.多对多 外键字段建立在第三张表中3.一对一 建立在任何一方都可以,但是建议建立在操作频率高的一张表中注意:目前关系的判断可以采用表与表之间换位思考原则
基础表的准备
- 创建基础表(书籍表、出版社表、作者表、作者详情表)
- 确定外键关系
一对一 ORM与MySQL一致,外键字段建立在查询频率较高的一方一对多 ORM与MySQL一致,外键建立在多的一方多对多 ORM比MySQL有更多的变化1.外键字段可以之间建在某张表中(查询频率较高的)内部会自动帮你创建第三张关系表2.自己创建的三张关系表并创建外键字段后续讲解
- ORM创建
针对一对多和一对一同步到表中之后自动
_id的后缀,如book中建立的外键字段名publish,会自动变成publish_id。
1.一对多关系publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE) 在多的表中建立外键字段,会在表中产生一个实际的字段(自动加'_id后缀')2.一对一author_detail = models.OneToOneField(to='AuthorDetail',on_delete=models.CASCADE)在查询频率较高的表中建立外键字段,会在表中产生一个实际的字段(自动加'_id后缀')django1.x 针对外键的创建后的同步,是无需级联更新级联删除的,(on_delete = models.CASCADE)django2.x 3.x则需要添加on_delete参数
针对多对多,不会在表中有展示,而是自动创建第三张表
1.多对多authors = models.ManyToManyField(to='Author')在查询频率较高的表中建立外键字段(ORM自动创建的,也可自己创建)不会在表中产生实际的字段,而是告诉ORM创建第三张关系表。
模型表创建一对一、一对多和多对多的实例

需要注意的事项:
1.创建一对多关系
和sql语句一样,外键建立到多的那张表上,不同的是,我们可以不讲究关联表和被关联表的建立顺序。字段类为ForeignKey在django2.x版本以上,建立一对多关系时需要指定on_delete参数为CASCADE,不加会报错,不过也不一定就是CASCADE,可能为其他实参,这里不展开。建立外键时,系统会自动加上_id后缀作为字段名。2.创建多对多关系
sql中是将两张表建立好后,将外键字段创建在第三张表中,而django为我们省去了这一步骤,我们可以在多对多关系双方的一个模型表中直接建立一个虚拟外键,ManyToManyField在底层,sql依旧创建了第三张表来存储两表的多对多关系,但是在orm操作中我们就可以将模型表中的外键当做实实在在的联系,因为在查询时,我们感受不到第三张的表的存在。多对多关系的外键没有on_delete关键字参数。3.创建一对多关系
一对一的字段类为OneToOneField,建议建立在查询频率高的一方。建立一对一关系时需要指定on_delete参数,否则报错。
多对多三种创建方法的补充
注意:多对多关系这种虚拟外键才有add、set、clear、remove,一对一和一对多的表是无法使用这些方法
1.全自动创建
class Book(models.Model):title = models.CharField(max_length=32)authors=models.ManyToManyField(to='Author')class Author(models.Model):name = models.CharField(max_length=32)
优势:自动创建第三张表,并且提供了add、remove、set、clear四种操作
劣势:第三张表无法创建更多的字段,扩展性较差。如果我们有一些业务逻辑就是在关系表上,我们就无法通过第三张表完成了。
2.纯手动创建
class Book(models.Model):title = models.CharField(max_length=32)class Author(models.Model):name = models.CharField(max_length=32)class Book2Author(models.Model):book=models.ForeignKey(to='Book')author= models.ForeigKey(to='Author')others=models.CharField(max_length=32)join_time = models.DataField(auto_now_add=True)
优势:第三张表完全由自己创建,扩展性强
劣势:编写繁琐,并不支持add、remove、set、clear以及正反向概念。
3.半自动创建
