一、C#程序
1.1 基础程序
using System; //引入命名空间namespace CsharpTest //将以下类定义在CsharpTest命名空间中
{internal class TestProgram //定义TestProgram类{public void Test() { }//定义Test方法}
}
方法是C#中的诸多种类的函数之一。另一种函数*,还有构造器,属性,事件,索引器,终结器。
public unsafe static void Test2(int *p1,int p2){int * p = p1 + p2;}
1.2 编译
C#编译器将一系列.cs扩展名的源代码文件编译成程序集。程序集是.NET中的最小打包和部署单元。程序集可以是一个应用程序或者是一个库。应用程序是一个.exe文件,包含一个Main方法。库是一个.dll文件。C#的编译器是csc.exe。
二、语法
c#的语法基于c和c++语法。
2.1 标识符
标识符是程序员为类、方法、变量等选择的名字。
例:
System Test Main x Console WeiteLine
2.2 关键字
关键字是对编译器有特殊意义的名字。
例:
Using class static void int
其它关键字:
| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 |
|---|---|---|---|---|
| abstract | do | in | protected | true |
| as | double | int | public | try |
| base | else | interface | readonly | typeof |
| bool | enum | internal | ref | uint |
| break | event | is | return | ulong |
| byte | explicit | lock | sbyte | unchecked |
| case | extern | long | sealed | unsafe |
| catch | false | namespace | short | ushort |
| chat | finally | new | sizeof | using |
| checked | fixed | null | stackalloc | virtual |
| class | float | object | static | void |
| const | for | operator | string | volatitle |
| continue | foreach | out | struct | while |
| decinmal | goto | override | switch | |
| default | if | params | this | |
| delegate | implicit | private | throw |
2.2.1 避免冲突
如果希望用关键字作为标识符,需要在关键字前面加上@前缀,如:
public void @class() { }
2.2.2 上下文关键字
一些关键字是上下文相关的,它们有时不用添加@前缀就可以用作标识符。
| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 |
|---|---|---|---|---|
| add | dynamic | in | orderby | var |
| ascending | equals | into | patrial | when |
| async | from | join | remove | where |
| await | get | let | select | yield |
| by | global | nameof | set | |
| descending | group | on | value |
2.2.3 字面量、标点、运算符
字面量是静态的嵌入程序的原始数据。12,30
标点:
{} ;
运算符
.() * =
2.2.4 注释
单行注释 //
多行注释 /*开始 */结束
2.3 类型基础
类型是值的蓝图。
int x = 2 * 3;
变量表示一个存储位置,其中的值可能会不断的变换。与之对应,常量总是表示同一个值。
const int y = 360;
C#的所有值都是一种类型的实例。值或者变量所包含的可能取值均由器类型决定。
2.3.1 预定义类型示例
预定义类型是指那些由编译器特别支持的类型。
如
int
string
bool
2.3.2 自定义类型示例
如自己定义一个类Person
Person person = new Person();
2.3.3 类型成员
类型包含数据成员和函数成员。
数据成员如字段
函数成员如构造器和方法
2.3.4构造器和实例化
构造器
如下代码中
internal class Person{string name;public Person(string name){this.name = name;}}
构造器部分为
public Person(string name)
{this.name = name;
}
实例化
Person xiao_ming = new Person("小明");
2.3.5 实例与静态成员
由类型的实例操作的数据成员和函数成员称为实例成员。
那些不是由类型的实例操作,而是由类型本身操作的数据成员和函数成员必须标记为static。Console.WeiteLine就是静态方法。Console类是一个静态类,它的所有成员都是静态的,由于Console类型无法实例化,因此控制台将在整个应用程序内共享使用。
例:
类
internal class Panda
{public string name;public static int population;public Panda(string name){this.name = name;population += 1;}
}
调用
Panda xm = new Panda("xm");
Panda xz = new Panda("xz");
Console.WriteLine(Panda.population);
如果试图xm.population 或者 Panda.Name会出现编译错误。
2.3.6 转换
C#可以转换兼容类型的实例。转换始终会根据一个已经存在的值创建一个新的值。转换可以是隐式或显式的:隐式转换自动发生而显示转换需要强制转换。我们将int隐式转换为long类型(其存储位数是int的两倍);并将一个int显示转换为一个short类型(其存储位数是int的一半);
int x = 123;
long y = x;
short z = (short)x;
隐式转换:
~编译器能确保转换总能成功
~没有信息在转换过程中丢失
显式转换
~编译器不能保证转换总是成功
~信息在转换过程中有可能丢失
2.4 值类型与引用类型
所有的C#类型可以分为以下几类:
~值类型
~引用类型
~泛型参数
~指针类型
值类型包含大多数的内置类型(具体包括所有数值类型、char类型和bool类型)以及struct和enum。
引用类型包含所有的类、数组、委托和接口,包括自定义的string类型。
引用类型和值类型最根本的不同在于它们在内存中的处理方式。
2.4.1值类型
值类型的变量或常量仅仅是一个值。
| Point结构体 |
|---|
| X |
| Y |
public struct Point
{public int X;public int Y;
}
值类型实例的赋值总是会进行实例的复制。例如:
Point p1 = new Point();
p1.X = 7;
Point p2 = p1;
p1.X = 9;Console.WriteLine(p1.X);
Console.WriteLine(p2.X);
p1和p2拥有不同的空间
运行结果
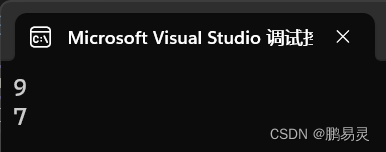
赋值操作复制了值类型的实例。
2.4.2 引用类型
引用类型比值类型复杂,它由两部分组成:对象和对象引用。引用类型变量和常量中的内容是一个含值对象的引用。
内存中的引用类型的实例:
注:结构体的命名和类的命名在同一命名空间下不能相同。以下改写为Point类
public class Point
{public int X;public int Y;
}
给引用类型变量赋值只会复制引用,而不是实例。这允许不同变量指向同一个对象,而值类型通常不会出现这种情况。如果Point是一个类,那么按照之前Point结构体那样操作,p1的操作就会影响p2:
Point p1 = new Point();
p1.X = 7;
Point p2 = p1;
p1.X = 9;Console.WriteLine(p1.X);
Console.WriteLine(p2.X);
运行结果:

赋值操作复制了引用。
2.4.3 Null
引用可以赋值为字面量null,表示它并不指向任何对象
Point p = null;
值类型则不行,例如结构体Point用上面的写法会直接编译报错

C#中也有一种代表值类型的null结构,称为可空类型(nullable)。
Point? p = null;
如上所示,结构体类型采用可空类型写法,编译就可以通过。
2.4.4 储存开销
值类型实际占用的内存大小是储存其字段的内存。例如,结构体Point需要8字节的内存:
public struct Point
{public int X;//4 Bytespublic int Y;//4 Bytes
}
技术上,CLR采用整数倍大小(最大到8个字节)来分配内存地址。因此,下面定义的对象实际会占用16字节的内存,则第一个字段的7个字节被“浪费了”:
public struct P
{public byte b;//1 Bytes CLR采用整数倍大小 最大 8 bytespublic long l;//8 Bytes
}
这种行为可以通过StructLayout重写。
[StructLayout(LayoutKind.Explicit)]internal struct P{[FieldOffset(0)] public byte b;//1 Bytes[FieldOffset(1)] public long l;//偏移1个字节取值}
这样的Struct占用9个字节0。
引用类型要求为引用和对象单独分配内存。对象除占用了个字段一样的字节数外,还需要额外的管理空间开销。管理开销的精确值本质上属于.NET运行时实现的细节,但最少也需要8个字节来存储该对象的类型的键,以及一些诸如多线程锁的状态,是否可以被垃圾回收器固定等信息。根据.NET运行时是工作在32位或64位平台上。每一个对象的引用都需要额外的4到8个字节。
2.4.5 预定义类型分类
C#预定义类型:
值类型
⊶ \origof ⊶数值
⊸ \multimap ⊸有符号整数(sbyte、short、int、long)
⊸ \multimap ⊸无符号整数(byte、ushort、uint、ulong)
⊸ \multimap ⊸实数(float、double、decimal)
⊶ \origof ⊶逻辑值(bool)
⊶ \origof ⊶字符(char)
引用类型
⊶ \origof ⊶字符串(string)
⊶ \origof ⊶对象 (object)
C#的预定义类型又称为框架类型,它们都在System命名空间下。下面语句仅在拼写方面不同:
int i= 1;
System.Int32 i = 1;
在CRL中,除了decimal外的一系列预定义值类型称为基元类型。之所以称为基元类型是因为它们在编译过程中有直接的命令支持。而这种指令通常翻译为底层处理器直接支持的指令。如:
int i= 0;
bool b = true;
char c = 'A';
float f = 0.2f;
System.IntPtr以及System.UIntPtr类型也是基元类型。
2.5 数值类型
C#中的预定义数值类型
| C#类型 | 系统 | 后缀 | 容量 | 数值范围 |
|---|---|---|---|---|
| 整数有符号 | ||||
| sbyte | Sbyte | 8 位 | − 2 − 7 -2^{-7} −2−7~ 2 7 − 1 2^{7}-1 27−1 | |
| short | Int16 | 16 位 | − 2 − 15 -2^{-15} −2−15~ 2 15 − 1 2^{15}-1 215−1 | |
| int | Int32 | 32 位 | − 2 − 31 -2^{-31} −2−31~ 2 31 − 1 2^{31}-1 231−1 | |
| long | Int64 | L | 64 位 | − 2 − 63 -2^{-63} −2−63~ 2 63 − 1 2^{63}-1 263−1 |
| 整数无符号 | ||||
| byte | Byte | 8 位 | 0 0 0~ 2 8 − 1 2^{8}-1 28−1 | |
| ushort | UInt16 | 16 位 | 0 0 0~ 2 16 − 1 2^{16}-1 216−1 | |
| uint | UInt32 | U | 32 位 | 0 0 0~ 2 32 − 1 2^{32}-1 232−1 |
| ulong | UInt64 | UL | 64 位 | 0 0 0~ 2 64 − 1 2^{64}-1 264−1 |
| 实数 | ||||
| float | Single | F | 32 位 | ∓ \mp ∓( 1 0 − 45 10^{-45} 10−45~ 1 0 38 10^{38} 1038 ) |
| double | Souble | D | 64 位 | ∓ \mp ∓( 1 0 − 324 10^{-324} 10−324~ 1 0 308 10^{308} 10308 ) |
| decimal | Decimal | M | 128 位 | ∓ \mp ∓( 1 0 − 28 10^{-28} 10−28~ 1 0 28 10^{28} 1028 ) |
在整数类型中 int 和 long 是最基本的类型,C#和运行时对其有良好的支持。其他的整数类型通常用于实现互操作性或存储空间使用效率要求更高的情况。
在实数类型中 float 和 double 称为浮点类型,并通常用于科学和图形计算。decimal 类型通常用于金融计算这种十进制下的高精度算术运算。
2.5.1 数值字面量
数值字面量的任意位置加下划线以方便阅读:
int million = 1_000_000;
16进制以 0x 前缀:
long y = 0x7F;
2进制以 0b 前缀:
var b = 0b1001_0000;
实数字面量可以用小数或指数表示:
double d = 1.5;
double million = 1E06;
2.5.1.1 数值字面量类型接口
默认情况下,编译器将数值字面量推断为double类型或是整数类型。
⊶ \origof ⊶如果这个字面量包含小数点或者指数符号(E),那么他就是double.
