本章概要
- 数组特性
- 用于显示数组的实用程序
- 一等对象
- 返回数组
简单来看,数组需要你去创建和初始化,你可以通过下标对数组元素进行访问,数组的大小不会改变。大多数时候你只需要知道这些,但有时候你必须在数组上进行更复杂的操作,你也可能需要在数组和更加灵活的 集合 (Collection)之间做出评估。因此本章我们将对数组进行更加深入的分析。
注意: 随着 Java Collection 和 Stream 类中高级功能的不断增加,日常编程中使用数组的需求也在变少,所以你暂且可以放心地略读甚至跳过这一章。但是,即使你自己避免使用数组,也总会有需要阅读别人数组代码的那一天。那时候,本章依然在这里等着你来翻阅。
数组特性
明明还有很多其他的办法来保存对象,那么是什么令数组如此特别?
将数组和其他类型的集合区分开来的原因有三:效率,类型,保存基本数据类型的能力。在 Java 中,使用数组存储和随机访问对象引用序列是非常高效的。数组是简单的线性序列,这使得对元素的访问变得非常快。然而这种高速也是有代价的,代价就是数组对象的大小是固定的,且在该数组的生存期内不能更改。
速度通常并不是问题,如果有问题,你保存和检索对象的方式也很少是罪魁祸首。你应该总是从 ArrayList (来自 集合)开始,它将数组封装起来。必要时,它会自动分配更多的数组空间,创建新数组,并将旧数组中的引用移动到新数组。这种灵活性需要开销,所以一个 ArrayList 的效率不如数组。在极少的情况下效率会成为问题,所以这种时候你可以直接使用数组。
数组和集合(Collections)都不能滥用。不管你使用数组还是集合,如果你越界,你都会得到一个 RuntimeException 的异常提醒,这表明你的程序中存在错误。
在泛型前,其他的集合类以一种宽泛的方式处理对象(就好像它们没有特定类型一样)。事实上,这些集合类把保存对象的类型默认为 Object,也就是 Java 中所有类的基类。而数组是优于 预泛型 (pre-generic)集合类的,因为你创建一个数组就可以保存特定类型的数据。这意味着你获得了一个编译时的类型检查,而这可以防止你插入错误的数据类型,或者搞错你正在提取的数据类型。
当然,不管在编译时还是运行时,Java都会阻止你犯向对象发送不正确消息的错误。然而不管怎样,使用数组都不会有更大的风险。比较好的地方在于,如果编译器报错,最终的用户更容易理解抛出异常的含义。
一个数组可以保存基本数据类型,而一个预泛型的集合不可以。然而对于泛型而言,集合可以指定和检查他们保存对象的类型,而通过 自动装箱 (autoboxing)机制,集合表现地就像它们可以保存基本数据类型一样,因为这种转换是自动的。
下面给出一例用于比较数组和泛型集合:
CollectionComparison.java
import java.util.*;import static com.example.test.ArrayShow.show;class BerylliumSphere {private static long counter;private final long id = counter++;@Overridepublic String toString() {return "Sphere " + id;}
}public class CollectionComparison {public static void main(String[] args) {BerylliumSphere[] spheres =new BerylliumSphere[10];for (int i = 0; i < 5; i++) {spheres[i] = new BerylliumSphere();}show(spheres);System.out.println(spheres[4]);List<BerylliumSphere> sphereList = Suppliers.create(ArrayList::new, BerylliumSphere::new, 5);System.out.println(sphereList);System.out.println(sphereList.get(4));int[] integers = {0, 1, 2, 3, 4, 5};show(integers);System.out.println(integers[4]);List<Integer> intList = new ArrayList<>(Arrays.asList(0, 1, 2, 3, 4, 5));intList.add(97);System.out.println(intList);System.out.println(intList.get(4));}
}
Suppliers.java
import java.util.Collection;
import java.util.function.BiConsumer;
import java.util.function.Supplier;
