Introduction to Diffusion Models
生成模型
主要指的是无监督学习中的生成模型,在无监督学习中的主要任务是让机器学习给定的样本,然后生成一些新的东西出来。比如:给机器看一些图片,能够生成一些新的图片出来,给机器读一些诗,然后能够自己写诗出来。

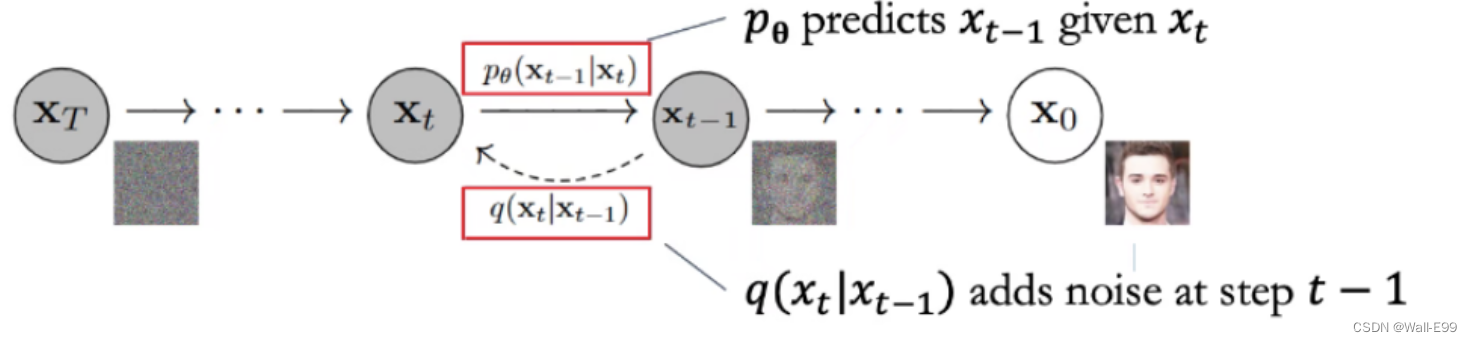
Forward Process
Forward Process I
Given q ( X 0 ) , q ( X t ∣ X t − 1 ) q\left(X_0\right), q\left(X_t \mid X_{t-1}\right) q(X0),q(Xt∣Xt−1), calculate q ( X t ∣ X 0 ) q\left(X_t \mid X_0\right) q(Xt∣X0)
Forward step
X t = α t X t − 1 + 1 − α t ϵ t X_t=\sqrt{\alpha_t} X_{t-1}+\sqrt{1-\alpha_t} \epsilon_t Xt=αtXt−1+1−αtϵt, where ϵ t ∼ N ( 0 , I ) \epsilon_t \sim N(0, I) ϵt∼N(0,I)
Thus, q ( X t ∣ X t − 1 ) = N ( α t X t − 1 , ( 1 − α t ) I ) q\left(X_t \mid X_{t-1}\right)=N\left(\sqrt{\alpha_t} X_{t-1},\left(1-\alpha_t\right) I\right) q(Xt∣Xt−1)=N(αtXt−1,(1−αt)I)
(你保证alpha都是(0,1)的就行)
Forward Process II
X t = α t X t − 1 + 1 − α t ϵ t = α t ( α t − 1 X t − 2 + 1 − α t − 1 ϵ t − 1 ) + 1 − α t ϵ t = α t α t − 1 X t − 2 + α t − α t α t − 1 ϵ t − 1 + 1 − α t ϵ t \begin{gathered} X_t=\sqrt{\alpha_t} X_{t-1}+\sqrt{1-\alpha_t} \epsilon_t \\ =\sqrt{\alpha_t}\left(\sqrt{\alpha_{t-1}} X_{t-2}+\sqrt{1-\alpha_{t-1}} \epsilon_{t-1}\right)+\sqrt{1-\alpha_t} \epsilon_t \\ =\sqrt{\alpha_t \alpha_{t-1}} X_{t-2}+\sqrt{\alpha_t-\alpha_t \alpha_{t-1}} \epsilon_{t-1}+\sqrt{1-\alpha_t} \epsilon_t \end{gathered} Xt=αtXt−1+1−αtϵt=αt(αt−1Xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1Xt−2+αt−αtαt−1ϵt−1+1−αtϵt
Fact: The sum of two normal distributions is still a normal distribution
Therefore: α t − α t α t − 1 ϵ t − 1 + 1 − α t ϵ t ∼ N ( 0 , ( α t − α t α t − 1 + 1 − α t ) I ) \sqrt{\alpha_t-\alpha_t \alpha_{t-1}} \epsilon_{t-1}+\sqrt{1-\alpha_t} \epsilon_t \sim N\left(0,\left(\alpha_t-\alpha_t \alpha_{t-1}+1-\alpha_t\right) I\right) αt−αtαt−1ϵt−1+1−αtϵt∼N(0,(αt−αtαt−1+1−αt)I)
Let α i = 1 − β i \alpha_i=1-\beta_i αi=1−βi
Forward Process III