⊶ \origof ⊶否则,这个字面量的类型就是下列能满足这个字面量的第一个类型:int、uint、long、ulong,如:
Console.WriteLine(1.3.GetType());
Console.WriteLine(1E06.GetType());
Console.WriteLine(1.GetType());
Console.WriteLine(0xF0000000.GetType());
Console.WriteLine(0x100000000.GetType());
运行结果:
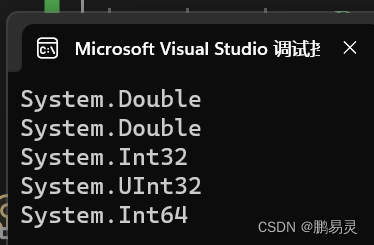
2.5.1.2 数值后缀
数值后缀显示定义了字面量的类型。后缀可以是大写或小写字母:
| 种类 | C#类型 | 例子 |
|---|---|---|
| F | float | float f = 1.0F; |
| D | double | double d = 1D; |
| M | decimal | decimal d = 1.0M; |
| U | uint | uint = 1U; |
| L | long | long i = 1L; |
| UL | ulong | ulong i = 1UL |
一般 U 和 L 后缀是很少需要的。因为uint、long和ulong总是可以推断出来或者从int类型隐式转换过来;
long i = 5;
浮点数类型,后缀D是多余的,编译器数值字面量默认推断为 double 类型。因此可以不用加后缀D:
double i = 1.2;
后缀F和M是最有用的,应该在指定 float 或 decimal 字面量是使用。下面语句不能在没有后缀 F 时进行编译。这是因为4.5会认定为 double 而 double 无法隐式转换为 float:
float f = 4.5F;
同理 double :
decimal d = 1.23M;
2.5.2 数值转换
2.5.2.1 整数类型到整数类型的转换
整数类型转换在能够表示源类型的所有可能值时是隐式转换,否则是显示转换。如:
int x = 123;
隐式转换:
long y = x;
显示转换:
short z = (short)x;
2.5.2.2 浮点类型到浮点类型的转换
double 能表示所有可能的 float 的值,因此 float 能隐式转换为 double。反之则必须是显示转换。
2.5.2.3 浮点类型到整数类型的转换
所有整数类型都可以隐式转换为浮点类型:
int i = 1;
float f = i;
反之,则必须是显示转换:
int i2 = (int)f;
2.5.2.4 decimal类型转换
所有的整数类型都能隐式转换成 decimal 类型。这是因为 decimal 可以表示所有可能的C#整数类型值。其他所有的数值类型转换为 decimal 或从 decimal 类型转换都必须是显示转换。
2.5.3 算术运算符
算术运算符(+、-、*、/、%)可用于除8位和16位的整数类型之外的所有数值类型。
2.5.4 自增和自减运算符
自增(++)和自减运算符分别给数值类型加1或者减1。具体要将其放在变量之前还是之后取决于需要得到变量在自增/自减之前的值还是之后的值。
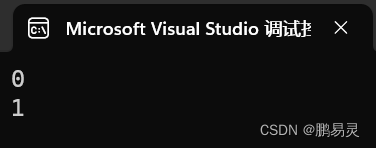
int x = 0, y = 0;Console.WriteLine(x++);Console.WriteLine(++y);
运行结果:
2.5.5 特殊整数类型运算
2.5.5.1 整数除法
整数类型的除法运算总是会截断余数(向0舍入)。用一个值为0的变量做除数将产生运行时错误(DivideByZeroException):
int a = 2 / 3; //0
int b = 0;
int c = 5/ b;//thow DivideByZeroException
2.5.5.2 整数溢出
在运行时执行整数类型的算术可能会造成溢出。默认情况下,溢出会默默的发生而不会抛出任何异常,且其溢出行为是“循环”的。就像是运算发生在更大的整数类型上,而超出的部分就被丢弃了。例如,减小最小的整数值将产生最大的整数值:
int a = int.MinValue;
a--;
Console.WriteLine(a == int.MaxValue);//True
int b = int.MaxValue;
b++;
Console.WriteLine(b == int.MinValue);//True
2.5.5.3 整数运算溢出检查运算符
checked运算符的作用是:在运行时当整数类型表达式或语句超过相应类型的算术限制时不再默默地溢出,而是抛出 OverflowException。
checked运算符对double和float没有作用(它们的溢出为特殊的“无限”值),对decimal也没有作用(这种类型总是会进行溢出检查)。
checked运算符能和表达式或语句块结合使用:
int a = 1000000;
int b = 1000000;
int c = checked(a * b);
checked
{c = a * b;
}
如果你想禁止指定表达式或语句的溢出检查。用unchecked运算符
int x = int.MaxValue;
int y = unchecked(x+1);
unchecked
{int z = unchecked(x+1);
}
2.5.5.4 常量表达式的溢出检查
无论是否用了/checked + 命令开关,编译时的表达式计算总会检查溢出,除非应用了uchecked运算符。
以下语句编译报错
int x = int.MaxValue + 1;//编译报错
解决方案
int x = unchecked(int.MaxValue + 1);
2.5.5.4 位运算符
~ 按位取反
运算规则:二进制上的每一位上的数0变为1,1变为0
例如 10的8位二进制
10 的二进制 00001010 取反得负二进制 11110101 减一 11110100 取反 00001011 二进制转十进制 11 负二进制转十进制 − 11 \def\arraystretch{1.5} \begin{array}{c} 10的二进制 &00001010 \\ \hline 取反得负二进制 &11110101\\ \hline 减一 &11110100\\ \hline 取反 & 00001011\\ \hline 二进制转十进制 & 11 \\ \hline 负二进制转十进制 &-11 \end{array} 10的二进制取反得负二进制减一取反二进制转十进制负二进制转十进制0000101011110101111101000000101111−11
相应的负二进制转换技巧请查看:1.5 负数的二进制
所以 ~10 的结果为 -11
代码示例:
Console.WriteLine(~10); //-11
& 按位与
运算规则:若两个二进制数同一位上的数都为1时,该位上的结果为1;若两个二进制数同一位上的数,其中一个数为0,该位上的结果为0;
以11&13为例:
11 的二进制 1011 13 的二进制 1101 与运算结果 1001 转化为十进制 9 \def\arraystretch{1.5} \begin{array}{c} 11的二进制 &1011 \\ \hline 13的二进制 &1101\\ \hline 与运算结果 & 1001 \\ \hline 转化为十进制 & 9 \end{array} 11的二进制13的二进制与运算结果转化为十进制1011110110019
所以 11&13的结果为 9
代码示例:
int a = 0b1011; //11
int b = 0b1101; //13
int c = 0b1001; //9
Console.WriteLine(a);
Console.WriteLine(b);
Console.WriteLine(a & b); //9
Console.WriteLine(11 & 13); //9
Console.WriteLine(c);
| 按位或
运算规则:若两个二进制数同一位上的数,其中一个数为1,则该位上的结果为1,否则为0;
以3|9为例:
3 的二进制 0011 9 的二进制 1001 或运算结果 1011 转化为十进制 11 \def\arraystretch{1.5} \begin{array}{c} 3的二进制 &0011 \\ \hline 9的二进制 &1001\\ \hline 或运算结果 & 1011 \\ \hline 转化为十进制 & 11 \end{array} 3的二进制9的二进制或运算结果转化为十进制00111001101111
所以 3|9 的结果为 11
代码示例:
int a = 0b0011; //3int b = 0b1001; //9int c = 0b1011; //11Console.WriteLine(a);Console.WriteLine(b);Console.WriteLine(a | b); //11Console.WriteLine(3 | 9); //11Console.WriteLine(c);
^ 按位异或
运算规则:若两个二进制数同一位上的数,其中一个数为1,另一个数为0,则该位上的结果为1,否则为0;
以3^9为例:
3 的二进制 0011 9 的二进制 1001 异或运算结果 1010 转化为十进制 10 \def\arraystretch{1.5} \begin{array}{c} 3的二进制 &0011 \\ \hline 9的二进制 &1001\\ \hline 异或运算结果 & 1010 \\ \hline 转化为十进制 & 10 \end{array} 3的二进制9的二进制异或运算结果转化为十进制00111001101010
