目录
一、什么是数据库索引?
1.1 索引的概念
1.2 索引的特点
1.3 索引的适用场景
1.4 索引的使用
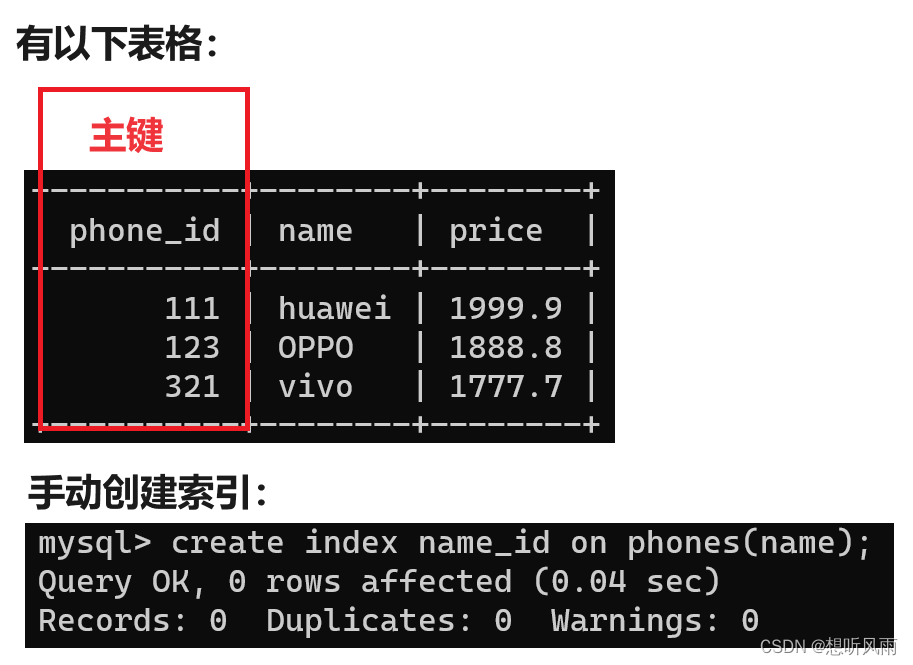
1.4.1 创建索引
1.4.2 查看索引
1.4.3 删除索引
二、数据库索引的底层结构是什么?
2.1 数据库中的 B+树 长啥样?
2.2 B+树为什么适合做数据库索引的底层结构?
一、什么是数据库索引?
1.1 索引的概念
索引(index),与数组下标表示数组中元素的索引值相似,数据库索引也表示了数据表中数据的引用指针,这个指针指向数据表中对应的数据。
可以对数据表中的一列或多列数据创建索引。索引起到类似“书籍目录”的作用,可以用于快速定位和检索数据,对提高数据库性能有较大帮助。
1.2 索引的特点
| (1)可以加快查询速度 |
| 在不使用进行数据库查询时,需要遍历数据来得到查询结果。但是数据库存储介质是硬盘,而不是内存,硬盘的读写比内存慢很多。因此,如果需要提高数据库的查询速度,那么使用索引查询,搭配条件语句筛选数据,减少数据规模,减少硬盘的读写,是一个有效的方式。 |
| (2)索引本身也占据存储空间 |
| 索引本身也是数据,存储索引也需要占用存储空间。 |
| (3)会产生额外的开销 |
| 数据库数据在进行增、删、改时,也需要针对索引进行更新,这就会产生额外的开销。 |
1.3 索引的适用场景
如果数据表中的某列或多列符合以下条件,则可以考虑创建索引以提高查询效率:
| (1)数据量大,查询频高 |
| (2)增、删、改操作频率低 |
| (3)存储空间充足 |
如果不符合以上的条件,创建索引反而可能会拖累数据库的运行效率,此时则不考虑创建索引。
1.4 索引的使用
1.4.1 创建索引
| 创建方式 | 说明 |
| 自动创建 | 在使用主键约束(primary key)、唯一约束(unique)、外键约束(foreign key)时,会自动创建对应列的索引。 |
| 手动创建 | 使用 create index 索引名 on 表名(列名) 的语法进行创建。 |
如果存在大量数据,手动创建索引时则应考虑到触发大量硬盘IO的问题,这将导致服务器在完成该创建语句之前,无法响应其他的操作请求。
1.4.2 查看索引
| 语法 | show index from 表名; |
| 释义 | 展示指定表中的索引。 |

1.4.3 删除索引
| 语法 | drop index from 表名; |
| 释义 | 删除指定表中指定列的索引。 |

二、数据库索引的底层结构是什么?
