文章目录
- 一、通俗理解:从“取外卖”看中断
- 二、软中断
- 2.1 网卡收发数据包
- 2.2 查看软中断和内核线程
- 2.3 案例
- 2.3.1 案例:动态库 sleep 导致软中断
- 2.3.2 Nginx
进程的不可中断状态是系统的一种保护机制,可以保证硬件的交互过程不被意外打断。所以,短时间的不可中断状态是很正常的。
但是,当进程长时间都处于不可中断状态时,你就得当心了。这时,你可以使用 dstat、pidstat 等工具,确认是不是磁盘 I/O 的问题,进而排查相关的进程和磁盘设备。关于磁盘 I/O 的性能问题,你暂且不用专门去背,我会在后续的 I/O 部分详细介绍,到时候理解了也就记住了。
其实除了 iowait,软中断(softirq)CPU 使用率升高也是最常见的一种性能问题。接下我们就来学习软中断的内容,我还会以最常见的反向代理服务器 Nginx 的案例,带你分析这种情况。
一、通俗理解:从“取外卖”看中断
说到中断,我在前面关于“上下文切换”的文章,简单说过中断的含义,先来回顾一下。中断是系统用来响应硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求。
你可能要问了,为什么要有中断呢?我可以举个生活中的例子,让你感受一下中断的魅力。
比如说你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。
不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。
这里的“打电话”,其实就是一个中断。没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
这个例子你就可以发现,中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断本身要做的事情不多,那么处理起来也不会有太大问题;但如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
特别是,中断处理程序在响应中断时,还会临时关闭中断。这就会导致上一次中断处理完成之前,其他中断都不能响应,也就是说中断有可能会丢失。
那么还是以取外卖为例。假如你订了 2 份外卖,一份主食和一份饮料,并且是由 2 个不同的配送员来配送。这次你不用时时等待着,两份外卖都约定了电话取外卖的方式。但是,问题又来了。
当第一份外卖送到时,配送员给你打了个长长的电话,商量发票的处理方式。与此同时,第二个配送员也到了,也想给你打电话。
但是很明显,因为电话占线(也就是关闭了中断响应),第二个配送员的电话是打不通的。所以,第二个配送员很可能试几次后就走掉了(也就是丢失了一次中断)。
二、软中断
如果你弄清楚了“取外卖”的模式,那对系统的中断机制就很容易理解了。事实上,为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
比如说前面取外卖的例子,上半部就是你接听电话,告诉配送员你已经知道了,其他事儿见面再说,然后电话就可以挂断了;下半部才是取外卖的动作,以及见面后商量发票处理的动作。
这样,第一个配送员不会占用你太多时间,当第二个配送员过来时,照样能正常打通你的电话。
2.1 网卡收发数据包
除了取外卖,我再举个最常见的网卡接收数据包的例子,让你更好地理解。
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。你可以自己先想一下,这种情况下的上半部和下半部分别负责什么工作呢?
对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
所以,这两个阶段你也可以这样理解:
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行;
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
实际上,上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
不过要注意的是,软中断不只包括了刚刚所讲的硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁(Read-Copy Update 的缩写,RCU 是 Linux 内核中最常用的锁之一)等。
那要怎么知道你的系统里有哪些软中断呢?
