目录:
- 蒙特卡罗强化学习的问题
- 基于转移的策略评估
- 时序差分评估
- Sarsa-算法
- Q-学习算法
一 蒙特卡罗强化学习的的问题
有模型学习: Bellman 等式
免模型学习: 蒙特卡罗强化学习
迭代:
使用策略
生成一个轨迹,
for t = 0,1,...T-1 do #完成多次采样的动作
: 累积奖赏
求平均累积奖赏作为期望累积奖赏(有模型学习)的近似
1.1 优点:
便于理解
样本数足够时可以保证收敛性
2.2 缺点
状态值的学习互相独立
没有充分状态之间的联系
例4次采样:
B 和 E 状态同样转移到C 状态,但是最后的平均累积奖赏却相差很大

小样本对强化学习最终的结果影响特别大,B和E 都转移到C状态
能否用C 来辅助估计B和E, 这也是有模型学习里面的状态转移概率的思想
如下C 出现的次数最多(大数定理),能否用出现次数多的来辅助估计出现次数少的
值
| 状态 | 更新次数 |
| C | 2 |
| E | 2 |
| B | 2 |
二 基于转移的策略评估
通过策略评估提升我们对策略的评估
(bellman 公式: 即时奖励+转移概率*下一刻状态的累积奖赏)
思路: 采样所有到达的转移做平均
假设采样转移为
则:
跟bellman 很相似,少了转移概率,但是思想一样
如果 s 更高的转移到某个状态,该状态会更高的出现在样本库里面
三 时序差分评估TD
3.1 原理
当我们经历一个从状态s 出发的转移样本的四元组(s,a,s',r) ,更新
转移概率更大的状态s' 的值对s的更新影响更大.
时序差分评估: 将状态值朝着后续出现的状态值靠近
采用滑动平均的方案
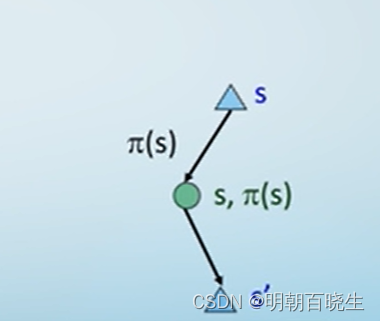
采样:
更新:
(历史的价值函数+ 当前的价值函数)
3.2 总结

3.3 算法
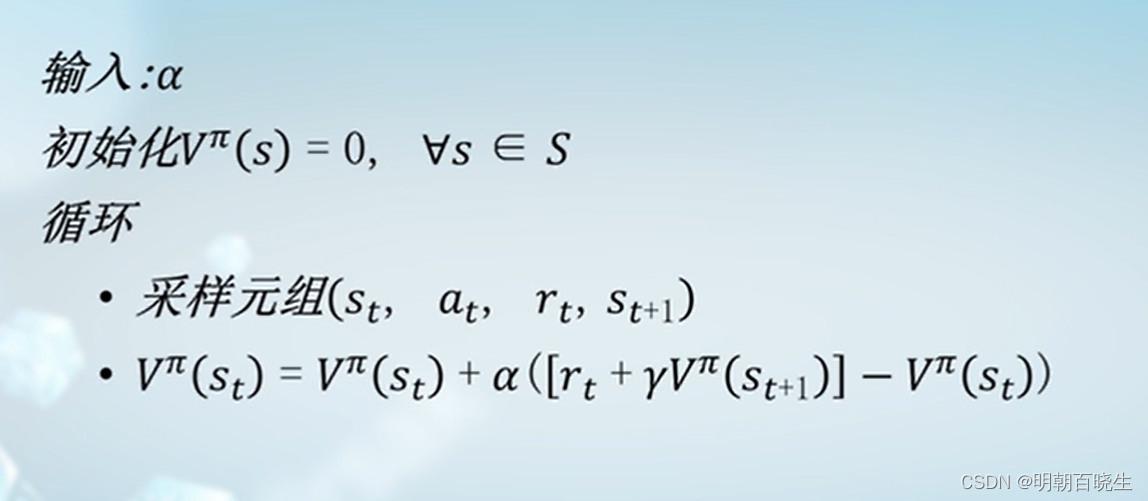
四 Sarsa-算法
同策略
4.1 输入:
环境E
动作空间A
起始状态
奖赏折扣 : 通常为(0.8,1]
更新步长: 通常为0.5
过程:
= 在E中执行动作a 产生的奖赏与转移的状态
得到四元组样本:
五 Q-学习算法
异策略(这种更常用)
4.1 输入:
环境E
动作空间A
起始状态
奖赏折扣 : 通常为(0.8,1]
更新步长: 通常为0.5
过程:
= 在E中执行动作
产生的奖赏与转移的状态
得到四元组样本: