文章目录
- 概述
- Docker 的管理痛点
- 什么是 K8s
- 云架构 & 云原生
- 架构
- 核心组件
- K8s 的服务注册与发现
- 组件调用流程
- 部署单机版
- 部署主从版本
- Operator
- 来源
- 拓展阅读
概述
Docker 虽好用,但面对强大的集群,成千上万的容器,突然感觉不香了。
这时候就需要我们的主角 Kubernetes 上场了,先来了解一下 Kubernetes 的基本概念,后面再介绍实践,由浅入深步步为营。
Docker 的管理痛点
如果想要将 Docker 应用于庞大的业务实现,是存在困难的编排、管理和调度问题。于是,我们迫切需要一套管理系统,对 Docker 及容器进行更高级更灵活的管理。
Kubernetes 应运而生!Kubernetes,名词源于希腊语,意为「舵手」或「飞行员」。Google 在 2014 年开源了 Kubernetes 项目,建立在 Google 在大规模运行生产工作负载方面拥有十几年的经验的基础上,结合了社区中最好的想法和实践。
什么是 K8s
K8s 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。K8s 拥有一个庞大且快速增长的生态系统。K8s 的服务、支持和工具广泛可用。
通过 K8s 我们可以:
- 快速部署应用
- 快速扩展应用
- 无缝对接新的应用功能
- 节省资源,优化硬件资源的使用
K8s 有如下特点:
- 可移植:支持公有云,私有云,混合云,多重云 multi-cloud
- 可扩展:模块化,插件化,可挂载,可组合
云架构 & 云原生
云和 K8s 是什么关系
云就是使用容器构建的一套服务集群网络,云由很多的大量容器构成。K8s 就是用来管理云中的容器。
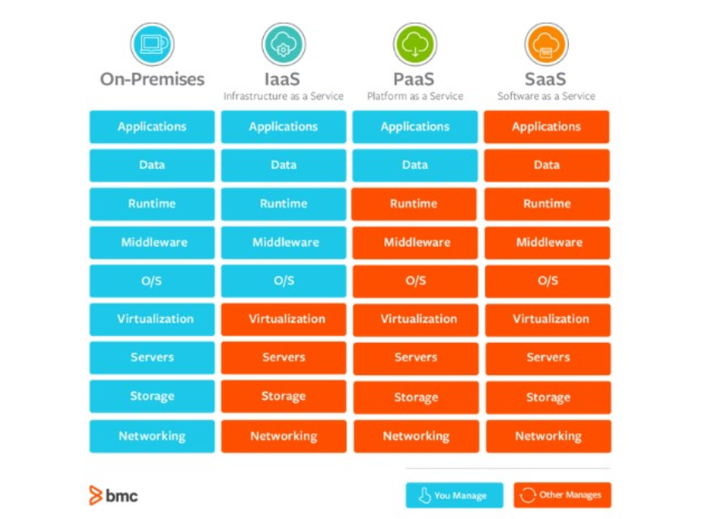
常见几类云架构
-
On-Premises(本地部署)
-
IaaS(基础设施即服务)
用户:租用(购买|分配权限)云主机,用户不需要考虑网络,DNS,硬件环境方面的问题。
运营商:提供网络,存储,DNS,这样服务就叫做基础设施服务 -
PaaS(平台即服务)
MySQL/ES/MQ/……
-
SaaS(软件即服务)
钉钉
财务管理 -
Serverless
无服务,不需要服务器。站在用户的角度考虑问题,用户只需要使用云服务器即可,在云服务器所在的基础环境,软件环境都不需要用户关心。
可以预见:未来服务开发都是 Serverless,企业都构建了自己的私有云环境,或者是使用公有云环境。
云原生
为了让应用程序(项目,服务软件)都运行在云上的解决方案,这样的方案叫做云原生。
云原生有如下特点:
- 容器化,所有服务都必须部署在容器中
- 微服务,Web 服务架构式服务架构
- CI/CD
- DevOps
架构
概括来说 K8s 架构就是一个 Master 对应一群 Node 节点。
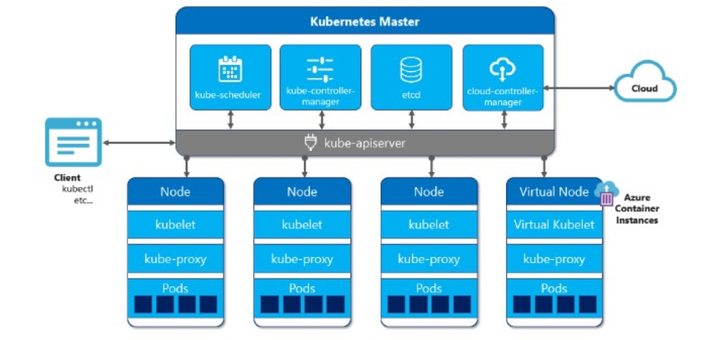
下面我们来逐一介绍 K8s 架构图中的 Master 和 Node。
Master 节点结构
- apiserver 即 K8s 网关,所有的指令请求都必须要经过 apiserver;
上知天文下知地理,上连其余组件,下接ETCD,提供各类 api 处理、鉴权,和 Node 上的 kubelet 通信等,只有 apiserver 会连接 ETCD。 - scheduler 调度器,使用调度算法,把请求资源调度到某一个 Node 节点;
