为什么会存在分布式锁?
经典场景-扣库存,多人去同时购买一件商品,首先会查询判断是否有剩余,如果有进行购买并扣减库存,没有提示库存不足。假如现在仅存有一件商品,3人同时购买,三个线程同时执行方法,第一人通过了库存>0的校验,此时线程阻塞,第二人通过校验后抢先购买,此时库存已经为0,第一人继续执行扣减,库存就为-1,也就是【超卖】。
首先会想到加锁的方式解决,使用synchronized或者ReentrantLock解决,但如果多个服务器同时对一个共享资源操作时,多个服务器的内存是不共享的,加锁只能锁住当前服务器的进程。但在分布式系统下,例如使用nginx负载均衡,请求会发送到不同的tomcat容器。
1、基于关系型数据库
(1)lock表

基于主键或者唯一索引,一个线程尝试获取锁时往表中插入一条数据,插入成功则表示获取锁成功,获取锁依赖于数据库,架构简单,但是一旦出现宕机等问题,锁就无法释放,需要设置一个定时任务清理数据。并且获取不到锁的线程,需要一直等待,轮询查询什么时候可获取锁。
(2)悲观版本
锁数据提前初始化,抢锁时,使用select ...... for update; 数据库的悲观锁可以自动阻塞其他等待锁的线程,实现锁等待的功能,如果持有锁的节点宕机,数据库事务会自动回滚,锁自然释放。
这种锁可能存在两个问题:
第一个是MySQL可能会对查询做优化,对于小表可能采用表锁代替行锁,表中不同的锁之间就变成串行互斥的关系;
第二个是使用悲观锁需要开启事务,需要一直占用数据库的连接,如果锁过多,则对数据库造成压力。
2、基于Redis
(1)setnx+uuid+finally
setnx命令,只有key不存在时,才能添加成功,达到加锁的目的
void reduceStock() {//uidString uuid = UUID.randomUUID().toString();// 获取锁///Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, "1");// 设置锁过期时间//redisTemplate.expire("lock",30, TimeUnit.SECONDS);// 解决原子性问题boolean result = redisTemplate.opsForValue().setIfAbsent(lock, uuid, 10, TimeUnit.SECONDS);if (lock) {try{int num = stockMapper.selectNum();if(num > 0) {//扣减库存stockMapper.reduceStock();}else{log.info("库存不足");}} finally {//校验是否是当前线程的锁String lockValue = redisTemplate.opsForValue().get("lock");if(lockValue.equals(uuid)) {redisTemplate.delete("lock"); } }} else {log.info("未获取锁");}
}- 在线程A获取锁之后,如果出现宕机或者代码报错异常,锁不会释放,需要在finally中释放锁。
- 仍存在一个问题,如果在执行释放锁逻辑的时候服务器宕机,释放锁失败,在重启服务器后,加锁的数据又被恢复,就出现死锁的问题。需要再redis中添加锁的过期时间。
- 那么又会出现,在获取锁和设置时间之间,如果存在宕机问题,时间会失败,也就是不满足原子性。通过setnx可以同时满足。(Lua脚本,后续阐述)
- 此时又会出现,在高并发的情况下,如果锁设置30s,线程A获取到锁,但方法执行了35s,线程A的锁已经过期,线程B重新获取锁并开始执行方法执行到5s时,线程A执行finally释放锁,导致线程A将线程B的锁释放。可以设置一个uuid表示当前线程的锁。
(2)redisson
void reduceStock() {RLock lock = redissonClient.getLock("lock");if (lock.tryLock()) {try {int stockNum = stockMapper.selectNum();if (stockNum > 0) {stockMapper.reduceStock();} else {log.info("库存不足");}} finally {lock.unlock();}} else {log.info("未获取锁");}
}- 使用:通过getLock方法获取到RLock对象,tryLock或lock()来进行加锁(Lua脚本);
- 底层:reids的key是锁的名称,这个key对应的值是一个HASH结构,HASH的key是持有锁的客户端ID+线程ID,value初始化为1表示锁的重入次数,当其他线程去获取锁时,使用redis提的的subcribe特性等待redis的key的变动,方式轮询造成的系统消耗资源。
- 看门狗:当前持有锁的线程在redission客户端初始化一个watch dog线程,定时刷新key的过期时间,默认是30s,监听主线程是否还在执行,如果还在执行通过LUA脚本每10s给锁续期30秒。这个值可以config自定义。
- 【注意】加锁时,如果使用 tryLock(long t1,long t2, TimeUnit unit) 或 lock(long t1,long t2, TimeUnit unit) 第二个参数不是-1,则看门狗无法生效;
LUA脚本为什么能保证原子性呢?
因为redis是单线程的,当redis执行lua脚本时,lua脚本将一系列操作封装成一个命令,redis会把lua作为一个整体任务,加入到一个队列,单线程执行任务会按照队列的顺序依次执行,在执行时lua是不会被其他线程请求打断的,从而保证原子性。
优点:
减少网络开销,一次请求和接受一次响应;直接在redis上执行无需解析和转换;
缺点:
新的语言;需要单独存储和管理,需要维护;占用redis资源和时间;
源码解析
首先找到这个方法的实现