import java.util.stream.Stream;public class Suppliers {// Create a collection and fill it:public static <T, C extends Collection<T>> Ccreate(Supplier<C> factory, Supplier<T> gen, int n) {return Stream.generate(gen).limit(n).collect(factory, C::add, C::addAll);}// Fill an existing collection:public static <T, C extends Collection<T>>C fill(C coll, Supplier<T> gen, int n) {Stream.generate(gen).limit(n).forEach(coll::add);return coll;}// Use an unbound method reference to// produce a more general method:public static <H, A> H fill(H holder,BiConsumer<H, A> adder, Supplier<A> gen, int n) {Stream.generate(gen).limit(n).forEach(a -> adder.accept(holder, a));return holder;}
}
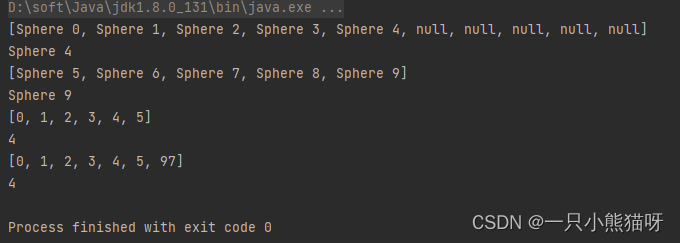
Suppliers.create() 方法在泛型一章中被定义。上面两种保存对象的方式都是有类型检查的,唯一比较明显的区别就是数组使用 [ ] 来随机存取元素,而一个 List 使用诸如 add() 和 get() 等方法。数组和 ArrayList 之间的相似是设计者有意为之,所以在概念上,两者很容易切换。但是就像你在集合中看到的,集合的功能明显多于数组。
随着 Java 自动装箱技术的出现,通过集合使用基本数据类型几乎和通过数组一样简单。数组唯一剩下的优势就是效率。然而,当你解决一个更加普遍的问题时,数组可能限制太多,这种情形下,您可以使用集合类。
用于显示数组的实用程序
在本章中,我们处处都要显示数组。Java 提供了 Arrays.toString() 来将数组转换为可读字符串,然后可以在控制台上显示。然而这种方式视觉上噪音太大,所以我们创建一个小的库来完成这项工作。
import java.util.*;public interface ArrayShow {static void show(Object[] a) {System.out.println(Arrays.toString(a));}static void show(boolean[] a) {System.out.println(Arrays.toString(a));}static void show(byte[] a) {System.out.println(Arrays.toString(a));}static void show(char[] a) {System.out.println(Arrays.toString(a));}static void show(short[] a) {System.out.println(Arrays.toString(a));}static void show(int[] a) {System.out.println(Arrays.toString(a));}static void show(long[] a) {System.out.println(Arrays.toString(a));}static void show(float[] a) {System.out.println(Arrays.toString(a));}static void show(double[] a) {System.out.println(Arrays.toString(a));}// Start with a description:static void show(String info, Object[] a) {System.out.print(info + ": ");show(a);}static void show(String info, boolean[] a) {System.out.print(info + ": ");show(a);}static void show(String info, byte[] a) {System.out.print(info + ": ");show(a);}static void show(String info, char[] a) {System.out.print(info + ": ");show(a);}static void show(String info, short[] a) {System.out.print(info + ": ");show(a);}static void show(String info, int[] a) {System.out.print(info + ": ");show(a);}static void show(String info, long[] a) {System.out.print(info + ": ");show(a);}static void show(String info, float[] a) {System.out.print(info + ": ");show(a);}static void show(String info, double[] a) {System.out.print(info + ": ");show(a);}
}