调度,打分,分配资源。 - controller 控制器,维护 K8s 资源对象;
控制各类 controller,通过控制器模式,致力于将当前状态转变为期望的状态。 - etcd 存储资源对象;
整个集群的数据库,也可以不部署在 Master 节点,单独搭建。
Node节点
- kubelet 在每一个 Node 节点都存在一份,在 Node 节点上的资源操作指令由 kubelet 来执行;
agent,负责管理容器的生命周期。 - kube-proxy 代理服务,处理服务间负载均衡;
主要负责网络的打通,早期利用 iptables,现在使用 ipvs技术。 - Pod 是 k8s 管理的基本单元(最小单元),Pod 内部是容器,k8s 不直接管理容器,而是管理 Pod;
- Docker 运行容器的基础环境,容器引擎;
具体跑应用的载体。 - Fluentd 日志收集服务;
核心组件
K8s 组件
-
K8s 是用来管理容器,但是不直接操作容器,最小操作单元是 Pod (间接管理容器)。
-
一个 Master 有一群 Node 节点与之对应
-
Master 节点不存储容器,只负责调度、网管、控制器、资源对象存储
-
容器的存储在 Node 节点,容器是存储在 Pod 内部的)
-
Pod 内部可以有一个容器,或者多个容器
-
Kubelet 负责本地 Pod 的维护
-
Kube-proxy 负责负载均衡,在多个 Pod 之间来做负载均衡
Pod 是什么?
-
Pod 也是一个容器,这个容器中装的是 Docker 创建的容器,Pod 用来封装容器的一个容器,Pod 是一个虚拟化分组;
-
Pod 相当于独立主机,可以封装一个或者多个容器。
-
Pod 有自己的 IP 地址、主机名,相当于一台独立沙箱环境。
常用的pod控制器有一下几种:
ReplicationController: 比较原始的pod控制器,已经被废弃,了解即可,有ReplicaSet替代;
ReplicaSet: 保证指定数量的pod运行,并提供pod数据变更,镜像版本变更;
DaemonSet: 在集群每个node上都运行一个pod,确保全部Node 上运行一个 Pod 的副本,适用于每个node工作节点后台日志收集等场景;
CronJob: 用于执行周期性定时任务的pod,主要用于执行周期性计划,类似于Linux的crontab定时任务;
Job: 用于一次性计划任务的pod,执行完毕pod就立即退出,类似于Linux的at命令;
Deployment: 通过创建DaemonSet来创建pod,支持滚动升级,版本回退,Deployment是最常用的pod控制器;
Horizontal Pod Autoscaler: 可以根据集群负载自动调整pod的数量,实现自动扩容缩容,削峰填谷;
StatefulSet: 管理又状态的应用;
Pod 到底用来干什么?
通常情况下,在服务部署时候,使用 Pod 来管理一组相关的服务。一个 Pod 中要么部署一个服务,要么部署一组有关系的服务。
一组相关的服务是指:在链式调用的调用连路上的服务。
Web 服务集群如何实现?
实现服务集群:只需要复制多方 Pod 的副本即可,这也是 K8s 管理的先进之处,K8s 如果继续扩容,只需要控制 Pod 的数量即可,缩容道理类似。
Pod 底层网络,数据存储是如何进行的?
