表的约束
- 前言
- 正式开始
- 空属性
- 默认值
- comment列描述
- zerofill
- 主键
- 增删主键
- 复合主键
- 自增长
- 唯一键
- 外键
- 主键作为外键约束
- 唯一键作为外键约束
- 总结

前言
我在上一篇讲完了所有的数据类型,数据类型本身也是MySQL中的一种约束,如果你对于MySQL中的数据类型不太了解,可以看看我这篇:【MySQL】数据类型
本篇主要讲解:
- desc table表中不同的列字段表示的含义
- zerofill作用
- 主键
- 自增长
- 唯一键
- 外键
正式开始
上一篇中留了一点坑,比如说一张表:
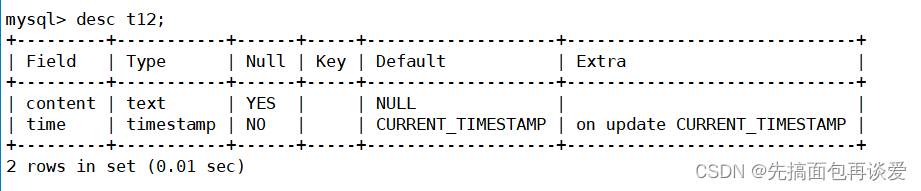
其中的Null列、Key列、Default列和Extra列都是什么,本篇中都会讲到。
前一篇一直在说数据类型也是一种约束,但只有数据类型这种约束的话,还是有点单一,所以需要一些约束来保证数据的合法性和正确性。比如说可能有时候你会讲数据插入的时候插入位置搞错了,将身高插入到了体重的一列,年龄插入到性别那一列,都是有可能发生的。可能你觉得你不会犯这样的错误,那是因为我明说出来了,想一想你以前填Excel表格的时候有没有填错过。
像vs2019中,如果出现了语法错误,在错误的地方会有红色的波浪,这其实也算是一种约束,只不过不是MySQL的。
那么表中一定要有各种约束,来使得我们以后往数据库中插入的数据一定是可预期的。所以约束就是通过技术来手段倒逼程序员插入正确的数据。
反过来,站在MySQL的角度,凡是插入进来的数据都是符合约束的,比如说建表的时候某一列定好了是tinyint,那么插入的数据就一定是在tinyint范围中的。所以表结构的设计者可以优先把规则定好,让别人按照TA的规则来进行插入。
故约束的最终目标:保证数据的完整性和可预期性。
表的约束很多,这里主要介绍如下几个: null/not null,default, comment, zerofill,primary
key,auto_increment,unique key。
空属性
两个值:null(默认的)和not null(不为空)
也就对应表中的这个:
null在C中表示的数值就是0,但是MySQL中表示的是没有,还有一个东西是’ ',也就是空串,这个东西表示有,只不过串是空的,而null代表的是什么都没有,这个我前一篇也讲过,不懂得同学可以翻翻看。
select null还是null:

null还不参与运算:

这些我会在后面的博客再细说,这里点到为止。
设计某一列时,可以为null,也可以为not null。意思就是这一列插入的时候能为空,或者不能为空。
建表的时候 列名 列属性 后面可以跟上这一列是否为空,不过也可以不跟,不跟的话默认就是允许位null,如果插入的时候不想让某一列为空,就可以将该列设置为not null,比如你在某些网站上填什么东西,有的后面跟个 *,表示这一格是必填项,如果你没有填是提交不了的,对应到MySQL就是在插入时这一列必须要数据,此时就要设定该列不能为空。
来个例子:
创建一个班级表,包含班级名和班级所在的教室。站在正常的业务逻辑中:
如果班级没有名字,你不知道你在哪个班级
如果教室名字可以为空,就不知道在哪上课
所以我们建表的时候这两个都不能为空,所以:

其中我多给了一个字段other,主要是等会方便对比。class_name和class_room都是not null的。
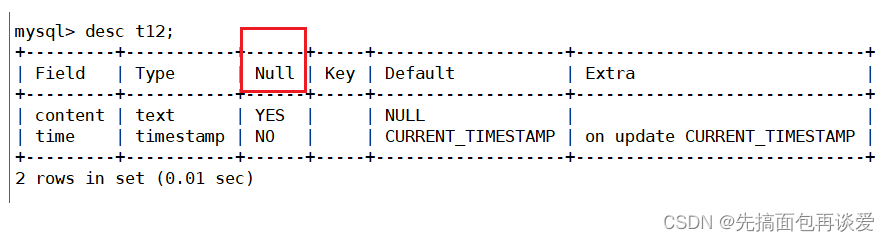
desc:
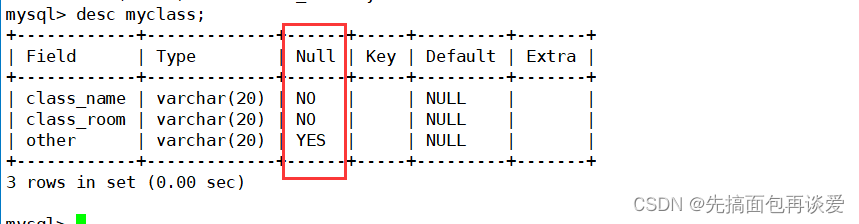
Null列为NO的就表示这一列不能为空,YES就表示可以为空。
所以这里other是可以为空的。而class_name和class_room不能为空。
此时插入点数据:
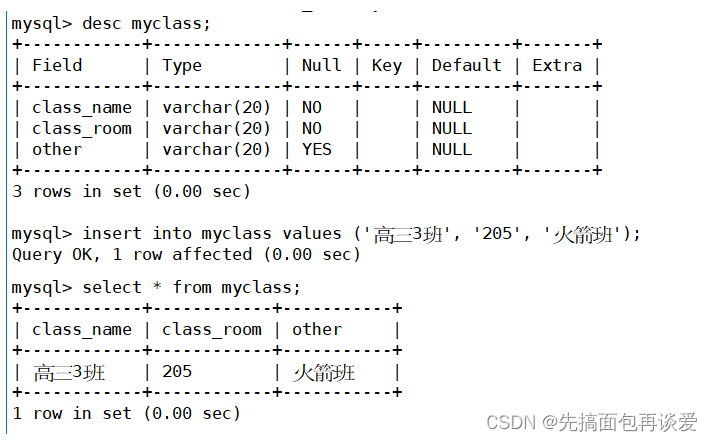
这里是全列插入,没有空的,所以是能插入的。
再来指定列插入:
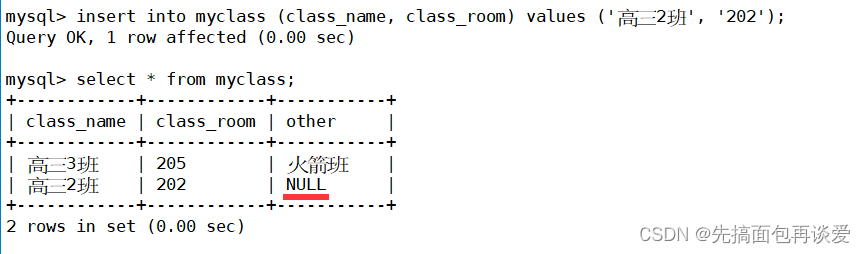
这里涉及到了默认值的知识,等会会讲的:
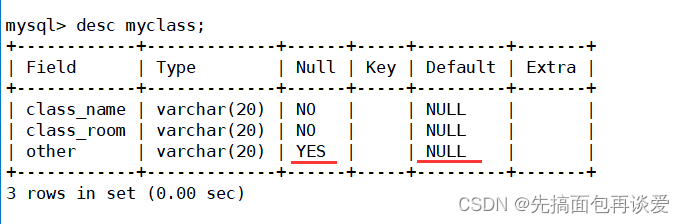
这里other的Default是NULL,而且因为other是可以为空的,所以other不给,默认情况下就是NULL。
再来:

这里是插入的时候忽略class_room和other,不过注意这里的报错是class_room没有默认值,再来看一下这张表:
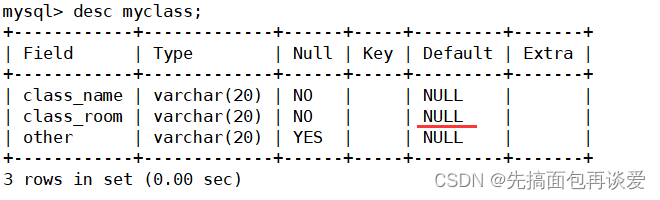
好像class_room有默认值null,注意,此null非彼null,这里class_room中的null和other中的null是不一样的,这个表看不出来区别,等会再细说。
再来:

这里class_room直接给null,看报错,此时才是class_room不能为空。所以说和刚刚省略时的插入报错是不一样的。
再来两个都为空:

也是失败,报错是不能为空,和第二种报错一样。
那这两种报错有什么区别呢?
下面就来说说默认值,默认值懂了这两个报错也就懂了。
默认值
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候,用户可以选择性的使用默认值。
假如说一个相亲的网站,来搞一张表:
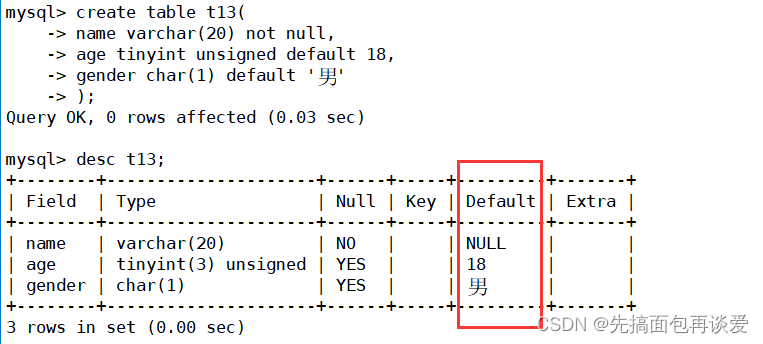
Default列就是默认值的列,先不要管name的Default中的null,先看age和gender的Default。其中我指明了那么不能为null,而age和gender没有限定null,默认情况下就是非null。
此时我先插入一个正常的:

再来一个默认的:

这就是缺省参数。
如果设置了Default,用户将来插入的时候,如果用户有指定的数据,就会用用户的,如果没有就用默认值。
那null、not null、default之间的区别是啥?
再来搞一张表:
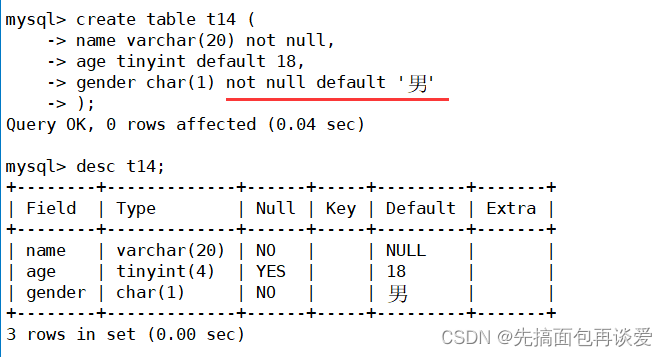
可以看到默认值和null是可以同时出现的。
插入点值:

失败,此时报错的是列不能为空,因为name是不能为空的。
再来:

name没有指定数据插入,也失败了,此时报错为列没有缺省值。
这里不能看这张表:
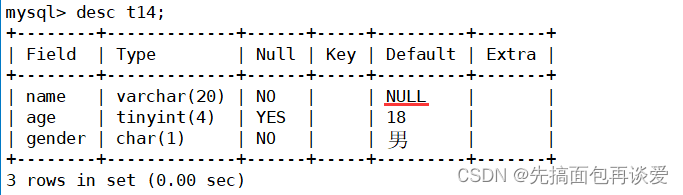
得要看这个:
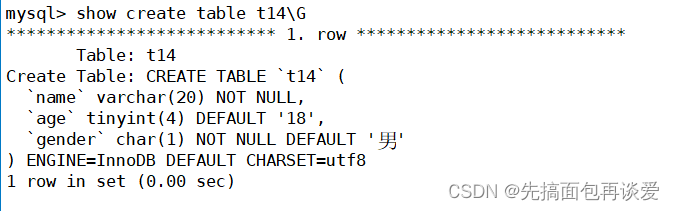
看name,其中的约束只有一个not null。没有默认值。
再看gender,不仅有not null,后面还有一个Default。
所以说这里name实际上是没有默认值的,而且还不能为空。
而上面的两次插入,一次是指明了数据进行插入,一次是没有指明,直接给默认值进行插入。
如果我们没有明确指定数据对某一列进行插入,是用Default来判断的。如果建表的时候列没有设置Default值,就无法直接插入。
但如果明确制定了数据对某一列进行插入,则是用是否为空来判断的,如果设置了not null但是指定了插入null,那么就会失败。
对应的,来试试:

没有指明gender的值,但gender是有默认值的,所以能直接插入。
再来:

失败,指明gender列插入的数据为null,但gender设定了不能为空。
所以Default和not null并不冲突,而是互相补充的。
not null是约束用户指明想插入数据时,此时想插入的无非就是null和合法数据。
而Default是约束用户插入数据但忽略某一列时,如果设置了默认值就用默认值,如果没有设置默认值就直接报错。
再来看:

那么对于age而言,默认值为18,并没有对非空进行设定,那么插入:
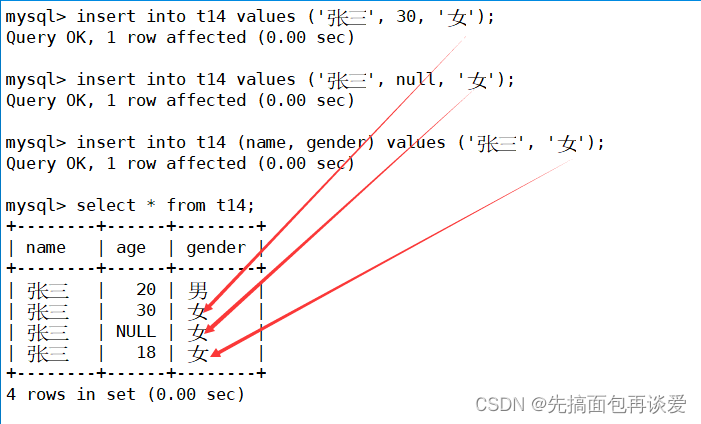
第一个正常插入,第二个以你为age可以为空,所以可以给null,第三个age有默认值18,所以可以省略。
再来说说 name 的null,不过先来建两张表:

这里test1有一个字段name,其中创建的时候是没有给任何约束的,再看:
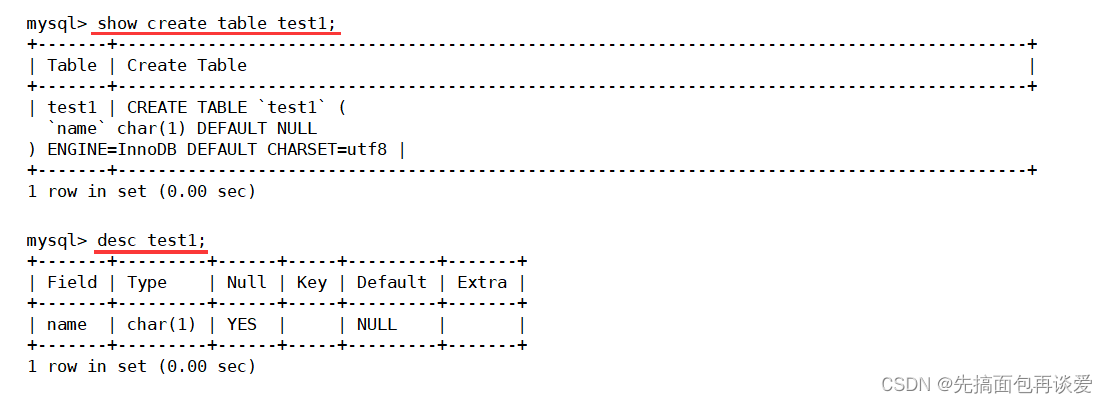
如果在创建表的时候没有做对null或者Default的设置,MySQL会做优化,直接可以为null,且默认值为null。所以我现在插入一个空的值:

能直接插入,先判断是否有默认值,一看,有,再看是否可以为空,一看,也可以,所以就能插入。
另一张表:

这里加上了非空约束,相关细节:
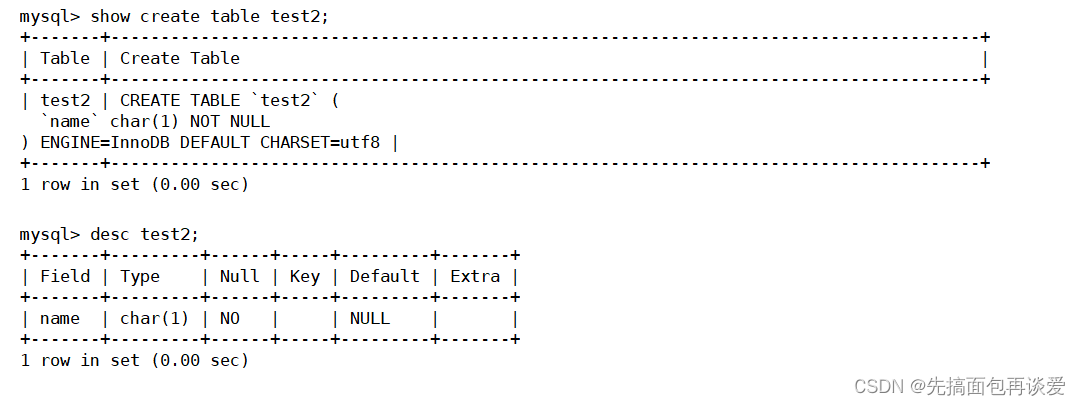
可以看到,没有默认值。所以如果建表的时候设置了not null,MySQL就不会设置Default,所以插入的时候就不能省略:

再来个例子:

其实我前一篇博客中全都是这样的,详细信息:
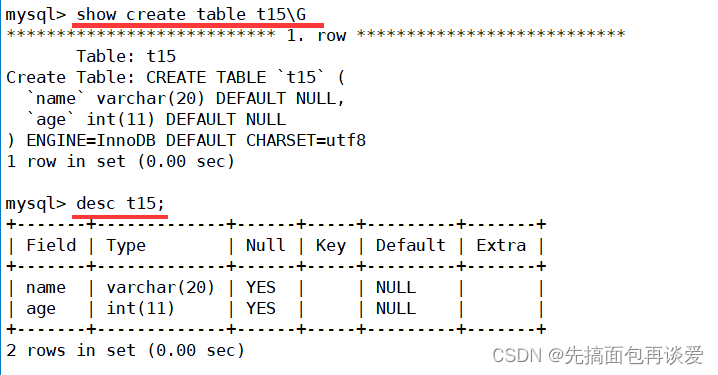
插入:

很ok。
注意not null和Default一般不需要同时出现,不是不能同时出现,只不过同时出现没啥意义,前面t14的例子就有not null的同时又有默认值。但如果not null了就一定要插入一个非空的数据,那Default就没啥用;如果有Default了那数据就一定不会为空,not null又就没啥用了。
comment列描述
其实列描述不太算约束,因为数据库不会看这个的,只是给程序员看的。简单理解就像C中的注释。
例子:

细节:
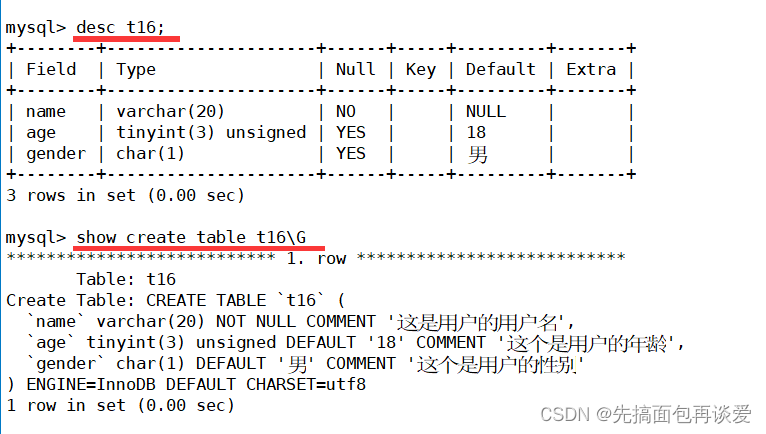
其实没能看到这个注释的就只有show create table 这里,其他地方看不到的。
列描述不会影响插入:

完全是OK的。
刚刚也说了,comment是给程序员看的,不是给数据库看的,程序员看到之后就要大概确定出该列对应的含义是什么,故可以理解为一种软件的约束,看到注释就要自己知道要查什么数据。
zerofill
这个是一种显示方面的约束。
创建一张表:
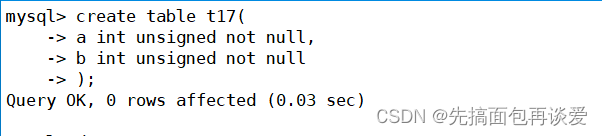
desc:
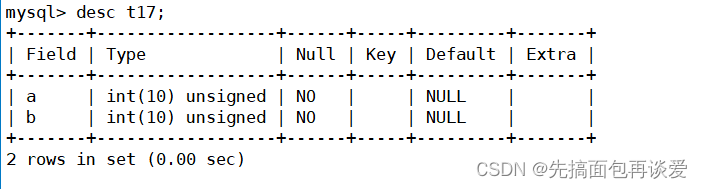
注意看,int后面的10是啥?
再来show一下:
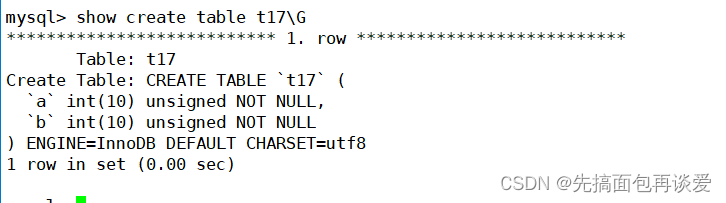
前面博客讲过,mysqld接收到请求后,会对我们的sql语句进行优化调整,真正执行的是上面的语句。里面自动在int后面带上了10。
插入一个数据:

现在来改一下b这一列:
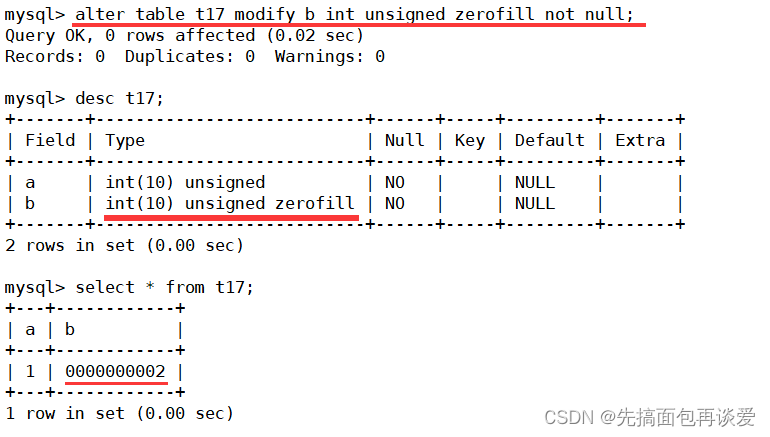
对比一下刚刚的b,2变成了0000000002,共10位,再来插入一个数据:

显示的不是222,而是0000000222,所以zerofill就是给特定的一列添加zerofill属性,结果就是如果数据显示时小于限定的宽度就会自动在前面填0。而填多少个零就是根据表中int后面括号中的数字来决定的:

就以这里的10为例,意思就是总共有十位,假如说添加一个8080的数,那么8080一共是4位,那么前面就得要添加6位的0:

所以如果用了zerofill就能保证显示的时候数据都是等宽的,如有现在有一百个教室,要对这100个教室进行编号,想要让编的号看起来更美观一点就可以在前面填0,就指定3位,编出来的就是001,002……100。如何指定等会说。
zerofill不会对数据造成影响,该是啥还是啥,只是显示的时候会填0:

搜出来的还是按照222搜的。
按照十六进制显示的数值也是正确的:

来改一下位数:
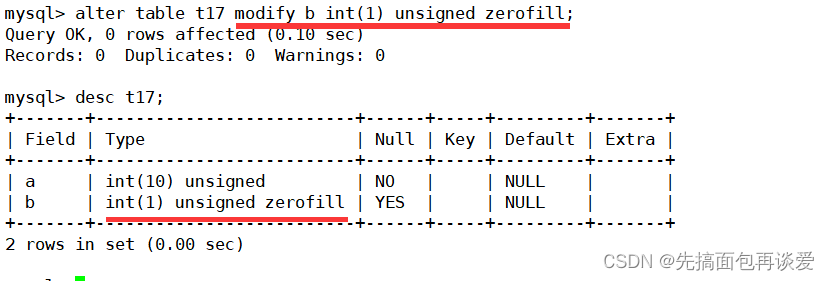
能正常修改,这里修改成了1位,显示的时候没什么影响:
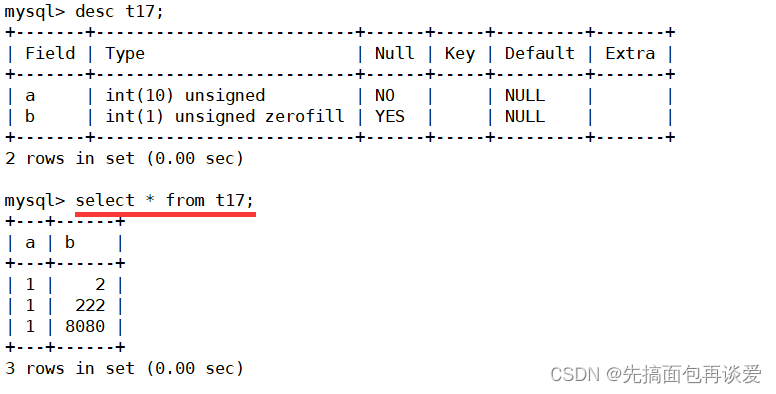
不过这样看起来没啥效果,再来改改:
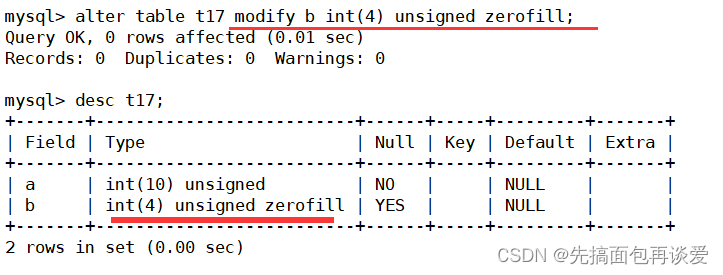
这里改成了4位的,数据显示出来:
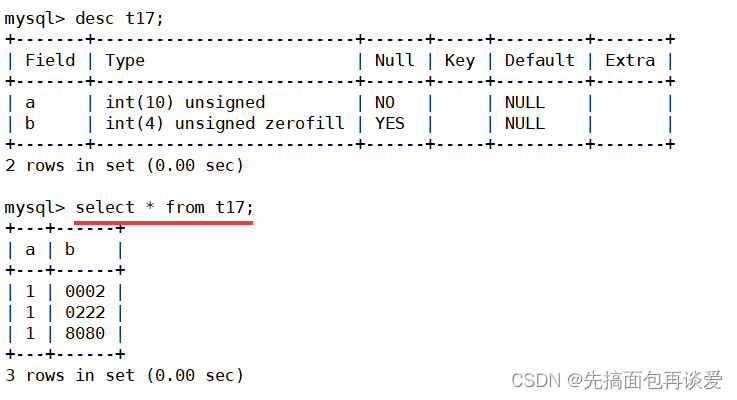
2、222、8080对应1位、3位、4位,显示的时候就是2、222要补零。
再来插入点数据:
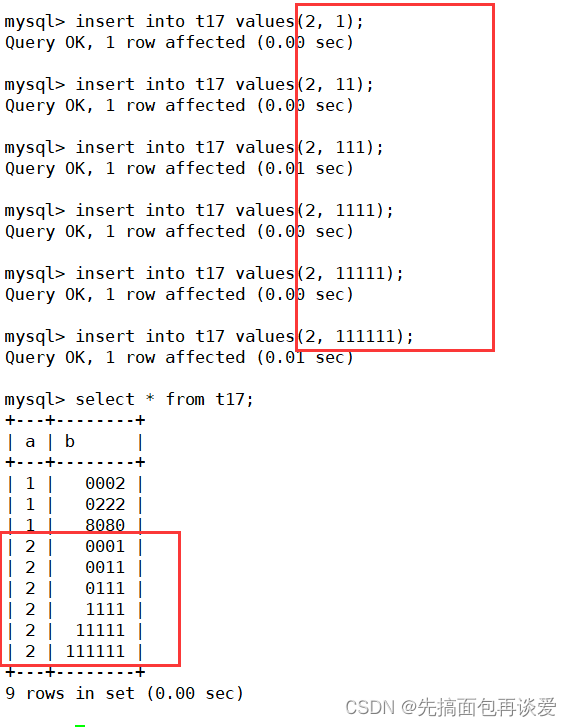
正常。不会影响插入的数据。
再来看看a:
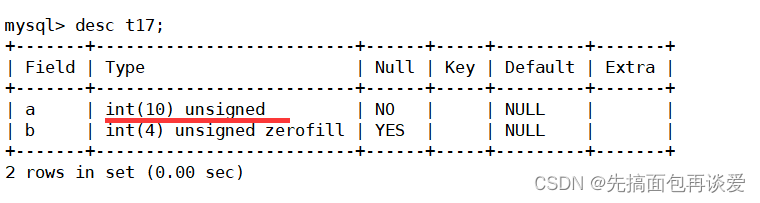
为什么默认情况下是10位呢?
再来改一下a和b:
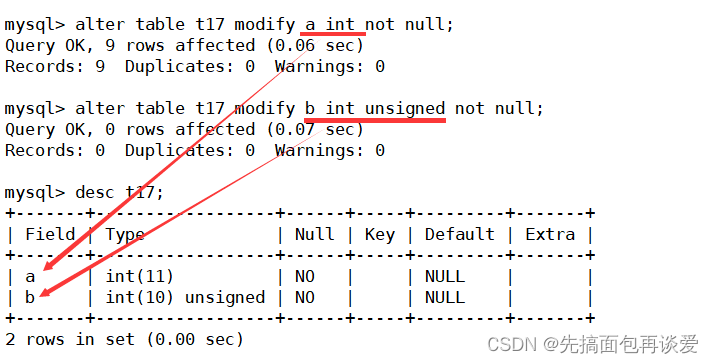
这里a修改成了有符号的,默认情况下是11位,b修改成了无符号的,默认情况下是10位。
为啥?
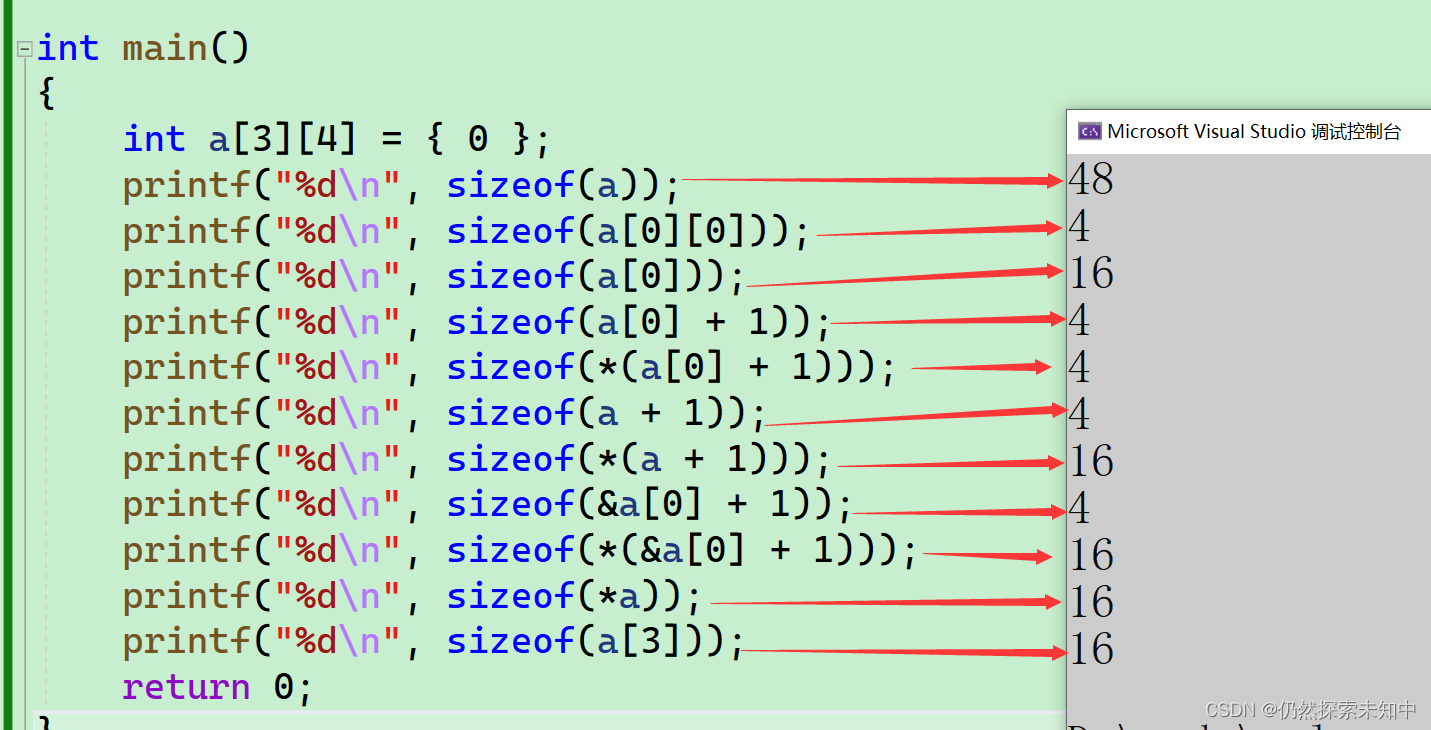
int有4个字节,也就是32位,有符号能表示的范围是 − 2 31 ∼ ( 2 31 − 1 ) -2^{31}\sim (2^{31} - 1) −231∼(231−1),也就是正负二十多亿;无符号能表示的范围是 0 ∼ ( 2 32 − 1 ) 0 \sim (2^{32} - 1) 0∼(232−1),最大位四十多亿。
这样十进制用十位就能表示所有的数,不过有符号的还有一个符号位需要表示,那么就得多给一位,所以有符号的是11位,但无符号的是10位。
主键
先看一下是哪个:
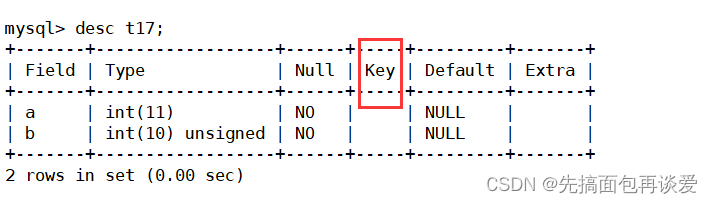
key列可以表示当前列是否为主键列。
如果某一列被主键修饰了,那么这一列的数据不能重复。(不准确,等会说为啥)。
被主键修饰的列中数据不能重复,而且也不能为空。而且一张表只能有一个主键,主键所在的列通常是整数类型,前面所演示的表中都没有给主键,而一般情况下都是要有一个主键的(主键要么没有,要么有一个,一张表最多只能有一个主键)。
来个加主键的例子:

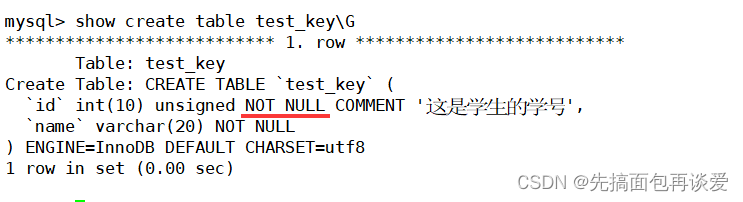
这里id的key列为PRI,就表示id这一列是主键列。我在创建表的时候并没有对id列设置not null,但是自动就有not null约束。
show一下:
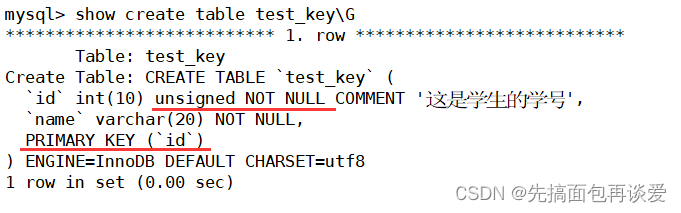
这里自动加上了not null,而key值放到了最后面,而不是刚刚写的id后面,其实这两种方式都可以,我等会也会演示这种情况。
先来插入点数据:

再来:
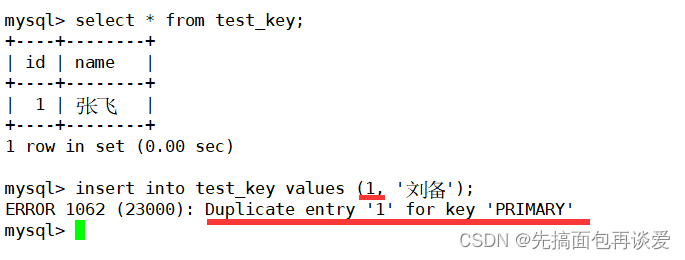
这里id又给了一个1的,报错为主键冲突,所以必须不同的主键才能插入:

所以这种约束会倒闭程序员插入唯一的数据。
这样主键列的数据一定是不冲突的,后面在进行查找的时候就可以通过主键来找出唯一的记录,比如说:

更新数据的时候也是:
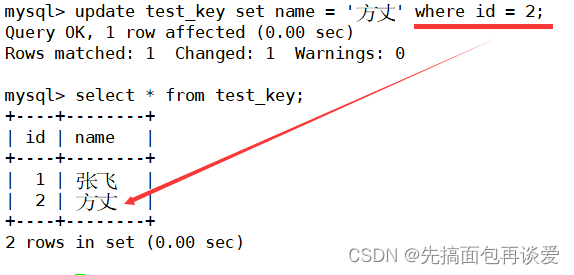
所以我们可以通过主键来对特定的数据进行增删查改。
相信主键这里理解起来并不是很难,不过后面还要讲外键和唯一键,再加上这两个键有的同学就容易搞混,不过这也是后话,等会就说这两个键。
增删主键
主键不仅可以在最初创建表的时候设定,还可以在建表后再设置主键,当然,也可在建表后删除主键,下面先来演示一下删除主键:

这里直接给drop primary key就行,因为主键是唯一的,只需要告诉mysql你要删除主键就行了,可以看到这里id的PRI没有了。
但数据依旧还是在的:
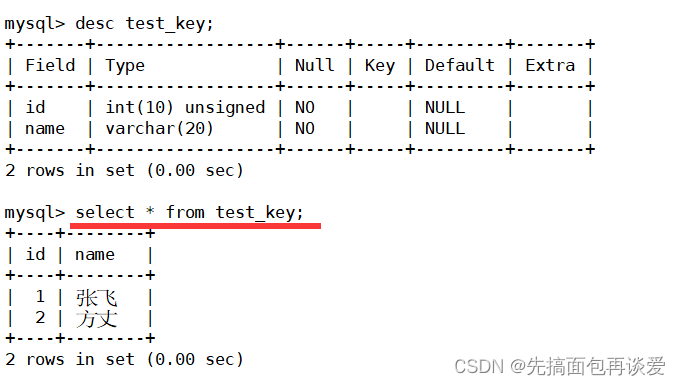
此时没有了主键,就可以插入重复的数据了:

有两个2,不会拦截。
id是正常的,没有主键。
再来加上主键:

就是add,然后括号里面给想要添加主键的列,不过这里出问题了,因为我们刚刚id插入了两个2,那么就得要删一个,或者改一个,这里直接删了吧:

此时再插入2:

主键冲突了。
复合主键
一张表中最多只能有一个主键,不意味着一个表中的主键只能添加给一列,也就是一个主键可以被添加到一列或者多列上,添加到多列上的主键就是复合主键。
来个例子,假如说搞一个选课的表,一个学生可以选门课,一门课也可以被多个学生选取,但是一个学生不能同时多次选一门课,这样就可以将学生和课程都设置为主键:

可以看到id列和course_id列的key都是PRI,但不是说有两个主键,而是说这两个都是主键。只要是id和course_id合起来不重复就行。
插入点数据:

再来一个id相同但course_id不同的,表示一个学生可以选择多门课程:

可以看到是成功的。
再来一个id不同但course_id相同的,表示一门课程可以被多个学生选择:
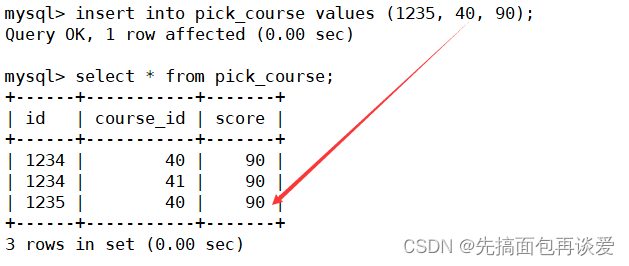
但是id和course_id都相同的是不行的:

这里主键冲突,是将1234-40当成了整体来看才冲突的。
所以复合主键只有多个主键同时重复的时候才会出现主键冲突,只要有PRI列和历史记录中的不一样就能成功插入。故只有所有的主键合起来才是一个主键。
自增长
auto_increment:当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值+1操作,得到一个新的不同的值。一般主键搭配使用,作为逻辑主键,也可以和唯一键搭配使用,不过唯一键还没讲,等会讲唯一键的时候再说。
看例子:

show:
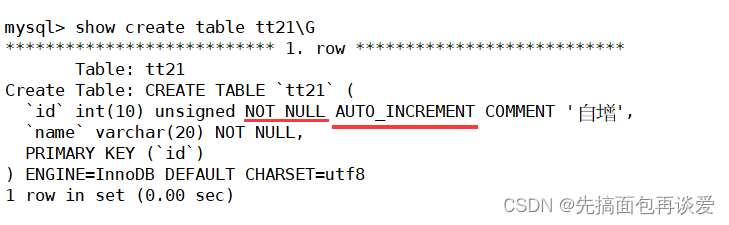
desc:
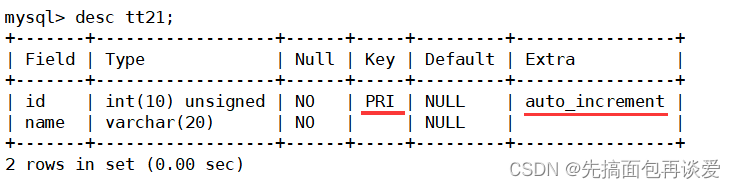
这里id的Extra为auto_increment,插入点数据:

虽然我没有指明id的值,但是1,2,3都自动加上去了。
故自增长不会和其他数冲突,而且还是连续的。再来插入一个:

再来,插入一个指定的id:

再来插入一个1000的:

失败,主键冲突,确实能够履行主键的职责。
再插一个不指明id的,那id是会从5还是1001?

答案是1001。
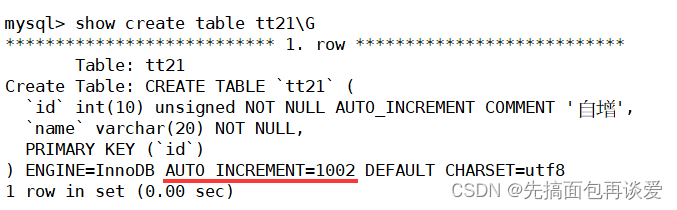
在()外有一个auto_increment=1002,这个值就是下一次不知名id插入数据时的id值。
故除了()里面的id、name属性可以被设置,auto_inrement的值也可被设置,而这个值就是下次省略该字段插入的起始值。
再来个例子验证一下:
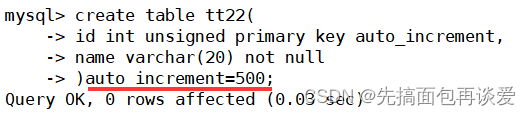
show:
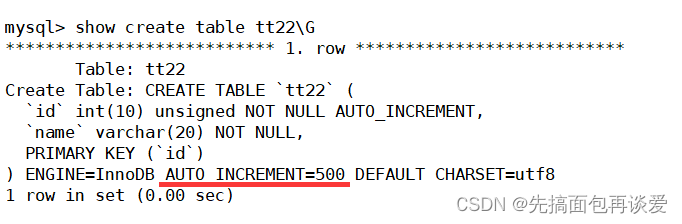
默认插入一个:

所以auto_increment是可以设置起始值的,如果没有设置起始值就会从1开始,设置了就从设置的值开始向后累加。
我们常用的qq在注册的时候会自动给你返回一个账号,登录的时候要用这个返回的账号登录。不像有的是直接注册用户名和密码,直接用你注册的用户名和密码登录。qq号其实就是一个自增长的例子,马化腾的qq就是10001(现在搜不到)。
自增列必须为主键:

不给主键约束会直接报错。
一张表最多只能有一个自增长:

这里报错是只能有一个自增列并且必须为主键,因为auto_increment设置的时候必须要加上主键,但是这里如果给后面的加上主键又会主键重复。
想要获取最后一次插入时的自增长数可以用last_insert_id():

这是刚刚插入v的时候的auto_increment的值,注意不是下一次auto_increment的值,而是上次插入的时候的值,下一次插入的值是在show create table中看的。
再来试一试:
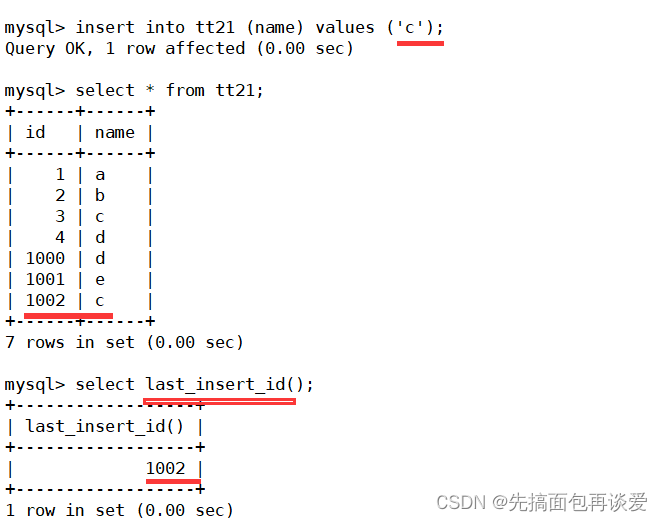
自增长的特点:
- 任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)
- 自增长字段必须是整数
- 一张表最多只能有一个自增长
这里简单讲一下索引:
索引:
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结
构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
后续我会有专门的博客讲索引,这就就是简单的提一嘴。记住索引一般要和主键搭配就行。
唯一键
听名字就知道这个具有唯一性,先不说什么概念,先讲例子:

desc:
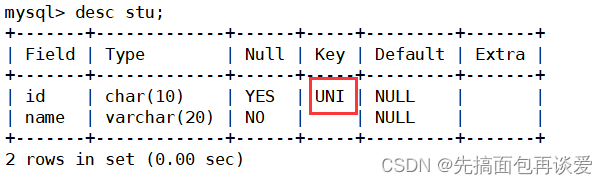
可以看到id的Key列为UNI,就是unique的意思,表示id列的值不能重复。
试试:

插入一个id重复的:

键值冲突了。
但是我可以插入NULL:

甚至还能多插入几个:

为null的时候并不会冲突。前面讲主键的时候说了主键不能冲突也不能为空。
唯一键功能与主键的功能类似,只不过是可以为空,以你为null是不参与计算的,前面也说过:

还是null,所以mysql中的null和C语言中的 ‘\0’,0值,NULL不一样,就是简单的空,什么都没有。
那唯一键是不是一个阉割版的主键呢?
可以说是的,二者在语法上的区别就是是否可以为空。
可能你还不是很理解,二者都能表示为一项,那查找的时候应该选哪个呢?
简单讲讲。
我们身上是有很多的属性值的,比如姓名、年纪、性别、身高、电话、学号等等,而可能不止一个字段需要唯一性,比如说电话和学号(不止这两个),但是一张表只能有一个主键,光用主键来表示唯一性是完全不够的。所以就要用唯一键来修饰其余需要唯一性的列。
任何人都会有各种各样的属性,建表的本质就是通过一张表来描述某些同类对象,表中的每一列就是每个对象身上的属性,列的内容就是属性的值,所以mysql中的一张表其实就相当于C中的结构体,C++中的类,用来描述一个现实的事物。
主键可以表示某一属性的唯一性,通常选主键有两种做法:
- 从我身上具有唯一性的众多列中选出某一列来作为主键。
- 选择一个和业务无关的列作为主键,比如刚讲的auto_increment
每个人身上有众多属性,虽然有很多属性未被选择成主键,但是其可能依旧需要唯一性保证,能作为主键仅仅是该列被选择成了主键而已,所以并不能因为设置了主键就不需要唯一键了,而是因为选择了这一列为主键它才是主键,其他列也可能需要唯一性,所以主键和唯一键并不冲突,而是互相补充的。
来个例子,比如说现在刚开学,班长要统计学生的信息,姓名、电话什么的,建表:
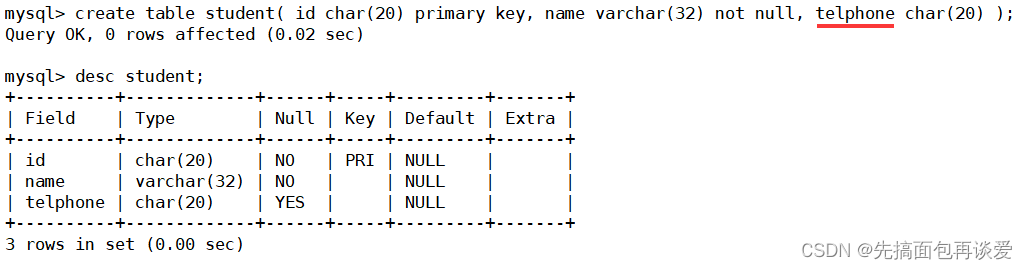
我们日常生活中的电话号是不可能重复的,所以电话号要有唯一性,但是我这里先演示一下不标准的写法,等会再改一下telphone的唯一性。
插入点数据:

很正常。
假如说现在有个班长输入的时候因为粗心看错了,电话号输入的时候和张飞重复了:
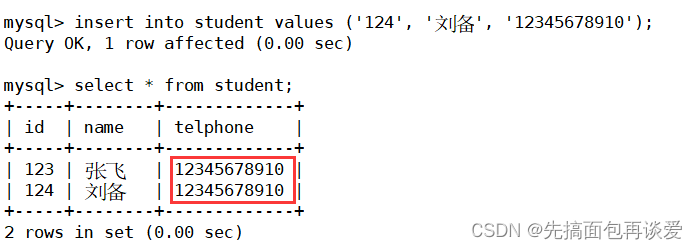
那这就出问题了。
如果辅导员现在要给电话为12345678910的同学打电话,一搜搜出来两个人,在现实生活中是不可能的,比如:

因为没有唯一性约束,所以这里插入的时候允许插入相同的电话,就会导致查的时候对不上,万一班长又因为粗心又插入了一个重复的tel,问题就更大了。
一有重复的就会对不上号,就无法准确定位到某个电话是谁的。
所以这里表的设计是有问题的。因为现实生活中不可能存在电话相同的两个人。所以主键要保证唯一性的同时不能说其他列不需要唯一性,其他列也有可能需要防止插入重复的数据。
所以理解唯一键不能只站在技术方面,还有站在业务的角度。
故主键和唯一键的区别,技术上是一个不允许为空,一个允许为空。二者更大的区别是业务上主键用来表定某行记录在整表中的唯一性,而唯一键的侧重点是让自己插入的列值和表中其他列的列值不要产生冲突,从而保证上层(业务上)字段的唯一性,故二者不对立,而是相互补充。二者的侧重点是不同的。
来重新建一下这个表,先删掉:

再重建:

注意上面的unique后面的key可以加也可以不加。
主键是不能省略key的:

desc:
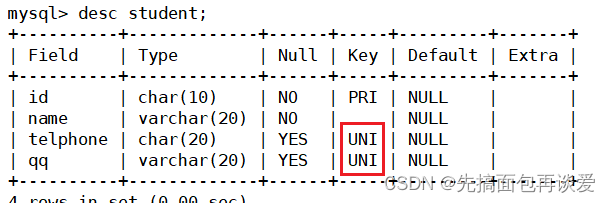
可以看到telphone和qq的Key列为UNI。
来插入点数据:

正常。
来插入点重复的:
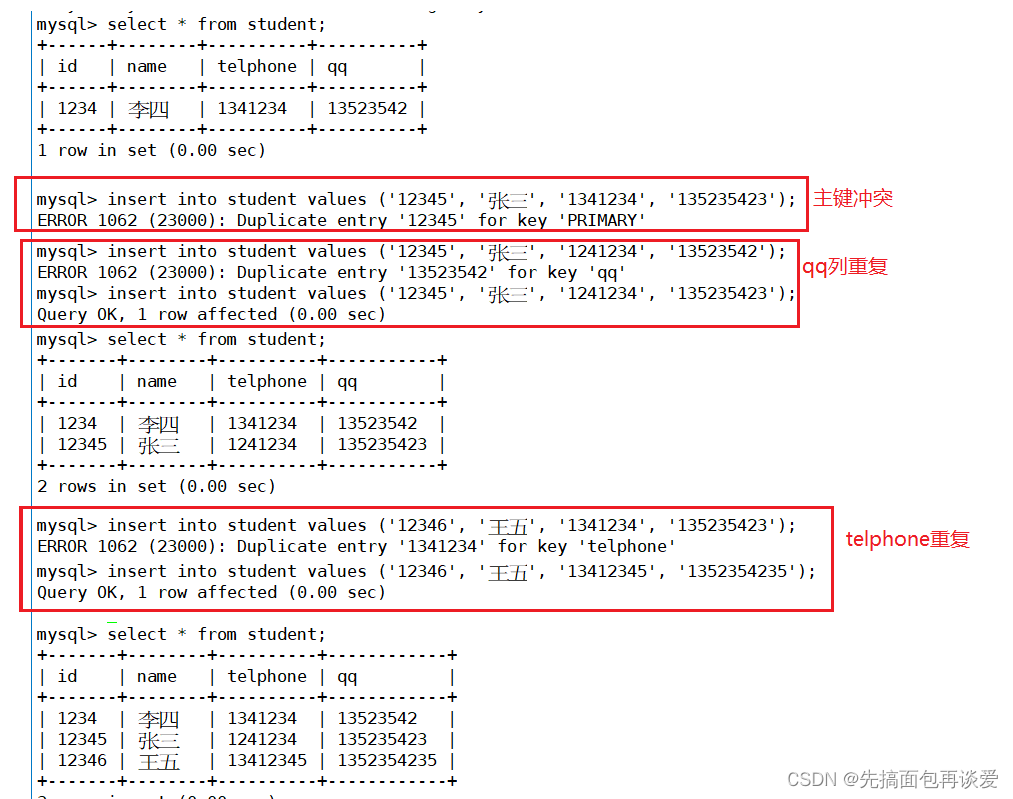
这样tel和qq时一定不会出现冲突的数据的,此即唯一性的约束。
这样能规避掉一些不必要的错误,但是也不能完全避免,架不住有时在填写的时候虽然不是重复,但是填错了,这种人为性的错误数据库防不了,这种错误只有测试业务的时候才能发现,比如说打电话人名对不上。
能不能给唯一键加上非空属性呢?
可以的,先把原先的给出来:
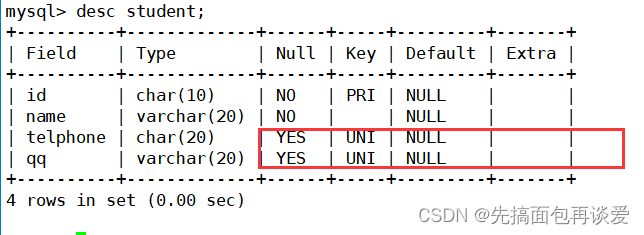
再来修改一下:
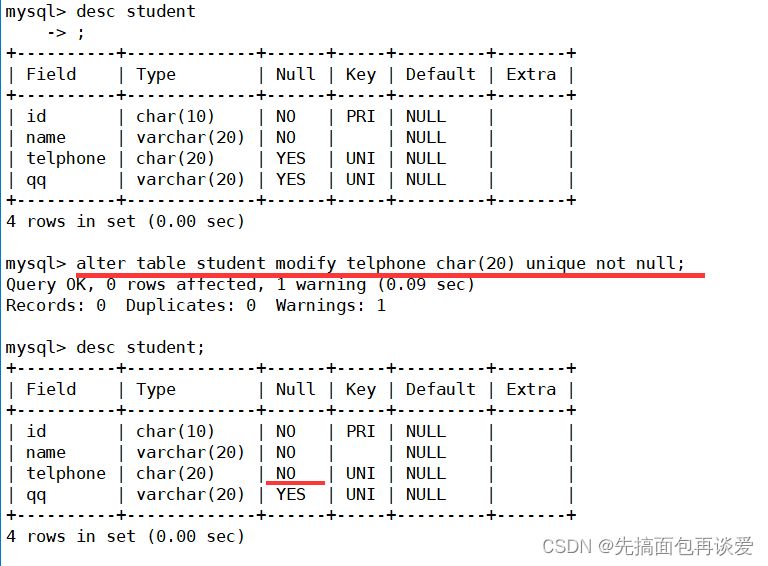
此时telphone就有非空约束了。
插入数据:

加上非空的:
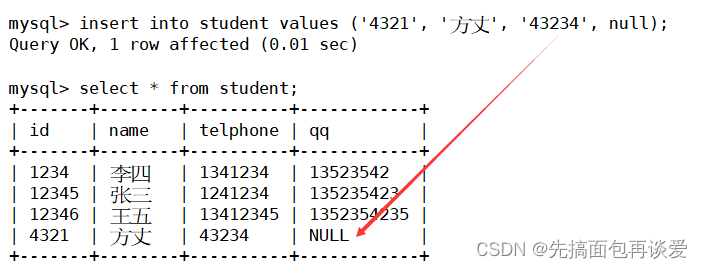
成功。注意这里我并没有对qq加上非空约束,是可以插入NULL的。其实这里的telphone已经可以当做主键了,但是唯一键还是唯一键,和主键的侧重点不一样,长得再像也不是一个人。
最后再总结一下二者的区别:
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多个字段需要唯一性约束的问题。
唯一键的本质和主键差不多,唯一键允许为空,而且可以多个为空,空字段不做唯一性比较。
关于唯一键和主键的区别:
我们可以简单理解成,主键更多的是标识唯一性的。而唯一键更多的是保证在业务上,不要和别的信息出现重复。
一般而言,我们建议将主键设计成为和当前业务无关的字段(比如说一个auto_increment),这样,当业务调整的时候,我们可以尽量不会对主键做过大的调整。
试一下自增长的唯一键:

插入:
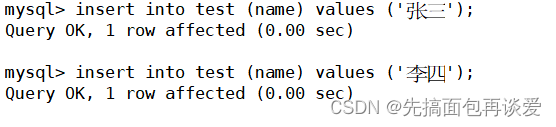
结果:

所以,唯一键也是可以设置自增长的。
外键
外键强调两点,一点是表与表之间的关联,二是表与表之间的约束(外键叫全了就是外键约束)。
来个简单的例子,比如现在有一张学生表:
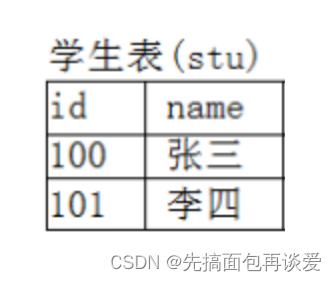
如果我此时还想再统计一下学生的所在班级,可以在后面加一列:
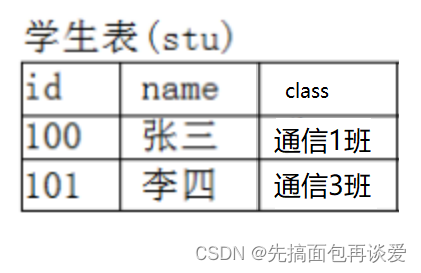
但是如果全部的学生都这样搞,就会出现很多的重复字段:
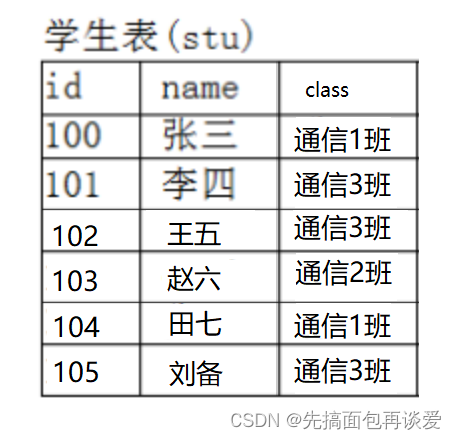
会产生大量的通信x班,数据冗余,所以这个方法其实不太好。
我们可以再搞一张班级表:
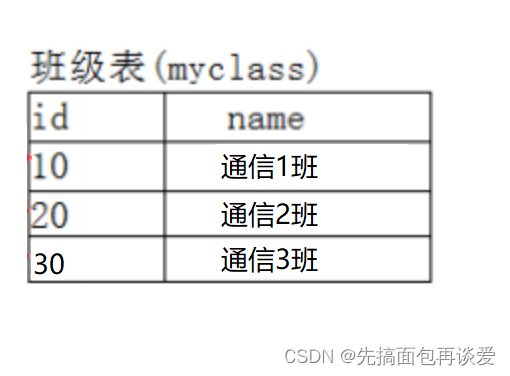
这里班级表中搞一个id来作为主键,然后让刚刚的学生表最后一列存放班级表中的主键:
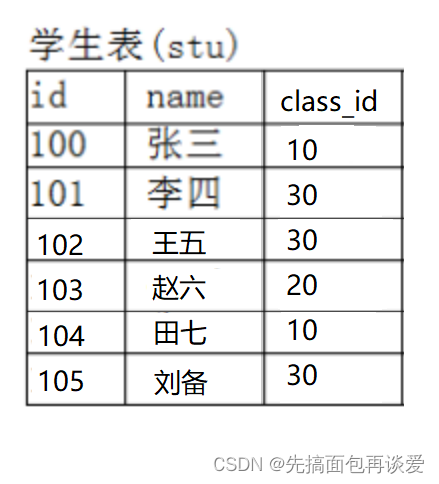
然后就是这样:
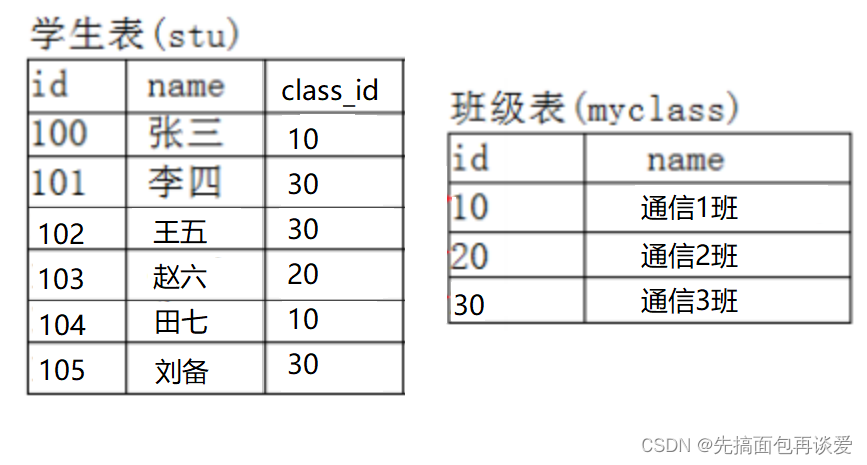
此时这两个表就产生了关联,可通过学生表的class_id来找班级表中的所属班级。
这样就能尽量避免数据冗余的问题。
此时学生表就不是孤立的,而是会与班级表产生关联,前面所讲的约束都是在一张表中做约束,而MySQL是关系型数据库,故一定存在表和表之间的关联。
这样专门用class_id列来和其他表产生关联,这一列就可称为外键(这个概念不完整,这里先简单介绍一下,暂时这样记)。
此时两个表之间还会产生一层主从关系,班级表为主表,学生表为从表,学生表依附于班级表。外键一定是在从表中的,主表只需要负责给从表提供能和自己关联的外键约束就行了。
主键作为外键约束
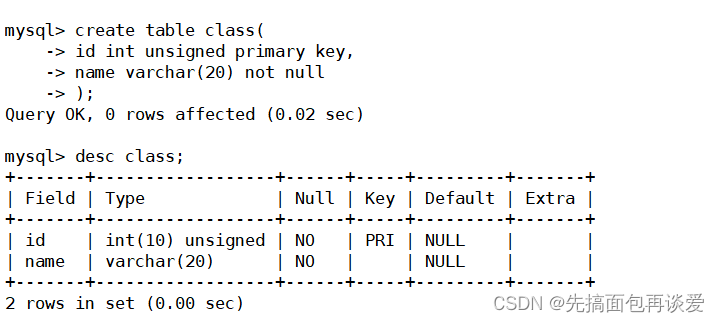
来点sql,重新建一张学生表:

这里先不给class_id外键约束,先来简单演示没有外键的情况。
desc:

再来建一张班级表:
来定两个班级:

然后搞几个学生:

那么第一个就表示张三是通信1班的。
想要知道谁是哪个班的就查一下:

但是这里还没加外键约束,万一有人粗心把班级加错了,加入了一个不在班级表中的班级,比如说:
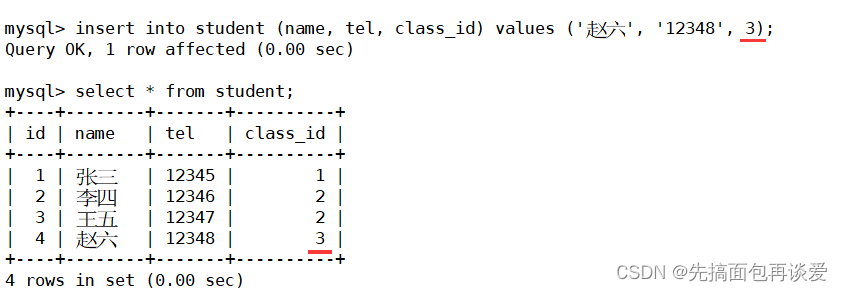
这样对于业务来说是错误的,因为根本不存在id为3的这个班级,但没有添加外键,MySQL是查不出来的。但是如果加了外键就能完全避免这样的问题。这条赵六的记录完全就不应该被插入。
还有一点,如果想要删除某个班级,删之前必须要确定这个班级中没有学生:

这样直接删除,这里的李四和王五就会又出现赵六这条记录的问题。
目前没有添加外键,是能进行插入和删除的,但是不符合正常逻辑,虽然我们上层程序员是可以保证逻辑的严谨性的,可以每次在操作的时候对两个表都查看一下,仔细对比就能避免(但也不能完全避免)。但是实际这样做起来还是有点复杂,每次都要查,万一在查的时候有人又进行了删除呢?这都是问题。
刚开始讲外键的时候说了,外键要讲两个东西,一是关联,二是约束。刚刚建的这两张表只是有了外键之名,意思就是光有一个关联关系,并没有实打实的进行约束,学生表就是从表,班级表就是主表,学生表的class_id与班级表的id相对应。下面就来重新建一张学生表来产生实打实的约束。
班级表不变:
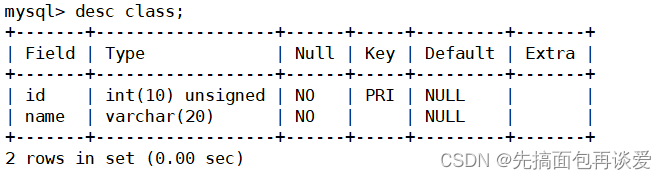
学生表:
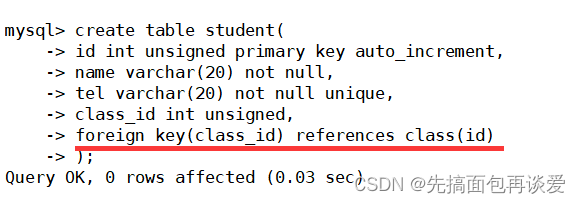
这里外键设置的时候语法就是foreign key(从表外键) references 主表(主表主键或唯一键)。

这里class_id的Key为MUL,就表示这是当前表的外键。
把刚刚删掉的通信102加上:

再重新添加学生:

添加一个不存在的班级:

报错如下:
Cannot add or update a child row: a foreign key constraint fails (`my_test`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`))
就是因为外键约束无法插入。
同样的,这里学生表中的主键也能起作用:

此时如果删除一个班级是删不掉的:
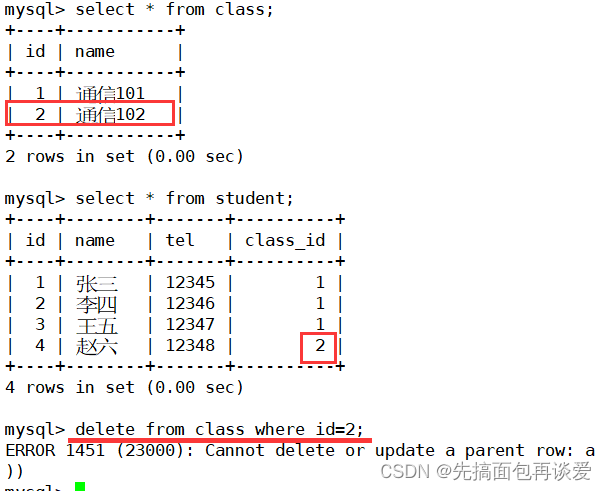
因为通信102这个班还有一个赵六,如果把赵六删掉就能删掉通信102了,因为此时班级已经空了:
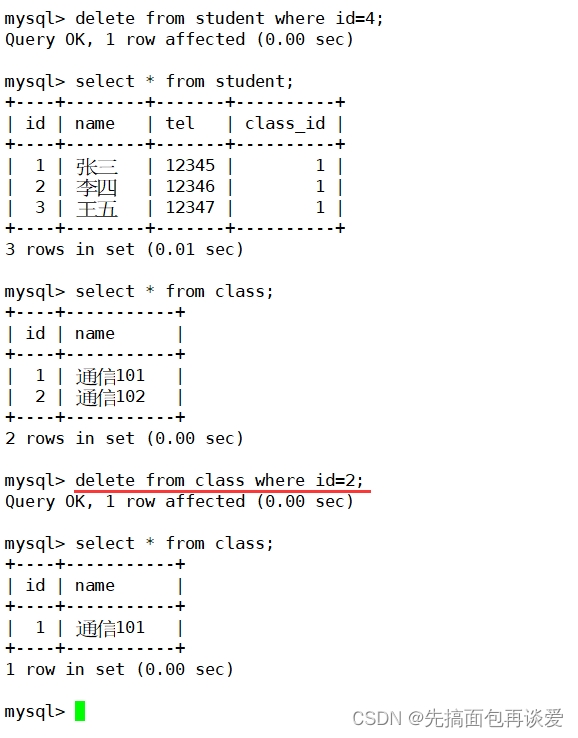
这就是外键的约束,一定能保证向从表中插入数据时外键列数据有效,主表删除时删掉的记录是一定可以删除的,从而保证了数据的完整性。
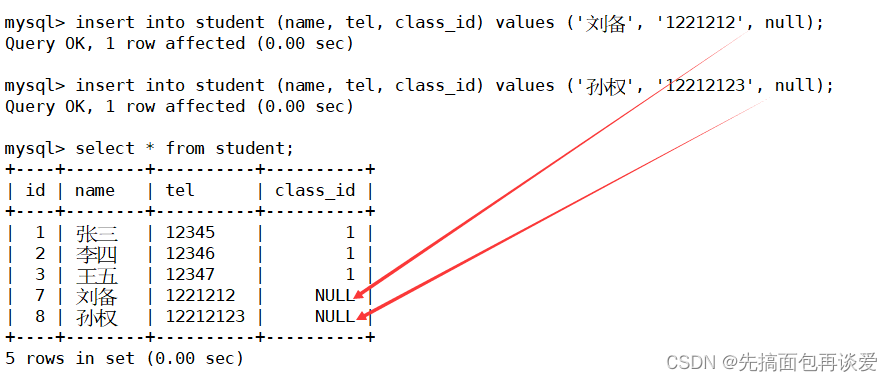
唯一键作为外键约束
来演示一下主表用唯一键作为从表的外键,先建一个主表:

再建一个从表:
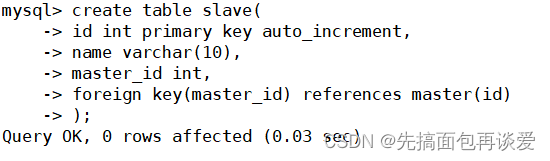
主表插数据:

从表插数据:

再插入个不合法的:

但因为我这里唯一键没有设置非空约束,所以外键插入的时候是允许为空的:
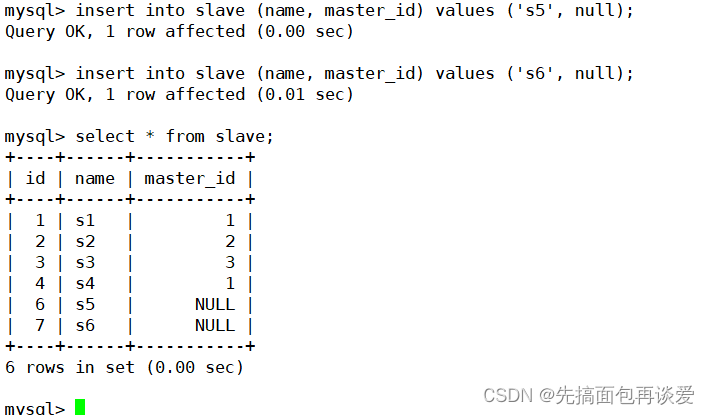
因为null不会参与计算或者比较。
总结
结合前面的博客,我已经将MySQL中的所有DDL语句讲完了。
来个小例子练习一下。
有一个商店的数据,记录客户及购物情况,有以下三个表组成:
- 商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商
provider) - 客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
- 购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
要求:
- 每个表的主外键
- 客户的姓名不能为空值
- 邮箱不能重复
- 客户的性别(男,女)
这里就不细讲了,注意purchase表中的客户号和商品号要设置成外键。
create table if not exists goods(goods_id int primary key auto_increment comment '商品编号',goods_name varchar(32) not null comment '商品名称',unitprice int not null default 0 comment '单价,单位分',category varchar(12) comment '商品分类',provider varchar(64) not null comment '供应商名称'
);create table if not exists customer(customer_id int primary key auto_increment comment '客户编号',name varchar(32) not null comment '客户姓名',address varchar(256) comment '客户地址',email varchar(64) unique key comment '电子邮箱',sex enum('男','女') not null comment '性别',card_id char(18) unique key comment '身份证'
);create table if not exists purchase(order_id int primary key auto_increment comment '订单号',customer_id int comment '客户编号',goods_id int comment '商品编号',nums int default 0 comment '购买数量',foreign key (customer_id) references customer(customer_id),foreign key (goods_id) references goods(goods_id)
);
下一篇讲解对表中内容的操作。
到此结束。。。