X t = α t α t − 1 X t − 2 + 1 − α t α t − 1 ϵ X_t=\sqrt{\alpha_t \alpha_{t-1}} X_{t-2}+\sqrt{1-\alpha_t \alpha_{t-1}} \epsilon Xt=αtαt−1Xt−2+1−αtαt−1ϵ
After doing it for many times: X t = α t α t − 1 … α 1 X 0 + 1 − α t α t − 1 … α 1 ϵ X_t=\sqrt{\alpha_t \alpha_{t-1} \ldots \alpha_1} X_0+\sqrt{1-\alpha_t \alpha_{t-1} \ldots \alpha_1} \epsilon Xt=αtαt−1…α1X0+1−αtαt−1…α1ϵ
Therefore: q ( X t ∣ X 0 ) = N ( α t ‾ X 0 , ( 1 − α t ‾ ) I ) q\left(X_t \mid X_0\right)=N\left(\sqrt{\overline{\alpha_t}} X_0,\left(1-\overline{\alpha_t}\right) I\right) q(Xt∣X0)=N(αtX0,(1−αt)I), where α t ‾ = α t α t − 1 … α 1 \overline{\alpha_t}=\alpha_t \alpha_{t-1} \ldots \alpha_1 αt=αtαt−1…α1
Reverse Process
Reverse Process I
Let us use Bayes Theorem
q ( X t − 1 ∣ X t ) = q ( X t − 1 ∣ X t , X 0 ) = q ( X t ∣ X t − 1 , X 0 ) q ( X t − 1 ∣ X 0 ) q ( X t ∣ X 0 ) q\left(X_{t-1} \mid X_t\right)=q\left(X_{t-1} \mid X_t, X_0\right)=\frac{q\left(X_t \mid X_{t-1}, X_0\right) q\left(X_{t-1} \mid X_0\right)}{q\left(X_t \mid X_0\right)} q(Xt−1∣Xt)=q(Xt−1∣Xt,X0)=q(Xt∣X0)q(Xt∣Xt−1,X0)q(Xt−1∣X0)
Reverse Process II
We know these identities are true
q ( X t ∣ X t − 1 , X 0 ) ∼ N ( α t X t − 1 , ( 1 − α t ) I ) q ( X t ∣ X 0 ) = N ( α t ‾ X 0 , ( 1 − α t ‾ ) I ) q ( X t − 1 ∣ X 0 ) = N ( α t − 1 ‾ X 0 , ( 1 − α t − 1 ‾ ) I ) \begin{gathered} q\left(X_t \mid X_{t-1}, X_0\right) \sim N\left(\sqrt{\alpha_t} X_{t-1},\left(1-\alpha_t\right) I\right) \\ q\left(X_t \mid X_0\right)=N\left(\sqrt{\overline{\alpha_t}} X_0,\left(1-\overline{\alpha_t}\right) I\right) \\ q\left(X_{t-1} \mid X_0\right)=N\left(\sqrt{\overline{\alpha_{t-1}}} X_0,\left(1-\overline{\alpha_{t-1}}\right) I\right) \end{gathered} q(Xt∣Xt−1,X0)∼N(αtXt−1,(1−αt)I)q(Xt∣X0)=N(αtX0,(1−αt)I)q(Xt−1∣X0)=N(αt−1X0,(1−αt−1)I)
Reverse Process III
Let us apply these identities to the Bayes Theorem