所以 3^9 的结果为 10
代码示例:
int a = 0b0011; //3int b = 0b1001; //9int c = 0b1010; //10Console.WriteLine(a);Console.WriteLine(b);Console.WriteLine(a ^ b); //10Console.WriteLine(3 ^ 9); //10Console.WriteLine(c);
<< 按位左移
以3<<2为例,将3的二进制数做移2个位置。
3 的二进制 00000011 左移 2 个位置 00001100 转化为十进制 12 \def\arraystretch{1.5} \begin{array}{c} 3的二进制 &00000011\\ \hline 左移2个位置 & 00001100 \\ \hline 转化为十进制 & 12 \end{array} 3的二进制左移2个位置转化为十进制000000110000110012
代码示例:
int a = 0b00000011;//3
int b = 0b00001100;//1
Console.WriteLine(a << 2);//12
Console.WriteLine(3 << 2);//12
所以3<<2的结果为12
>> 按位右移
以9>>3为例,将9的二进制数右移3个位置。
9 的二进制 00001001 右移 3 个位置 00000001 转化为十进制 1 \def\arraystretch{1.5} \begin{array}{c} 9的二进制 &00001001\\ \hline 右移3个位置 & 00000001 \\ \hline 转化为十进制 & 1 \end{array} 9的二进制右移3个位置转化为十进制00001001000000011
代码示例:
int a = 0b00001001;//9int b = 0b00000001;//1Console.WriteLine(a >> 3);//9Console.WriteLine(9 >> 3);//1
所以9>>3的结果为1
2.5.6 8位和16位整数类型
8位和16位整数类型指的是byte、sbyte、short、ushort。这些类型自己并不具备算术运算,所以C#隐式的将它们转换为所需的更大一些的类型。当试图把运算结果赋给一个小的整数类型时会产生编译错误:
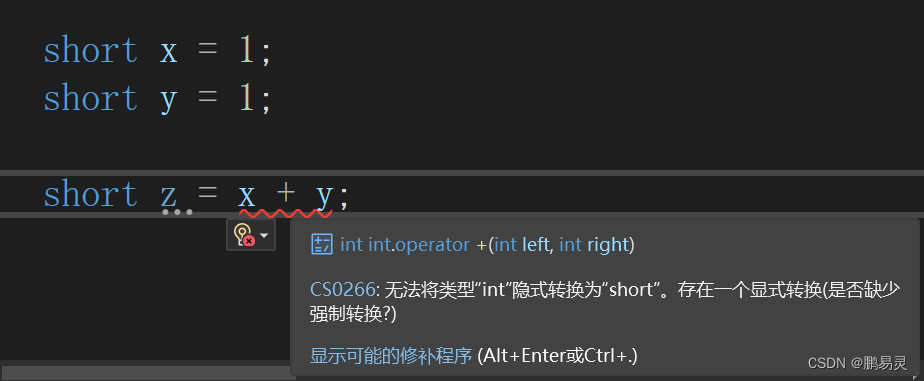
以上情况,x和y会隐式转换成int以便进行加法运算。因此结果也是int,它不能隐式转换回short(因为这可能造成数据丢失)。我们必须显示转换才能令其通过编译:
short z = (short)(x + y);
2.5.7 特殊的float和double值
不同于整数类型,浮点类型包含某些特定运算需要特殊对待的值。这些特殊值是NaN(Not a NUmber,非数字)、 + ∞ +\infin +∞、 − ∞ -\infin −∞和-0。float和double类型包含表示NaN、 + ∞ +\infin +∞、 − ∞ -\infin −∞值的常量。其它常量还有MaxValue、MinBalue、Epsilon。例:
Console.WriteLine(double.NegativeInfinity);
double和float特殊值常量表:
| 特殊值 | double类型常量 | float类型常量 |
|---|---|---|
| NaN | double.NaN | float.NaN |
| + ∞ +\infin +∞ | double.PositiveInfinity | float.PositiveInfinity |
| − ∞ -\infin −∞ | double.NegativeInfinity | float.NegativeInfinity |
| -0 | -0.0 | -0.0f |
非零值除以零,结果是无穷大。例:
Console.WriteLine(1.0/0.0);
Console.WriteLine(-1.0 / 0.0);
Console.WriteLine(1.0 / -0.0);
Console.WriteLine(-1.0 / -0.0);

零除以零或无穷大减去无穷大的结果NaN。例如:
Console.WriteLine(0.0 / 0.0);
Console.WriteLine((1.0 / 0.0) - (1.0 / 0.0));
使用比较运算符(==)时,一个NaN的值永远也不等于其他值,甚至不等于其他NaN的值:
Console.WriteLine((0.0 / 0.0) == double.NaN); //False
必须使用float.IsNaN或double.IsNaN方法来判断一个值是否为NaN:
Console.WriteLine(double.IsNaN(0.0 / 0.0)); //True
Console.WriteLine(float.IsNaN(0.0f / 0.0f)); //True
但使用object.Equal时两个NaN确实相等的
Console.WriteLine(object.Equals(0.0 / 0.0, double.NaN)); //True
NaN在表示特殊值时很有用,在WPF中,double.NaN表示值为“Automatic”自动。另一种表示方法是可空类型(nullable)。还可以使用一个包含数值类型和一个额外字段的自定义结构体。
float和double遵循IEEE 754格式类型规范。处理器原生支持此规范。
2.5.8 double和decimal的对比
double类型在科学计算(例如计算空间坐标)时很有用。decimal在金融计算和计算那些“人为”的而非真实世界度量的结果时很有用。两种类型对比:
| double | decimal | |
|---|---|---|
| 内部表示 | 基数为2 | 基数为10 |
| 精度 | 16为有效数字 | 29位有效数字 |
| 范围 | ∓ \mp ∓( 1 0 − 324 10^{-324} 10−324~ 1 0 308 10^{308} 10308 ) | ∓ \mp ∓( 1 0 − 28 10^{-28} 10−28~ 1 0 28 10^{28} 1028 )) |
| 特殊值 | NaN、 + ∞ +\infin +∞、 − ∞ -\infin −∞和-0 | 无 |
| 速度 | 处理器原生支持 | 非处理器原生支持(速度大约比double慢十倍) |
2.5.9 实数的舍入误差
float和double在内部都是基于2来表示数值的。因此只有基于2表示数值才能够精确表示。事实上,这意味着大多数有小数字部分的字面量(它们都基于10)将无法精确表示。例如:
float tenth = 0.1001f;
float one = 1f;
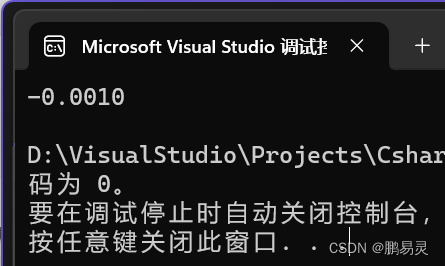
Console.WriteLine(one - tenth * 10f);
理论上,结果应该为:-0.001。
而运行结果为

同样的,如果将关键字float改为decimal:
decimal t = 0.1001M;
decimal o = 1M;
Console.WriteLine(o - t * 10M);
运行结果为
这就是为什么float和double不适合做金融计算。相反,decimal基于10,它能够精确表示基于10的数值(也包括它的因数,基于2和基于5的数值)。因为实数的字面量都是基于10的,所以decimal能够精确表示像0.1这样的数。然而,double和decimal都不能精确表示那些基于10的循环小数:
decimal m = 1M / 6M;
double d = 1.0 / 6.0;
Console.WriteLine(m); //0.1666666666666666666666666667
Console.WriteLine(d); //0.16666666666666666
这样会导致累计性的误差
decimal wholeM = m + m + m + m + m + m;
double wholeD = d + d + d + d + d + d;
Console.WriteLine(wholeM);//1.0000000000000000000000000002
Console.WriteLine(wholeD);//0.9999999999999999
这也将影响相等和比较操作
Console.WriteLine(wholeM == 1M);//False
Console.WriteLine(wholeD < 1.0);//True
2.6 布尔运算和运算符
C#中的bool(System.Boolean)类型是能赋值为True和false字面量的逻辑值。
尽管布尔类型的值仅需要1位的存储空间,但是运行时却需要1字节内存空间。这是因为字节是运行时和处理器能够有效使用的最小单位。为避免使用数组时的空间浪费,.NET framework在System.Collections命令空间下提供了BitArray类,其中的每一个布尔值仅占用一位。
BitArray s = new BitArray(new bool[10]);
s.Set(0, true);
2.6.1 布尔运算和运算符
bool类型不能转换为数值类型,反之亦然。
2.6.2 相等和比较运算符
==和=!用于判断任意类型相等与不等,并总是返回一个bool.
