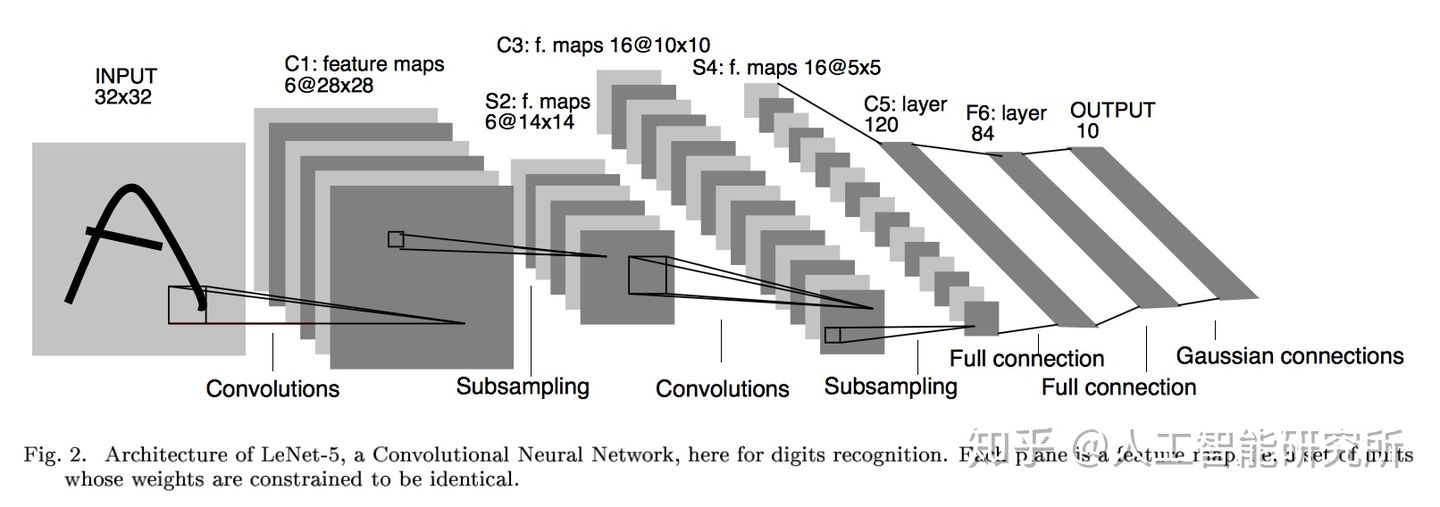
深入了解性能
-
索引类型
本例中,索引类型对查询速度、token 用量或评估没有明显影响。这可能是因为数据量较小的关系。索引类型对较大语料库可能更重要。
-
Embedding 模型

text-embedding-ada-002 在准确性(0.72,平均 0.60)和答案相关度(0.82,平均0.62)上优于 MiniLM Embedding 模型。两者在上下文相关度上表现一致。这个结果可能是 OpenAI Embedding 更适合百科信息的缘故。
-
相似度 top-K
top-k 的增加可以略微提高检索质量(通过上下文相关度测量)。检索的文本块越多,检索器获取高质量上下文的可能性越大。
top-K 的增加也改善了准确性(0.71,平均 0.62)和答案相关度(0.76,平均0.68)。检索更多上下文文本块可以为语言模型提供更多支持其结论的内容。但是更高的 top-K 意味着更高的 token 使用成本(每次调用平均需要额外使用 590 个 token)。

-
分块大