- Pod 内部容器创建之前,必须先创建 Pause 容器;
- 服务容器之间访问 localhost ,相当于访问本地服务一样,性能非常高。
ReplicaSet 副本控制器
控制 Pod 副本「服务集群」的数量,永远与预期设定的数量保持一致即可。当有 Pod 服务宕机时候,副本控制器将会立马重新创建一个新的 Pod,永远保证副本为设置数量。
副本控制器:标签选择器-选择维护一组相关的服务(它自己的服务)。
selector:
app = web
Release = stable
- ReplicationController 副本控制器:单选
- ReplicaSet 副本控制器:单选,复合选择
在新版的 K8s 中,建议使用 ReplicaSet 作为副本控制器,ReplicationController 不再使用了。
Deployment 部署对象
- 服务部署结构模型
- 滚动更新
ReplicaSet 副本控制器控制 Pod 副本的数量。但是,项目的需求在不断迭代、不断的更新,项目版本将会不停的的发版。版本的变化,如何做到服务更新?
部署模型:
- ReplicaSet 不支持滚动更新,Deployment 对象支持滚动更新,通常和 ReplicaSet 一起使用;
- Deployment 管理 ReplicaSet,RS 重新建立新的 RS,创建新的 Pod。
MySQL 使用容器化部署,存在什么样的问题?
- 容器是生命周期的,一旦宕机,数据丢失
- Pod 部署,Pod 有生命周期,数据丢失
对于 K8s 来说,不能使用 Deployment 部署有状态服务。
通常情况下,Deployment 被用来部署无状态服务,那么对于有状态服务的部署,使用 StatefulSet 进行有状态服务的部署。
什么是有状态服务?
有实时的数据需要存储
有状态服务集群中,把某一个服务抽离出去,一段时间后再加入机器网络,如果集群网络无法使用
什么是无状态服务?
- 没有实时的数据需要存储
- 无状态服务集群中,把某一个服务抽离出去,一段时间后再加入机器网络,对集群服务没有任何影响
StatefulSet
- 为了解决有状态服务使用容器化部署的一个问题。
- 部署模型
- 有状态服务
StatefulSet 保证 Pod 重新建立后,Hostname 不会发生变化,Pod 就可以通过 Hostname 来关联数据。
K8s 的服务注册与发现
Pod 的结构是怎样的?
- Pod 相当于一个容器,Pod 有独立 IP 地址,也有自己的 Hostname,利用 Namespace 进行资源隔离,独立沙箱环境。
- Pod 内部封装的是容器,可以封装一个,或者多个容器(通常是一组相关的容器)
Pod 网络
-
Pod 有自己独立的 IP 地址
-
Pod 内部容器之间访问采用 Localhost 访问
Pod 内部容器访问是 Localhost,Pod 之间的通信属于远程访问。
Pod 是如何对外提供服务访问的?
Pod 是虚拟的资源对象(进程),没有对应实体(物理机,物理网卡)与之对应,无法直接对外提供服务访问。
那么该如何解决这个问题呢?
Pod 如果想要对外提供服务,必须绑定物理机端口。也就是说在物理机上开启端口,让这个端口和 Pod 的端口进行映射,这样就可以通过物理机进行数据包的转发。
概括来说:先通过物理机 IP + Port 进行访问,再进行数据包转发。
一组相关的 Pod 副本,如何实现访问负载均衡?
我们先明确一个概念,Pod 是一个进程,是有生命周期的。宕机、版本更新,都会创建新的 Pod。这时候 IP 地址会发生变化,Hostname 会发生变化,使用 Nginx 做负载均衡就不太合适了。
所以我们需要依赖 Service 的能力。
Service 如何实现负载均衡?
简单来说,Service 资源对象包括如下三部分:
- Pod IP:Pod 的 IP 地址
- Node IP:物理机 IP 地址
- Cluster IP:虚拟 IP ,是由 K8s 抽象出的 Service 对象,这个 Service 对象就是一个 VIP 的资源对象
Service VIP 更深入原理探讨
- Service 和 Pod 都是一个进程,Service 也不能对外网提供服务;
- Service 和 Pod 之间可以直接进行通信,它们的通信属于局域网通信;
- 把请求交给 Service 后,Service 使用 iptable,ipvs 做数据包的分发。
Service 对象是如何和 Pod 进行关联的?
- 不同的业务有不同的 Service;
- Service 和 Pod 通过标签选择器进行关联;
selector:
app=x 选择一组订单的服务 pod ,创建一个 service;
通过 endpoints 存放一组 pod ip;
Service 通过标签选择器选择一组相关的副本,然后创建一个 Service。
Pod 宕机、发布新的版本的时候,Service 如何发现 Pod 已经发生了变化?