int x = 1;
int y = 2;
int z = 1;
Console.WriteLine(x == y); //False
Console.WriteLine(z == x); //True
对于引用类型,默认情况下相等说基于引用的,而不是底层对象的实际值:
Person p1 = new Person("Wan");Person p2 = new Person("Li");Console.WriteLine(p1 == p2);//FalsePerson p3 = p1;Console.WriteLine(p1 == p3);//True
相等和比较运算符==、!=、<、>、>=、<=可用于所有的数值类型,但是用于实数类型要特别注意参考前面。比较运算符也可以用于枚举类型(enum)类型的成员,他比较的是表示枚举成员的整数值。
public enum EnumValue
{Zero,One,Two
}
Console.WriteLine(EnumValue.Two > EnumValue.One);//True
Console.WriteLine(EnumValue.Zero > EnumValue.One);//False
Console.WriteLine(EnumValue.Two.GetHashCode() > 1);//True
Console.WriteLine(((int)EnumValue.Two) > 1);//True
其中
语句
Console.WriteLine(EnumValue.Two.GetHashCode() > 1);
比语句
Console.WriteLine(((int)EnumValue.Two) > 1);
执行速度快一倍。
2.6.3 条件运算符
&& 和 ||运算符用于判断与和条件。它们常常与代表“非”的!运算符一起使用。在下面例子中,UseUmberalla方法在下雨或阳光充足(雨伞可以保护我们不会经受日晒雨淋),以及无风(因为雨伞在有风的时候true:
static bool UseUmbrella(bool rainy, bool sunny, bool windy)
{return !windy && (sunny || rainy);
}
&& 和 ||运算符会在可能的情况下执行短路计算。如上例子中,如果刮风(windy=true),则(sunny || rainy)将不会计算。
短路计算在某些表达式中是非常必要的,它可以允许如下表达式允许而不会抛出NullReferenceException异常:
if(sb == null ** sb.Length > 0)
{
}
& 和 **|**运算符也可用于判断与和或条件:
return !windy & (sunny | rainy);
不同之处是&和|运算符不支持短路计算。因此它们很少用于替代条件运算符。
三元条件运算符
三元条件运算符(由于它是唯一一个使用三个操作数的运算符,因此也简称为三元运算符)使用q ? a:b的形式。它在q为真时计算a否则计算b。例如:
static int Max(int a, int b)
{return (a > b) ? a : b;
}
条件运算符在LINGQ语句中尤其有用。
2.7 字符串和字符
C# char(System.Char)类型表示一个Unicode字符并占用两个字节。char字面量应位于两个单引号之间:
char c = ‘A’;
转义字符指那些不能用字面量表示或解释的字符。转义字符由反斜线和一个表示特殊含义的字符组成,例如:
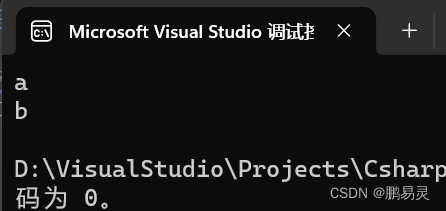
char newLine = '\n';
Console.WriteLine("a" + newLine + "b");
运行结果:
char backSlash = '\\';Console.WriteLine(backSlash);
运行结果:
转义字符序列表:
| 字符 | 含义 | 值 |
|---|---|---|
| \’ | 单引号 | 0x0027 |
| \" | 双引号 | 0x0022 |
| \\ | 斜线 | 0x005C |
| \0 | 空(null) | 0x0000 |
| \a | 警告 | 0x0007 |
| \ b | 退格 | 0x0008 |
| \f | 走纸 | 0x000C |
| \n | 换行 | 0x000A |
| \r | 回车 | 0x000D |
| \t | 水平制符表 | 0x0009 |
| \v | 垂直制符表 | 0x000B |
\u(或\x)转义字符通过4位十六进制代码来指定任意Unicode字符:
char copyrighySymbol = '\u00A9';
char omegasymbol = '\u03A9';
char newLine = '\u000A';
2.7.1 char转换
从chat类型到数值类型的隐式转换只在这个数值类型可以容纳无符号 short 类型时有效。对于其它数值类型,则需要显示转换。
2.7.2 字符串类型
C#中字符串类型(System.String)表示不可变的Unicode字符序列。字符串字面量应位于两个引好(”)之间:
string a = "hahaha";
string类型是引用类型而不是值类型。但是它的相等运算符却遵守值类型的语义。
string x = "test";
string y = "test";
Console.WriteLine(x == y);//True
对char字面量有效的转义字符在字符串中同样有效:
string a = "Here 's a tab:\tmini";
Console.WriteLine(a);
这意味着当需要一个反斜杠时,需要写两次才可以:
string a1 = "\\\\server\\fileshare\\selloworld.cs";
Console.WriteLine(a1);//\\server\fileshare\selloworld.cs
为避免这种情况,C#引入了原意字符串字面量。原意字符串字面量要加@前缀,它不支持转义字符。下面的原意字符串和之前的字符串是一样的。
string a2 = @"\\server\fileshare\selloworld.cs";
愿意字符串可以贯穿多行:
string escaped = "Frist Line\r\nSecond Line";string verbatim = @"Frist Line
Second Line";Console.WriteLine(escaped == verbatim);//True
愿意字符串中需要两个双引号来表示一个双引号字符:
string xml = @"<customer id = ""123""></customer>";
Console.WriteLine(xml);//<customer id = "123"></customer>
2.7.2 .1连接字符串
+运算符可连接两个字符串:
string s = "a" + "b";
Console.WriteLine(s);//ab
如果操作数之一是非字符串值,则会调用其 ToString 方法,例如:
string s = "a" + 5;
Console.WriteLine(s);//a5
重复使用+运算符来构建字符串是低效的。更好的解决方案是使用 System.Text.StringBuilder 类型。
2.7.2.2字符串插值
以$字符为前缀的字符串称为插值字符串。插值字符串可以在大括号内包含表达式:
int x = 4;
Console.WriteLine($"Square has {x} sides");//Square has 4 sides
大括号内可以是任意类型的合法C#表达式。C#会调用其 ToString 方法或等价方法将表达式转换成字符串。若要更改表达式格式,可以使用冒号(:),并继以格式字符串:
var x2 = 0xFF;
string s = $"255 in hex is {byte.MaxValue:x2}";
Console.WriteLine(s);//255 in hex is ff
插值字符串只能是在单行内声明,除非使用意愿字符串运算符。需要注意,$ 运算符必须在 @ 运算符之前:
编译错误:

加意愿字符解决:
int x = 2;
string s = $@"this spans {x} lines";
Console.WriteLine(s);
若要在插值字符中表示大括号,只需要写两个大括号字符即可。
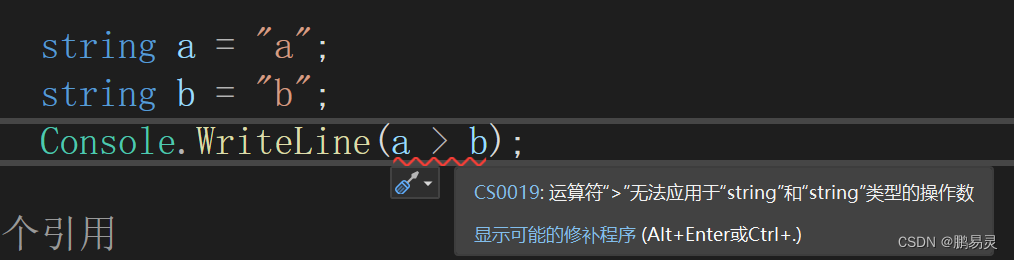
2.7.2.3字符串比较
string 类型不支持 < 和 > 的比较。必须使用字符串的 CompareTo 方法。
编译报错:
比较用法:
例如 StrA.CompareTo(StrB)
如果StrA在StrB排序顺序之前,返回值小于0;
string a = "a";
string b = "c";
Console.WriteLine(a.CompareTo(b));//-1
如果StrA在StrB排序顺序一样,返回值为0;
string a = "a";
string b = "a";
Console.WriteLine(a.CompareTo(b));//0
如果StrA在StrB排序顺序一后或者StrB为null,返回值大于0。
string a = "c";
string b = "a";
Console.WriteLine(a.CompareTo(b));//1
2.8 数组
数组是固定数量的特定类型的集合。为了实现高效的访问,数组中的元素总是储存在连续的内存块中。
C#里面的数组用元素类型后,加方括号表示。例:
char[] chars = new char[3];
方括号也可用于检索数组,数组的索引从零开始,通过位置访问特定元素:
chars[0] = 'a';
chars[1] = 'b';
chars[2] = 'c';
Console.WriteLine(chars[1]);//b
我们可以使用 for 循环语句来遍历数组的每一个元素:
for (int i = 0; i < chars.Length; i++)
{Console.Write(chars[i]);
}//abc
数组的Length属性返回数组中的元素数目。一旦数组创建完毕,它的长度将不能更改。System.Collection命名空间和子命名空间提供了可变长数组和字典等高级数据结构。
数组初始化表达式可以让你一次性声明并填充数组:
char[] chars = new char[] { 'a', 'b', 'c' };
简化写法:
char[] chars = { 'a', 'b', 'c' };
所有数组都继承自System.Array类。它为所有数组提供了通用服务。包括与数组类型无关的获取和设定数组元素的方法。
2.8.1 默认数组元素初始化
创建数组时其元素总会用默认值初始化,类型的默认值是按位取0的内存表示值。例如,若定义一个整数数组,由于int是值类型,因此该操作会在连续的内存块中分配1000个整数。每一个元素的默认值都是0:
int[] a = new int[1000];
Console.WriteLine(a[111]);//0
值类型和引用类型的区别
数组元素的类型是值类型还是引用类型对其性能有重要的影响。若元素类型是值类型,每个元素的值将作为数组的一部分进行分配,例如:
public struct Point
{public int X;public int Y;
}
Point[] a = new Point[1000];
int x = a[500].X; //0
若Point是类,创建数组则仅仅分配了1000空引用:
public class Point
{public int X;public int Y;
}
Point[] a = new Point[1000];
int x = a[500].X; //编译报错,NullReferenceException
为了避免这个错误,我们必须在实例化数组之后显式实例化1000个Point实例:
Point[] a = new Point[1000];
for (int i = 0;i < a.Length; i++)
{a[i] = new Point();
}
int x = a[500].X; //0
无论元素是何种类型,数组本身总是引用类型对象。例如,下面语句是合法的:
int[] a = null;