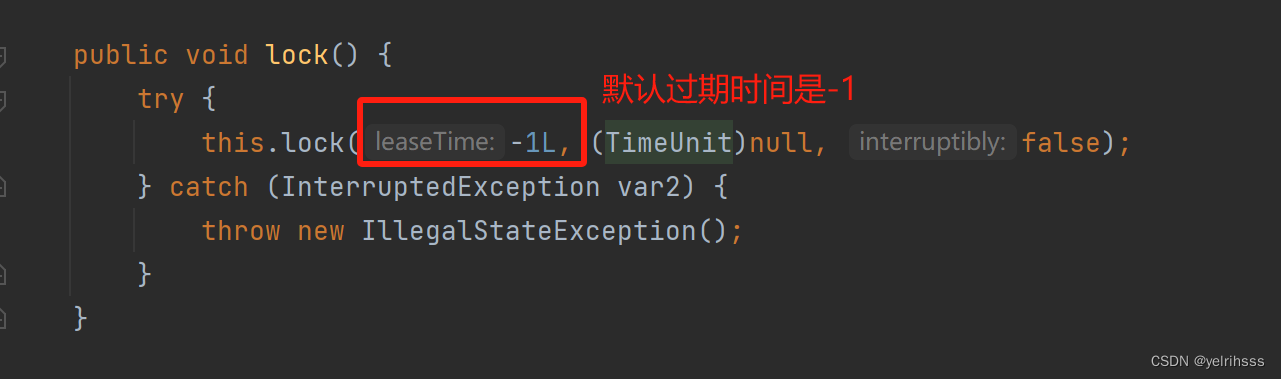
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {long threadId = Thread.currentThread().getId();//【核心方法】,尝试去获取锁,返回null时表示获取成功Long ttl = tryAcquire(-1, leaseTime, unit, threadId);if (ttl == null) {return;}//通过线程id去订阅锁CompletableFuture<RedissonLockEntry> future = subscribe(threadId);pubSub.timeout(future);RedissonLockEntry entry;if (interruptibly) {entry = commandExecutor.getInterrupted(future);} else {entry = commandExecutor.get(future);}try {//锁自旋while (true) {//尝试获取锁,获取成功后,break跳出循环ttl = tryAcquire(-1, leaseTime, unit, threadId);if (ttl == null) {break;}//获取锁成功,并且获取到锁的线程需要等待一段时间ttlif (ttl >= 0) {try {entry.getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);} catch (InterruptedException e) {if (interruptibly) {throw e;}//如果发生中断,根据 interruptibly 参数判断是否重新尝试获取许可entry.getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);}} else {//获取锁成功,但获取到锁的线程无需等待,可以直接执行后续操作if (interruptibly) {entry.getLatch().acquire();} else {entry.getLatch().acquireUninterruptibly();}}}} finally {//取消订阅unsubscribe(entry, threadId);}
// get(lockAsync(leaseTime, unit));}
首先看核心代码:


Lua脚本分析:

刷新时间:

这里为什么要使用ConCurrentHashMap呢?
锁的过期时间刷新任务需要在不同的节点之间共享,确保在一个节点续约锁的时候,其他节点也能够知道锁的状态,让不同的节点能够访问和更新相同的数据结构,保证一致性。其中putIfAbsent 也是原子的,防止并发问题。
看门狗:


(3) RedLock
redission解决了锁续期的问题,但是在redis集群中,主从复制是有延时性的。例如,当线程A获取锁成功后,主节点保存了锁信息,当主节点还未同步到从节点锁信息时,主节点宕机,从节点切换为主节点后,线程的锁就丢失了。
而使用RedLock解决这个问题,就是认为每台redis都是独立的主节点,在加锁时,会记录开始加速的时间,以及加锁成功后的时间。
例如:5台redis服务器
- 客户端获取当前毫秒级的时间戳,设置超时时间ttl=5
- 向5个redis服务发起请求,保证全局唯一的value请求key锁
- 如果存在3个(一半以上)那么就是获取锁成功,否则失败
- 如果失败,或者超过ttl超过5,则向所有的redis服务发出解锁请求
- 获取锁失败后,在 随机时间后重试获取锁,同时重试需要限制次数(随机时间是防止过多的客户端尝试去获取,但孩子有一台能获取到,导致大批出现失败的问题)
【注意】向redis服务建立网络连接时,要设置一个超时时间,避免redis服务宕机,客户端仍在等待,官方建议5-50毫秒之间。
如果所有节点同时宕机,怎么办?参考

延迟重启:reids同步到磁盘方式默认1次/s,在redis崩溃后,等待ttl之后再重启。
ttl时间后全部锁都过期,不会对现有的锁造成影响,但在ttl时间内是宕机状态,影响性能和使用。
(4)基于zookeeper
后续学到,继续更新




![23111701[含文档+PPT+源码等]计算机毕业设计javaweb点餐系统全套餐饮就餐订餐餐厅](https://img-blog.csdnimg.cn/img_convert/5ba3b2e41f5bf233bf4cddda4a3181af.png)