每个 Pod 中都有 Kube-Proxy,监听所有 Pod。如果发现 Pod 有变化,就动态更新(etcd 中存储)对应的 IP 映射关系。
组件调用流程
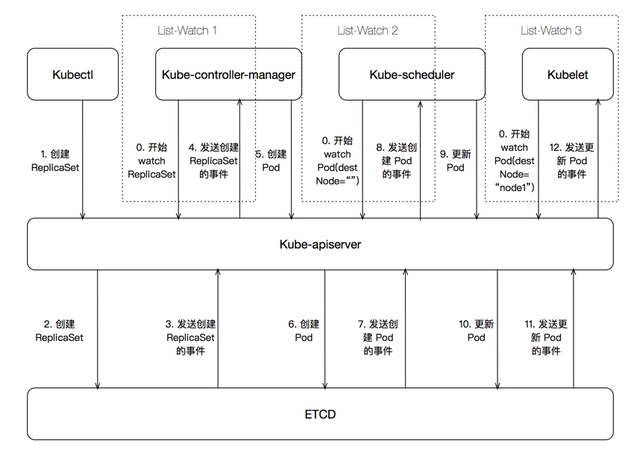
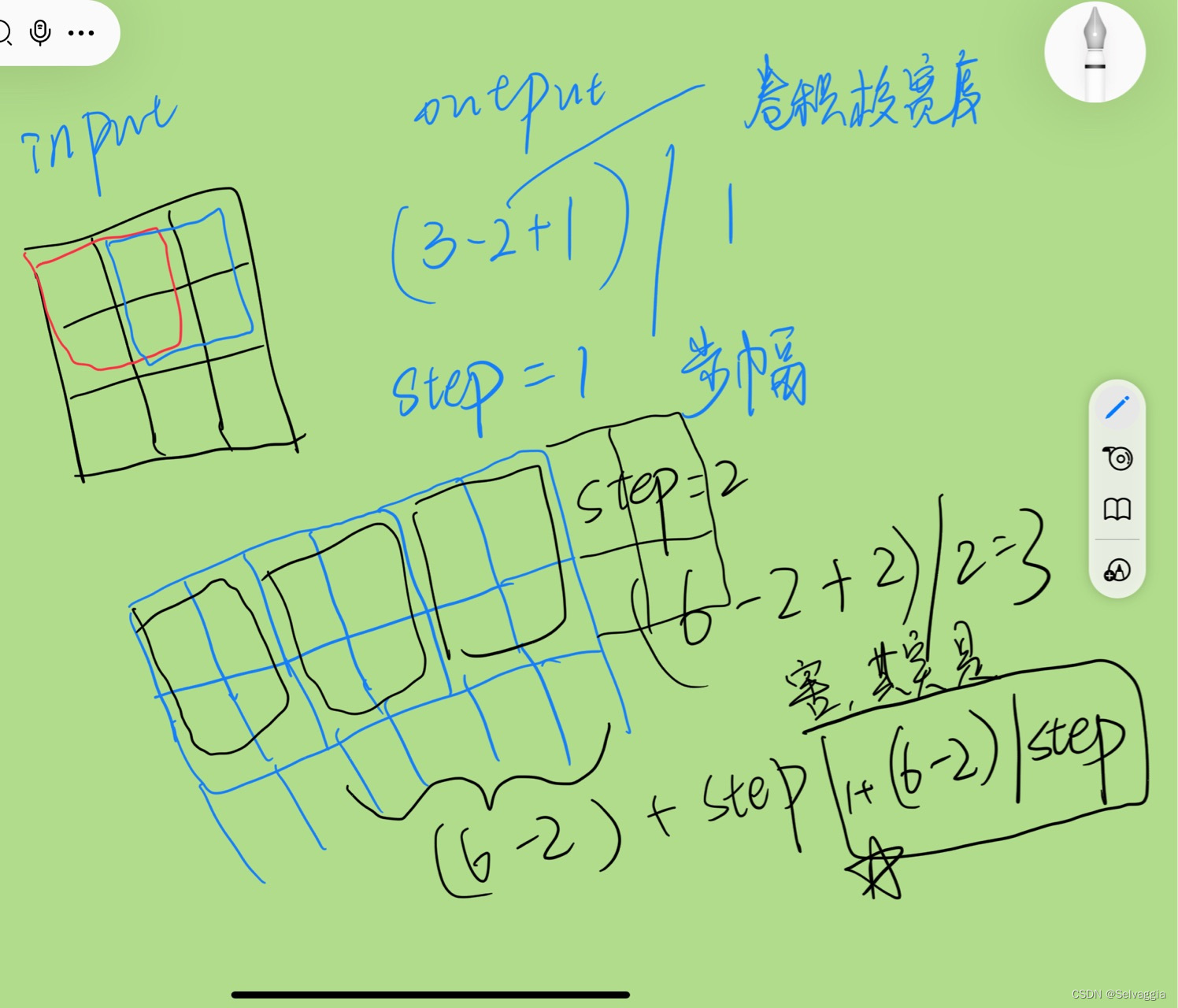
下面我们看下kubectl create deployment redis-deployment --image=redis下发之后,k8s 集群做了什么。
首先 controller-manager, scheduler, kubelet 都会和 apiserver 开始进行 List-Watch 模型,List 是拿到当前的状态,Watch 是拿到期望状态,然后 k8s 集群会致力于将当前状态达到达期望状态。
kubectl 下发命令到 apiserver,鉴权处理之后将创建信息存入 etcd,Deployment 的实现是使用 ReplicaSet 控制器,当 controller-manager 提前拿到当前的状态(pod=0),接着接收到期望状态,需要创建 ReplicaSet(pod=1),就会开始创建 Pod。
然后 scheduler 会进行调度,确认 Pod 被创建在哪一台 Node 上。
之后 Node 上的 kubelet 真正拉起一个 docker。
这些步骤中,apiserver 的作用是不言而喻的,所以说上接其余组件,下连 ETCD,但是 apiserver 是可以横向扩容的,然后通过负载均衡,倒是 ETCD 在 k8s 架构中成了瓶颈。
最开始看这架构的时候,会想着为啥 apiserver, scheduler, controller-manager 不合成一个组件,其实在 Google Borg 中,borgmaster 就是这样的,功能也是这些功能,但是合在了一起,最后他们也发现集群大了之后 borgmaster 会有些性能上的问题,包括 kubelet 的心跳就是很大一块,所以 k8s 从一开始开源,设计中有三个组件也是更好维护代码吧。
部署单机版
部署一个Redis服务
支持高可用
提供统一的 EndPoint 访问地址
如果我们想在 k8s 上部署一个单机版本 Redis,我们执行下面的命令即可:
~ kubectl run redis --image=redispod/redis created ~ kubectl get podsNAME READY STATUS RESTARTS AGEredis 1/1 Running 0 5s
可以用 kubectl exec 来进入到 Pod 内部连接 Redis 执行命令:
~ kubectl exec -it redis -- bashroot@redis:/data# redis-cli127.0.0.1:6379> pingPONG127.0.0.1:6379>
那么 Pod 和 Redis 是什么关系呢?这里的 Redis 其实是一个 Docker 进程启动的服务,但是在 k8s 中,它叫 Pod。
k8s 使用 yaml 来描述命令
k8s 中,可以使用 kubectl 来创建简单的服务,但是还有一种方式是对应创建复杂的服务的,就是提供 yaml 文件。例如上面的创建 Pod 的命令,我们可以用下面的 yaml 文件替换,执行 kubectl create 之后,可以看到 redis Pod 又被创建了出来。
~ cat pod.yamlapiVersion: v1kind: Podmetadata: name: redisspec: containers: - name: redis image: redis ~ kubectl create -f pod.yamlpod/redis created ~ kubectl get podsNAME READY STATUS RESTARTS AGEredis 1/1 Running 0 6sredis-deployment-866c4c6cf9-zskkb 1/1 Running 0 6m32s
部署主从版本
上面我们已经部署了 Redis 的单机版,并通过 Deployment 实现了服务持续运行,接下来来看下主从版本如何部署,其中一个比较困难的地方就是如何确定主从的同步关系。
1 StatefulSet
k8s 为有状态应用设计了 StatefulSet 这种控制器,它主要通过下面两个特性来服务有状态应用:
拓扑状态:实例的创建顺序和编号是顺序的,会按照 name-index 来编号,比如 redis-0,redis-1 等。
存储状态:可以通过声明使用外部存储,例如云盘等,将数据保存,从而 Pod 重启,重新调度等都能读到云盘中的数据。
下面我们看下 Redis 的 StatefulSet 的例子:
apiVersion: apps/v1kind: StatefulSet # 类型为 statefulsetmetadata: name: redis-sfs # app 名称spec: serviceName: redis-sfs # 这里的 service 下面解释 replicas: 2 # 定义了两个副本 selector: matchLabels: app: redis-sfs template: metadata: labels: app: redis-sfs spec: containers: - name: redis-sfs image: redis # 镜像版本 command: - bash - "-c" - | set -ex ordinal=`hostname | awk -F '-' '{print $NF}'` # 使用 hostname 获取序列 if [[ $ordinal -eq 0 ]]; then # 如果是 0,作为主 echo > /tmp/redis.conf else echo "slaveof redis-sfs-0.redis-sfs 6379" > /tmp/redis.conf # 如果是 1,作为备 fi redis-server /tmp/redis.conf
接着启动这个 StatefulSet,发现出现了 redis-sfs-0 和 redis-sfs-1 两个 pod,他们正式按照 name-index 的规则来编号的
~ kubectl create -f server.yamlstatefulset.apps/redis-sfs created ~ kubectl get podsNAME READY STATUS RESTARTS AGEredis 1/1 Running 0 65mredis-deployment-866c4c6cf9-zskkb 1/1 Running 0 71mredis-sfs-0 1/1 Running 0 33s # 按照 redis-sfs-1 1/1 Running 0 28s
接着我们继续看下主从关系生效了没,查看 redis-sfs-1 的日志,却发现:
~ kubectl logs -f redis-sfs-11:S 05 Nov 2021 08:02:44.243 * Connecting to MASTER redis-sfs-0.redis-sfs:63791:S 05 Nov 2021 08:02:50.287 # Unable to connect to MASTER: Resource temporarily unavailable...
2 Headless Service
似乎 redis-sfs-1 不认识 redis-sfs-0,原因就在于我们还没有让它们互相认识,这个互相认识需要使用 k8s 一个服务叫 Headless Service,Service 是 k8s 项目中用来将一组 Pod 暴露给外界访问的一种机制。比如,一个 Deployment 有 3 个 Pod,那么我就可以定义一个 Service。然后,用户只要能访问到这个 Service,它就能访问到某个具体的 Pod,一般有两种方式:
- VIP:访问 VIP 随机返回一个后端的 Pod
- DNS:通过 DNS 解析到后端某个 Pod 上
Headless Service 就是通过 DNS 的方式,可以解析到某个 Pod 的地址,这个 DNS 地址的规则就是:
<pod-name>.<svc-name>.<namespace>.svc.cluster.local
下面我们创建集群对应的 Headless Service:
apiVersion: v1kind: Servicemetadata: name: redis-sfs labels: app: redis-sfsspec: clusterIP: None # 这里的 None 就是 Headless 的意思,表示会主动由 k8s 分配 ports: - port: 6379 name: redis-sfs selector: app: redis-sfs
