文章目录
- 一、单进程版---最简单的程序替换
- 二、进程替换的原理
- 三、多进程的程序替换
- 1.多进程的程序替换实例
- 2.那么程序在替换时候有没有创建子进程呢
- 3.再谈原理
- 4.一个现象
- 5.我们的CPU如何得知程序的入口地址?
- 四、各个接口的介绍
- 1.execl
- 2.execlp
- 3.execv
- 4.execvp
- 5.execle
一、单进程版—最简单的程序替换
在linux中存在这样的一批接口,exec系列的接口,我们可以用man手册去查看
man 3 exec
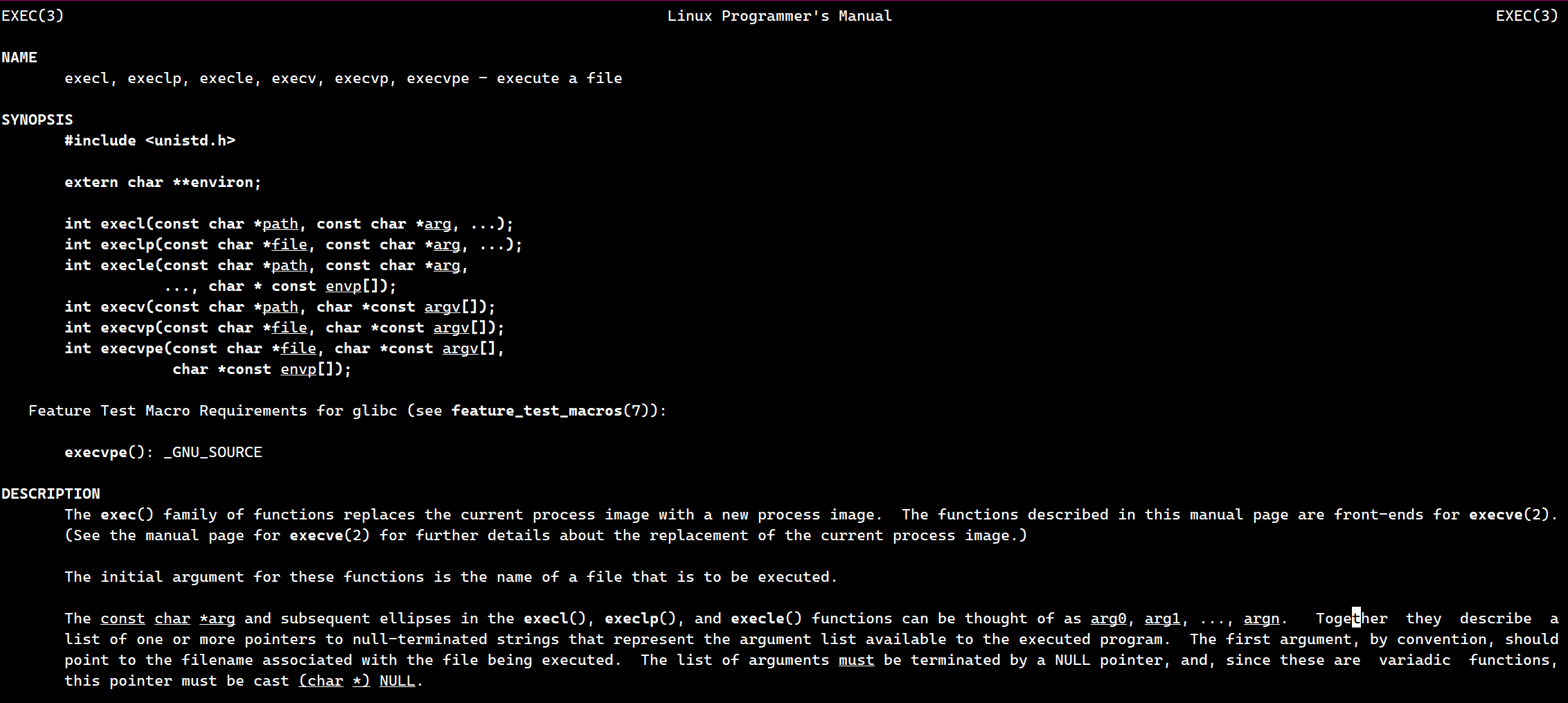
我们先来看一下execl函数,它的第一个参数是路径,即某个程序的路径,第二个是该程序,后面的可变参数列表是该程序的选项,我们可以自己随意填写。但是最后一个一般是为NULL的,这是标准写法,但是有些编译器,即便不写NULL也是可以的
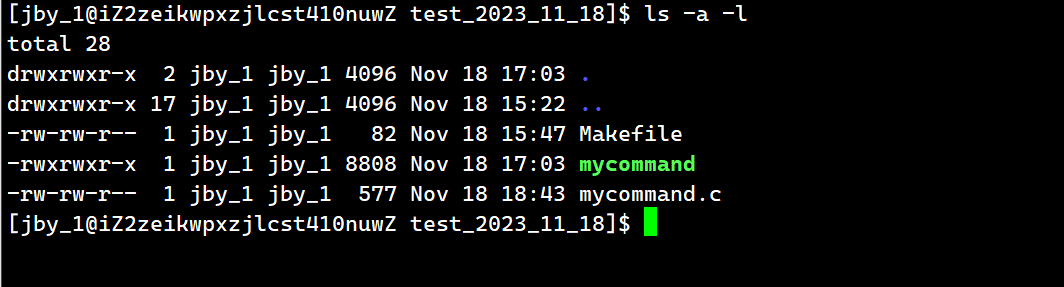
我们可以先简单的跑一下这个代码
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{ printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());execl("/usr/bin/ls","ls","-a","-l",NULL);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid()); return 0;
}
运行结果为
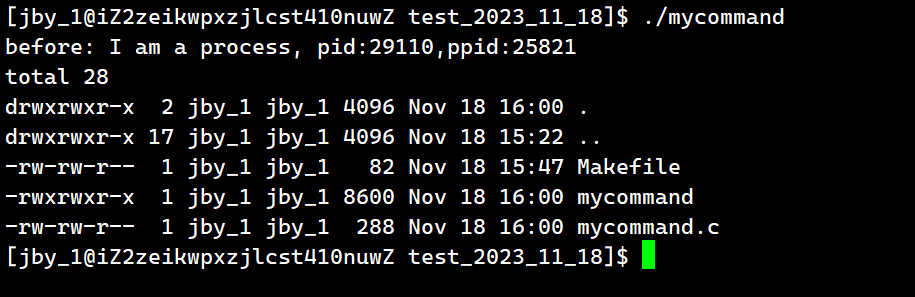
我们可以看到,这个进程将ls这个命令给跑起来了,而且最后after是没有被执行的。
甚至我们也可以这样做
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{ printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid()); execl("/usr/bin/top","top",NULL); printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid()); return 0;
}
这样的话,最终会执行这个top命令的
所以我们现在知道了使用这个execl后会发生什么事情了
将别人的程序给替换一下,然后去跑别人的程序。在替换之后,后面的程序都不会去跑了。
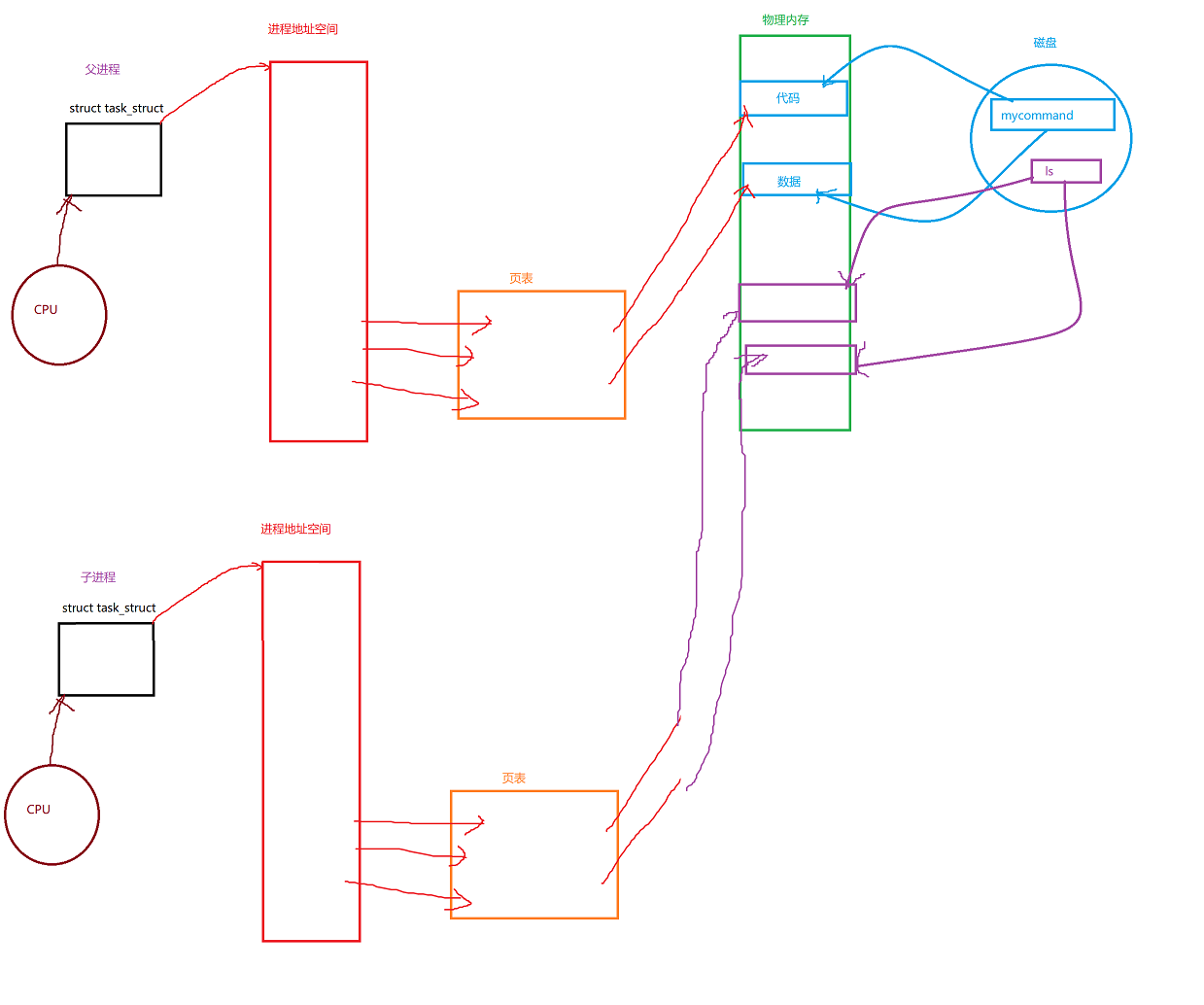
二、进程替换的原理
如下图所示
在程序一开始的时候,CPU调度这个进程,然后这个进程会将磁盘中的代码和数据加载到物理内存中,开始执行代码
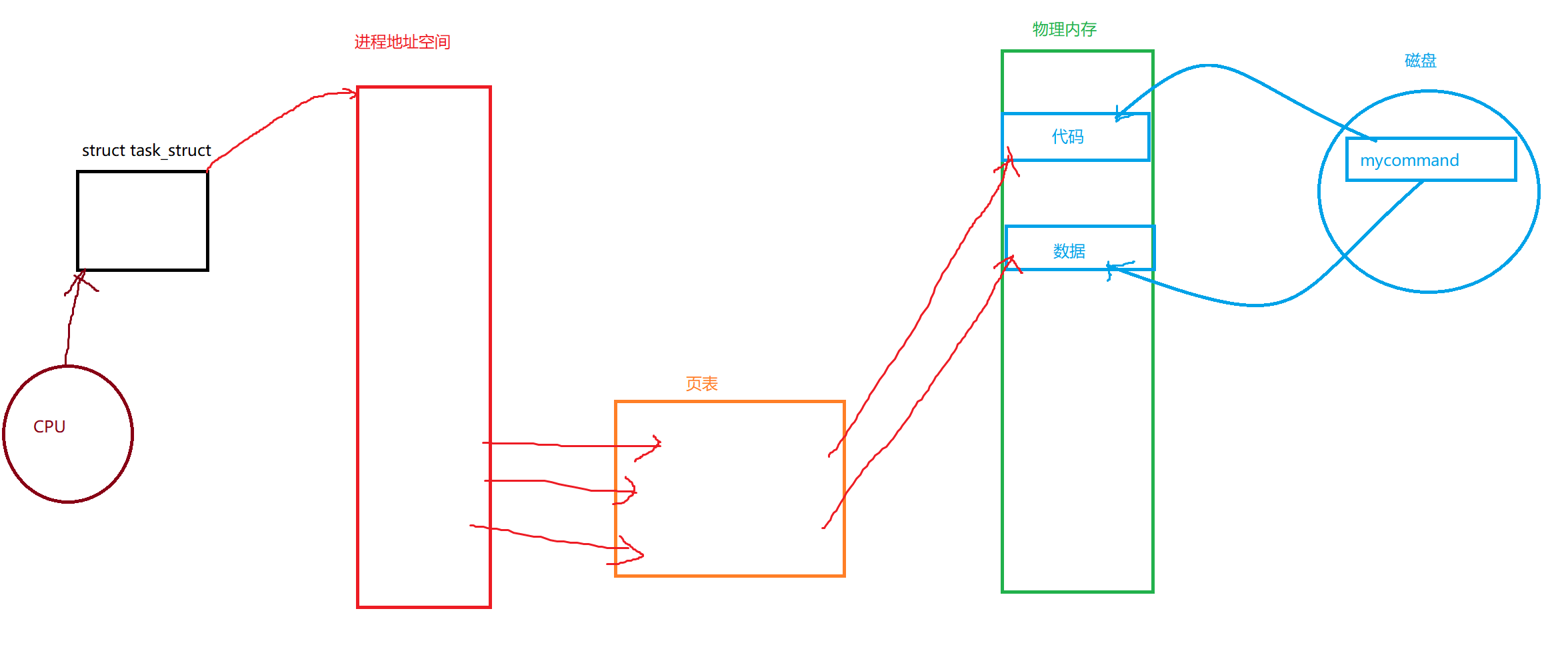
当我们前面的程序在执行execl时候
它里面由于用的是ls,所以ls直接将原来的代码和数据给替换下来
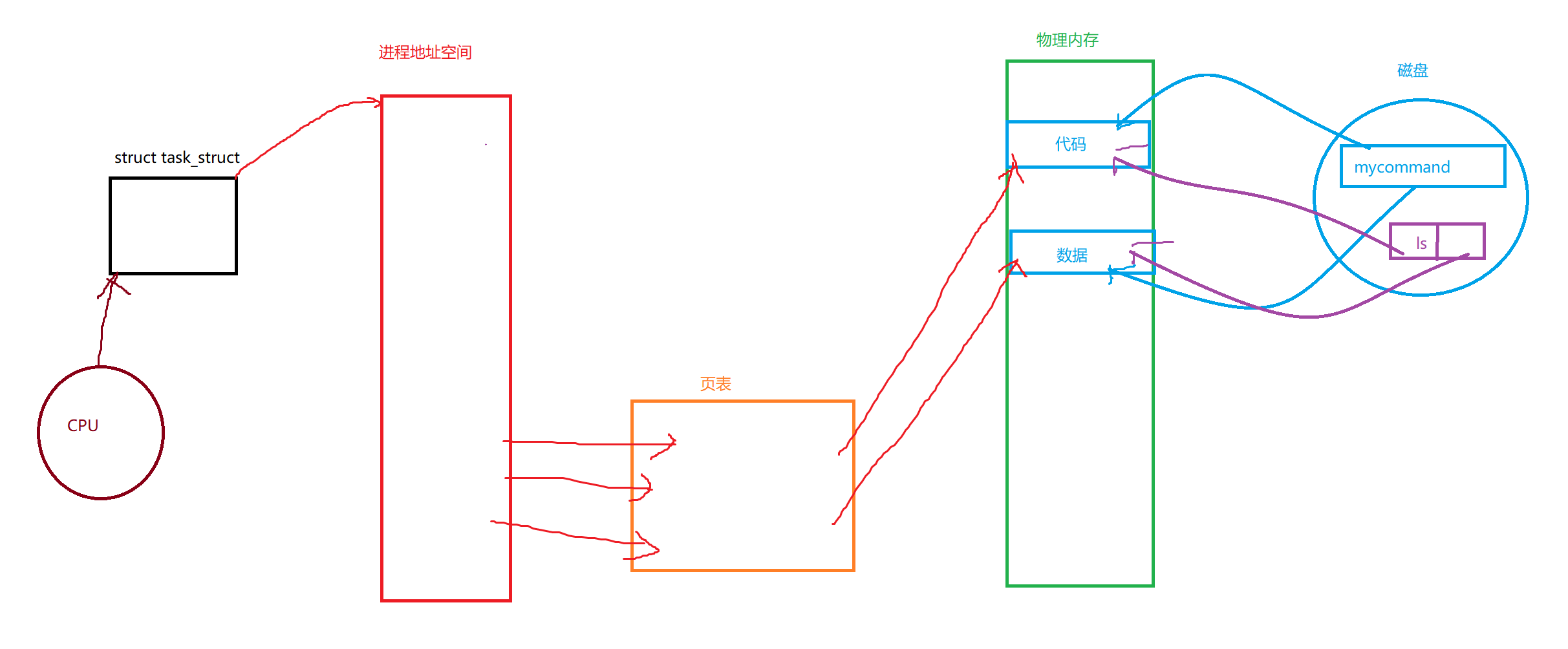