2.8.2 多维数组
多维数组分为两种类型:矩形数组和锯齿形数组。矩形数组代表n维的内存块,而锯齿形数组则是数组的数组。
2.8.2.1矩形数组
矩形数组声明时用逗号分隔每个维度。下面语句声明了一个矩形二维数组,它的维度是3x3:
int[,] matrix = new int[3,3];
数组的 GetLength 方法返回给定维度的长度:
for (int i = 0; i < matrix.GetLength(0); i++)
{for(int j = 0; j < matrix.GetLength(1); j++){matrix[i, j] = i * 3 + j;}
}
矩形数组可以按照如下方式进行初始化,以下示例创建了一个和上例一样的数组:
int[,] matrix = new int[,]
{{ 0, 1, 2 },{ 3, 4, 5 },{ 6, 7, 8 }
};
2.8.2.2锯齿形数组
锯齿形数组在声明时用一对方括号对表示每个维度。以下例子声明了一个最外层是3的二维锯齿数组:
int[][] matrix = new int[3][];
这里是 new int[3][] 而非 new int[][3] 。
对不同于矩形数组,锯齿形数组内层维度在声明时并未指定。每个内层数组都可以是任意长度。每一个内层数组都隐式初始化为null而不是一个空数组,因此都需要手动创建。
for (int i = 0; i < matrix.GetLength(0); i++)
{matrix[i] = new int[3];for (int j = 0; j < matrix.GetLength(1); j++){matrix[i][j] = i * 3 + j;}
}
锯齿形数组可以按照如下方式进行初始化,以下示例创建了一个和上例一样的数组:
int[][] matrix = new int[][]
{new int[] {0,1,2},new int[] {3,4,5},new int[] {6,7,8,9},
};
2.8.3简化数组初始化表达式
有两种方式可以简化数组初始化表达式。
第一种是省略new运算符和类型限制条件:
char[] vowels = { 'a', 'b', 'c', 'd', 'e' };int[,] rectangularMatrix ={{0, 1, 2},{3, 4, 5},{6, 7, 8}};int[][] jaggedMatirx ={new int[]{0, 1, 2},new int[]{3, 4, 5},new int[]{6, 7, 8}};
第二种是使用var关键字,使编译器隐式确定局部变量类型:
var i = 3;//implicitly int
var s = "sssss";//implicitly stringvar rectangularMatrix = new int[,] //implicitly int[,]
{{0, 1, 2},{3, 4, 5},{6, 7, 8}
};var jaggedMatirx = new int[][]//implicitly int[][]
{new int[]{0, 1, 2},new int[]{3, 4, 5},new int[]{6, 7, 8}
};
数组类型可以进一步应用隐式类型转换规则:可以直接在 new 关键字之后忽略类型限定符,而由编译器推断数组的类型:
var vowels = new[]{ 'a', 'b', 'c', 'd', 'e' };
为了使上述机制工作,数组中的所有元素必须能够隐式转换为一种类型。例:
var x = new[] { 1, 1000000000 }; //all convertible to long
2.8.4边界检查
运行时会为所有数组的索引操作进行边界检查。如果是用了不合法的索引值,就会抛出 IndexOutOfRangeException 异常。
int[] arr = new int[3];
arr[3] = 1;//thow IndexOutOfRangeException
数组边界检查对类型安全和调试简化都是非常必要的。
通常,边界检查的性能开销很小,且JIT(即时编译器)也会对其优化。例如,在进入循环之前预先确保所有的索引操作的安全性来避免每次循环中都进行检查。另外C#还提供了 unsafe 代码来显式绕过边界检查。
2.9 变量和参数
变量表示存储着可变值的存储位置。变量可以是局部变量、参数(value、ref或out)、字段(实例或静态)以及数组元素。
2.9.1 栈和堆
栈和堆是存储变量和常量的地方。它们分别具有不同生命周期语义。
2.9.1.1 栈
栈是存储局部变量和参数的内存块。逻辑上,栈会在函数进入和退出时增加或减少。考虑下面方法(为了避免干扰,该范例省略了输入参数检查):
static int Factorial(int x)
{if (x == 0) return 1;return x * Factorial(x - 1);
}
这个方法是递归的,即调用它自身。每一次进入这个方法的时候就在栈上分配一个新的 int 而每一次离开这个方法,就会释放一个 int。
2.9.1.2 递归的风险
递归调用在深度上不可预测,层数过多不断压栈,可能会引起栈溢出而崩溃。
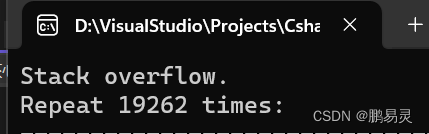
1.死循环
static int Factorial(int x)
{return x * Factorial(x - 1);
}
运行结果:
2.栈不够用
例如一个局部变量buffer为10M,如果你的栈默认也为10M,这就会发生溢出,因为其他东西会占掉少量栈空间,局部变量能用的空间肯定小于10M,就会跳出 stack overflow异常
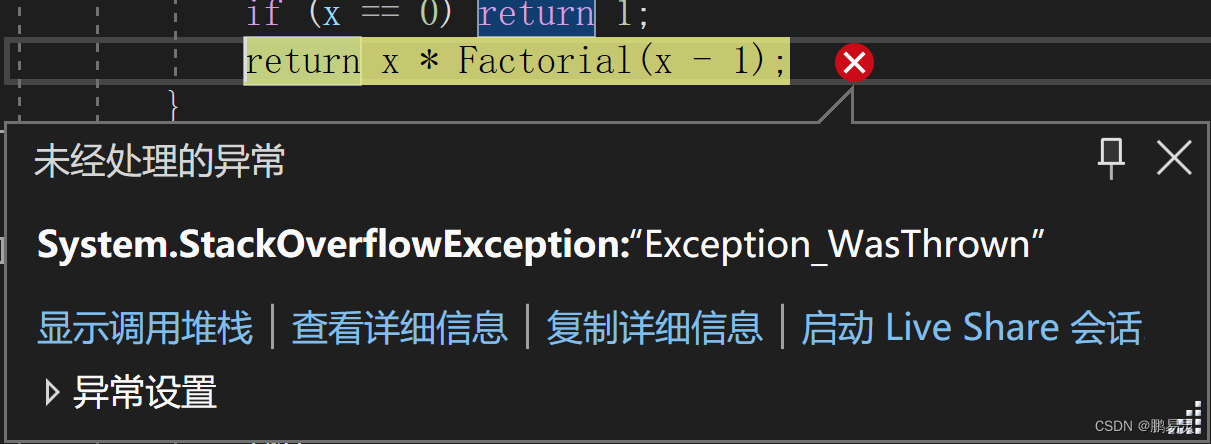
3.调用层数太深
在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当程序执行进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,就会导致栈溢出。函数的参数是通过stack栈来传递的,在调用中会占用线程的栈资源。递归调用在到达最后的结束点后,函数才能依次退栈清栈,如果递归调用层数过多,就可能导致占用的栈资源超过线程的最大值,从而导致栈溢出,程序异常退出。
例:
static int Factorial(int x)
{if (x == 0) return 1;return x * Factorial(x - 1);
}
Console.WriteLine(Factorial(100000));
运行结果:
3.1递归层数太深解决方法
3.1.1将递归改为循环
static int FactorialWhile(int x)
{int num = 1;while(x > 0){num *= x;x--;}return num;
}
3.1.2 加线程
定义
static int count = 0;
static int total = 1;
static void FactorialEnd(int i)
{count++;//Console.WriteLine(count);if (i == 0){Console.WriteLine("total:" + total);return;}if (count % 10 == 0){Thread thread = new Thread(delegate(){total *= i;FactorialEnd(i - 1);});thread.Start();return;}total *= i;FactorialEnd(i - 1);
}
调用:
FactorialEnd(20000);
2.9.1.2 堆
堆是保存对象(例如引用类型的实例)的内存块。新创建的对象会分配在堆上并返回其引用。程序执行过程中,堆就会被新创建的对象不断填充。.NET运行时的垃圾回收器会定时从堆上释放对象,因此应用程序不会内存不足。只要对象没有被”存活“的对象引用,它就可以被释放。
下面例子中,我们创建了一个 StringBuilder 对象并将其引用赋值给 ref1 变量,之后在其中写入内容。StringBuilder 对象在后续没有使用的情况下可立即被垃圾回收器释放。
之后,我们创建另一个 StringBuilder 对象赋值给 ref2 ,再将引用复制给 ref3 。虽然 ref2 之后便不再使用,但是由于 ref3 保持着同一个 StringBuilder 对象的引用,因此在 ref3 使用完毕之前它不会被垃圾回收器回收。
StringBuilder ref1 = new StringBuilder("object1");
Console.WriteLine(ref1);StringBuilder ref2 = new StringBuilder("object2");
StringBuilder ref3 = ref2;
Console.WriteLine(ref3);
值类型的实例(和对象的引用)就存储在变量声明的地方。如果声明为类的字段或数组的元素,则该实例会存储在堆上。C#中无法像C++那样显示的删除对象。未引用的对象最终将被垃圾回收器回收。
静态字段也会存储在堆上。与分配在堆的对象(可以被垃圾回收器回收)不同,这些变量一直存活直至应用程序域结束。
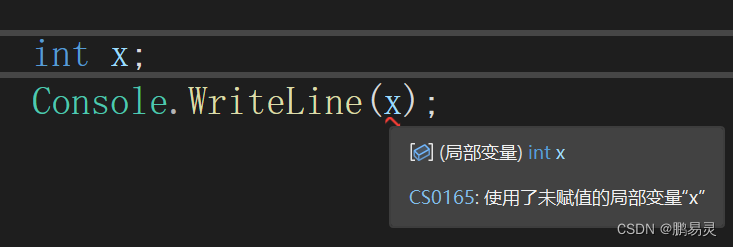
2.9.2 明确赋值
C#强制执行明确赋值策略。实践中这意味着在 unsafe 上下文之外无法访问未初始化的内存。明确赋值有三种含义:
1.局部变量在读取之前必须赋值。
2.调用方法时必须提供函数的实际参数。
3.运行时将自动初始化其他变量(例如字段和数组元素)。
例如,以下示例将产生编译错误:
字段和数组会自动初始化为其类型的默认值。以下代码输出0,就是因为数组元素会隐式赋值为默认值:
int[] ints = new int[2];
Console.WriteLine(ints[0]);//0
以下代码输出0,因为字段会隐式赋值为默认值:
static int x;
static void main()
{Console.WriteLine(x);//0
}
2.9.3 默认值
所有类型的实例都有默认值。预定义类型的默认值是按位取0的内存表示的值。
| 类型 | 默认值 |
|---|---|
| 所有引用类型 | null |
| 所有数字和枚举类型 | 0 |
| char类型 | ‘\0’ |
| bool类型 | false |
default 关键字可用于获得任意类型的默认值(这对泛型非常有用)
decimal d =default(decimal);
Console.WriteLine(d);//0
自定义值类型(例如struct)的默认值等同于每一个字段都取其默认值。
2.9.4 参数
方法可以有一连串参数。在调用方法时必须为这些参数提供实际值。
方法
static void Foo(int p)
{p = p + 1;Console.WriteLine(p);
}
调用
Foo(10);
使用 ref 和 out 可以控制参数的传递方式:
| 参数修饰符 | 传递类型 | 必须明确赋值的变量 |
|---|---|---|
| 无 | 按值传递 | 传入 |
| ref | 按引用传递 | 传入 |
| out | 按引用传递 | 传出 |
2.9.4.1 按值传递参数
默认情况下,C#中的参数默认按值传递,这是最常用的方式。这意味着在将参数值传递给方法的时将创建一份参数值的副本。
方法
static void Foo(int p)
{p = p + 1;Console.WriteLine(p);
}
调用
int x = 8;
Foo(x);//make a copy of x
Console.WriteLine(x); //8
为p赋一个新的值并不会改变x的值因为p和x分别存储在不同的内存位置中。
按值传递引用类型参数复制的是引用本身而非对象本身。下例中,Foo方法中的StringBuilder对象和Main方法中实例同化的是同一个对象,但是它们的引用不同。换句话说,变量sb个fooSB是引用同一个StringBuilder对象的不同变量。
方法
static void Foo(StringBuilder fooSB)
{fooSB.Append("test");fooSB = null;
}
Main方法调用
StringBuilder sb = new StringBuilder();
