一、什么是分区
MySQL分区是一种数据库设计和管理技术,它允许你将表分割成独立的、具有特定规则的存储单元。每个分区可以独立地进行管理,包括备份、恢复和优化。分区的主要目的是提高查询性能、简化维护以及实现数据的更有效管理。
以下是MySQL分区的一些关键概念:
-
分区键(Partition Key): 分区键是用于将表数据分割成不同部分的列。分区键的选择通常取决于你的查询模式和数据分布。常见的分区键包括日期、范围、列表等。
-
分区类型: MySQL支持多种分区类型,包括范围分区、列表分区、哈希分区等。每种分区类型都有其适用的场景,选择合适的分区类型取决于你的需求。
-
分区表的创建: 你可以在创建表的时候指定分区方式,也可以在表已经存在的情况下通过
ALTER TABLE语句进行分区。在创建或更改分区表时,你需要指定分区键和每个分区的规则。 -
分区操作: 分区表的操作通常包括将数据插入到特定的分区、查询特定分区的数据、合并或拆分分区等。这些操作使得你可以更灵活地管理大量数据。
-
性能提升: 使用分区可以显著提高查询性能,特别是在处理大型数据集时。当查询只涉及到特定分区时,数据库引擎只需要扫描相关的分区,而不是整个表。
-
数据维护: 分区可以简化备份和恢复操作,因为你可以只备份或恢复特定的分区。此外,对于一些表维护操作,如重建索引,也可以只针对特定分区进行。
分区是一个高级的数据库设计和管理特性,通常在处理大型数据集或者需要高性能查询的情况下使用。在使用分区时,需要考虑好分区键的选择和分区规则,以充分发挥其优势
二、为什么分区
MySQL数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去。
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
三、分区类型
1、RANGE 分区:
基于属于一个给定连续区间的列值,把多行分配给分区。
2、LIST 分区:
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
3、HASH分区:
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式。
4、KEY分区:
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
5、复合分区:
基于RANGE/LIST 类型的分区表中每个分区的再次分割。子分区可以是 HASH/KEY 等类型。
四、以时间分区为例
1、创建表
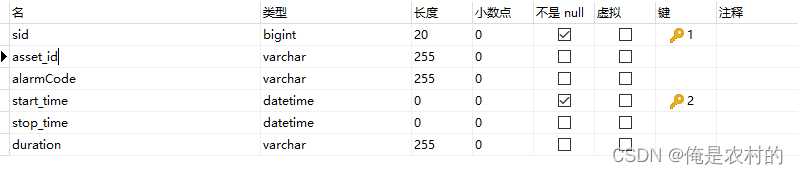
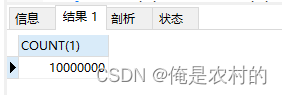
该表生成1000万的数据
2、创建分区
要以start_time字段做分区字段,那么start_time必须是主键
alter table alarm_record_year DROP PRIMARY KEY, ADD PRIMARY key(sid, start_time);分区:按年分区,每年做一个分区