也就是说,对于页表以左部分是不会变化的,只会将右侧部分的代码和数据给替换,然后将页表给稍微调整一下即可。
总之就是用自己原来的代码和数据替换为新的代码和数据,然后从新的代码和数据从0开始执行,重新开始执行。
这就是程序替换
三、多进程的程序替换
1.多进程的程序替换实例
我们用如下代码
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
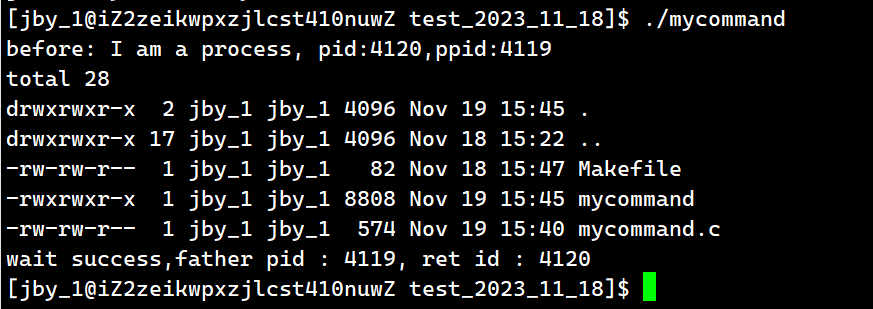
{pid_t id = fork();if(id == 0){printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());sleep(5);execl("/usr/bin/ls","ls","-a","-l",NULL);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());exit(0);}pid_t ret = waitpid(id,NULL,0);if(ret > 0) {printf("wait success,father pid : %d, ret id : %d\n",getpid(),ret);}sleep(5);return 0;
}
搭配上监控,我们来测试观察一下现象
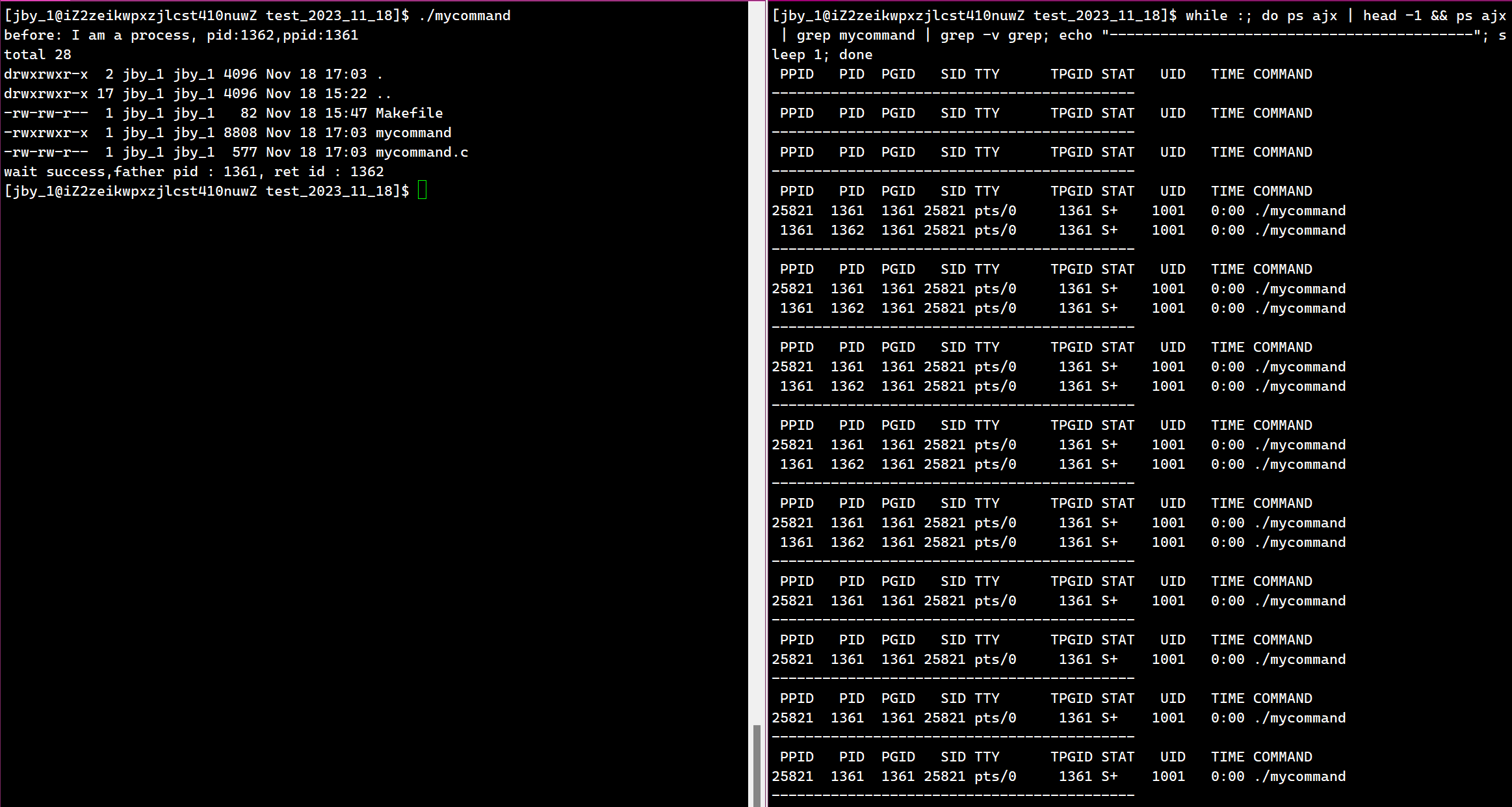
一开始,父子进程同时运行,但是父进程直接进入进程等待,等待子进程结束。对于子进程则是执行了一行代码后,进程替换。然后随之结束。
子进程执行进程替换的时候,需要替换代码和数据,但是并不会影响父进程,因为有写时拷贝,以及进程之间是要保持独立性的
注意:对于数据有写时拷贝我们可以理解,对于代码而言,也是存在写时拷贝的。所以代码也并不是那么的绝对不可写入的,主要看谁去修改。这里是由操作系统去修改的,当然是可以的。
2.那么程序在替换时候有没有创建子进程呢
其实是没有的,还是在原来的进程上,从我们前面的运行结果可以看出来,进程等待完毕后,还是原来的子进程
所以这里只进行程序代码和数据的替换工作
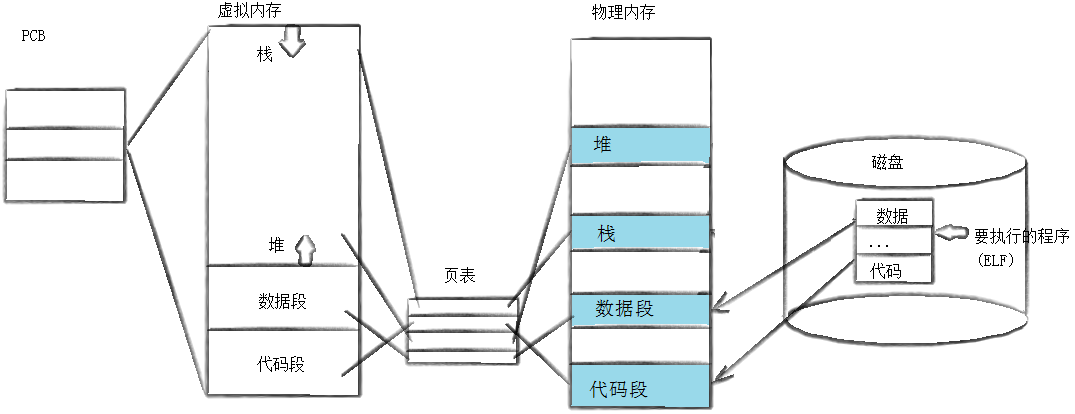
3.再谈原理
用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数,以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变
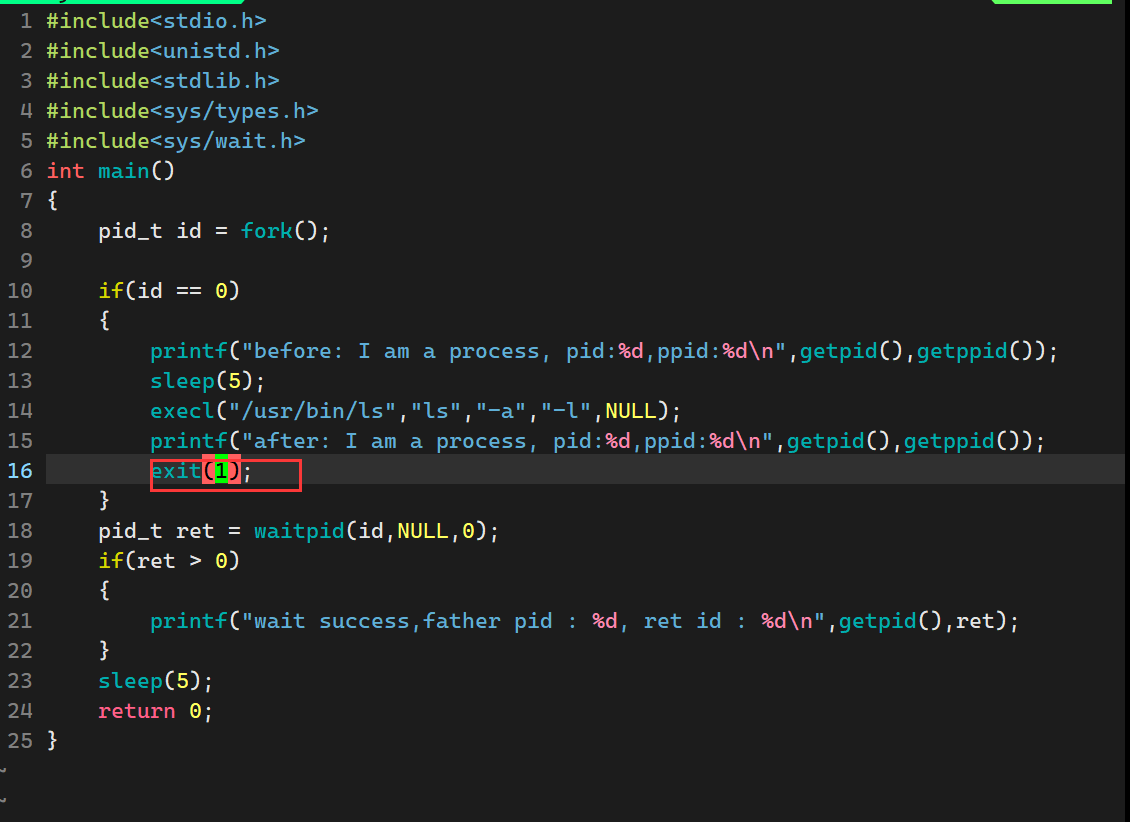
4.一个现象
我们可以注意到,exec系列函数之后的代码似乎没有被执行
所以说程序替换成功之后,exec*后续的代码不会被执行,如果替换失败,才可能执行后续代码,exec*函数,它只有在失败的时候,才会有返回值,如果成功是不会返回任何值的,因为也没办法返回。
所以其实我们上面的代码可以稍作修改
在这里我们可以让他退出的时候退出码为1,因为为0也没有什么意义,程序替换失败才会执行到这里。
5.我们的CPU如何得知程序的入口地址?