第一个方法适用于对象数组,包括那些包装基本数据类型的数组。所有的方法重载对于不同的数据类型是必要的。
第二组重载方法可以让你显示带有信息 字符串 前缀的数组。
为了简单起见,你通常可以静态地导入它们。
一等对象
不管你使用的什么类型的数组,数组中的数据集实际上都是对堆中真正对象的引用。数组是保存指向其他对象的引用的对象,数组可以隐式地创建,作为数组初始化语法的一部分,也可以显式地创建,比如使用一个 new 表达式。数组对象的一部分(事实上,你唯一可以使用的方法)就是只读的 length 成员函数,它能告诉你数组对象中可以存储多少元素。[ ] 语法是你访问数组对象的唯一方式。
下面的例子总结了初始化数组的多种方式,并且展示了如何给不同的数组对象分配数组引用。同时也可以看出对象数组和基元数组在使用上是完全相同的。唯一的不同之处就是对象数组存储的是对象的引用,而基元数组则直接存储基本数据类型的值。
import static com.example.test.ArrayShow.show;public class ArrayOptions {public static void main(String[] args) {// Arrays of objects:BerylliumSphere[] a; // Uninitialized localBerylliumSphere[] b = new BerylliumSphere[5];// The references inside the array are// automatically initialized to null:show("b", b);BerylliumSphere[] c = new BerylliumSphere[4];for (int i = 0; i < c.length; i++) {if (c[i] == null) // Can test for null reference{c[i] = new BerylliumSphere();}}// Aggregate initialization:BerylliumSphere[] d = {new BerylliumSphere(),new BerylliumSphere(),new BerylliumSphere()};// Dynamic aggregate initialization:a = new BerylliumSphere[]{new BerylliumSphere(), new BerylliumSphere(),};// (Trailing comma is optional)System.out.println("a.length = " + a.length);System.out.println("b.length = " + b.length);System.out.println("c.length = " + c.length);System.out.println("d.length = " + d.length);a = d;System.out.println("a.length = " + a.length);// Arrays of primitives:int[] e; // Null referenceint[] f = new int[5];// The primitives inside the array are// automatically initialized to zero:show("f", f);int[] g = new int[4];for (int i = 0; i < g.length; i++) {g[i] = i * i;}int[] h = {11, 47, 93};// Compile error: variable e not initialized://- System.out.println("e.length = " + e.length);System.out.println("f.length = " + f.length);System.out.println("g.length = " + g.length);System.out.println("h.length = " + h.length);e = h;System.out.println("e.length = " + e.length);e = new int[]{1, 2};System.out.println("e.length = " + e.length);}
}
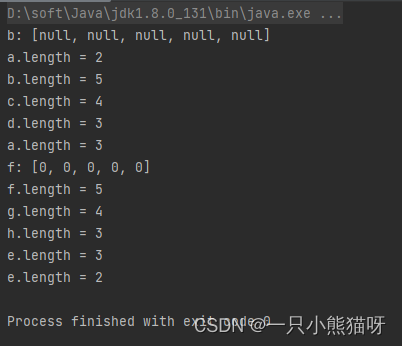
数组 a 是一个未初始化的本地变量,编译器不会允许你使用这个引用直到你正确地对其进行初始化。数组 b 被初始化成一系列指向 BerylliumSphere 对象的引用,但是并没有真正的 BerylliumSphere 对象被存储在数组中。尽管你仍然可以获得这个数组的大小,因为 b 指向合法对象。
这带来了一个小问题:你无法找出到底有多少元素存储在数组中,因为 length 只能告诉你数组可以存储多少元素;这就是说,数组对象的大小并不是真正存储在数组中对象的个数。然而,当你创建一个数组对象,其引用将自动初始化为 null,因此你可以通过检查特定数组元素中的引用是否为 null 来判断其中是否有对象。基元数组也有类似的机制,比如自动将数值类型初始化为 0,char 型初始化为 (char)0,布尔类型初始化为 false。