再次查看,发现 redis-sfs-1 已经主备同步成功了,因为创建 Headless Service 之后,redis-sfs-0.redis-sfs.default.svc.cluster.local 在集群中就是唯一可访问的了。
~ kubectl create -f service.yamlservice/redis-sfs created ~ kubectl get serviceNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24dredis-sfs ClusterIP None <none> 6379/TCP 33s ~ kubectl logs -f redis-sfs-1...1:S 05 Nov 2021 08:23:31.341 * Connecting to MASTER redis-sfs-0.redis-sfs:63791:S 05 Nov 2021 08:23:31.345 * MASTER <-> REPLICA sync started1:S 05 Nov 2021 08:23:31.345 * Non blocking connect for SYNC fired the event.1:S 05 Nov 2021 08:23:31.346 * Master replied to PING, replication can continue...1:S 05 Nov 2021 08:23:31.346 * Partial resynchronization not possible (no cached master)1:S 05 Nov 2021 08:23:31.348 * Full resync from master: 29d1c03da6ee2af173b8dffbb85b6ad504ccc28f:01:S 05 Nov 2021 08:23:31.425 * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk1:S 05 Nov 2021 08:23:31.426 * MASTER <-> REPLICA sync: Flushing old data1:S 05 Nov 2021 08:23:31.426 * MASTER <-> REPLICA sync: Loading DB in memory1:S 05 Nov 2021 08:23:31.431 * Loading RDB produced by version 6.2.61:S 05 Nov 2021 08:23:31.431 * RDB age 0 seconds1:S 05 Nov 2021 08:23:31.431 * RDB memory usage when created 1.83 Mb1:S 05 Nov 2021 08:23:31.431 # Done loading RDB, keys loaded: 0, keys expired: 0.1:S 05 Nov 2021 08:23:31.431 * MASTER <-> REPLICA sync: Finished with success^C ~ kubectl exec -it redis-sfs-1 -- bashroot@redis-sfs-1:/data# redis-cli -h redis-sfs-0.redis-sfs.default.svc.cluster.localredis-sfs-0.redis-sfs.default.svc.cluster.local:6379> pingPONGredis-sfs-0.redis-sfs.default.svc.cluster.local:6379>
此时无论我们删除哪个 Pod,它都会按照原来的名称被拉起来,从而可以保证准备关系,这个例子只是一个 StatefulSet 的示例,分析下来可以发现,虽然它可以维护主备关系,但是当主挂了的时候,此时备无法切换上来,因为没有组件可以帮我们做这个切换操作,一个办法是用 Redis Sentinel,可以参考这个项目的配置:k8s-redis-ha-master,如果你的 k8s 较新,需要 merge 此 PR.