Linux中形成的可执行程序,是有格式的,ELF,这个可执行的程序有它自己的表头。可执行程序入口地址就在表头。
所以说,在程序加载到内存的时候,一定会先将表头入口地址加载到内存中的,然后后面的在慢慢加载
当我们程序替换以后,它也有自己的表头,CPU可以直接读取到表头的入口地址,从而进行执行。
四、各个接口的介绍
我们可以用man手册查找到,其实,对于exec系列有很多个接口,一共有七个,但是man手册中的三号手册有6个
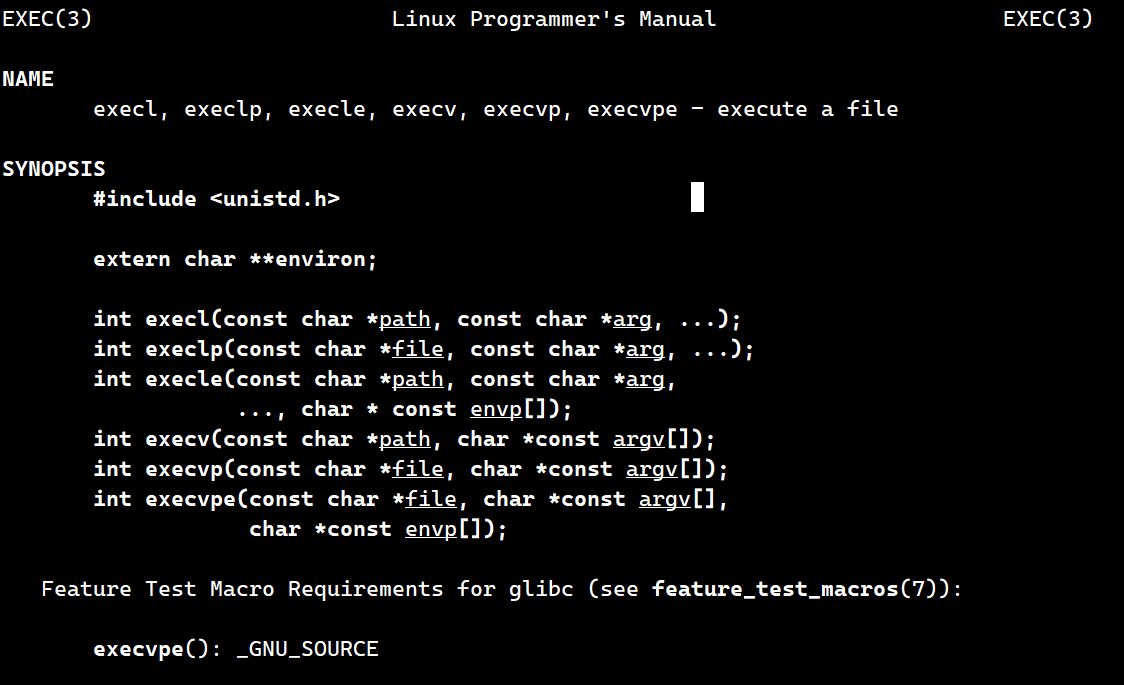
还有一个是在2号手册中的。
在exec系列的函数中,开头都是exec开头的
1.execl
int execl(const char *path, const char *arg, ...);
这个l我们可以理解为list,即列表。
如下所示,像我们刚刚所用到的这个函数
execl("/usr/bin/ls","ls","-a","-l",NULL);
list就相当于,在传参的时候,从第二个开始,一个一个的往里传参的,像链表一样,最后一个结点为空
像我们之前在命令行跑这个程序的时候,是这样的
而现在,我们只需要将中间的空格改为逗号,最后加一个NULL,输入指令的时候是怎样的,最后就如何去传参。
对于第一个参数,我们要知道,执行一个程序的第一件事情一定是先找到这个程序。所以第一个参数就是用来找到这个程序的。
找到这个程序之后,接下来要怎么办???
找到这个程序以后,要做的就是如何执行这个程序,要不要涵盖选项,涵盖哪些?
所以最终就是命令行怎么写,我们就怎么传
2.execlp
如下所示,是第二个该系列的接口
int execlp(const char *file, const char *arg, ...);
这个我们会发现,多了一个p
这个p其实就是PATH的意思,execlp会在默认的PATH环境变量中查找。
对于第一个参数,这里我们可以带上它的路径,也可以不带上路径,后面的参数都是和前面的函数一样的
如下是带上路径的
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
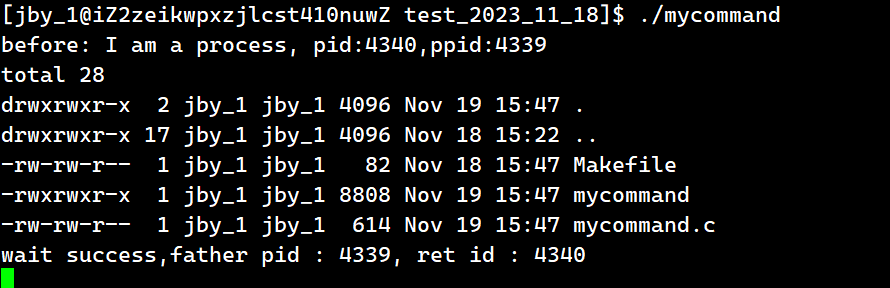
{pid_t id = fork();if(id == 0){printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());sleep(5);execlp("/usr/bin/ls","ls","-al",NULL);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());exit(1);}pid_t ret = waitpid(id,NULL,0);if(ret > 0) {printf("wait success,father pid : %d, ret id : %d\n",getpid(),ret);}sleep(5);return 0;
}
运行结果为
如果我们不带上路径
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{pid_t id = fork();if(id == 0){printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());sleep(5);// execlp("/usr/bin/ls","ls","-al",NULL);execlp("ls","ls","-al",NULL);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());exit(1);}pid_t ret = waitpid(id,NULL,0);if(ret > 0) {printf("wait success,father pid : %d, ret id : %d\n",getpid(),ret);}sleep(5);return 0;
}
运行结果为
在这里所有的子进程都会继承父进程的环境变量。环境变量具有全局属性,所以最终可以解决路劲的问题。
不过在这里,我们可能会觉得这个函数的用法比较奇怪
execlp("ls","ls","-al",NULL);
我们会注意到写了两个ls,很奇怪,其实这是合理的,第一个ls解决的是路径的问题,即去找到这条指令,后面是执行该指令的问题。
而要找到该指令,环境变量帮我们解决了一部分,剩下的就是在该路径下找到该指令到底有没有,要找到该指令的程序名
3.execv
其中这个v代表的就是vector。
int execv(const char *path, char *const argv[]);
这里没有带p,所以它就是需要路径去寻找。
像前面的两个都是以可变参数列表的形式传入的,现在这个使用的是字符串指针数组。
这个和前面不同之处就在于,将前面的改为了指针数组的形式。因为我们的指令最终也是要被解析为一个一个的字符串。所以这个操作直接就是将这些字符串整合为了一共字符串指针数组而已,没有什么太大的变化
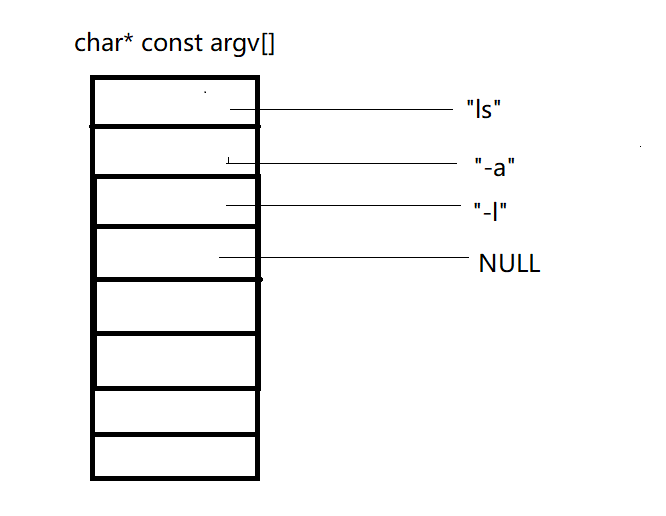
如下代码所示
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
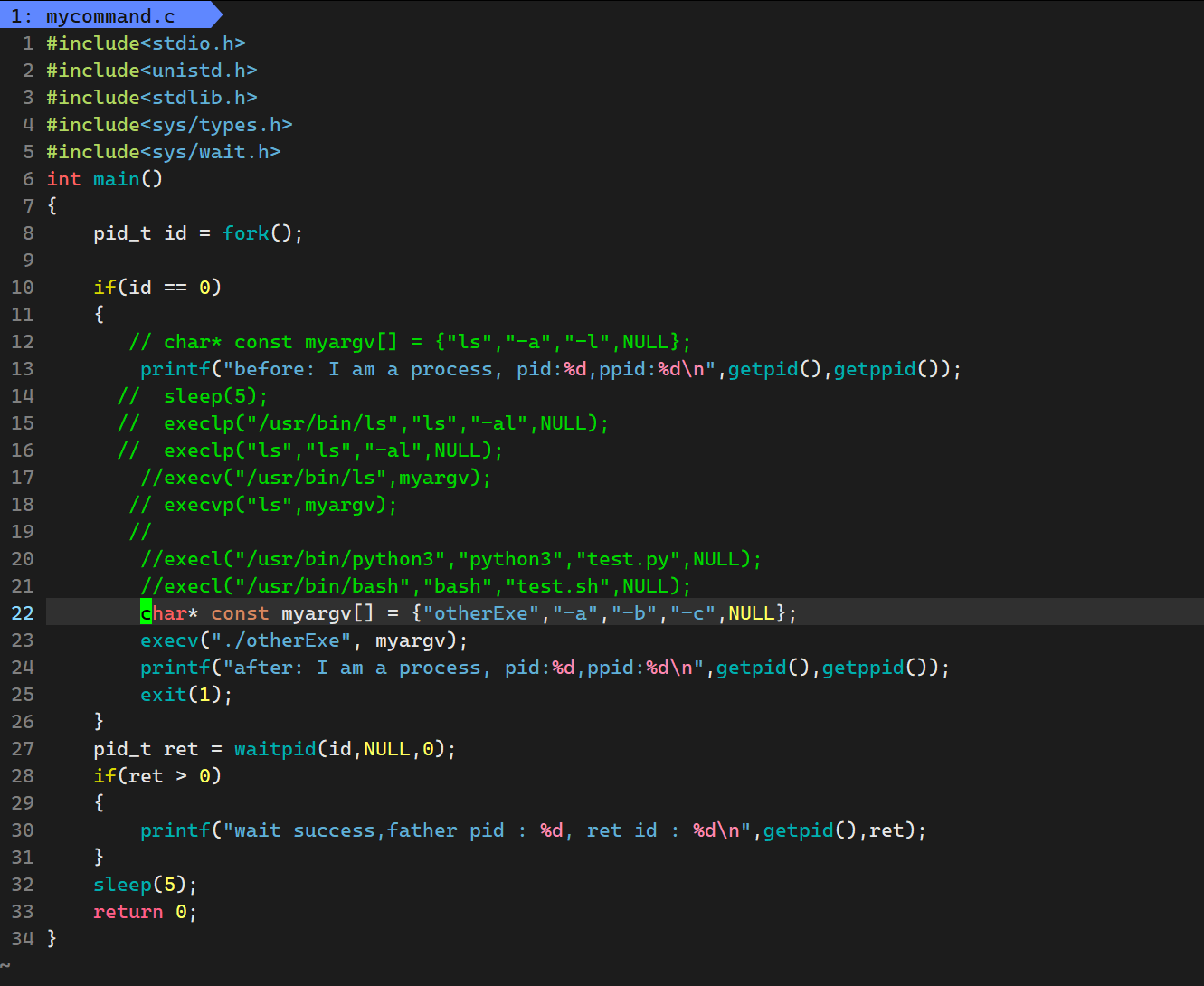
int main()
{pid_t id = fork();if(id == 0){char* const myargv[] = {"ls","-a","-l",NULL};printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());sleep(5);// execlp("/usr/bin/ls","ls","-al",NULL);// execlp("ls","ls","-al",NULL);execv("/usr/bin/ls",myargv);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());exit(1);}pid_t ret = waitpid(id,NULL,0);if(ret > 0) {printf("wait success,father pid : %d, ret id : %d\n",getpid(),ret);}sleep(5);return 0;
}运行结果为
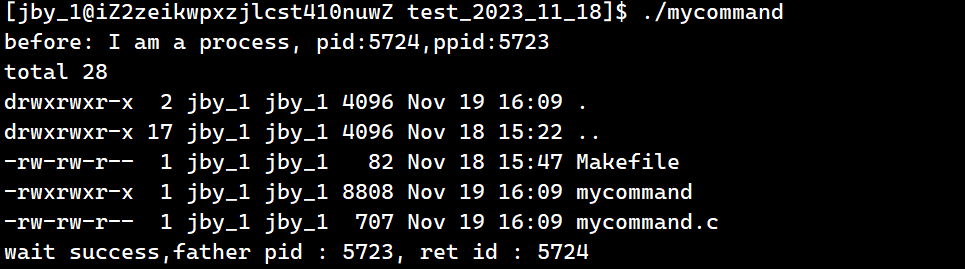
我们知道ls是一个被编译好的程序,ls有它自己的main函数,ls也有它自己的命令行参数,而它的命令行参数就是在这个系统调用中传入的。以及前面的execl也是一样的,它这种链表的形式,也要最终变为一共指针数组,然后进行命令行传参
在linux,所有的进程都是被人的子进程,在命令行中,所有的进程都是bash的子进程
所以,所有的进程在启动的时候都是采用exec系列的函数启动执行的!