Foo(sb);
Console.WriteLine(sb.ToString());//test
由于fooSB是引用的一份副本,因此将它赋值为null并不会把sb也赋值为null(然而,如果在声明和调用fooSB时使用ref修饰符,则sb会变成null)。
2.9.4.2 ref修饰符
在C#中,若按引用传递参数则应使用ref参数修饰符。下面例子中,p和x指向同一块内存位置:
static void Foo(ref int p)
{p = p + 1;Console.WriteLine(p);
}
int x = 8;
Foo(ref x);
Console.WriteLine(x);
现在给p赋新值将改变x的值。注意 ref 修饰符在声明和调用时都是必须的。
ref 修饰符对于实现交换方法是必要的。
static void Swap(ref string a,ref string b)
{string temp = a;a = b;b = temp;
}
string x = "Panny";
string y = "Teller";
Swap(ref x, ref y);
Console.WriteLine(x);//Teller
Console.WriteLine(y);//Panny
无论参数是引用类型还是值类型,都可以按引用传递或值传递。
2.9.4.3 out修饰符
out参数和ref参数类似,但在以下几点上不同:
1.不需要在传入函数前赋值。
2.必须在函数结束之前赋值。
out修饰符通常用于获得方法的多个返回值,例如:
static void Split(string name, out string firstNames,out string lastName)
{int i = name.LastIndexOf(' ');firstNames = name.Substring(0,i);lastName = name.Substring(i+1);
}
string a, b;
Split("Stevie Ray Vaughan",out a,out b);
Console.WriteLine(a);//Stevie Ray
Console.WriteLine(b);//Vaughan
与ref参数一样,out参数按引用传递。
2.9.4.4 out变量及丢弃变量
从C#7开始,允许调用含有 out 参数的方法时直接声明变量。因此我们可以将前面的例子简化为:
Split("Stevie Ray Vaughan",out string a,out string b);
Console.WriteLine(a);//Stevie Ray
Console.WriteLine(b);//Vaughan
当调用含有多个out参数方法时,若我们并非关注所有参数值,那么可以用下划线来”丢弃“不感兴趣的参数:
Split("Stevie Ray Vaughan",out string a,out _);
Console.WriteLine(a);//Stevie Ray
此时,编译器会将下划线认定为一个特殊的符号,称为丢弃符号。一次调用可以引入多个丢弃符号。假设SomeBigMethod定义了7个out参数,除第4个之外的其他全部被丢弃。
static void SomeBigMethod(out int a1, out int a2, out int a3, out int a4, out int a5, out int a6, out int a7)
{a1 = 1;a2 = 2;a3 = 3;a4 = 4;a5 = 5;a6 = 6;a7 = 7;
}
SomeBigMethod(out _, out _, out _, out int x, out _, out _, out _);
Console.WriteLine(x);//4
2.9.4.5 按引用传递的含义
按引用传递参数是为了现存变量的存储位置起了一个别名而不是创建了一个新的存储位置。下面的例子中,x和y代表相同的实例:
方法
static int x;
static void Yoo(out int y)
{Console.WriteLine(x);//0y = 1;Console.WriteLine(x);//1
}
调用
Yoo(out x);
2.9.4.6 params修饰符
params参数修饰符只能修饰方法中的最后一个参数,它能够使方法接受任意数量的指定类型参数。参数类型必须声明为数组。例如:
static int Sum(params int[] ints)
{int sum = 0;for(int i =0;i<ints.Length;i++){sum += ints[i];}return sum;
}
int total = Sum(1,2,3,4);
Console.WriteLine(total);//10
也可以将普通数组提供给params参数。和上例方法等价:
int total = Sum(new int[] { 1, 2, 3, 4 });
Console.WriteLine(total);//10
2.9.4.7 可选参数
从C#4.0开始,方法,构造器和索引器中都可以声明可选参数。只要在参数声明中提供默认值,这个参数就是可选参数:
static void Xoo(int x = 23)
{Console.WriteLine(23);
}
可选参数在调用方法时可以省略:
Xoo();
默认参数23实际上传递给了可选参数x,编译器在调用端将值23传递到编译好的代码中。上例中调用Xoo的代码语义上等价于:
Xoo(23);
这是由于编译器在用到可选参数的地方使用默认值代替可选参数而造成的。
若public方法对其他程序集可见,则在添加可选参数时双方均需要重新编译,就像参数是必须提供的一样。
2.9.4.8 命名参数
除了用位置确定参数外,还可以用名称来确定参数,例如:
static void Test()
{Foo(x: 1, y: 2);//1:2
}static void Foo(int x, int y)
{Console.WriteLine(x + ":" + y);
}
命名参数能够以任意顺序出现。下面两种调用Foo方式在语义上是一样的:
Foo(x: 1, y: 2);//1:2
Foo(y: 2, x: 1);//1:2
上述写法的不同之处是参数表达式将按调用端参数出现的顺序计算。通常,这种不同只出现在非独立的拥有副作用的表达式中。例如下面的代码将输出1:0:
static void Foo(int x, int y)
{Console.WriteLine(x + ":" + y);
}
int a = 0;
Foo(y: a++, x: a--);
命名参数和可选参数可以混合使用:
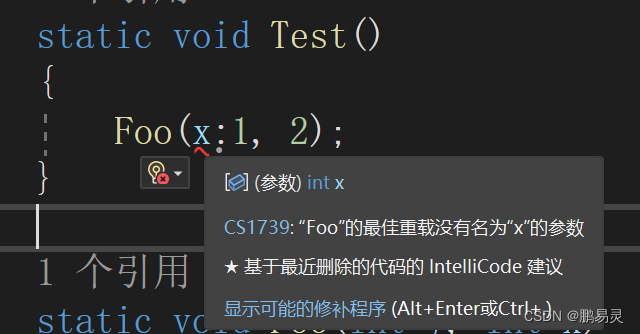
Foo(1, y: 2);
当然这里有一个限制,按位置传递的参数必须出现在命名参数之前。因此不能这样调用Foo方法:
static void Foo(int y, int x)
{Console.WriteLine(x + ":" + y);
}
编译错误
命名参数在和可选参数混合使用时特别有效。例:
void Bar(int a = 0, int b = 0, int c = 0, int d = 0){}
我们可以用以下方式在调用它的时候仅提供d的值:
Bar(d:3);
2.9.5 引用局部变量
C#7中添加了一个令人费解的特性:即定义了一个用于引用数组中某一个元素或对象中某一个字段的局部变量:
int[] numbers = { 0, 1, 2, 3, 4 };
ref int numRef = ref numbers[2];
numRef = 100;
Console.WriteLine(numbers[2]);//100
在这个例子中。numRef是numbers[2]的引用。当我们更改numRef的值时,也相应更改了数组中的元素值。
引用局部变量的目标只能是数组的元素,对象字段或者局部变量;而不能是属性。引用局部变量适用于在特定的场景下进行小范围优化,并通常和引用返回值合并使用。
2.9.6 引用返回值
从方法中返回的引用局部变量,称为引用返回值(ref return):
声明
static string X = "Old value";
static ref string GetX() => ref X;
调用
ref string xRef = ref GetX();
xRef = "New Value";
Console.WriteLine(X);//New Value
2.9.7 var引用类型局部变量
我们通常会在一步中完成变量的声明和初始化。如果编译器能够从初始化表达式中推断出变量的类型,就能够使用var关键字来代替类型声明,例如:
var x = "hello";
var y = new System.Text.StringBuilder();
var z = (float)Math.PI;
完全等价于:
string x = "hello";
System.Text.StringBuilder y = new System.Text.StringBuilder();
float z = (float)Math.PI;
因为完全等价,所以隐式类型变量仍是静态的。
编译报错
var x = 5;
x = "hello";//编译报错
必须使用var的情况(匿名类型);
2.10 表达式和运算符
表达式的本质是值。最简单的表达式是常量和变量。表达式能够用运算符进行转换和组合。运算符用一个或者多个输入操作数来输出一个新的表达式。
常量表达式例子:
12
可以用 * 运算符来组合两个操作数。
12*13
由于操作数本身可以是表达式,使用可以创建出更复杂的表达式。例如(12 * 13)是下面表达是中的操作数。
1 + (12 * 13)
C#中的运算符分为一元运算符、二元运算符和三元运算符,这取决于它们使用的操作数数量(1、2或3)。二元运算符总是使用中缀发表示,在两个操作数直间。
一元运算符
示例
a--,a++,++a,--a
二元运算符
示例
a+b,a-b,a*b,a/b,a%b,a&b,a^b,a|b
由于操作数本身可以是表达式,则如下为二元运算符
1 + (12 * 13)
三元运算符
示例
a+b-c,a+b*c.....
条件运算符也是三元运算符
a>b ? a:b,a<b ? a:b,
多元运算符
总之看操作数,或者条件运算符的嵌套层数,嵌套n层,则为n+3元运算符。
2.10.1 基础表达式
基础表达式由C#内置的基础运算符表达式组成,例如
Math.Log(1)
这个表达式由两个基础表达式构成,第一个表达式执行成员查找(用.运算符),而第二个表达式执行方法调用(用()运算符)。
2.10.2 空表达式
空表达式是没有值的表达式,例如:
Console.WriteLine(1);
2.10.3 赋值表达式
赋值表达式用 = 运算符将另一个表达式的值赋值给变量,例如:
x = x * 5;
赋值表达式不是一个空表达式,它的值即是被赋予的值。因此赋值表达式可以和其他表达式组合。下面例子中,将2赋给x并将10赋给y:
y = 5 * (x = 2);
这种类型也可以用于初始化多个值:
a = b = c = d = 0
复合赋值运算是由其他运算符组合而成的简化运算符。例如:
x *=2
x <<= 1
这条规则的例外是事件(event)。它的+=和-=运算符会特殊对待并映射至事件的add和remove访问器上。
2.10.4 运算符优先级和结合性
当表达式包含多个运算符时,运算符优先级和结合性决定了计算的顺序。优先级高的运算符先于优先级低的运算符执行。如果运算符的优先级相同,那么运算符的结合性决定计算的顺序。
2.10.4.1 优先级
以下表达式:
1 + 2 * 3
由于*的优先级高于+,因此它将按下面的方式计算:
1 + (2 * 3)
2.10.4.2 左结合运算符
二元运算符(除了赋值运算符、Lambda表达式、null合并运算符)是左结合运算符。换句话说,它们是从左往右计算。例如:
8 / 4 / 2
由于左结合性将按如下的方式计算
(8 / 4) / 2 //1
插入括号可以改变实际的计算顺序
8 / (4 / 2) //4
2.10.4.3 右结合运算符
除了赋值运算符、Lambda表达式、null合并运算符和条件运算符是右结合的。换句话说,它们是从右往左计算。右结合性允许多重赋值,例如:
x = y = 3;
首先将3赋值给y,之后再将表达式(3)的结果赋值给x.