2.2 查看软中断和内核线程
不知道你还记不记得,前面提到过的 proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
运行下面的命令,查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数:
$ cat /proc/softirqsCPU0 CPU1HI: 0 0TIMER: 811613 1972736NET_TX: 49 7NET_RX: 1136736 1506885BLOCK: 0 0IRQ_POLL: 0 0TASKLET: 304787 3691SCHED: 689718 1897539HRTIMER: 0 0RCU: 1330771 1354737
在查看 /proc/softirqs 文件内容时,你要特别注意以下这两点。
- 第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
- 第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。
不过你可能发现,TASKLET 在不同 CPU 上的分布并不均匀。TASKLET 是最常用的软中断实现机制,每个 TASKLET 只运行一次就会结束 ,并且只在调用它的函数所在的 CPU 上运行。
因此,使用 TASKLET 特别简便,当然也会存在一些问题,比如说由于只在一个 CPU 上运行导致的调度不均衡,再比如因为不能在多个 CPU 上并行运行带来了性能限制。
另外,刚刚提到过,软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
其实用 ps 命令就可以做到,比如执行下面的指令:
$ ps aux | grep softirq
root 7 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/0]
root 16 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/1]
注意,这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数(cmline)。一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。

2.3 案例
2.3.1 案例:动态库 sleep 导致软中断
之前的c程序用到了别人写的动态库[如:lib.a],在物理机上,进程的cpu利用率在0%;而切换到了云服务器,即使空载,单进程的cpu利用率都有30%+。
以前没经验嘛,各种自查,无结果,但是自己的进程cpu利用率又那么高,总是不安心.
后来才通过vmstat 检测到系统的软中断每秒有100W+次.
最后各自百度,找人,才发现是那个动态库在处理网络收发消息时,使用了usleep(1)来休息,每次休息1纳秒,单次中断的耗时都不止1纳秒.
如果是现在,我会如下分析:
1.检测是哪个线程占用了cpu: top -H -p XX 1 / pidstat -wut -p XX 1
2.在进程中打印各线程号. 找到是哪个线程.[ 此过程也可以省略 但可以快速定位线程]
3.第一步应该可以判断出来中断数过高. 再使用 cat /proc/softirqs 查看是哪种类型的中断数过高.
4.不知道perf report -g -p XX 是否可以定位到具体的系统调用函数.
5.最终还是要查看源码,定位具体的位置,并加以验证.
大量的网络小包会导致性能问题,是因为会导致频繁的硬中断和软中断
2.3.2 Nginx
基于 Ubuntu 18.04,也同样适用于其他的 Linux 系统。我使用的案例环境是这样的:
- 机器配置:2 CPU、8 GB 内存。
- 预先安装 docker、sysstat、sar 、hping3、tcpdump 等工具,比如 apt-get install docker.io sysstat hping3 tcpdump。
这里我又用到了三个新工具,sar、 hping3 和 tcpdump,先简单介绍一下:
- sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
- hping3 是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
- tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
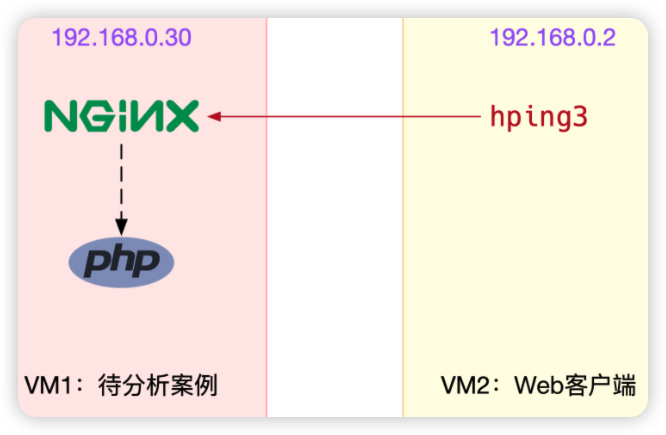
本次案例用到两台虚拟机,我画了一张图来表示它们的关系。
安装完成后,我们先在第一个终端,执行下面的命令运行案例,也就是一个最基本的 Nginx 应用:
# 运行 Nginx 服务并对外开放 80 端口
$ docker run -itd --name=nginx -p 80:80 nginx然后,在第二个终端,使用 curl 访问 Nginx 监听的端口,确认 Nginx 正常启动。假设 192.168.0.30 是 Nginx 所在虚拟机的 IP 地址,运行 curl 命令后你应该会看到下面这个输出界面:
$ curl http://192.168.0.30/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...接着,还是在第二个终端,我们运行 hping3 命令,来模拟 Nginx 的客户端请求:
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1
$ hping3 -S -p 80 -i u100 192.168.0.30
现在我们再回到第一个终端,你应该发现了异常。是不是感觉系统响应明显变慢了,即便只是在终端中敲几个回车,都得很久才能得到响应?这个时候应该怎么办呢?
虽然在运行 hping3 命令时,我就已经告诉你,这是一个 SYN FLOOD 攻击,你肯定也会想到从网络方面入手,来分析这个问题。不过,在实际的生产环境中,没人直接告诉你原因。
所以,我希望你把 hping3 模拟 SYN FLOOD 这个操作暂时忘掉,然后重新从观察到的问题开始,分析系统的资源使用情况,逐步找出问题的根源。
那么,该从什么地方入手呢?刚才我们发现,简单的 SHELL 命令都明显变慢了,先看看系统的整体资源使用情况应该是个不错的注意,比如执行下 top 看看是不是出现了 CPU 的瓶颈。我们在第一个终端运行 top 命令,看一下系统整体的资源使用情况。
# top 运行后按数字 1 切换到显示所有 CPU
$ top
top - 10:50:58 up 1 days, 22:10, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 122 total, 1 running, 71 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni, 96.7 id, 0.0 wa, 0.0 hi, 3.3 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni, 95.6 id, 0.0 wa, 0.0 hi, 4.4 si, 0.0 st
...PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND7 root 20 0 0 0 0 S 0.3 0.0 0:01.64 ksoftirqd/016 root 20 0 0 0 0 S 0.3 0.0 0:01.97 ksoftirqd/12663 root 20 0 923480 28292 13996 S 0.3 0.3 4:58.66 docker-containe3699 root 20 0 0 0 0 I 0.3 0.0 0:00.13 kworker/u4:03708 root 20 0 44572 4176 3512 R 0.3 0.1 0:00.07 top1 root 20 0 225384 9136 6724 S 0.0 0.1 0:23.25 systemd2 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kthreadd
...
这里你有没有发现异常的现象?我们从第一行开始,逐个看一下:
- 平均负载全是 0,就绪队列里面只有一个进程(1 running)。
- 每个 CPU 的使用率都挺低,最高的 CPU1 的使用率也只有 4.4%,并不算高。
- 再看进程列表,CPU 使用率最高的进程也只有 0.3%,还是不高呀。
那为什么系统的响应变慢了呢?既然每个指标的数值都不大,那我们就再来看看,这些指标对应的更具体的含义。毕竟,哪怕是同一个指标,用在系统的不同部位和场景上,都有可能对应着不同的性能问题。
仔细看 top 的输出,两个 CPU 的使用率虽然分别只有 3.3% 和 4.4%,但都用在了软中断上;而从进程列表上也可以看到,CPU 使用率最高的也是软中断进程 ksoftirqd。看起来,软中断有点可疑了。
根据上一期的内容,既然软中断可能有问题,那你先要知道,究竟是哪类软中断的问题。停下来想想,上一节我们用了什么方法,来判断软中断类型呢?没错,还是 proc 文件系统。观察 /proc/softirqs 文件的内容,你就能知道各种软中断类型的次数。
不过,这里的各类软中断次数,又是什么时间段里的次数呢?它是系统运行以来的累积中断次数。所以我们直接查看文件内容,得到的只是累积中断次数,对这里的问题并没有直接参考意义。因为,这些中断次数的变化速率才是我们需要关注的。
那什么工具可以观察命令输出的变化情况呢?我想你应该想起来了,在前面案例中用过的 watch 命令,就可以定期运行一个命令来查看输出;如果再加上 -d 参数,还可以高亮出变化的部分,从高亮部分我们就可以直观看出,哪些内容变化得更快。
比如,还是在第一个终端,我们运行下面的命令:
$ watch -d cat /proc/softirqsCPU0 CPU1HI: 0 0TIMER: 1083906 2368646NET_TX: 53 9NET_RX: 1550643 1916776BLOCK: 0 0IRQ_POLL: 0 0TASKLET: 333637 3930SCHED: 963675 2293171HRTIMER: 0 0RCU: 1542111 1590625
通过 /proc/softirqs 文件内容的变化情况,你可以发现, TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化。
其中,NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化倒是正常的。