所以进程替换,在单进程中,是把在内存中开辟空间以后,然后把程序和代码加载到内存当中
所以exec系列函数承担的是一个加载器的效果!把可执行程序导入到内存中。而且由于它还能接收命令行参数,所以调用可执行程序的时候,就可以将这个argv传入给可程序程序
4.execvp
所以有了前面三个函数的基础,我们也就可以理解下面这个函数了
int execvp(const char *file, char *const argv[]);
无非就是可以不用传入路径了,它可以直接在环境变量中找到对应的路径,然后我们只需要去找到这个可执行程序即可。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
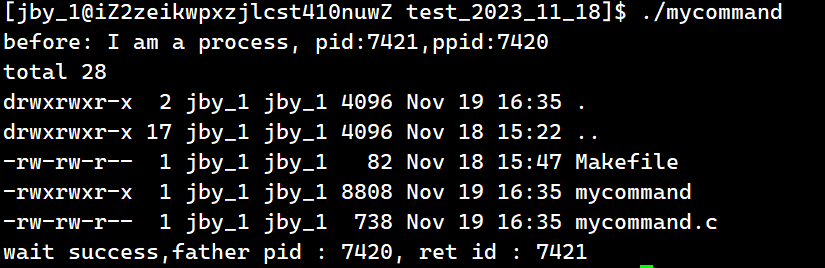
{pid_t id = fork();if(id == 0){char* const myargv[] = {"ls","-a","-l",NULL};printf("before: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());sleep(5);// execlp("/usr/bin/ls","ls","-al",NULL);// execlp("ls","ls","-al",NULL);//execv("/usr/bin/ls",myargv);execvp("ls",myargv);printf("after: I am a process, pid:%d,ppid:%d\n",getpid(),getppid());exit(1);}pid_t ret = waitpid(id,NULL,0);if(ret > 0) {printf("wait success,father pid : %d, ret id : %d\n",getpid(),ret);}sleep(5);return 0;
}
运行结果如下
5.execle
对于这个e,它代表的是env,即环境变量,换言之,它可以传入我们自己的环境变量
int execle(const char *path, const char *arg, ..., char * const envp[]);
对于这个函数而言,前面的三个参数和execl是完全一样的,
如果exec*可以执行系统命令,能不能执行我们自己的命令呢?
当然是可以的
这里我们先试着使用makefile工具一次生成多个可执行程序
我们先来创建一个c++代码(注意,对于c++代码,我们可以有三种后缀,cc、cpp、cxx这三种后缀都是一样的可以的)
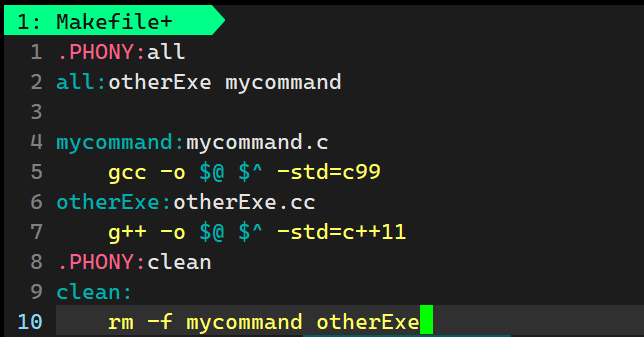
然后我们将我们的Makefile文件改为这样
.PHONY代表总是执行all这个依赖关系,然而all的依赖关系为这两个可执行程序,所以就会先去执行他们两个的依赖关系。all它本身就是一个伪依赖的,里面什么也不执行。这样的话,就可以执行我们的代码了
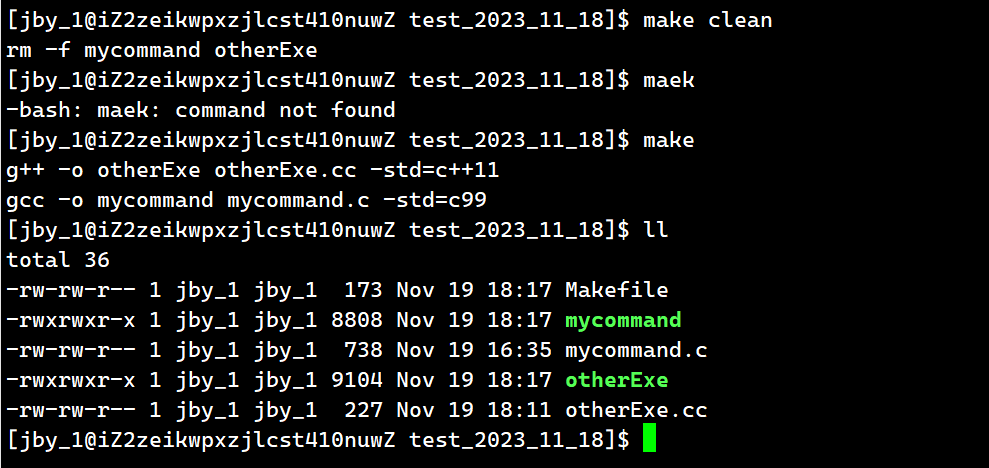
此时我们就可以一次生成两个可执行程序了
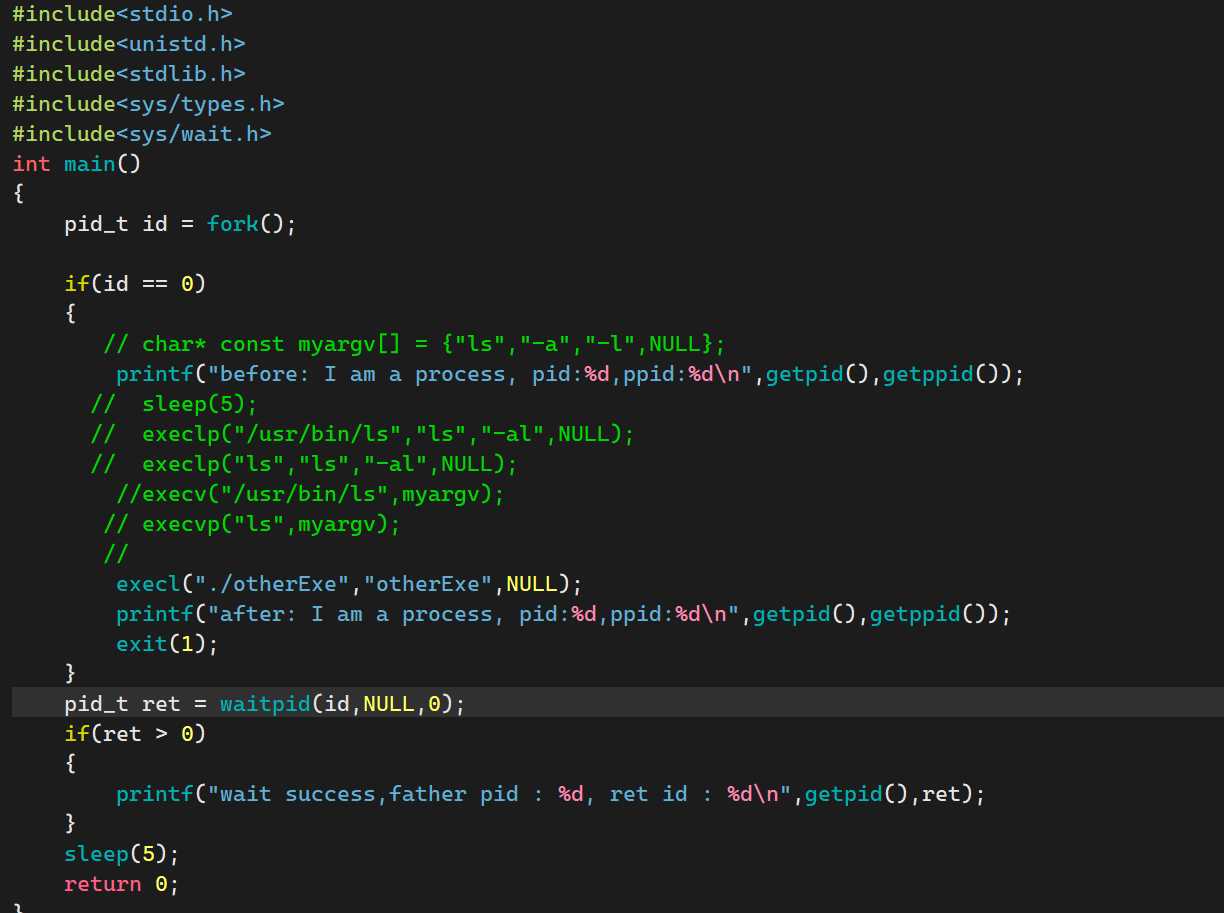
然后我们试着让这个c语言程序去调用这个c++程序
注意这里的两个参数,第一个代表的想要执行的可执行程序是谁,在哪里。第二个参数表示的是想怎么执行
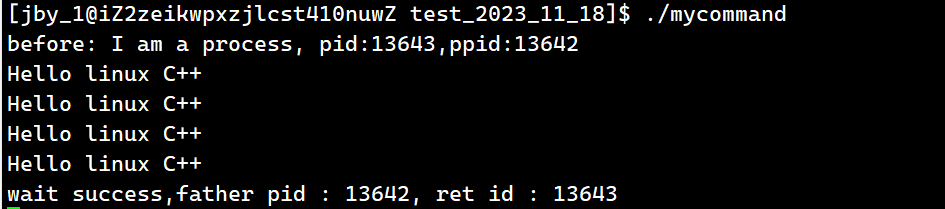
运行结果为
那么像我们C语言形成的可执行程序既然可以调用C++的可执行程序,那么可以调用那些脚本语言形成的可执行程序吗?