2.10.5 运算符表
C#的运算符(按照优先级顺序分类)
| 类别 | 运算符符号 | 运算符名称 | 示例 | 是否可重载 |
|---|---|---|---|---|
| 基础 | . | 成员访问 | x.y | 否 |
| ->(不安全代码) | 结构体指针 | x->y | 否 | |
| ( ) | 函数调用 | x() | 否 | |
| [ ] | 数组/索引 | a[x] | 通过索引器 | |
| ++ | 后自增 | x++ | 是 | |
| - - | 后自减 | x- - | 是 | |
| new | 创建实例 | new Fo() | 否 | |
| stackalloc | 不安全的栈空间分配 | stackalloc(10) | 否 | |
| typeof | 从标识符中获得类型 | typeof(int) | 否 | |
| nameof | 从标识符中获取名称 | nameof(x) | 否 | |
| checked | 检测整数溢出 | checked(x) | 否 | |
| unchecked | 不检测整数溢出 | unchecked(x) | 否 | |
| default | 默认值 | default(char) | 否 | |
| await | 等待异步操作 | await myTask | 否 | |
| sizeof | 获得结构体大小 | sizeof(int) | 否 | |
| ?. | null条件运算符 | x?.y | 否 | |
| + | 正数 | +x | 是 | |
| - | 负数 | -x | 是 | |
| ! | 非 | !x | 是 | |
| ~ | 按位取反 | ~x | 是 | |
| ++ | 前自增 | ++x | 是 | |
| - - | 前自减 | - -x | 是 | |
| ( ) | 转换 | (int) x | 否 | |
| *(不安全代码) | 取地址中的值 | *x | 否 | |
| &(不安全代码) | 取值的地址 | &x | 否 | |
| 乘法 | * | 乘 | x * y | 是 |
| / | 除 | x / y | 是 | |
| % | 取余 | x % y | 是 | |
| 加法 | + | 加 | x + y | 是 |
| - | 减 | x - y | 是 | |
| 位移 | << | 左移 | x<<1 | 是 |
| >> | 右移 | x>>1 | 是 | |
| 关系 | < | 小于 | x < y | 是 |
| > | 大于 | x > y | 是 | |
| <= | 小于等于 | x <= y | 是 | |
| >= | 大于等于 | x >= y | 是 | |
| is | 类型是/是子类 | x is y | 否 | |
| as | 类型转换 | x as y | 否 | |
| == | 相等 | x == y | 是 | |
| != | 不相等 | x != y | 是 | |
| 逻辑与 | & | 与 | x & y | 是 |
| 逻辑异或 | ^ | 异或 | x ^ y | 是 |
| 逻辑或 | | | 或 | x | y | 是 |
| 条件与 | && | 条件与 | x && y | 通过& |
| 条件或 | || | 条件或 | x || y | 通过| |
| null合并 | ?? | null合并运算符 | x ?? y | 否 |
| 条件 | ?: | 条件运算符 | a>b ? a:b | 否 |
| 赋值与Lambda | = | 赋值 | x = y | 否 |
| *= | 自身乘 | x *= 2 | 通过* | |
| /= | 自身除 | x /= 2 | 通过/ | |
| += | 自身加 | x += 2 | 通过+ | |
| -= | 自身减 | x -= 2 | 通过- | |
| <<= | 自身左移 | x <<= 2 | 通过<< | |
| >>= | 自身右移 | x >>= 2 | 通过>> | |
| &= | 自身与 | x &= 2 | 通过& | |
| ^= | 自身异或 | x ^= 2 | 通过^ | |
| |= | 自身或 | x |= 2 | 通过 | | |
| => | Lambda | x => x+ 1 | 否 |
2.11 null运算符
C#提供了两个简化null处理的运算符:null合并运算符和null条件运算符。
2.11.1 null合并运算符
null合并运算符写作??。它的意思是如果操作数不是null则结果为操作数,否则结果为一个默认的值。例如:
string s1 = null;
string s2 = s1 ?? "nothing";
Console.WriteLine(s2);//nothing
如果左侧的表达式不是null,则右侧的表达式将不会进行计算。null合并运算符同样适用于可空的值类型。
2.11.2 null条件运算符
C#6中引入了"?."运算符,称为null条件运算符或者Elvis运算符。该运算符可以像标准的“.”运算符那样访问成员以及调用方法。当运算符的左侧为null的时候,该表达式的运算结果也是null而不会抛出 NullReferenveException 异常。
StringBuilder sb = null;
string s = sb?.ToString();
Console.WriteLine(s);//
上述代码的第二行等价于
string s = (sb == null ? null : sb.ToString());
当遇到null时,Elvis运算符将直接略过表达式的其余部分。在接下来的例子中,即使ToString()和ToUpper()方法使用的是标准的.运算符,s的值仍然为null。
StringBuilder sb = null;
string s = sb?.ToString().ToUpper();
仅当直接的左侧运算数有可能为null的时候才有必要重复使用Elvis运算符。因此下述表达式在x和y都为null时依然是健壮的:
x?y?.z
它等价于(唯一不同在于x.y只执行了一次):
x == null ? null : (x.y == null ? null : x.y.x)
需要注意,最终的表达式必须能够处理null,因此下面的范例是不合法的:
StringBuilder sb = null;
int length = sb?.ToString().Length;//int cannot be null
我们可以使用可空类型来修正这个错误:
StringBuilder sb = null;
int? length = sb?.ToString().Length;//int? can be null
我们也可以使用null运算符调用返回值为void的方法
someObject?.SomeVoidMethod();
如果someObject为null,则表达式将不执行指令而不会抛出 NullReferenceException 异常
null条件运算符可以和第3章介绍的常用类型成员一起使用,包括方法、字段、属性和索引器。而且它也可以和null合并运算符一起使用。
StringBuilder sb = null;
string s = sb?.ToString() ?? "nothing";
Console.WriteLine(s);//nothing
2.12 语句
函数是语句构成的。语句按照出现的字面量顺序执行。语句块则是在大括号({})中的一系列语句。
2.12.1 声明语句
声明语句可以声明新的变量,并可以用表达式初始化变量。声明语句以分号结束。可以用逗号分隔的列表声明多个同类型的变量。例如:
bool rich = true, famous = false;
常量的声明和变量类似,但是它的值无法在声明之后改变,并且变量初始化必须和声明同时进行:
const double c = 2.12314;
c += 10;//编译时报错
局部变量
局部变量和常量的作用范围在当前语句块中。当前语句块或者嵌套的语句块中声明一个同名的局部变量是不行的,例如:
int x;
{int y;int x;//报错x,x已经定义
}
{int y;
}
Console.WriteLine(y);//报错,y在范围外
变量的作用范围是它所在的整个代码块(向前向后都包含)。这意味着虽然变量或常量声明之前引用它是不合法的,但即使实例中的x初始化移动的 方法的末尾我们也会得到相同的错误,这个规则与c++不同。
2.12.2 表达式语句
表达式语句既是表达式也是合法的语句。表达式语句必须改变状态或者执行某些可能改变状态的调用。状态改变本质上是改变一个变量的值。可能的表达式语句有:
1.赋值表达式(包括自增和自减表达式0)
2.(有返回值和没有返回值)方法调用表达式
3.对象实例化表达式
string s;
int x, y;
StringBuilder sb;//Expreddion statements
x = 1 + 2; //Assignment expression
x++; //Increnment expression
y = Math.Max(x, 5); //Assignment expression
Console.WriteLine(y); //Method call expression
sb = new StringBuilder();//Assignment expression
new StringBuilder(); //Object instantiation expression
当调用有返回值的构造器或方法时,并不一定要使用它的返回值。因此除非构造器或方法改变了某些状态,否则以下这些语句完全没有用处:
new StringBuilder();
new string('c', 3);
x.Equals(y);
2.12.3 选择语句
C#使用以下几种机制来有效的控制程序的执行流:
1.选择语句(if、switch)
2.条件语句(?:)
3.循环语句(while、do…while、for和foreach)
2.12.3.1 if语句
if 语句在bool表达式为真时执行的语句。例如:
if(5 < 2 * 3)Console.WriteLine("true");
if 语句可以时代码块:
if(5 < 2 * 3)
{Console.WriteLine("true");Console.WriteLine("let's move on");
}
2.12.3.2 if语句
if语句之后可以紧跟else子句:
if (2 + 2 == 5)Console.WriteLine("Does not compute");
elseConsole.WriteLine("False");
在else语句中,能嵌套另一个if语句:
if (2 + 2 == 5)Console.WriteLine("Does not compute");
else if(2 + 2 == 4)Console.WriteLine("compute");
2.12.3.3 用大括号改变执行流
else子句总是与它之前的语句块中紧邻的未配对的if语句结合。例如
if (true)if (false)Console.WriteLine();elseConsole.WriteLine("executes");
可以通过改变大括号的位置来改变执行流:
if (true)
{if (false)Console.WriteLine();
}
elseConsole.WriteLine("does not executes");
大括号可以明确表示结构,这能提高嵌套if的可读性。需要特别指出的是下面模式:
static void TellChatMethod(int age)
{if (age >= 35)Console.WriteLine("You can be persident!");else if (age >= 21)Console.WriteLine("You can drink!");else if (age >= 18)Console.WriteLine("You can vote");elseConsole.WriteLine("You can wait!");
}
这里参照其他语言的elseif结构(以及C#的预处理指令)来安排if和else语句。Visual Studio 自动识别这个模式并保持代码缩进。紧跟着每一个if语句的else语句从功能上都是嵌套在else子句中的。
2.12.3.4 switch语句
switch语句可以根据变量可能的取值来转移程序的执行。switch语句可以拥有比嵌套if语句更加简洁的代码。例如:
static void ShowCard(int carNumber)
{switch (carNumber){case 0:Console.WriteLine("King");break;case 1:Console.WriteLine("Queen");break;case 2:Console.WriteLine("Jack");break;case -1:goto case 2;default: Console.WriteLine(carNumber); break;}
}
这个例子演示了针对常量的 switch 。当指定常量时,只能指定内置的整数类型、bool、char、enum、string类型。
每一个case子句结束时必须使用某种跳转指令显式指定下一个执行点(除非你的代码是一个无限循环)。这些跳转指令有:
1.break(跳转到switch语句的最后)
2.goto case x(跳转到另外一个case子句)
3.goto default(跳转到default子句)
4.其他跳转语句,return、throw、continue、goto label
当多个值要执行相同的代码时,可以按照顺序列出共同的case条件:
switch (cardNumber)
{case 0:case 1:case 2:Console.WriteLine("a card");break;case -1:goto case 2;default:Console.WriteLine("card");break;
}
switch语句比多个if-else更简洁
2.12.3.5 带有模式的switch语句
C#7 开始支持按类型switch:
static void TellMeTheType(object x)