q ( X t − 1 ∣ X t ) = q ( X t ∣ X t − 1 , X 0 ) q ( X t − 1 ∣ X 0 ) q ( X t ∣ X 0 ) = exp ( − 1 2 ( ( X t − α t X t − 1 ) 2 1 − α t + ( X t − 1 − α ˉ t X 0 ) 2 1 − α ˉ t − 1 − ( X t − α ˉ t X 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t 1 − α t + 1 1 − α ˉ t − 1 ) X t − 1 2 − ( 2 α t 1 − α t X t + 2 α ˉ t − 1 1 − α ˉ t − 1 X 0 ) X t − 1 + C ( X t , X 0 ) ) ) \begin{gathered} q\left(X_{t-1} \mid X_t\right)=\frac{q\left(X_t \mid X_{t-1}, X_0\right) q\left(X_{t-1} \mid X_0\right)}{q\left(X_t \mid X_0\right)} \\ =\exp \left(-\frac{1}{2}\left(\frac{\left(X_t-\sqrt{\alpha_t} X_{t-1}\right)^2}{1-\alpha_t}+\frac{\left(X_{t-1}-\sqrt{\bar{\alpha}_t} X_0\right)^2}{1-\bar{\alpha}_{t-1}}-\frac{\left(X_t-\sqrt{\bar{\alpha}_t} X_0\right)^2}{1-\bar{\alpha}_t}\right)\right) \\ =\exp \left(-\frac{1}{2}\left(\left(\frac{\alpha_t}{1-\alpha_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right) X_{t-1}^2-\left(\frac{2 \sqrt{\alpha_t}}{1-\alpha_t} X_t+\frac{2 \sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}} X_0\right) X_{t-1}+C\left(X_t, X_0\right)\right)\right) \end{gathered} q(Xt−1∣Xt)=q(Xt∣X0)q(Xt∣Xt−1,X0)q(Xt−1∣X0)=exp(−21(1−αt(Xt−αtXt−1)2+1−αˉt−1(Xt−1−αˉtX0)2−1−αˉt(Xt−αˉtX0)2))=exp(−21((1−αtαt+1−αˉt−11)Xt−12−(1−αt2αtXt+1−αˉt−12αˉt−1X0)Xt−1+C(Xt,X0)))
Reverse Process IV
Find σ \sigma σ and μ \mu μ for the normal distribution
exp ( − 1 2 ( ( α t 1 − α t + 1 1 − α ˉ t − 1 ) X t − 1 2 − ( 2 α t 1 − α t X t + 2 α ˉ t − 1 1 − α ˉ t − 1 X 0 ) X t − 1 + C ( X t , X 0 ) ) ) exp ( − ( x − μ ) 2 2 σ 2 ) = exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \begin{aligned} & \exp \left(-\frac{1}{2}\left(\left(\frac{\alpha_t}{1-\alpha_t}+\frac{1}{1-\bar{\alpha}_{t-1}}\right) X_{t-1}^2-\left(\frac{2 \sqrt{\alpha_t}}{1-\alpha_t} X_t+\frac{2 \sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}} X_0\right) X_{t-1}+C\left(X_t, X_0\right)\right)\right) \\ & \exp \left(-\frac{(x-\mu)^2}{2 \sigma^2}\right)=\exp \left(-\frac{1}{2}\left(\frac{1}{\sigma^2} x^2-\frac{2 \mu}{\sigma^2} x+\frac{\mu^2}{\sigma^2}\right)\right) \\ & \end{aligned} exp(−21((1−αtαt+1−αˉt−11)Xt−12−(1−αt2αtXt+1−αˉt−12αˉt−1X0)Xt−1+C(Xt,X0)))exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2))
Reverse Process V
By matching the three terms, we get the solution for μ t , σ t \mu_t, \sigma_t μt,σt
μ t = 1 α t ( X t − 1 − α t 1 − α ˉ t ϵ t ) σ t 2 = ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α t α ˉ t − 1 \begin{gathered} \mu_t=\frac{1}{\sqrt{\alpha_t}}\left(X_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_t\right) \\ \sigma_t^2=\frac{\left(1-\alpha_t\right)\left(1-\bar{\alpha}_{t-1}\right)}{1-\alpha_t \bar{\alpha}_{t-1}} \end{gathered} μt=αt1(Xt−1−αˉt1−αtϵt)σt2=1−αtαˉt−1(1−αt)(1−αˉt−1)
μ t , σ t \mu_t, \sigma_t μt,σt是要我们解的东西
This is what we should use in the reserve process
Next: How to train the encoder ϵ t \epsilon_t ϵt
Loss Function
Want the reverse process p θ ( X ) \boldsymbol{p}_\theta(\boldsymbol{X}) pθ(X) as close as the forward process q ( X ) \boldsymbol{q}(\boldsymbol{X}) q(X)
Use KL divergence as loss to match two distributions
D ( q ( X 0 ) ∥ p θ ( X 0 ) ) = ∫ q ( X 0 ) log ( q ( X 0 ) p θ ( X 0 ) ) d X 0 D\left(q\left(X_0\right) \| p_\theta\left(X_0\right)\right)=\int q\left(X_0\right) \log \left(\frac{q\left(X_0\right)}{p_\theta\left(X_0\right)}\right) d X_0 D(q(X0)∥pθ(X0))=∫q(X0)log(pθ(X0)q(X0))dX0
常用tool:
The Evidence Lower Bound
- E L B O \mathrm{ELBO} ELBO (Evidence Lower Bound)
- Let p θ p_\theta pθ and q θ q_\theta qθ be two distributions, we have:
ln p θ ( x ) ≥ E z ∼ q ϕ [ ln p θ ( x , z ) q ϕ ( z ) ] . \ln p_\theta(x) \geq \mathbb{E}_{z \sim q_\phi}\left[\ln \frac{p_\theta(x, z)}{q_\phi(z)}\right] . lnpθ(x)≥Ez∼qϕ[lnqϕ(z)pθ(x,z)]. - Step 1:
L ( ϕ , θ ; x ) : = E z ∼ q ϕ ( ∣ x ) [ ln p θ ( x , z ) q ϕ ( z ∣ x ) ] . L(\phi, \theta ; x):=\mathbb{E}_{z \sim q_\phi(\mid x)}\left[\ln \frac{p_\theta(x, z)}{q_\phi(z \mid x)}\right] . L(ϕ,θ;x):=Ez∼qϕ(∣x)[lnqϕ(z∣x)pθ(x,z)]. - Step 2:
L ( ϕ , θ ; x ) = E z ∼ q ϕ ( ∣ x ) [ ln p θ ( x , z ) ] + H [ q ϕ ( z ∣ x ) ] = ln p θ ( x ) − D K L ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) . \begin{aligned} L(\phi, \theta ; x) & =\mathbb{E}_{z \sim q_\phi(\mid x)}\left[\ln p_\theta(x, z)\right]+H\left[q_\phi(z \mid x)\right] \\ & =\ln p_\theta(x)-D_{K L}\left(q_\phi(z \mid x) \| p_\theta(z \mid x)\right) . \end{aligned} L(ϕ,θ;x)=Ez∼qϕ(∣x)[lnpθ(x,z)]+H[qϕ(z∣x)]=lnpθ(x)−DKL(qϕ(z∣x)∥pθ(z∣x)). - Conclusion (Many details skipped): Can derive a quadratic lower bound on KL divergence
ps 初步了解了一下clip
CLIP
clip初认识
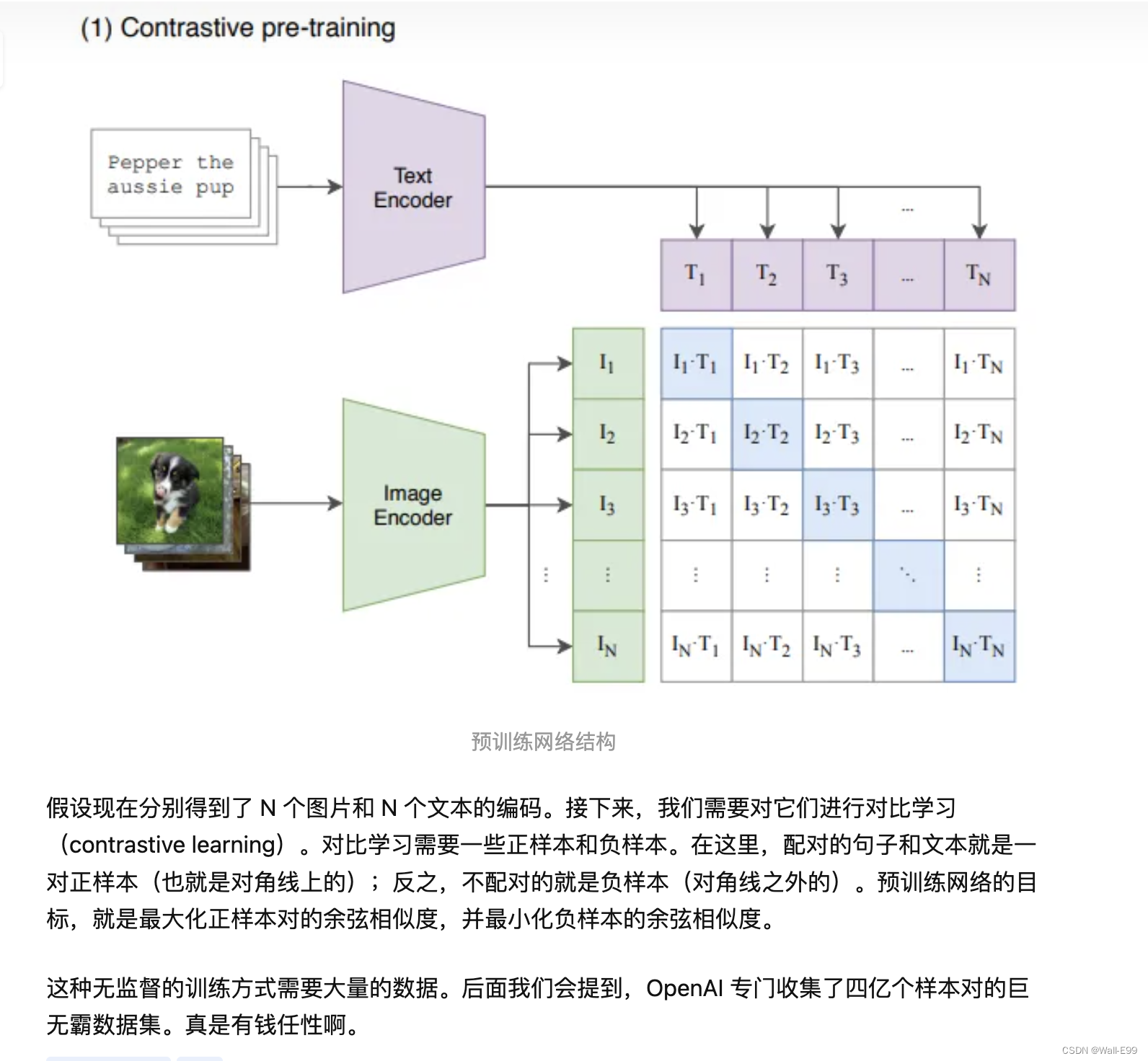
它是一个 zero-shot 的视觉分类模型,预训练的模型在没有微调的情况下在下游任务上取得了很好的迁移效果。作者在30多个数据集上做了测试,涵盖了 OCR、视频中的动作检测、坐标定位等任务。
预训练网络的输入是文字与图片的配对,每一张图片都配有一小句解释性的文字。将文字和图片分别通过一个编码器,得到向量表示。这里的文本编码器就是 Transformer;而图片编码器既可以是 Resnet,也可以是 Vision transformer,作者对这两种结构都进行了考察。
开源了预训练好的模型和 API,可以直接拿来做下游任务的推理:
https://github.com/openai/CLIP
https://openai.com/research/clip
一些可以试一试的项目:
https://github.com/yunhao-tech/Course_project/blob/master/Advanced%20Machine%20learning/Final%20project_CLIP.ipynb
当我们在谈论 Text-To-Image:Diffusion Model
背景
2022最卷的领域-文本生成图像
2021年1月,国际知名AI公司OpenAI公布了其首个文本生成图像模型DALL·E 。2021年12月底,OpenAI再次提出GLIDE模型,此模型能够生成比DALL·E更复杂、更丰富的图像。2022年4月,OpenAI又又又提出DALL·E 2,这次他们已经自信地表示“能够生成真实或者艺术图像”。仅一个月后,2022年5月,Google不甘落后发表其新模型Imagen,在写实性上击败DALL·E 2。
可以发现从2022年初开始,各种新模型如雨后春笋般冒出来,但其实它们背后都是一个模型范式:Diffusion Model 。下文我们就介绍下这个图像界的新贵,它在图像领域已经是比肩GAN的存在,或许其作用会进一步延伸到NLP,最终成为有一个通用模型范式。




![[PyTorch][chapter 63][强化学习-QLearning]](https://img-blog.csdnimg.cn/933bd586568f494fa86a22caa39a6652.png)