比如我们创建一个.sh为结尾的脚本语言文件
touch test.sh然后我们打开它,注意脚本语言,第一行一般都是#!开头的,然后它后面跟的是解释器。
然后这个解释器会对我们下面的文件边读取边执行,然后我们可以写一些脚本语言
然后我们要执行的时候就是这样执行的
此时就把刚刚的代码批量化的执行了
所以所谓的脚本语言就是利用这个命令行解释器,从对应的文件里,一行一行的读取然后一行一行的执行
对于这些脚本语言他们也有自己的语法,比如下面的
它的运行结果为
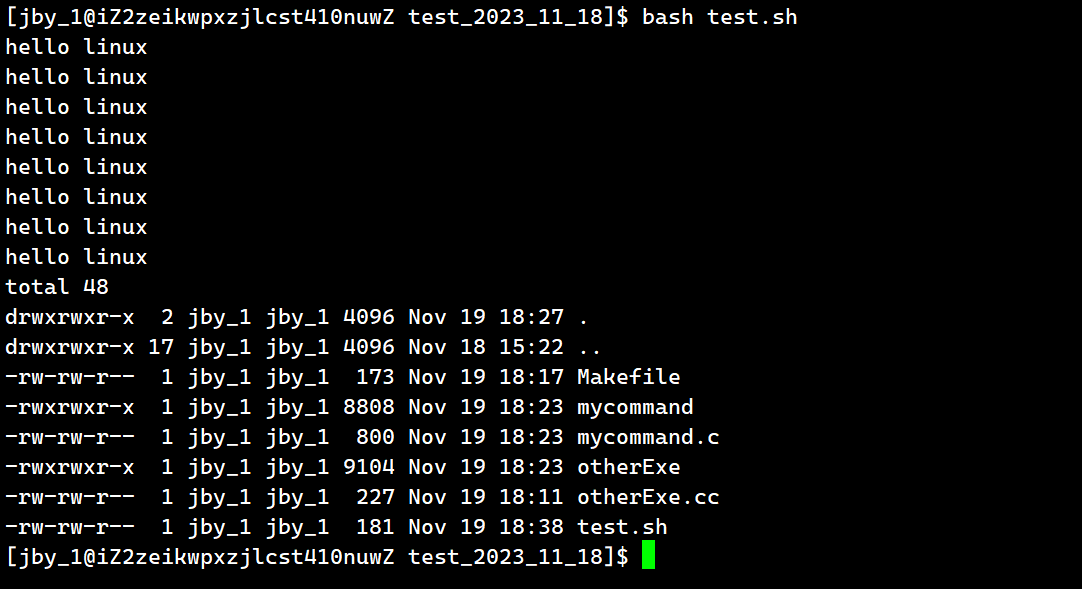
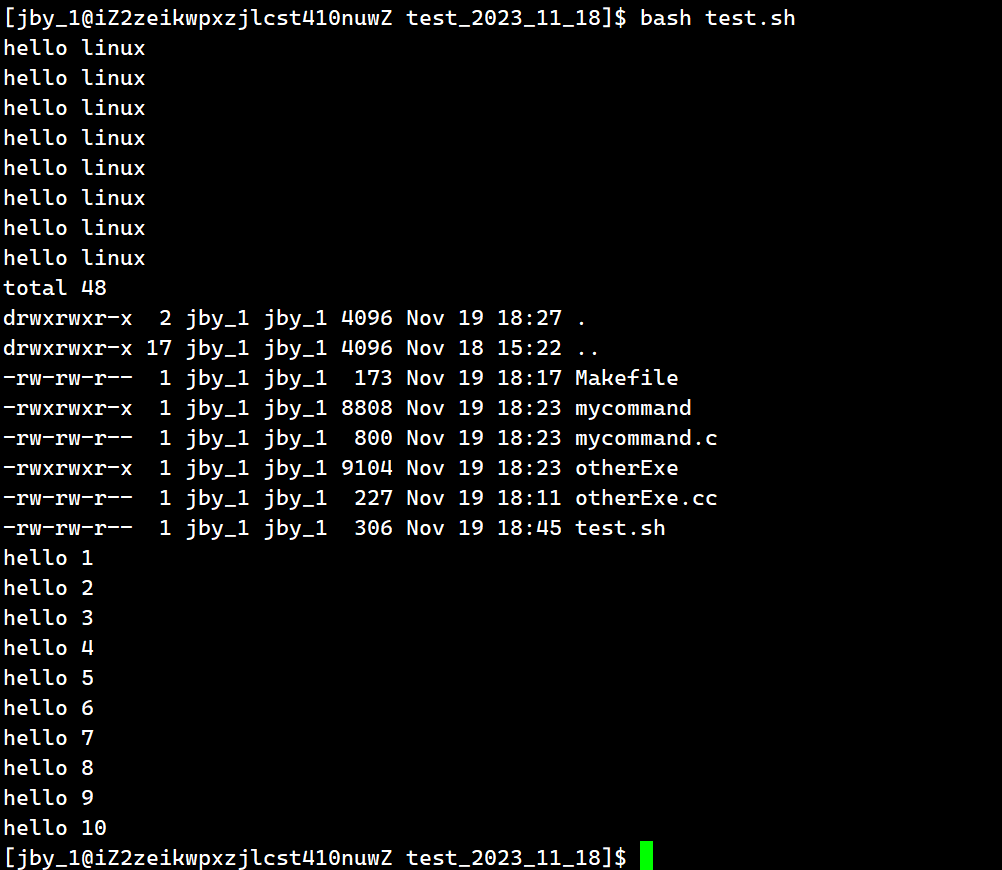
如果我们想要调用这个脚本语言的话,我们可以这样做,让bash这个可执行程序带上test.sh选项即可
运行结果为
我们也可以去执行一个python
直接使用命令行的话,结果如下
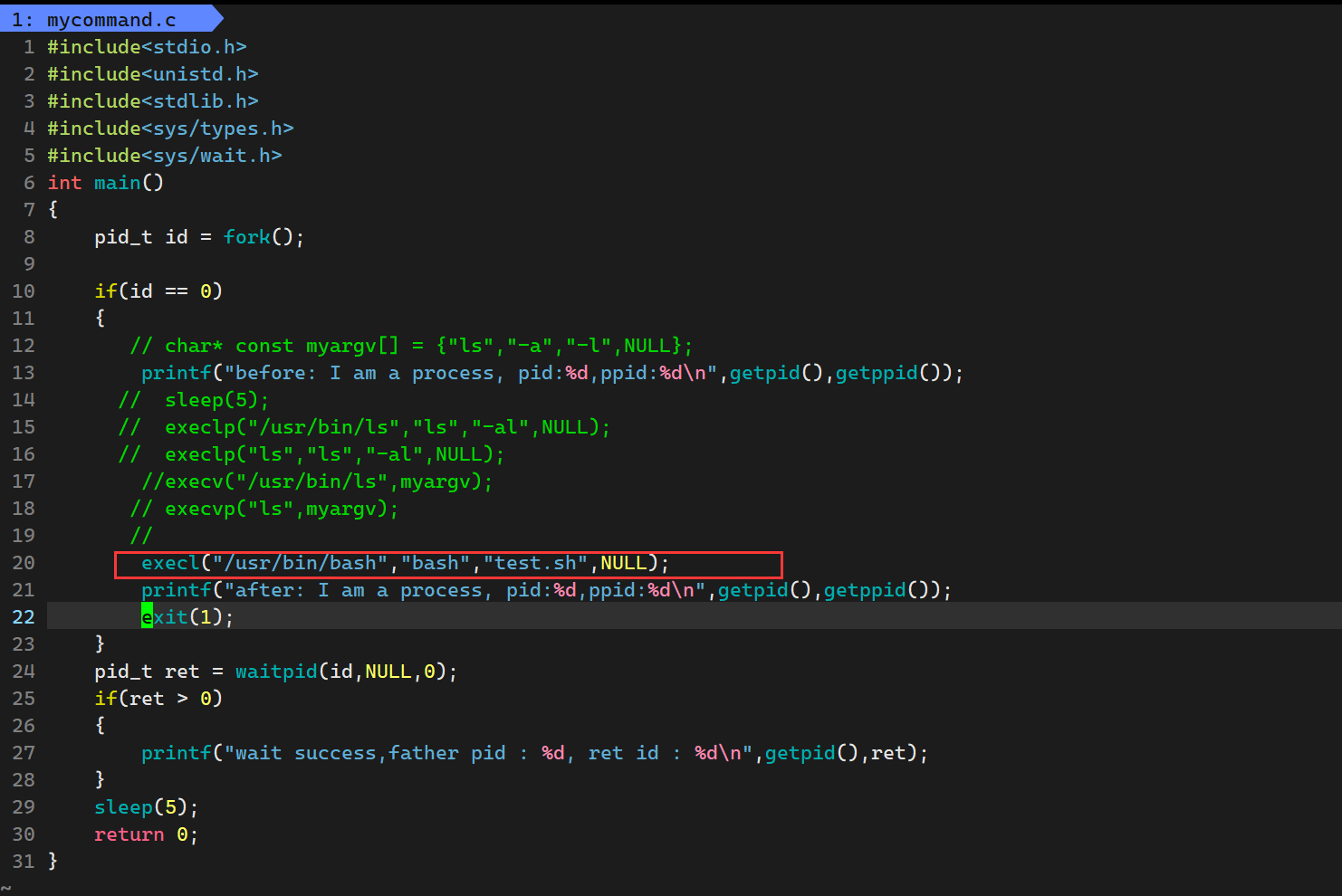
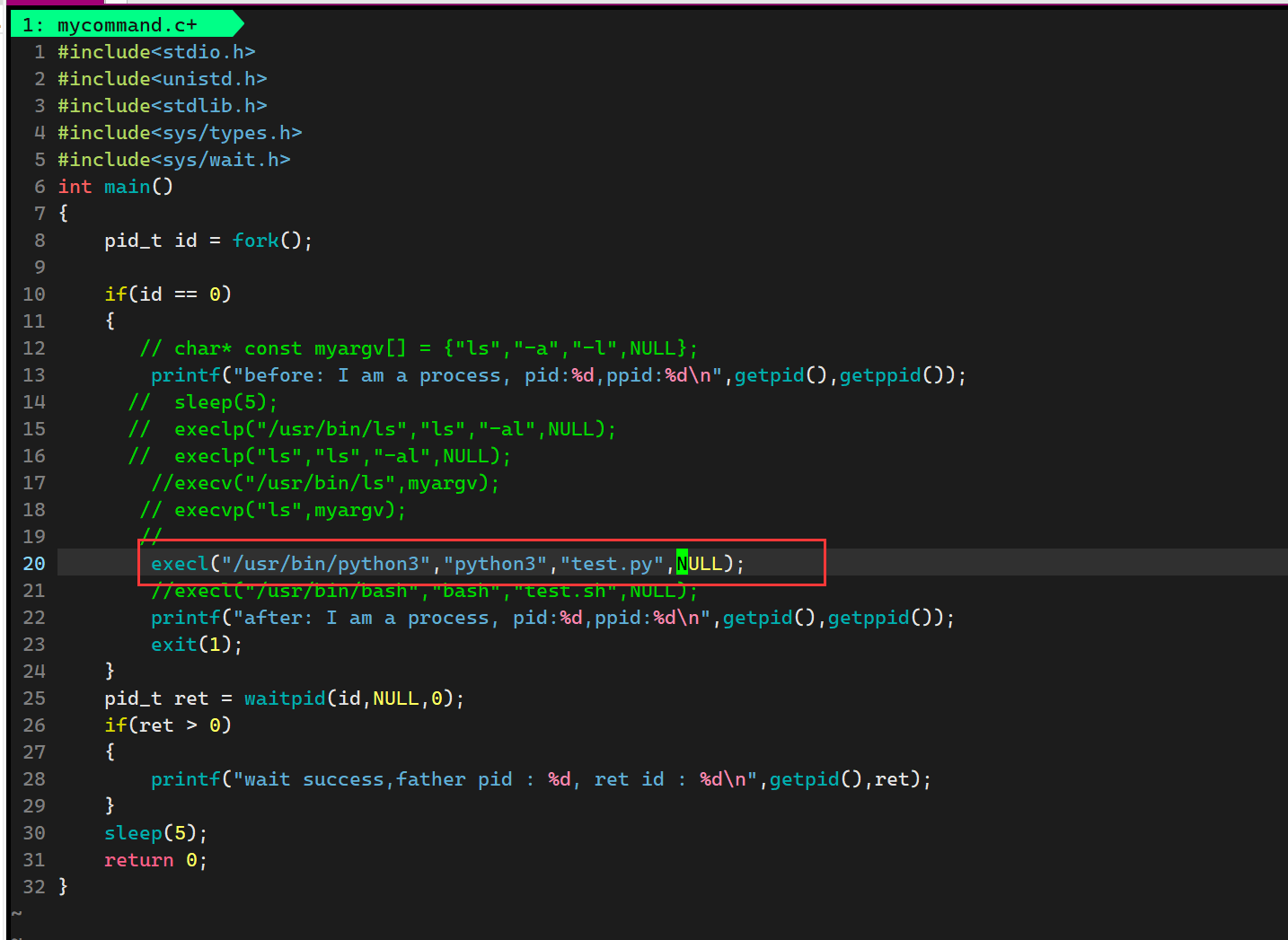
我们可以去用.c进程替换一下
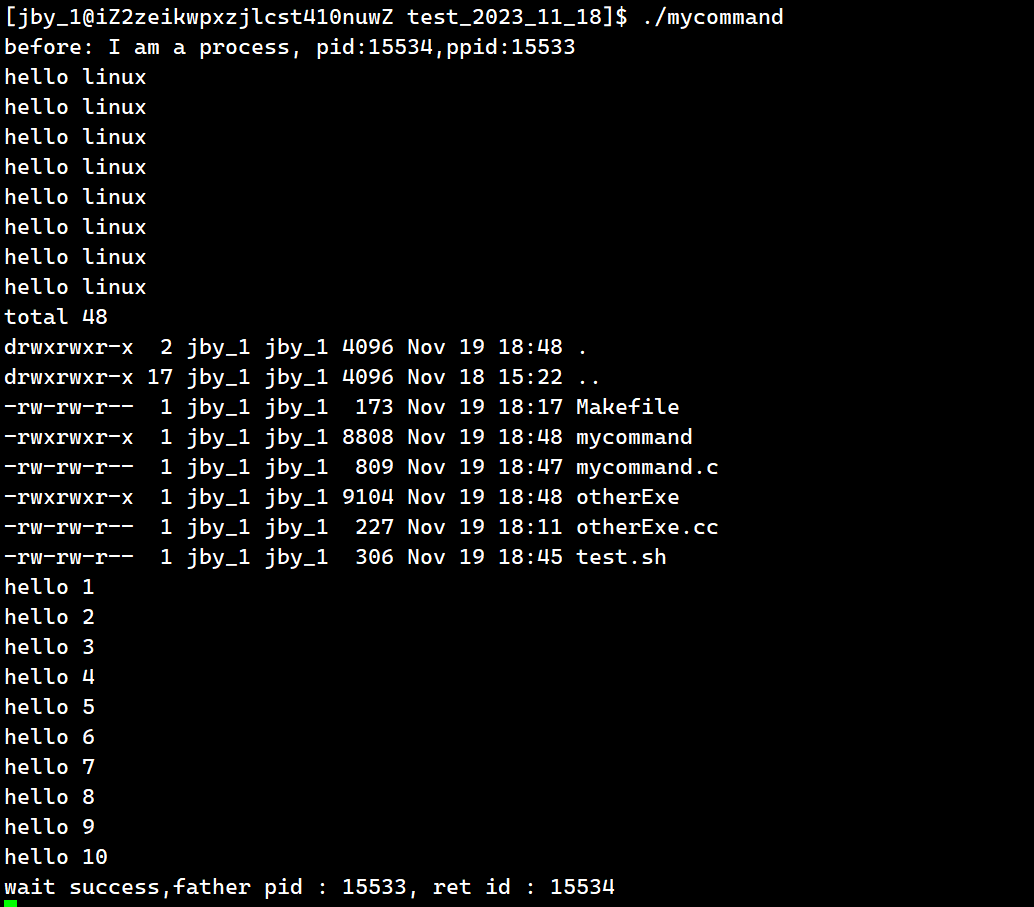
运行结果为
总之无论如何,这里是可以跨语言调用的
那么为什么无论是可执行程序,还是脚本,为什么可以跨语言调用呢?