class Book(models.Model):title = models.CharField(max_length=32)authors = models.ManyToManyField(to='Author',through='Book2Author',through_fields=('book','author')# 外键在哪个表就把book表放前面)class Author(models.Model):name = models.CharField(max_length=32)class Book2Author(models.Model):book = models.ForeignKey(to='Book', on_delete=models.CASCADE)author = models.ForeignKey(to='Author', on_delete=models.CASCADE)others = models.CharField(max_length=32)join_time = models.DateField(auto_now_add=True)
优势:第三张表完全由自己创建,扩展性强,正反向概念依然可以使用
劣势:编写繁琐,并不支持add、remove、set、clear。
七、外键字段的相关操作
数据的创建
基本数据:提前将Publish,author以及authordetail三个表的数据信息录入,Book以及关系的绑定在下面详细介绍
一对多和一对一实际外键字段的绑定
1.外键关联的实际字段
针对一对多,插入数据可以直接填写表中的实际字段
'''先创建未存储外键字段的表数据'''# models.Publish.objects.create(name='星海出版社',address='澳门')# models.Publish.objects.create(name='上海出版社',address='上海')# models.Publish.objects.create(name='北京出版社',address='北京')models.Book.objects.create(title='Python从入门到放弃',price='233.1',publish_id=1)models.Book.objects.create(title='Python爬虫从入门到入狱',price='666.6',publish_id=1)models.Book.objects.create(title='MySQL从入门到删库跑路',price='555.5',publish_id=2)models.Book.objects.create(title='论如何开启重启人生',price='999.9',publish_id=3)
2.外键的关联对象
针对一对多,插入数据也可以填写表中的类中字段名
publish_obj = models.Publish.objects.filter(pk=3).first()print(publish_obj)models.Book.objects.create(title='老人与海',price='111.1',publish_id=publish_obj.id)
3.一对一与一对多插入数据的方式是一致的
关于多对多关系外键字段的绑定
多对多外键属于实际不在模型表中的虚拟字段,多对多关系则需要django提供给我们的方法来实现增删改关系。拿到设立多对多外键的模型表的对象,用它点出外键属性,可以进行add、set、remove方法,这些方法都是这条记录对象的操作。
数据的增加add
语法:book_obj.authors.add() # 对象.外键.add()add可以通过关联的id或者关联的对象进行绑定关系book_obj = models.Book.objects.filter(pk=3).first()1.书与作者一对一绑定book_obj.authors.add(1) # 在第三张关系表中给当前书籍绑定作者2.书与作者一对多绑定book_obj.authors.add(2,3)3.作者对象与书对象的绑定book_obj = models.Book.objects.filter(pk=4).first()author_obj1 =models.Author.objects.filter(pk=2).first()author_obj2 =models.Author.objects.filter(pk=3).first()# book_obj.authors.add(author_obj1) # 可以添加一个作者对象book_obj.authors.add(author_obj1,author_obj2) # 也可同时添加两个作者对象总结:add(1) add(1,2) add(obj1) add(obj1,obj2)
数据的修改set