索引是通过额外的数据结构,针对数据表中的数据进行重新组织。索引保存的数据结构主要为B+树,及hash的方式。
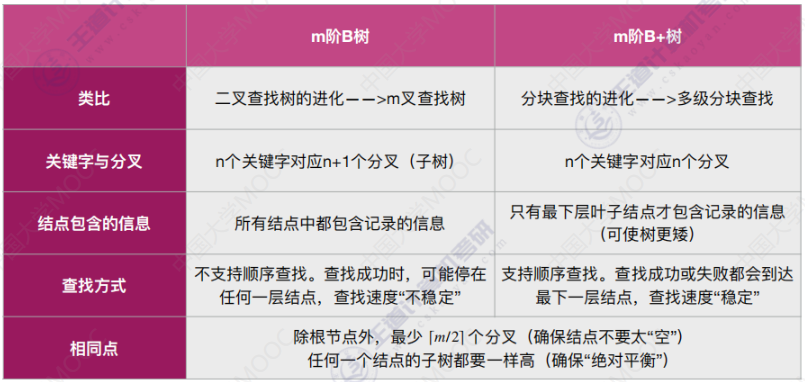
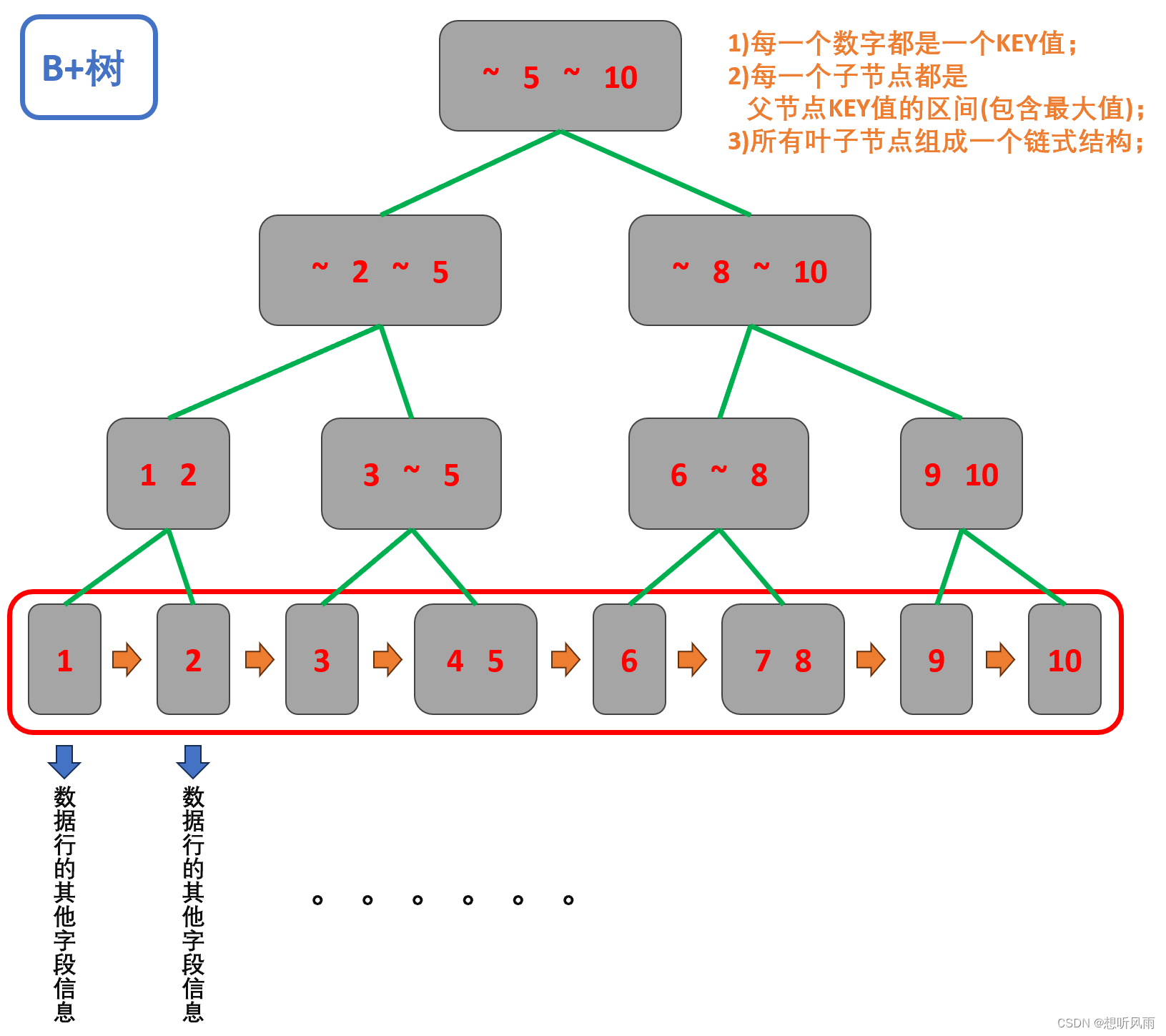
2.1 数据库中的 B+树 长啥样?
2.2 B+树为什么适合做数据库索引的底层结构?
简述B+树的部分特点:
| B+树的特点 | (1)B+树是一棵N叉搜索树,每个节点包含N个KEY,N个KEY划分出N个区间; |
| (2)每个节点的N个KEY值中,有区间内最大值(或最小值); | |
| (3)每个节点中的KEY都会在子树中重复出现; | |
| (4)最终树的叶子节点之间会使用链式结构相连; |
由以上特点可以得出,使用B+树作为数据库索引底层结构存在以下优点:
| (1)避免了查询数据时对树的回溯。 由于每个节点中的KEY都会在子树中重复出现,因此树的叶子节点就是数据的全集。将数据全集使用链式结构连接。此时对数据进行范围查找,则只需要查询一次根节点到叶子节点,再从叶子节点沿着链表向后查找即可,避免了子节点回溯父节点这一复杂过程。 |
| (2)稳定的查询时间。 查询任何元素,从根节点到叶子节点的距离是一致的。这意味着每次查询调用硬盘IO的次数是固定的,查询时间稳定。 |
| (3)充分利用内存进行比较,大幅减少硬盘IO的调用次数。 数据行的数据只存储在叶子节点,而非叶子节点中只保存了KEY值。KEY值只是索引,数据内存占用小,通常可以缓存到内存中,再进行内存比较。内存比较要比调用硬盘IO进行比较效率高许多个数量级,明显提高了查询效率,降低了开销。 |
阅读指针 -> 《MySQL--什么是数据库事务?事务该如何使用?》
链接生成中..........