-- 新建,年分区
ALTER TABLE alarm_record_year
PARTITION BY RANGE (year(start_time))
(PARTITION p0001 VALUES LESS THAN (2022), -- 2021PARTITION p0002 VALUES LESS THAN (2023), -- 2022PARTITION p0002 VALUES LESS THAN (2024), -- 2023PARTITION p_max VALUES LESS THAN (maxvalue) -- 不属于任何分区的数据 maxvalue是最后一个分区,后面不能再往后加分区
);解释:值是2022的存的是小于2022年的数据,值是maxvalue存的是不在任何分区中的数据
查询分区
-- 年-查询分区
select partition_name, partition_description as val from information_schema.partitions
where table_name='alarm_record_year' and table_schema='lyc';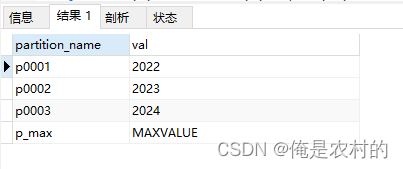
3、查询
3.1、查询是否走分区
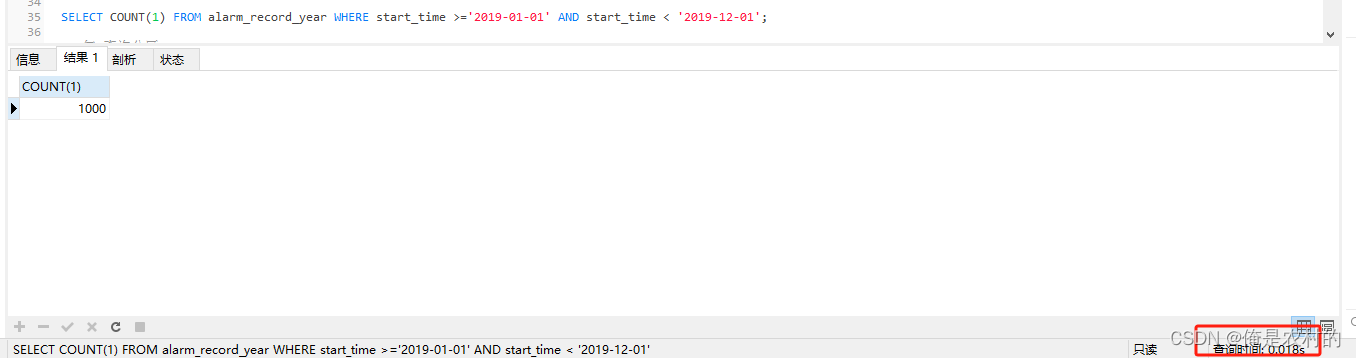
EXPLAIN SELECT COUNT(1) FROM alarm_record_year WHERE start_time >='2019-01-01' AND start_time < '2019-12-01';
3.2、对比加分区和不加分区的执行时间
没加分区的执行时间(4s)
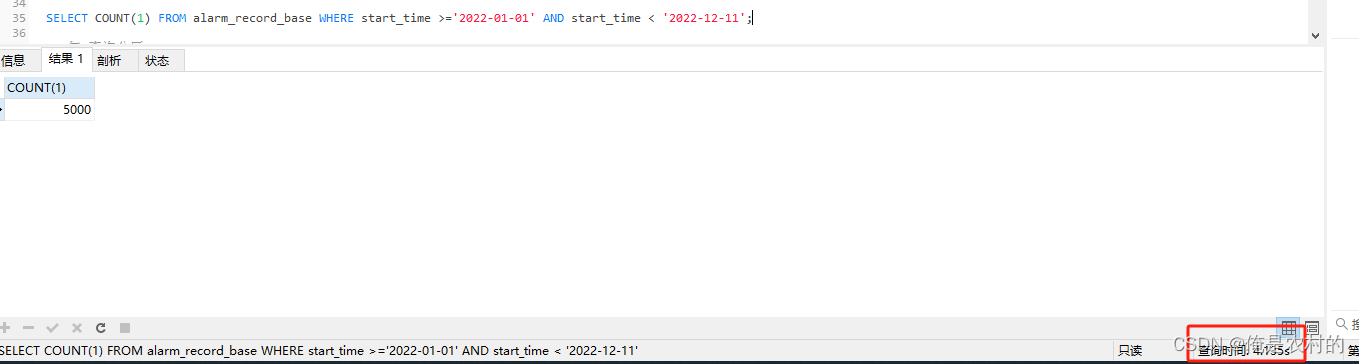
加分区的执行事件(0.018s)
五、其他操作
1、新建分区
ALTER TABLE alarm_record
PARTITION BY RANGE (year(start_time))
(PARTITION p_max VALUES LESS THAN (MAXVALUE)
);2、添加分区
ALTER TABLE alarm_record
ADD PARTITION
(PARTITION p0003 VALUES LESS THAN (2027)
);3、修改分区(注意:只能修改最后的一个分区,这样可以变相的新增一个分区)
ALTER TABLE alarm_record_year REORGANIZE PARTITION p_max INTO
(
PARTITION p0003 VALUES LESS THAN (2024) ,
PARTITION p_max VALUES LESS THAN (MAXVALUE)
);4、删除分区(注意:删除分区会删除分区内的数据,删除前备份!备份!备份!)