因为所有语言运行起来,本质都是进程,只要是进程,就可以被调用


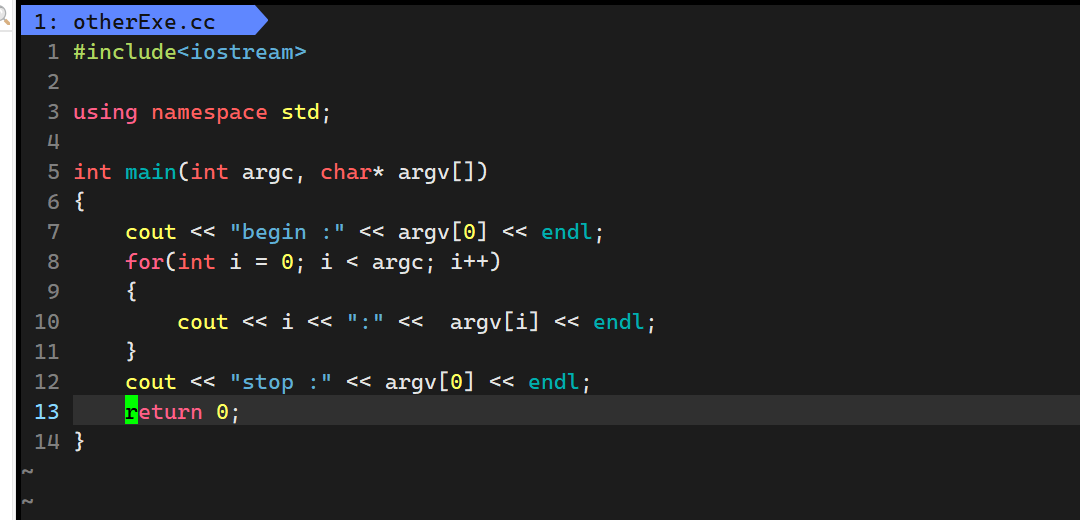
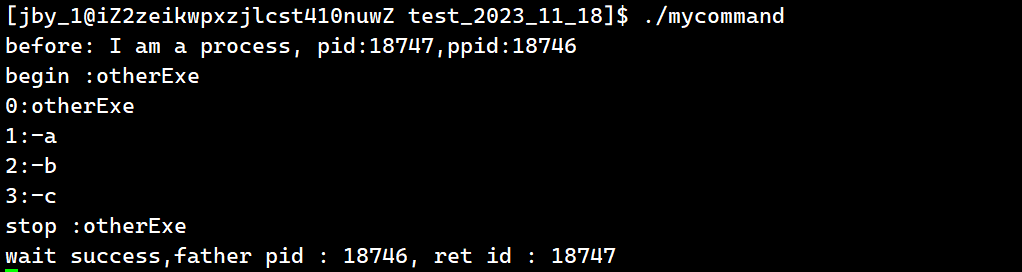
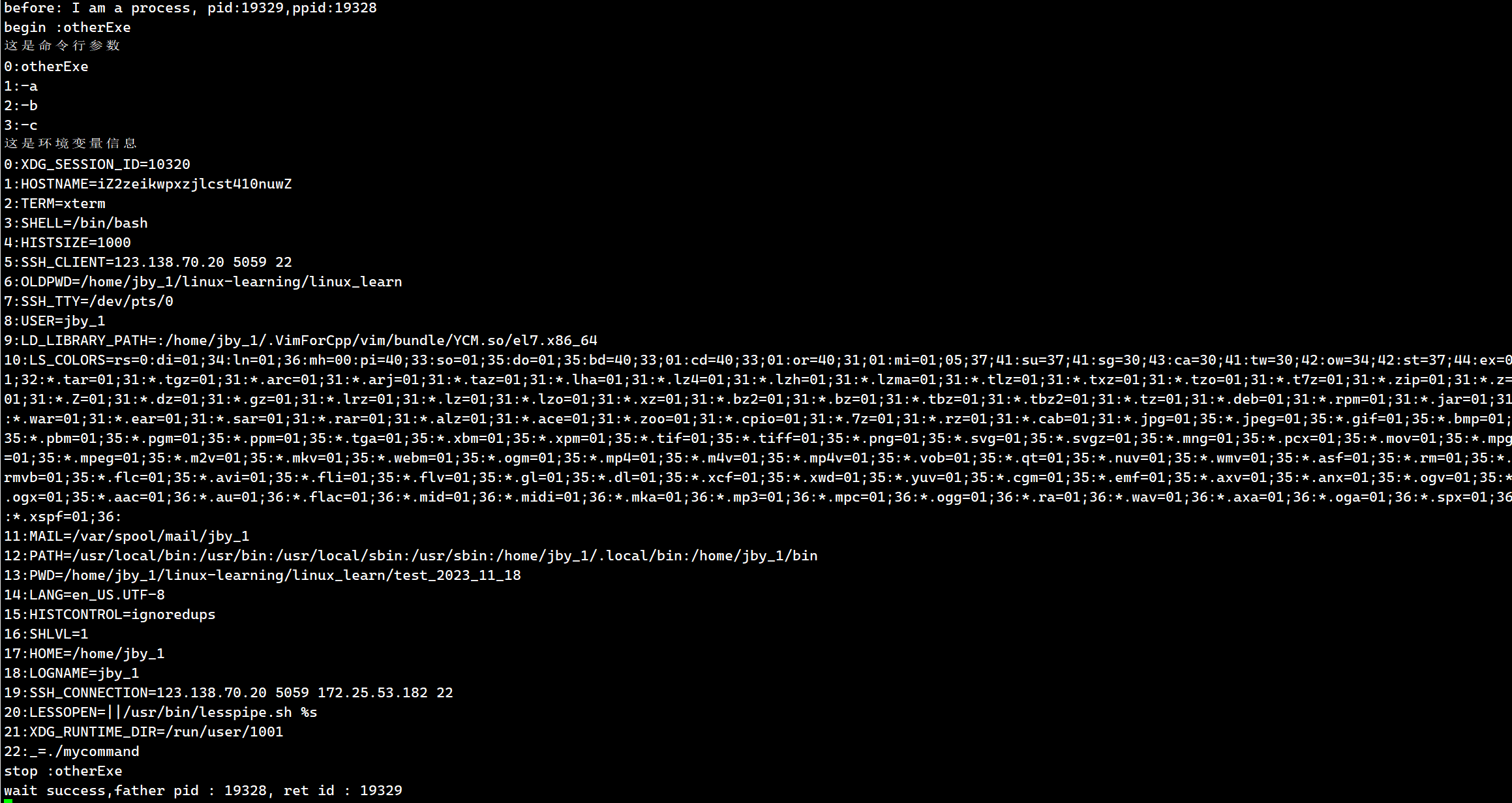
我们可以在进一步的验证一下传入命令行参数的时候
最终运行结果为
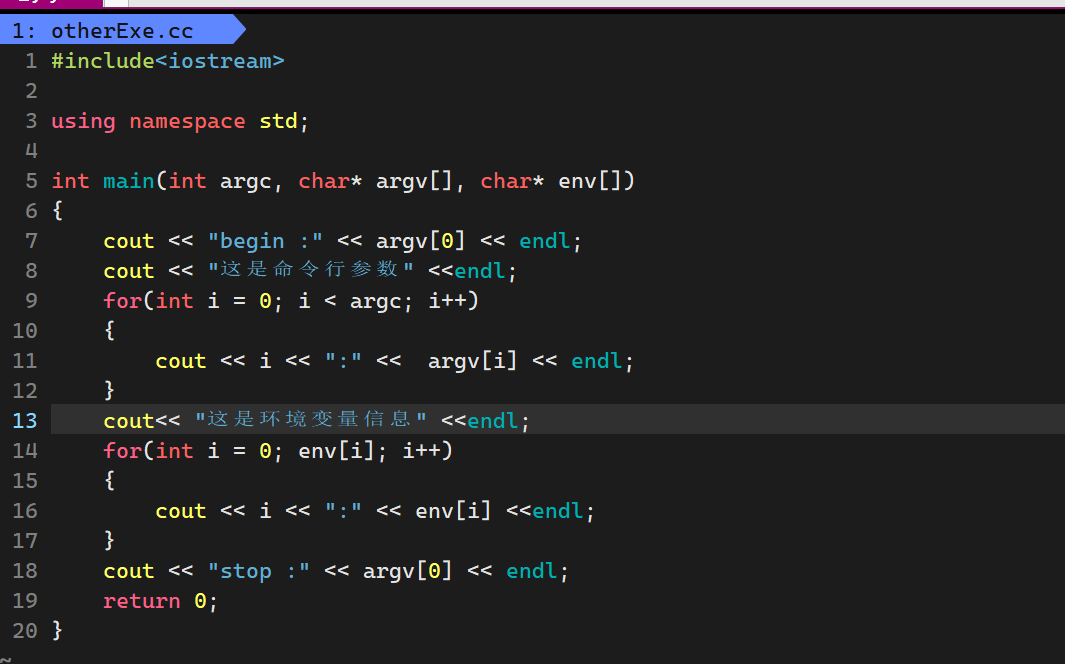
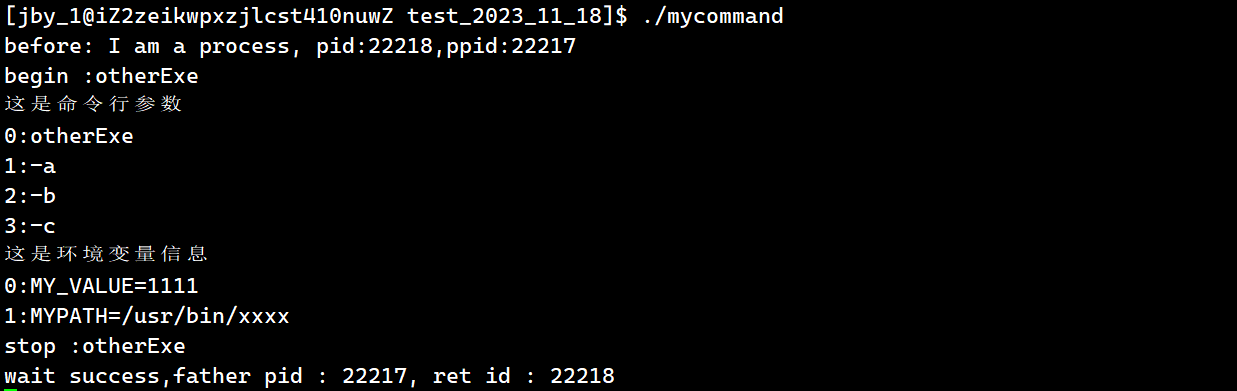
我们可以在试一下第三个命令行参数,环境变量
我们直接运行结果为
我们可以看到,即便我们没有传入环境变量,也会自动将环境变量给传入
那么这是为什么呢?