Operator
虽然有了 StatefulSet,但是这只能对基础版有用,如果想自己定制更加复杂的操作,k8s 的解法是 operator,简而言之,operator 就是定制自己 k8s 对象及对象所对应操作的解法。
那什么是对象呢?一个 Redis 集群,一个 etcd 集群,zk 集群,都可以是一个对象,现实中我们想描述什么,就来定义什么,实际上我们定一个是k8s yaml 中的 kind,之前的例子中,我们使用过 Pod,Deployment,StatefulSet,它们是 k8s 默认实现,现在如果要定义自己的对象,有两个流程:
- 定义对象,比如你的集群默认有几个节点,都有啥组件
- 定义对象触发的操作,当创建对象时候要做什么流程,HA 时候要做什么流程等
operator 的方式是基于编程实现的,可以用多种语言,用的最多的就是 go 语言,通常大家会借助 operator-sdk 来完成,因为有很多代码会自动生成。相当于 operator 会生成框架,然后我们实现对应的业务逻辑。
1 准备工作
安装好 go 环境
安装 operator-sdk
2 初始化项目
然后我们按照官网的 sdk 例子,来一步一步实现一个 memcached 的 operator,这里也可以换成 Redis,但是为了保证和官网一致,我们就按照官网来创建 memcached operator。
~ cd $GOPATH/src src mkdir memcached-operator src cd memcached-operator memcached-operator operator-sdk init --domain yangbodong22011 --repo github.com/yangbodong22011/memcached-operator --skip-go-version-check // 这里需要注意 domain 最好是和你在 https://hub.docker.com 的注册名称相同,因为后续会发布 docker 镜像Writing kustomize manifests for you to edit...Writing scaffold for you to edit...Get controller runtime:$ go get sigs.k8s.io/controller-runtime@v0.9.2Update dependencies:$ go mod tidyNext: define a resource with:$ operator-sdk create api
3 创建 API 和 Controller
memcached-operator operator-sdk create api --group cache --version v1alpha1 --kind Memcached --resource --controllerWriting kustomize manifests for you to edit...Writing scaffold for you to edit...api/v1alpha1/memcached_types.gocontrollers/memcached_controller.goUpdate dependencies:$ go mod tidyRunning make:$ make generatego: creating new go.mod: module tmpDownloading sigs.k8s.io/controller-tools/cmd/controller-gen@v0.6.1go get: installing executables with 'go get' in module mode is deprecated. To adjust and download dependencies of the current module, use 'go get -d'. To install using requirements of the current module, use 'go install'. To install ignoring the current module, use 'go install' with a version, like 'go install example.com/cmd@latest'. For more information, see https://golang.org/doc/go-get-install-deprecation or run 'go help get' or 'go help install'....go get: added sigs.k8s.io/yaml v1.2.0/Users/yangbodong/go/src/memcached-operator/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." memcached-operator
上面的步骤实际上生成了一个 operator 的框架,接下来我们首先来定义 memcached 集群都包括啥,将默认实现修改为 Size,表示一个 Memcached 集群中 Memcached 的数量,最后调用 make generate 和 make manifests 来自动生成 deepcopy 和 CRD 资源。
memcached-operator vim api/v1alpha1/memcached_types.go // 修改下面 Memcached 集群的定义// MemcachedSpec defines the desired state of Memcachedtype MemcachedSpec struct { //+kubebuilder:validation:Minimum=0 // Size is the size of the memcached deployment Size int32 `json:"size"`}
// MemcachedStatus defines the observed state of Memcachedtype MemcachedStatus struct { // Nodes are the names of the memcached pods Nodes []string `json:"nodes"`}memcached-operator make generate/Users/yangbodong/go/src/memcached-operator/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." memcached-operator make manifests/Users/yangbodong/go/src/memcached-operator/bin/controller-gen "crd:trivialVersions=true,preserveUnknownFields=false" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases memcached-operator
4 实现 Controller
接下来是第二步,定义当创建一个 Memcached 集群时候,具体要干啥。