那么接下来,我们就从网络接收的软中断着手,继续分析。既然是网络接收的软中断,第一步应该就是观察系统的网络接收情况。这里你可能想起了很多网络工具,不过,我推荐今天的主人公工具 sar 。
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
我们在第一个终端中运行 sar 命令,并添加 -n DEV 参数显示网络收发的报告:
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
$ sar -n DEV 1
15:03:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
15:03:47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
15:03:47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
15:03:47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
15:03:47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
对于 sar 的输出界面,我先来简单介绍一下,从左往右依次是:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
- 后面的其他参数基本接近 0,显然跟今天的问题没有直接关系,你可以先忽略掉。
我们具体来看输出的内容,你可以发现:
- 对网卡 eth0 来说,每秒接收的网络帧数比较大,达到了 12607,而发送的网络帧数则比较小,只有 6304;每秒接收的千字节数只有 664 KB,而发送的千字节数更小,只有 358 KB。
- docker0 和 veth9f6bbcd 的数据跟 eth0 基本一致,只是发送和接收相反,发送的数据较大而接收的数据较小。这是 Linux 内部网桥转发导致的,你暂且不用深究,只要知道这是系统把 eth0 收到的包转发给 Nginx 服务即可。具体工作原理,我会在后面的网络部分详细介绍。
从这些数据,你有没有发现什么异常的地方?
既然怀疑是网络接收中断的问题,我们还是重点来看 eth0 :接收的 PPS 比较大,达到 12607,而接收的 BPS 却很小,只有 664 KB。直观来看网络帧应该都是比较小的,我们稍微计算一下,664*1024/12607 = 54 字节,说明平均每个网络帧只有 54 字节,这显然是很小的网络帧,也就是我们通常所说的小包问题。
那么,有没有办法知道这是一个什么样的网络帧,以及从哪里发过来的呢?
使用 tcpdump 抓取 eth0 上的包就可以了。我们事先已经知道, Nginx 监听在 80 端口,它所提供的 HTTP 服务是基于 TCP 协议的,所以我们可以指定 TCP 协议和 80 端口精确抓包。
接下来,我们在第一个终端中运行 tcpdump 命令,通过 -i eth0 选项指定网卡 eth0,并通过 tcp port 80 选项指定 TCP 协议的 80 端口:
# -i eth0 只抓取 eth0 网卡,-n 不解析协议名和主机名
# tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
$ tcpdump -i eth0 -n tcp port 80
15:11:32.678966 IP 192.168.0.2.18238 > 192.168.0.30.80: Flags [S], seq 458303614, win 512, length 0
...
从 tcpdump 的输出中,你可以发现
- 192.168.0.2.18238 > 192.168.0.30.80 ,表示网络帧从 192.168.0.2 的 18238 端口发送到 192.168.0.30 的 80 端口,也就是从运行 hping3 机器的 18238 端口发送网络帧,目的为 Nginx 所在机器的 80 端口。
- Flags [S] 则表示这是一个 SYN 包。
再加上前面用 sar 发现的, PPS 超过 12000 的现象,现在我们可以确认,这就是从 192.168.0.2 这个地址发送过来的 SYN FLOOD 攻击。
到这里,我们已经做了全套的性能诊断和分析。从系统的软中断使用率高这个现象出发,通过观察 /proc/softirqs 文件的变化情况,判断出软中断类型是网络接收中断;再通过 sar 和 tcpdump ,确认这是一个 SYN FLOOD 问题。
SYN FLOOD 问题最简单的解决方法,就是从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中。
至于 SYN FLOOD 的原理和更多解决思路,你暂时不需要过多关注,后面的网络章节里我们都会学到。