语法:book_obj.authors.set() # 对象.外键.set()set可以通过关联的id或者关联的对象进行修改绑定关系4.绑定错误,如何修改使用set修改关系""" 通过id修改的"""book_obj = models.Book.objects.filter(pk=4).first()book_obj.authors.set((1,3)) # set括号里面只能填写一个可跌倒对象()/[]或者对象""" 原本id=4的书籍绑定的是作者2和作者3,通过set修改数据信息后绑定的是作者1和作者3"""book_obj.authors.set([2,4])"""通过对象修改的"""book_obj = models.Book.objects.filter(pk=2).first()book_obj.authors.add(1,2,4)""" id=2的书绑定了作者1,作者2和作者4"""book_obj = models.Book.objects.filter(pk=2).first()author_obj1=models.Author.objects.filter(pk=1).first()author_obj2=models.Author.objects.filter(pk=2).first()author_obj4=models.Author.objects.filter(pk=4).first()book_obj.authors.set((author_obj1,author_obj2))""" id=2的书由绑定的作者1,作者2和作者4修改为作者1和作者4"""book_obj.authors.set((author_obj1,author_obj2,author_obj4))""" 通过修改,id=2的书还是绑定了作者1,作者2和作者4"""总结set((1,)) set((1,2)) set((obj1,)) set((obj1,obj2))
数据的删除remove
语法:book_obj.authors.remove() # 对象.外键.remove()remove可以通过关联的id或者关联的对象进行移除绑定关系5.数据的删除book_obj= models.Book.objects.filter(pk=1).first()author_obj1= models.Author.objects.filter(pk=1).first()author_obj2= models.Author.objects.filter(pk=2).first()""" 通过id去删除"""book_obj.authors.remove(2) # 作者2#book_obj.authors.remove(1,3)""" 通过作者对象去删除"""book_obj.authors.remove(author_obj1) # 作者1#book_obj.authors.remove(author_obj1,author_obj2)总结:remove(1) remove(1,2) remove(obj1) remove(obj1,obj2)add()\remove() 多个位置参数(数字 对象)set() 可迭代对象(元组 列表) 数字 对象 clear() 情况当前数据对象的关系 ,不需要传参数
数据的清空 clear
语法:book_obj.authors.clear() # 对象.外键.clear()clear() 直接清空与book的id为1关联的所有作者""" 清空主键为1的绑定关系"""book_obj = models.Book.objects.filter(pk=1).first()book_obj.authors.clear()
八、正反向概念
'正反向的概念核心就在于外键字段在谁手上'外键在自己手上则是正向查询外键在别人手上则是反向查询正向查询通过书查询出版社 外键字段在书表中反向查询通过出版社查询书 外键字段不在出版社表中ORM跨表查询口诀>>>:正向查询按外键字段 反向查询按表名小写
九、ORM跨表查询
MySQL跨表查询的思路
1.子查询分步操作:将一条SQL语句用括号括起来当做另外一条SQL语句的条件2.连表操作先整合多张表之后基于单表查询即可inner join 内连接left join 左连接right join 右连接
基于对象的跨表查询(子查询)
数据准备
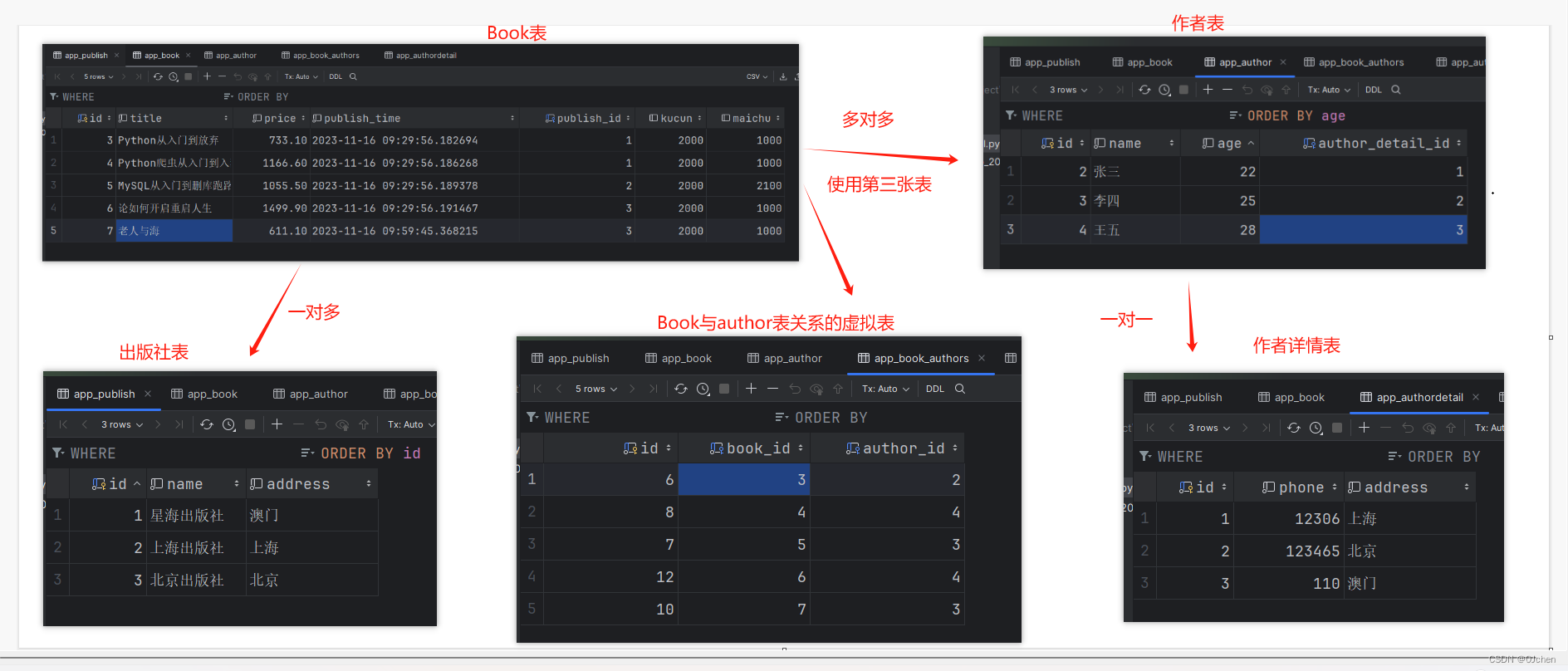
步骤:
- 先根据条件获取数据对象
- 判断正反向查询(正向查询按外键,反向查询按表名小写)
1.查询书籍主键为3的出版社# 书查询出版社表 正向 按照外键字段book_obj = models.Book.objects.filter(pk=3).first()print(book_obj.publish.name)print(book_obj.publish.address)2.查询书籍主键为2的作者# 书查询作者 正向 按照外键字段res = models.Book.objects.filter(pk=5).first()print(res.title)print(res.authors)print(res.authors.all())3.