-- 删除某个分区
ALTER TABLE alarm_record_year DROP PARTITION p_max;-- 删除全部分区
ALTER TABLE alarm_record REMOVE PARTITIONING;5、查询分区
select partition_name, partition_description as val from information_schema.partitions
where table_name='alarm_record' and table_schema='lyc';六、实战:以天为单位分区
生成某个年份到某个年份的所有的日期分区。例如:2020-01-01到2023-12-12
1、创建执行过程
入参:两个年份(2020,2023)
CREATE DEFINER=`root`@`localhost` PROCEDURE `create_day`(IN f_year_start YEAR,IN f_year_end YEAR
)
BEGINDECLARE v_days INT UNSIGNED DEFAULT 365;DECLARE v_year DATE DEFAULT '2020-01-01';DECLARE v_partition_name VARCHAR(64) DEFAULT '';DECLARE v_start_time DATE;DECLARE i,j INT UNSIGNED DEFAULT 1;SET @stmt = '';SET @stmt_begin = 'ALTER TABLE alarm_record_day PARTITION BY RANGE COLUMNS (start_time)(';SET i = f_year_start;WHILE i <= f_year_end DO SET v_year = CONCAT(i,'-01-01');SET v_days = DATEDIFF(DATE_ADD(v_year,INTERVAL 1 YEAR),v_year); SET j = 1;WHILE j <= v_days DOSET v_start_time = DATE_ADD(v_year,INTERVAL j DAY);SET v_partition_name = CONCAT('p',i,'_',LPAD(j,3,'0'));SET @stmt = CONCAT(@stmt,'PARTITION ',v_partition_name,' VALUES LESS THAN (''',v_start_time,'''),');SET j = j + 1; END WHILE;SET i = i + 1; END WHILE;SET @stmt_end = 'PARTITION p_max VALUES LESS THAN (maxvalue))';SET @stmt = CONCAT(@stmt_begin,@stmt,@stmt_end);PREPARE s1 FROM @stmt;EXECUTE s1;DROP PREPARE s1;SELECT NULL,NULL,NULL INTO @stmt,@stmt_begin,@stmt_end;END2、执行
CALL create_day('2022','2023');3、查询所有分区
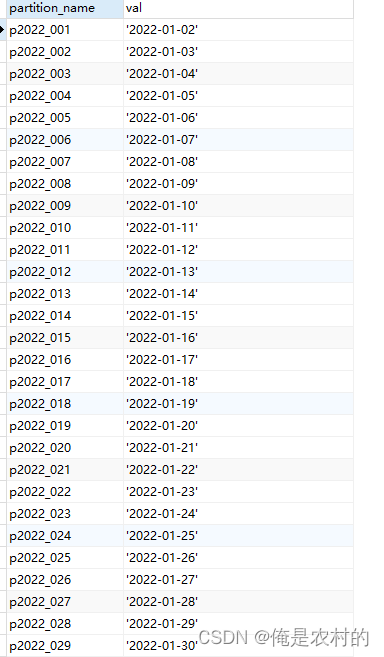
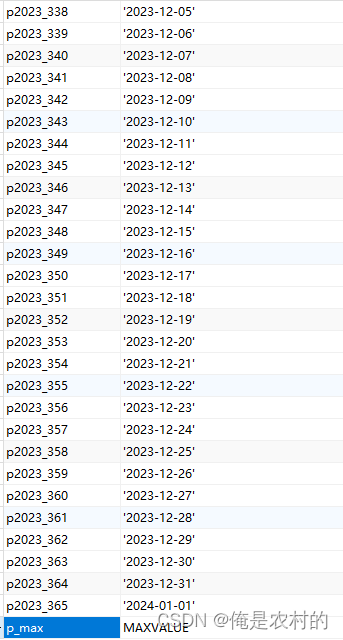
七、实战:动态生成天的分区
1、创建执行过程
入参:表名+需要保留数据时间(天)
CREATE DEFINER=`root`@`localhost` PROCEDURE `UPDATE_EXCHANGE_TABLE_PARTITION`(in table_name VARCHAR(50), keep_days INT)
BEGINdeclare create_index INT DEFAULT(0);declare create_p_name VARCHAR(100);declare create_p_description VARCHAR(100);declare drop_index INT DEFAULT(0);declare drop_count INT DEFAULT(0);declare drop_date VARCHAR(100); declare drop_p_name VARCHAR(100);set create_p_name = CONCAT('p', DATE_FORMAT(DATE_ADD(now(), INTERVAL 1 DAY), '%Y%m%d'));set create_p_description = DATE_FORMAT(DATE_ADD(now(), INTERVAL 1 DAY), '%Y-%m-%d 23:59:59');set @create_sql = CONCAT('alter table ', table_name, ' add PARTITION (partition ', create_p_name ,' values less than(TO_DAYS(\"', create_p_description ,'\")));');SELECT concat('@create_sql is ', @create_sql);PREPARE stmt_create FROM @create_sql;EXECUTE stmt_create;set drop_date = DATE_FORMAT(DATE_SUB(now(), INTERVAL keep_days DAY), '%Y-%m-%d 23:59:59');SELECT concat('drop_date is ', drop_date);set drop_p_name = CONCAT('p', DATE_FORMAT(DATE_SUB(now(), INTERVAL keep_days DAY), '%Y%m%d'));set @drop_sql = CONCAT('alter table ', table_name, ' drop partition ', drop_p_name);SELECT concat('@drop_sql is ', @drop_sql);PREPARE stmt_drop FROM @drop_sql;EXECUTE stmt_drop;END2、定时执行函数过程
-- 开启事件
SET GLOBAL event_scheduler = ON;-- 从2012-11-28 00:01:00开始,定时每天执行,执行表为db_data,保留7天的数据
alter EVENT RECEIVE_RECORD_PARTITION_EVENT ON SCHEDULE
EVERY 1 DAY STARTS '2012-11-28 00:01:00'
DO
begin CALL UPDATE_EXCHANGE_TABLE_PARTITION('db_data', 7);
end