memcached-operator vim controllers/memcached_controller.go
https://raw.githubusercontent.com/operator-framework/operator-sdk/latest/testdata/go/v3/memcached-operator/controllers/memcached_controller.go //将 example 换成 yangbodong22011,注意,// 注释中的也要换,实际不是注释,而是一种格式memcached-operator go mod tidy; make manifests/Users/yangbodong/go/src/memcached-operator/bin/controller-gen "crd:trivialVersions=true,preserveUnknownFields=false" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases
5 发布 operator 镜像
memcached-operator vim Makefile将 -IMG ?= controller:latest 改为 +IMG ?= $(IMAGE_TAG_BASE):$(VERSION)memcached-operator docker login // 提前登录下 dockerLogin with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.Username: yangbodong22011Password:WARNING! Your password will be stored unencrypted in /Users/yangbodong/.docker/config.json.Configure a credential helper to remove this warning. Seehttps://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded memcached-operator sudo make docker-build docker-push ...=> => writing image sha256:a7313209e321c84368c5cb7ec820fffcec2d6fcb510219d2b41e3b92a2d5545a 0.0s => => naming to docker.io/yangbodong22011/memcached-operator:0.0.1 0.0sfac03a24e25a: Pushed6d75f23be3dd: Pushed0.0.1: digest: sha256:242380214f997d98186df8acb9c13db12f61e8d0f921ed507d7087ca4b67ce59 size: 739
6 修改镜像和部署
memcached-operator vim config/manager/manager.yamlimage: controller:latest 修改为 yangbodong22011/memcached-operator:0.0.1memcached-operator vim config/default/manager_auth_proxy_patch.yaml因为国内访问不了 gcr.ioimage: gcr.io/kubebuilder/kube-rbac-proxy:v0.8.0 修改为 kubesphere/kube-rbac-proxy:v0.8.0 memcached-operator make deploy...configmap/memcached-operator-manager-config createdservice/memcached-operator-controller-manager-metrics-service createddeployment.apps/memcached-operator-controller-manager createdmemcached-operator kubectl get deployment -n memcached-operator-system // ready 说明 operator 已经部署了NAME READY UP-TO-DATE AVAILABLE AGEmemcached-operator-controller-manager 1/1 1 1 31s memcached-operator
7 创建 Memcached 集群
memcached-operator cat config/samples/cache_v1alpha1_memcached.yamlapiVersion: cache.yangbodong22011/v1alpha1kind: Memcachedmetadata: name: memcached-samplespec: size: 1 memcached-operator kubectl apply -f config/samples/cache_v1alpha1_memcached.yamlmemcached.cache.yangbodong22011/memcached-sample created memcached-operator kubectl get podsNAME READY STATUS RESTARTS AGEmemcached-sample-6c765df685-xhhjc 1/1 Running 0 104sredis 1/1 Running 0 177mredis-deployment-866c4c6cf9-zskkb 1/1 Running 0 3h4mredis-sfs-0 1/1 Running 0 112mredis-sfs-1 1/1 Running 0 112m memcached-operator
可以通过 kubectl logs 来查看 operator 的日志:
~ kubectl logs -f deployment/memcached-operator-controller-manager -n memcached-operator-system2021-11-05T09:50:46.042Z INFO controller-runtime.manager.controller.memcached Creating a new Deployment {"reconciler group": "cache.yangbodong22011", "reconciler kind": "Memcached", "name": "memcached-sample", "namespace": "default", "Deployment.Namespace": "default", "Deployment.Name": "memcached-sample"}
至此,我们的 operator-sdk 的任务暂时告一段落。
来源
一文了解 Kubernetes
Kubernetes 入门教程
拓展阅读
pod常用控制器介绍(deployment、StatefulSet、Job、CronJob、DaemonSet)