查询作者李四的电话号码# 作者查询作者详情 正向 按照外键字段res = models.Author.objects.filter(name='李四').first()print(res.author_detail.phone)"""在书写orm语句的时候跟写sql语句一样的不要企图一次性将orm语句写完 如果比较复杂 就写一点看一点正向什么时候需要加.all()当你的结果可能有多个的时候就需要加.all()如果是一个则直接拿到数据对象book_obj.publishbook_obj.authors.all()author_obj.author_detail"""4.查询出版社是上海出版社出版的书# 出版社查询书 反向 表名小写res = models.Publish.objects.filter(name='上海出版社').values('book__title')print(res)5.查询作者是王五写过的书# 作者查询书 反向 按照表名小写res = models.Author.objects.filter(name='王五').values("book__title")print(res)6.查询手机号是110的作者姓名# 作者详情表查询作者 反向 按照表名小写res = models.AuthorDetail.objects.filter(phone=110).select_related("author")for i in res:print(i.author.name)"""基于对象 反向查询的时候当你的查询结果可以有多个的时候 就必须加_set.all()当你的结果只有一个的时候 不需要加_set.all()自己总结出 自己方便记忆的即可 每个人都可以不一样"""
基于双下划线的跨表查询(联表查询)
1.查询李四的手机号和作者姓名res = models.Author.objects.filter(name='李四').values('author_detail__phone','name')print(res)'''反向查询'''res = models.AuthorDetail.objects.filter(author__name='李四').values('phone','author__name')print(res)2.查询书籍主键为4的出版社名称和书的名称# 书查询出版社 正向 外键字段res = models.Book.objects.filter(pk=4).values('publish__name','title')print(res)'''反向查询'''res = models.Publish.objects.filter(book__pk=4).values('book__title','name')print(res)3.查询书籍主键为3的作者姓名# 书查作者 正向 外键字段res = models.Book.objects.filter(pk=3).values('authors__name')print(res)'''反向查询'''res = models.Author.objects.filter(book__id = 3).values('name')print(res)查询书籍主键是5的作者的手机号res = models.Book.objects.filter(pk=5).values('authors__author_detail__phone')print(res)'''反向查询'''res = models.Author.objects.filter(book__id=5).values('author_detail__phone')print(res)"""你只要掌握了正反向的概念以及双下划线那么你就可以无限制的跨表"""
聚合查询
| 函数名 | 描述 |
|---|---|
| Max | 大于 |
| Min | 小于 |
| Sum | 求和 |
| Count | 统计某个数据 |
| Avg | 平均值 |
"""聚合查询通常情况下都是配合分组一起使用的只要是跟数据库相关的模块 基本上都在django.db.models里面如果上述没有那么应该在django.db里面"""如果我们在ORM中使用聚合函数,ORM支持单独使用聚合函数,步骤如下:from django.db.models import Max,Min,Sum,Count,Avg使用关键字aggregate1 所有书的平均价格res = models.Book.objects.aggregate(Avg('price'))print(res)2.上述方法一次性使用res = models.Book.objects.aggregate(Avg('price'),Sum('price'),Min('price'),Max('price'),Count('pk'))print(res)
分组查询
如果执行ORM分组查询报错,并且又关键sql_mode / strict mode ,那么就去移除sql_mode中的only_full_group_by