我们需要先知道,环境变量是什么时候传给进程的。
环境变量也是数据,当我们创建子进程的时候,环境变量就已经被子进程继承下去了!!!,所以像我们之前就可以用extern char** environ去指向环境变量表
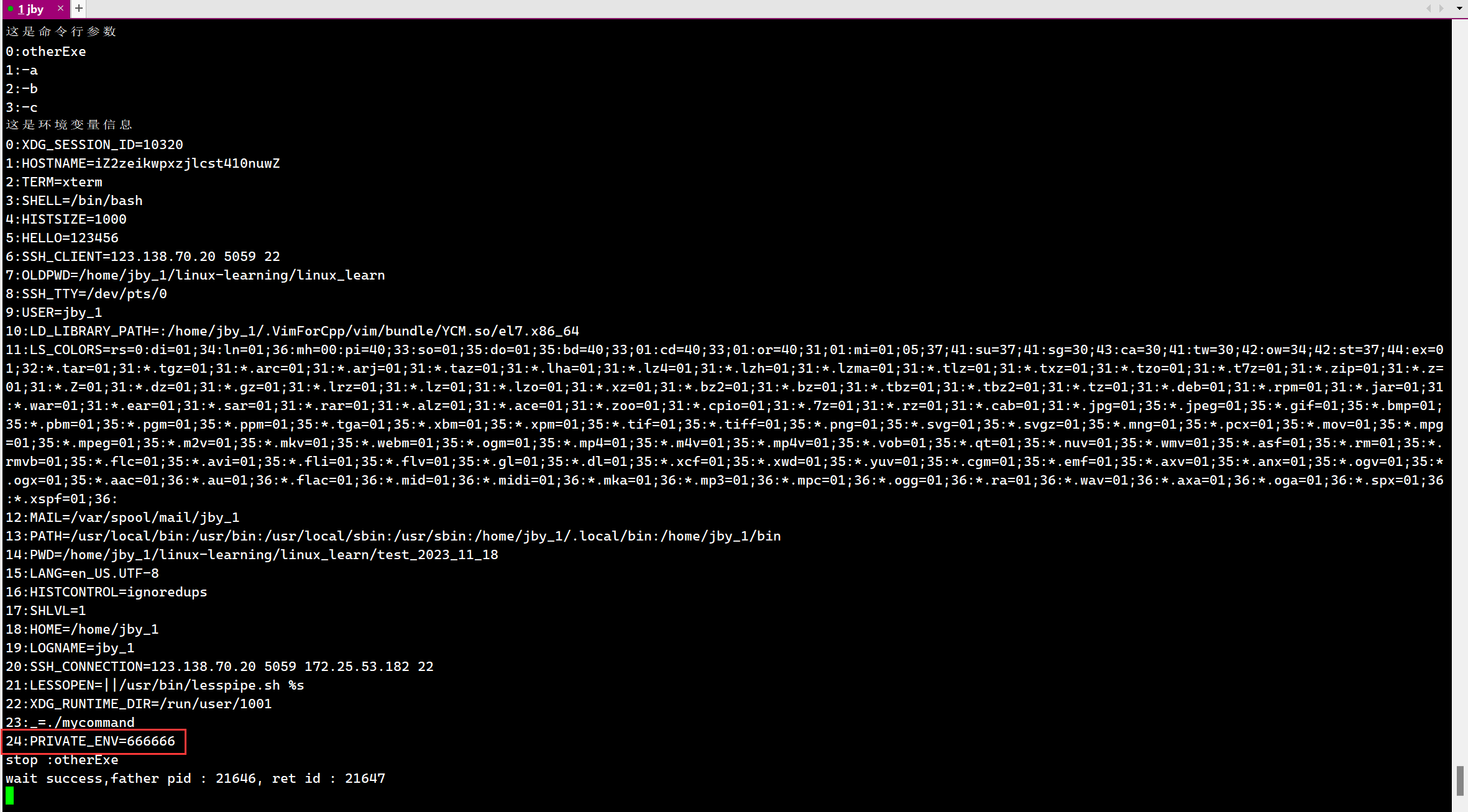
我们还发现,在发生程序替换的时候,环境变量信息依然可以打印,所以环境变量信息不会被替换
所以如果想给子进程传递环境变量,那么应该如何传递呢?
这里的传递可以分为两种
- 新增环境变量
- 彻底替换
我们先来看新增环境变量
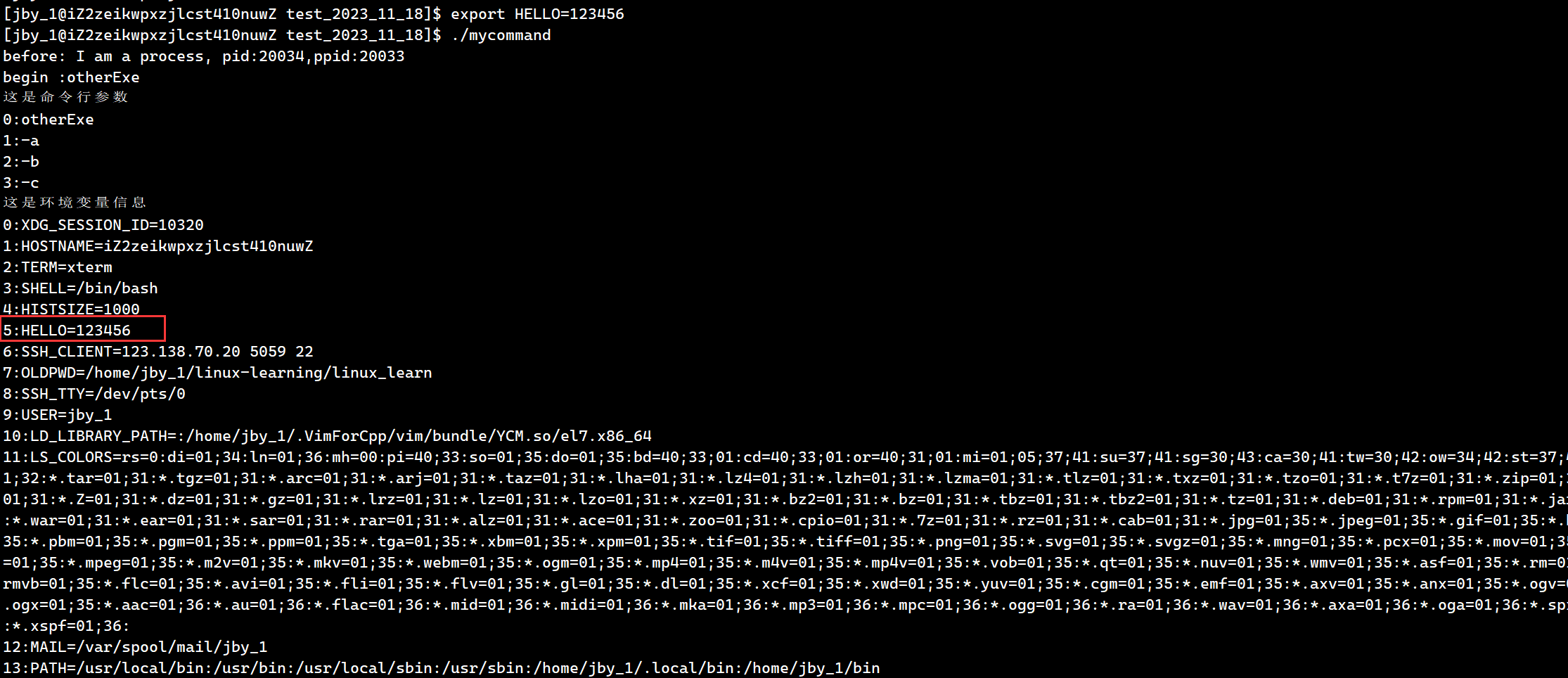
我们最简单,最粗暴的方式就是这样的,直接在bash上导入一个环境变量,然后这个环境变量由于不随着程序替换而消失,而是一路继承下去,所以最终的结果就是如下
那么如果我们不想要这么粗暴呢?即只在这个子进程中有这个环境变量,在bash中是没有这个环境变量的
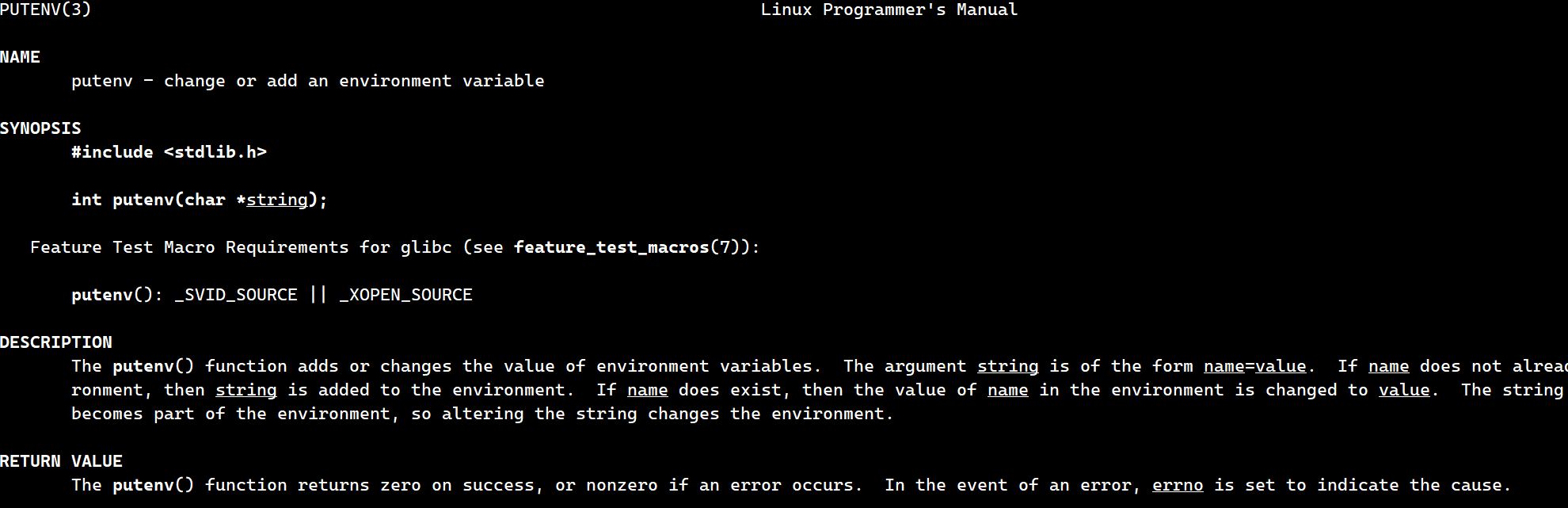