数组 c 展示了创建数组对象后给数组中各元素分配 BerylliumSphere 对象。数组 d 展示了创建数组对象的聚合初始化语法(隐式地使用 new 在堆中创建对象,就像 c 一样)并且初始化成 BeryliumSphere 对象,这一切都在一条语句中完成。
下一个数组初始化可以被看做是一个“动态聚合初始化”。 d 使用的聚合初始化必须在 d 定义处使用,但是使用第二种语法,你可以在任何地方创建和初始化数组对象。例如,假设 hide() 是一个需要使用一系列的 BeryliumSphere对象。你可以这样调用它:
hide(d);
你也可以动态地创建你用作参数传递的数组:
hide(new BerylliumSphere[]{new BerlliumSphere(),new BerlliumSphere()
});
很多情况下这种语法写代码更加方便。
表达式:
a = d;
显示了你如何获取指向一个数组对象的引用并将其分配给另一个数组对象。就像你可以处理其他类型的对象引用。现在 a 和 d 都指向了堆中的同一个数组对象。
ArrayOptions.java 的第二部分展示了基元数组的语法就像对象数组一样,除了基元数组直接保存基本数据类型的值。
返回数组
假设你写了一个方法,这个方法不是返回一个元素,而是返回多个元素。对 C++/C 这样的语言来说这是很困难的,因为你无法返回一个数组,只能是返回一个指向数组的指针。这会带来一些问题,因为对数组生存期的控制变得很混乱,这会导致内存泄露。
而在 Java 中,你只需返回数组,你永远不用为数组担心,只要你需要它,它就可用,垃圾收集器会在你用完后把它清理干净。
下面,我们返回一个 字符串 数组:
import java.util.*;import static com.example.test.ArrayShow.show;public class IceCreamFlavors {private static SplittableRandom rand =new SplittableRandom(47);static final String[] FLAVORS = {"Chocolate", "Strawberry", "Vanilla Fudge Swirl","Mint Chip", "Mocha Almond Fudge", "Rum Raisin","Praline Cream", "Mud Pie"};public static String[] flavorSet(int n) {if (n > FLAVORS.length) {throw new IllegalArgumentException("Set too big");}String[] results = new String[n];boolean[] picked = new boolean[FLAVORS.length];for (int i = 0; i < n; i++) {int t;do {t = rand.nextInt(FLAVORS.length);}while (picked[t]);results[i] = FLAVORS[t];picked[t] = true;}return results;}public static void main(String[] args) {for (int i = 0; i < 7; i++) {show(flavorSet(3));}}
}
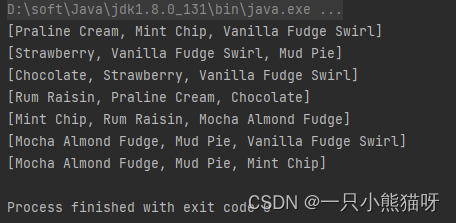
flavorset() 创建名为 results 的 String 类型的数组。 这个数组的大小 n 取决于你传进方法的参数。然后从数组 FLAVORS 中随机选择 flavors 并且把它们放进 results 里并返回。返回一个数组就像返回其他任何对象一样,实际上返回的是引用。数组是在 flavorSet() 中或者是在其他什么地方创建的并不重要。垃圾收集器会清理你用完的数组,你需要的数组则会保留。
如果你必须要返回一系列不同类型的元素,你可以使用 泛型 中介绍的 元组 。
注意,当 flavorSet() 随机选择 flavors,它应该确保某个特定的选项没被选中。这在一个 do 循环中执行,它将一直做出随机选择直到它发现一个元素不在 picked 数组中。(一个字符串
比较将显示出随机选中的元素是不是已经存在于 results 数组中)。如果成功了,它将添加条目并且寻找下一个( i 递增)。输出结果显示 flavorSet() 每一次都是按照随机顺序选择 flavors。
一直到现在,随机数都是通过 java.util.Random 类生成的,这个类从 Java 1.0 就有,甚至更新过以提供 Java 8 流。现在我们可以介绍 Java 8 中的 SplittableRandom ,它不仅能在并行操作使用(你最终会学到),而且提供了一个高质量的随机数。这本书的剩余部分都使用 SplittableRandom 。


![[acwing周赛复盘] 第 94 场周赛20230311](https://img-blog.csdnimg.cn/34aeb9753bad437bb4d2cbd58db5d2d8.png)

![[Docker]六.Docker自动部署nodejs以及golang项目](https://img-blog.csdnimg.cn/f3eb5b64e4c44d0c81a8554de39567eb.png)