1.统计每一本书的作者个数res = models.Book.objects.annotate(num_author=Count('authors')).values('title','num_author')'author_num是我们自己定义的字段 用来存储统计出来的每本书对应的作者个数'print(res)2.统计每个出版社卖的最便宜的书的价格res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')print(res)3.统计不止一个作者的图书res=models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title','author_num')print(res)4.查询每个作者出的书的总价格res = models.Author.objects.annotate(book_price=Sum('book__price')).values('name','book_price')print(res)
上述分组都是按照表来分组,我们也可以按照表中的字段名来分组
1.按照表分组models.表名.objects.annotate()2.按照表中字段名来分组models.表名.objects.values('字段名').annotate()eg:res= models.Book.objects.values('publish_id').annotate(count_pk=Count('pk')).values('publish_id','count_pk')print(res)注意:values在annotate前就是按照values()括号里面字段名来分组;values()在annotate后就是按照前面的表名分组,values就是拿值的
F与Q查询
F查询
当查询条件不是很明确的,也需要从数据库中获取,就需要使用F查询。
简单理解:
- 两个字段进行比较的筛选条件(库存数大于卖出数),
- 在原来的数值字段增加数值(500),
- 在原来的字段名后面加字(+爆款)
在上述条件等,我们只借助ORM操作,是实现不了的,我们需要在ORM中就需要借助F方法。
from django.db.models import F 导入模块1.查询卖出数大于库存数的书籍res = models.Book.objects.filter(maichu__gt=F('kucun')).values('title')print(res)2.将所有书籍的价格提升500块models.Book.objects.update(price=F('price')+500)'在操作字符类型的数据的时候 F不能够直接做到字符串的拼接'3.将所有书的名称后面加上爆款两个字from django.db.models.functions import Concatfrom django.db.models import Value# models.Book.objects.update(title=F('title')+'爆款') # 使用F会让所有的名称变为空白models.Book.objects.update(title=Concat(F'title',Value('爆款')))
Q查询
在ORM操作中,筛选条件中存在或、非的关系需要借助Q方法来实现。
| 符号 | 描述 |
|---|---|
| ,(逗号) | and的关系 |
| | | or的关系 |
| ~ | not的关系 |
from django.db.models import Q1.查询卖出数大于1000或者价格小于800的书籍res = models.Book.objects.filter(Q(maichu__gt=1000),Q(price__lt=800)).values('title')'''Q包裹逗号分割 还是and关系'''res = models.Book.objects.filter(Q(maichu__gt=1000)|Q(price__lt=800)).values('title')'''| or关系'''res = models.Book.objects.filter(~(Q(maichu__gt=1000)|Q(price__lt=800))).values('title')'''~ not关系'''# print(res)
Q方法使用总结:
- 两个条件是或关系Q(条件1) | Q(条件2)
- 两个条件是非关系~Q(条件)
Q查询的进阶操作
from django.db.models import Q'Q的高阶用法 能够将查询条件的左边也变成字符串的形式'q = Q() '产生一个Q对象'q.connector='or' '默认是多个条件的连接时and,修改成or'q.children.append(('maichu__gt',1000)) '添加查询条件'q.children.append('price__lt',800) '支持添加多个'res = models.Book.objects.filter(q) '查询文件直接填写Q对象'print(res)