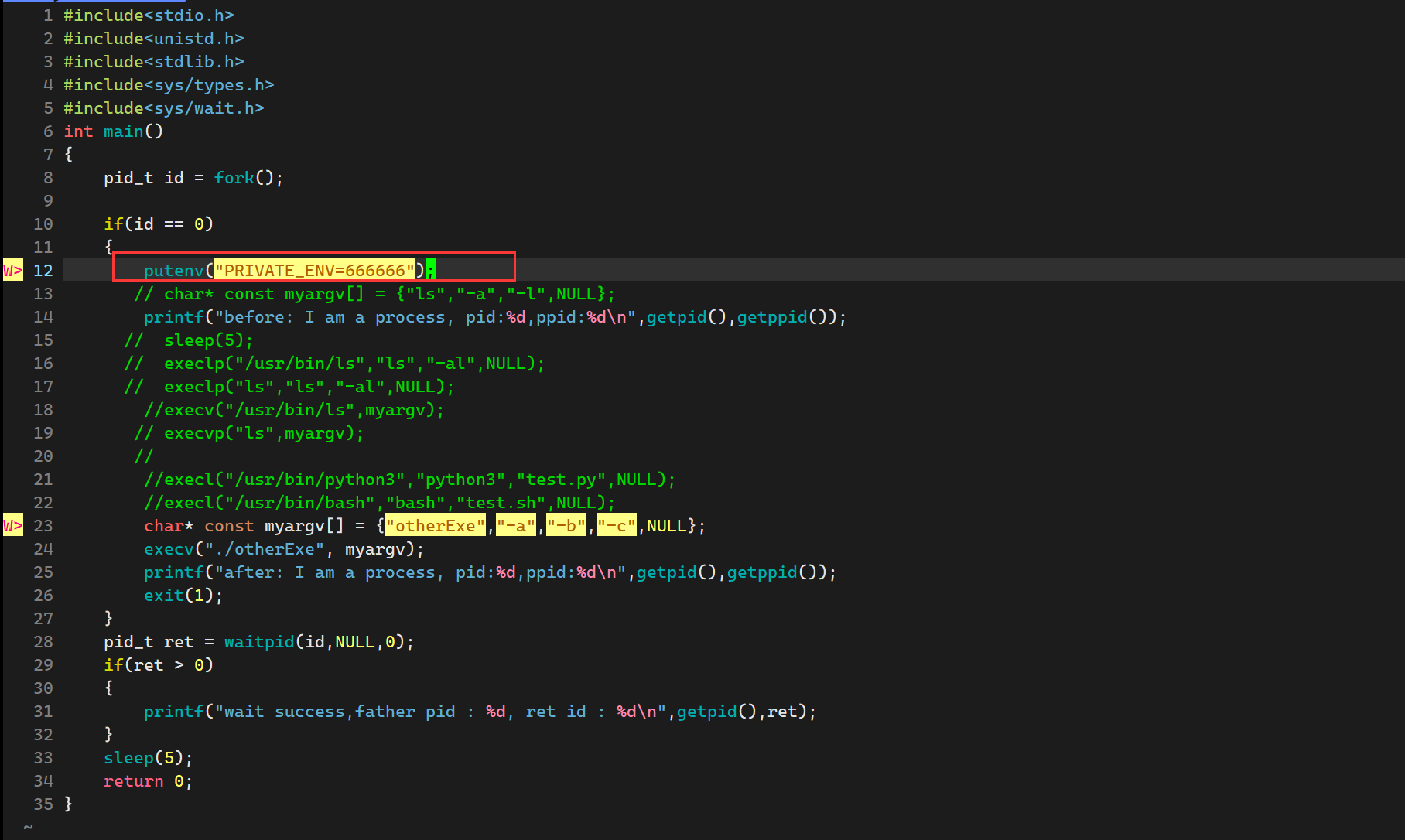
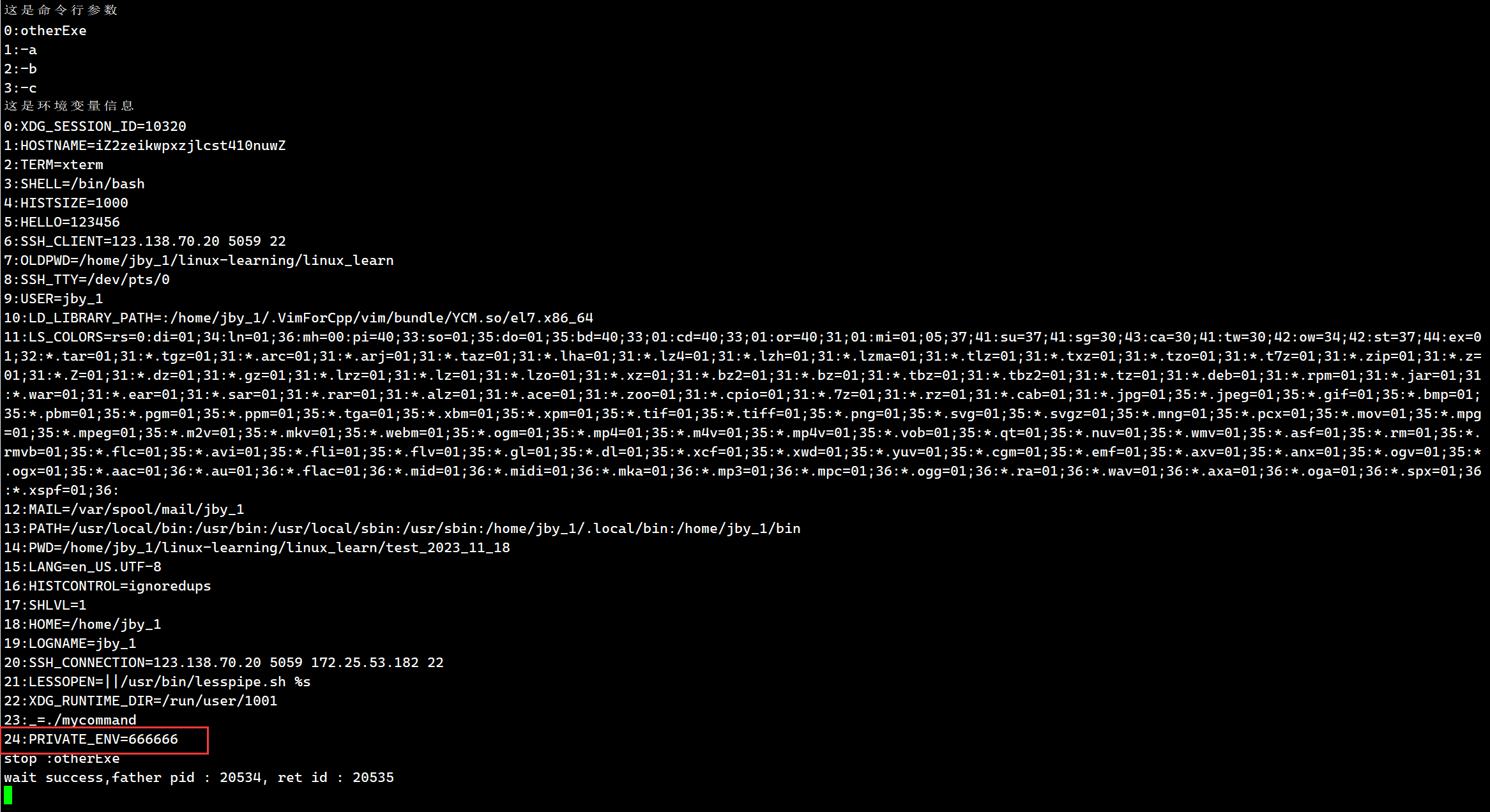
我们之前提过getenv函数获取一个环境变量(还有第三方的的变量,命令行参数两种),其实还有一个函数putenv用于添加一个环境变量
此时我们就可以看到我们的环境变量了
而我们在自己的bash里面是看不到这个环境变量的
所以这个环境变量是可以变得越来越多的
所以如果要新增一个环境变量,在对应的父进程的进程空间直接putenv即可
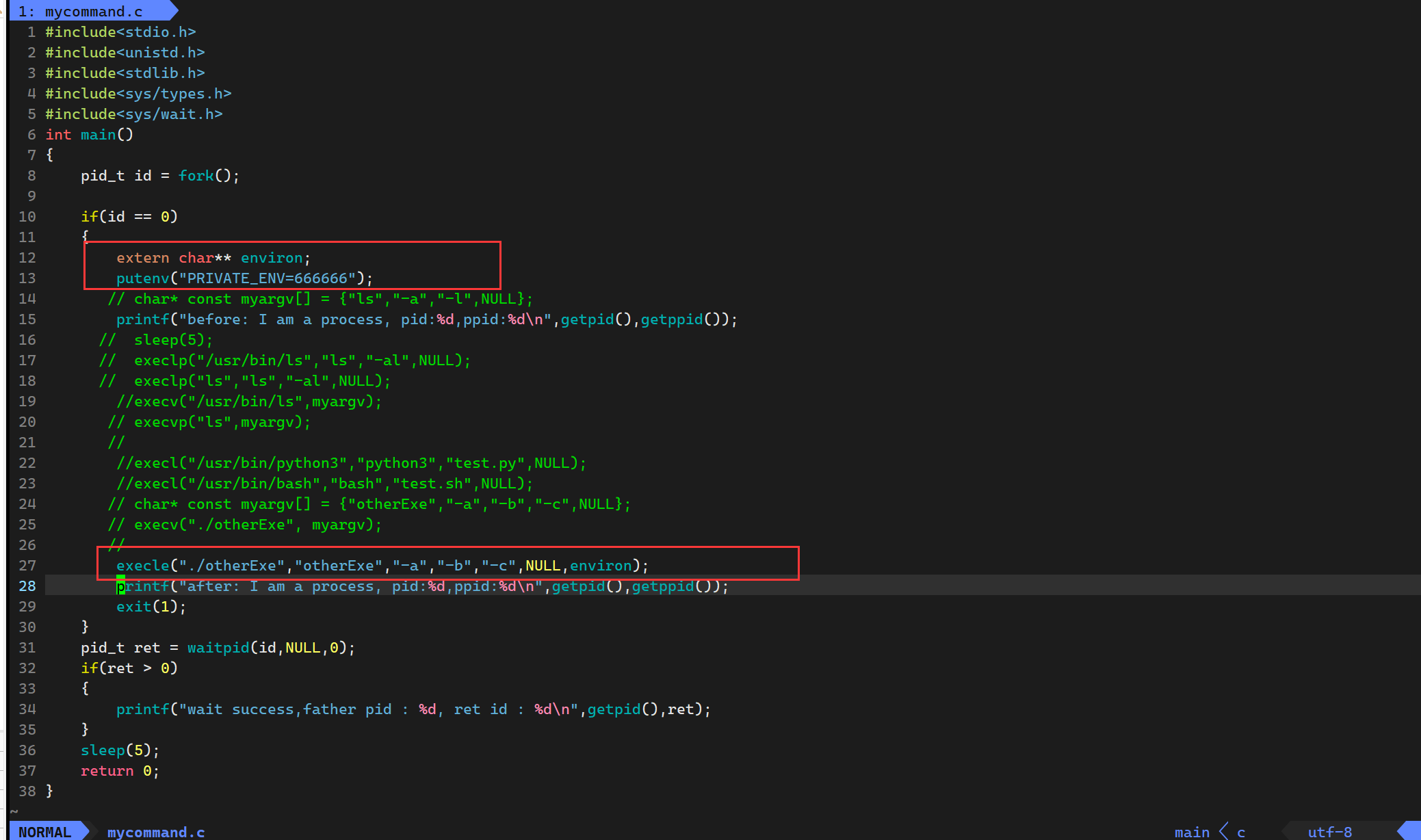
那么如果我们非要传入呢?
我们就需要用到exele函数了
运行结果为
所以这样就可以传入环境变量了
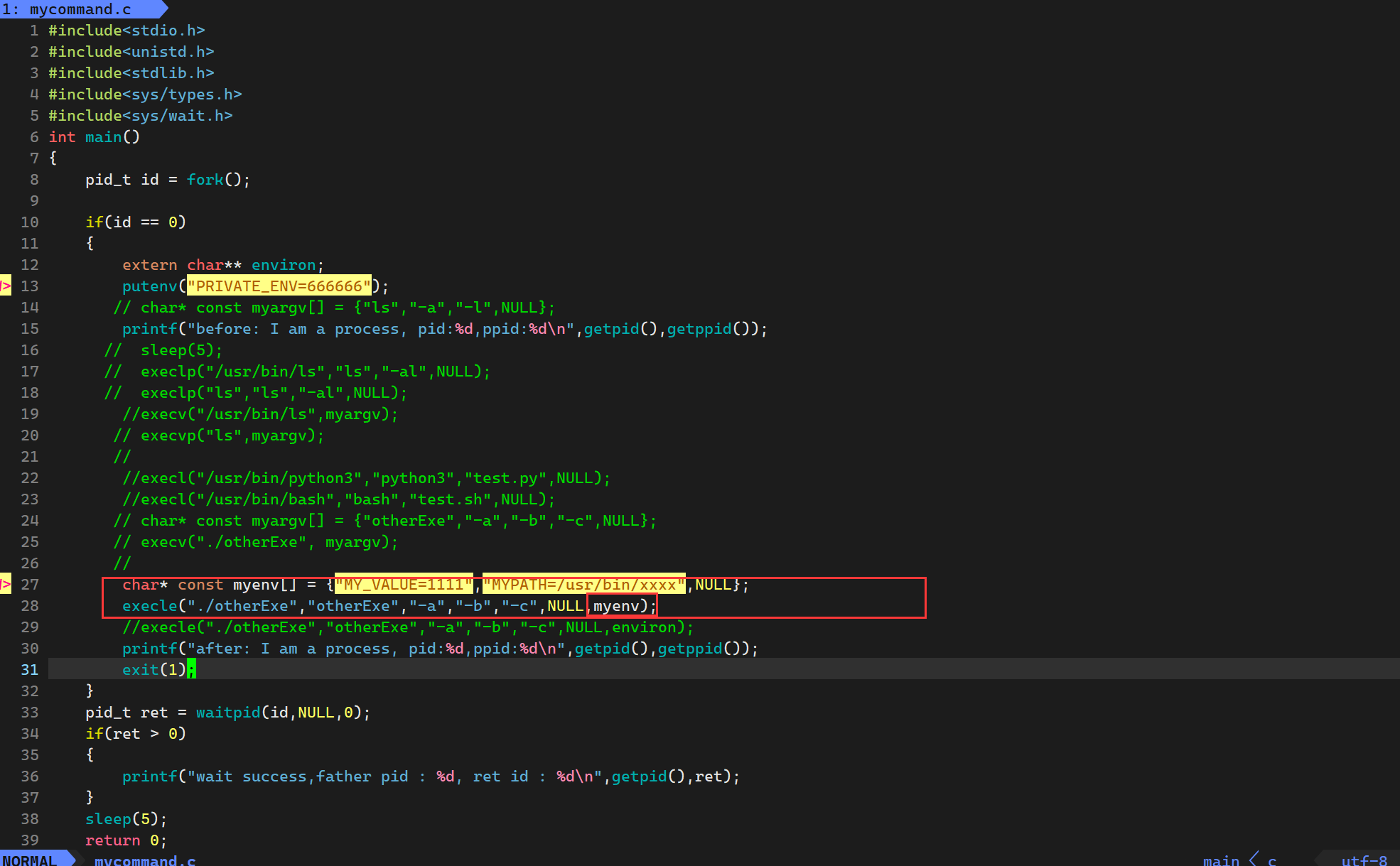
当然不过上面的都是利用了系统的环境变量,但是如果我们想要自定义环境变量的话,我们可以这样做
最终运行结果为
所以用这种方法当我们传递我们自定义的环境变量时候,采用的策略是覆盖,而不是追加