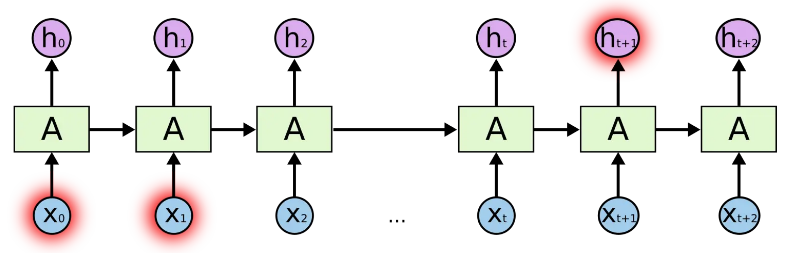
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
Why
LSTM提出的动机是为了解决「长期依赖问题」。
长期依赖(Long Term Dependencies)
在深度学习领域中(尤其是RNN),“长期依赖“问题是普遍存在的。长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖,例如下面例子
eg1: The cat, which already ate a bunch of food, was full.
| | | | | | | | | | |
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10
eg2: The cats, which already ate a bunch of food, were full.
| | | | | | | | | | |
t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10
我们想预测'full'之前系动词的单复数情况,显然full是取决于第二个单词’cat‘的单复数情况,而非其前面的单词food。根据RNN的结构,随着数据时间片的增加,RNN丧失了学习连接如此远的信息的能力。
LSTM vs. RNN

相比RNN只有一个传递状态 ,LSTM有两个传输状态,一个 (cell state),和一个 (hidden state)。(Tips:RNN中的 对于LSTM中的 )
其中对于传递下去的 改变得很慢,通常输出的 是上一个状态传过来的 加上一些数值。
而 则在不同节点下往往会有很大的区别。
Model 详解
状态计算
首先使用LSTM的当前输入 和上一个状态传递下来的 拼接训练得到四个状态。
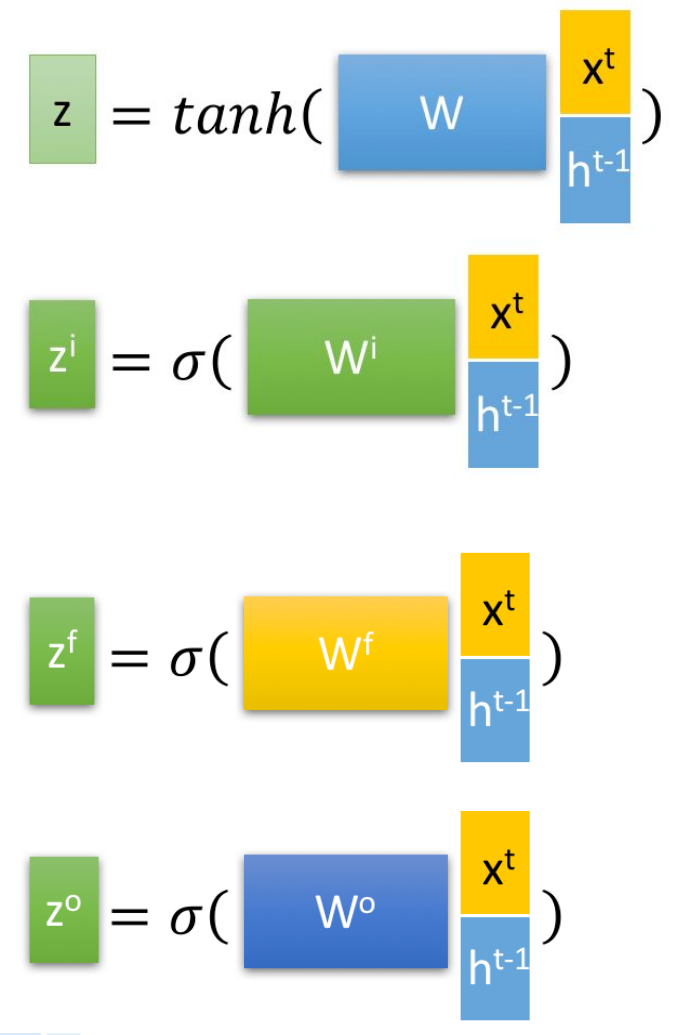
其中, , , 是由拼接向量乘以权重矩阵之后,再通过一个 激活函数转换成0到1之间的数值,来作为一种门控状态。而 则是将结果通过一个 激活函数将转换成-1到1之间的值(这里使用 是因为这里是将其做为输入数据,而不是门控信号)。
计算过程

⊙ 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。 ⊕ 则代表进行矩阵加法。
LSTM内部主要有三个阶段:
-
「忘记阶段」。这个阶段主要是对上一个节点传进来的输入进行 「选择性」忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 (f表示forget)来作为忘记门控,来控制上一个状态的 哪些需要留哪些需要忘。
-
「选择记忆阶段」。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 表示。而选择的门控信号则是由 (i代表information)来进行控制。
❝将上面两步得到的结果相加,即可得到传输给下一个状态的 。也就是上图中的第一个公式。
❞
-
「输出阶段」。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 来进行控制的。并且还对上一阶段得到的 进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 往往最终也是通过 变化得到。
Code
现在,我们从零开始实现长短期记忆网络。 与 8.5节中的实验相同, 我们首先加载时光机器数据集。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
-
初始化模型参数
定义和初始化模型参数。 如前所述,超参数num_hiddens定义隐藏单元的数量。 我们按照标准差0.01的高斯分布初始化权重,并将偏置项设为0。
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
-
定义模型
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
-
训练和预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# perplexity 1.3, 17736.0 tokens/sec on cuda:0
# time traveller for so it will leong go it we melenot ir cove i s
# traveller care be can so i ngrecpely as along the time dime

总结
-
长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。 -
长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。 -
长短期记忆网络可以缓解梯度消失和梯度爆炸。
Ref
-
https://zhuanlan.zhihu.com/p/32085405 -
https://zhuanlan.zhihu.com/p/42717426 -
https://zh.d2l.ai/chapter_recurrent-modern/lstm.html
本文由 mdnice 多平台发布