{switch (x){case int:Console.WriteLine("It's an int!");break;case string s:Console.WriteLine("It's a string");break;default:Console.WriteLine("I don't know what x is");break;}
}
object 类型允许其变量未任何类型。
每一个case子句都指定了一种需要匹配的类型和一个变量,如果类型匹配成功就对变量赋值。和常量不同,对于类型的使用并没有任何限制。
还可以用when关键字对case进行预测,例如:
static void TheType(object x)
{switch (x){case bool b when b == true:Console.WriteLine("True!");break;case bool b:Console.WriteLine("False!");break;}
}
case子句的顺序会影响类型的选择。如果交换case的顺序,则上述示例可以得到完全不同的结果。但default子句是一个例外,不论它出现在什么地方都会在最后执行。
堆叠多个case子句也是没有问题的。Console.WriteLine会在任何浮点类型的值大于1000时执行:
static void ValueType(object x)
{switch (x){case float f when f > 1000:case double d when d > 1000:case decimal m when m > 1000:Console.WriteLine("We can refer to x here but bot");break;}
}
when 子句中使用模式变量 f,g和m。当调用 Console.WriteLine 时,我们并不清楚到底三个模式变量中的哪一个会被赋值,因而编译器会将它们放在作用域之外。
除此之外,还可以混合使用常量选择和模式选择,甚至可以选择 null 值:
case null:break;
2.12.4 迭代语句
C#中可以使用while、do while、for、和foreach语句重复执行一系列语句。
2.12.4.1 while和do-while循环
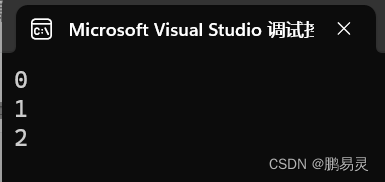
while循在其bool表达式为true的情况下重复执行循环体中的代码。这个表达式在循环体执行之前进行检测。例如:
int i = 0;
while(i < 3)
{Console.WriteLine(i);i++;
}
do-while 循环在功能上不同于while循环的地方是它在语句块执行之后才检查表达式的值(保证语句块至少执行过一次)。以下例子重新用do-while循环重新书写了一遍:
int i = 0;
do
{Console.WriteLine(i);i++;
}
while (i < 3);
2.12.4.2 for循环
for循环就像有特殊子句的while循环。这些特殊子句用于初始化和迭代循环变量。for循环有三个子句:
for(initiation-clause;condition-clause;iteration-clause)
statement-or-statement-block
1.初始化子句:在循环之前执行,初始化一个或多个迭代变量。
2.条件子句:它是一个bool表达式,当其为true时,将执行循环体。
3.迭代子句:在每次语句块迭代之后执行,通常用于更新迭代变量。
例如,下面例子将打印 0-2:
for (int i = 0; i < 3; i++)
{Console.WriteLine(i);
}
下面的代码将打印前10个斐波那契数(每一个数都是前面两个数和):
for (int i = 0,prevFib = 1,curFib = 1; i < 10; i++)
{Console.WriteLine(prevFib);int newFib = prevFib + curFib;prevFib = curFib;curFib = newFib;
}
for语句的这三个部分都可以省略,因而可以通过下面的代码来实现无限循环(也可以用while(true)来代替)
for(;;)Console.WriteLine("Log");
2.12.4.3 foreach循环
foreach语句遍历可枚举对象的每一个元素。大多数C#和.NET Framework中表示集合或元素列表的类型都是可枚举的。例如,数组和字符串都是可枚举的。例:
foreach(char c in "beer")Console.WriteLine(c);
2.12.5 跳转语句
C#中的跳转语句有break、continue、goto、return和throw。
跳转语句仍然遵守try语句的可靠性规则。这意味着:
1.到try语句块之外的跳转总是在达到目标之前执行try语句的finally语句块。
2.跳转语句不能从finally语句块跳到快外(除非使用throw)。
2.12.5.1 break语句
break 语句用于结束迭代或switch语句的执行:
int x = 0;
while (true)
{if (x++ > 5)break;
}
2.12.5.2 continue语句
continue语句放弃循环体中其后的语句,继续下一轮迭代。例如,以下循环跳过了偶数:
for (int i = 0; i < 10; i++)
{if (i % 2 == 0)continue;Console.Write(i + " ");
}
2.12.5.3 goto语句
goto语句将执行点转移到语句块的指定标签处。格式如下:
goto statement-label;
或者用于switch语句内:
goto case case-constant;
标签语句仅仅是代码块中的占位符,位于语句之前,用冒号后缀表示。下面的代码模拟for循环来遍历从1到5的数子:
int i = 1;
startLoop:
if(i <= 5)
{Console.Write(i + " ");i++;goto startLoop;
}
goto case case-constant 会将执行点转移到switch语句块的另一个条件上。
2.12.5.4 return语句
return语句用于退出方法。如果这个方法有放回值,则必须返回方法指定返回类型的表达式。
static decimal AsPercentage(decimal d)
{decimal p = d * 100m;return p;
}
return 语句能够出现在方法的任意位置(除finally块中)。
2.12.5.5 throw语句
throw语句抛出异常来表示有错误发生:
Person p = null;
if (p == null)throw new ArgumentNullException("P 未实例化");
2.12.6 其他语句
using 语句用一种优雅的语法在finally块中调用实现了 IDisposable 接口对象的 Dispose方法。
C#重载了using关键字,使它在不同上下文有不同的含义。特别注意using指令和using语句是不同的;
lock语句是调用mintor类型的Enter和Exit方法的简化写法。
2.13 命名空间
命名空间是一系列类型名称的领域。通常情况下,类型组织在分层的命名空间里,既避免了命名冲突又更容易查找。例如处理公钥加密的RSA类型就定义在如下的命名空间下:
System.Security.Cryptography.RSA
命名空间组成了类型名的基本部分。例下面代码调用了RSA类型的Create方法:
System.Security.Cryptography.RSA rsa = System.Security.Cryptography.RSA.Create();
拓展:
string s = "123小明是木头";
byte[] data = Encoding.UTF8.GetBytes(s);
Console.WriteLine("初始字节:");
for (int i = 0; i < data.Length; i++)
{Console.Write(data[i] + " ");
}
Console.WriteLine();
System.Security.Cryptography.RSA rsa = System.Security.Cryptography.RSA.Create();
byte[] rasEncryptData = rsa.Encrypt(data, RSAEncryptionPadding.OaepSHA256);Console.WriteLine("rasEncryptData:"+ rasEncryptData.Length);
for (int i = 0; i < rasEncryptData.Length; i++)
{Console.Write(rasEncryptData[i] + " ");
}byte[] rawData = rsa.Decrypt(rasEncryptData, RSAEncryptionPadding.OaepSHA256);
Console.WriteLine("rawData:" + rawData.Length);
for (int i = 0; i < rawData.Length; i++)
{Console.Write(rawData[i] + " ");
}
Console.WriteLine();
string rawStr = Encoding.UTF8.GetString(rawData);
Console.WriteLine("原来的值为:" + rawStr);
命名空间是独立于程序集的,程序集是像.exe或者.dll一样的部署单元。命名空间并不影响成员的public、internal、private的可见性。
namespace 关键字为其中定义了命名空间。例如,
namespace In.Middle.Inner
{class Class1 { }class Class2 { }
}
命名中的“.”表明了嵌套命名空间的层次结构。下面的代码在语义上和上一个例子是等价的:
namespace In
{namespace Middle{namespace Inner{class Class1 { }class Class2 { }}}
}
如果类型没有在任何命名空间中定义,则它存在于全局命名空间中。全局命名空间也包含了顶级命名空间,如例子中的 In 命名空间。
2.13.1 using指令
using指令用于导入命名空间。这是避免使用完全限定名称来指代某种类型的快捷方法。例如:
using In.Middle.Inner;
public class Test1
{static void Main() {Class1 c1;}
}
在不同命名空间中定义相同类型名称是合法的。然而,这种做法通常出现在开发者不会同时导入两个命名空间时。
2.13.2 using static指令
从C#6开始,我们不仅可以导入命名空间还可以使用 using static 指令导入特定的类型。这样就可以直接使用类型的静态成员而不需要指定类型名称了。调用 Console 类的静态方法WriteLine:
using static System.Console;
public class Test
{static void Main() {WriteLine("hello");}
}
using static 指令将类型的可访问的静态成员,包括字段、方法、属性以及嵌套类型,全部导入进来。同时,该指令也支持导入枚举类型的成员。因此如果导入枚举类型后,可能会出现相同的枚举的情况,多个静态类型导致二义性时会发生编译错误。
2.13.3 命名空间中的规则
2.13.3.1 名称范围
外层命名空间中声明的名称能够直接在内层命名空间中使用。以下示例中的Class1在Inner中不需要限定名称:
namespace Outer
{class Class1 { }namespace Inner {class Class2 : Class1{ }}
}
使用同一命名分层结构中不同分支的类型需要使用部分限定名称。在下面的例子中,SalesReport类继承Common.ReportBase:
namespace Common
{class ReportBase{}namespace ManagementReporting{class SalesReport : Common.ReportBase { }}
}
2.13.3.2 名称隐藏
如果相同名称同时出现在内层和外层的命名空间中,则内层类型优先。如果要使用外层命名空间中的类型,必须使用它的完全限定名称。
namespace Outer
{class Foo { }namespace Inner {class Foo { }class Test{Foo f1;//Outer.Inner.FooOuter.Foo f2;//Outer.Foo}}
}
所有的类型名在编译时都会转换为完全限定名称。中间语言(IL)代码不包含非限定名称和部分限定名称。
2.13.3.3 重复的命名空间
只要命名空间内的类型名称不冲突就可以重复声明同一个命名空间:
namespace In.Middle.Inner
{class Class1 { }
}namespace In.Middle.Inner
{class Class2 { }
}
上述例子也可以分为两个不同的源文件,并将每一个类都编译到不同的程序集中。
源文件1:
namespace In.Middle.Inner
{class Class1 { }
}
源文件2:
namespace In.Middle.Inner
{class Class2 { }
}
2.13.3.4 嵌套的using指令
我们能够在命名空间中嵌套使用using指令,这样可以控制using指令在命名空间声明中的作用范围。在以下例子中,Class1在一个命名空间中可见,但是在另一个命名空间中不可见:
namespace N1
{class Class1 { }
}
namespace N2
{using N1;class Class2 : Class1 { }
}namespace N2
{class Class3 : Class1 { }//Compile-time error
}
2.13.4 类型和命名空间别名
导入命名空间可能导致类型名称的冲突,因此可以只导入需要的特定类型而不是整个命名空间,并给它们创建别名。例如:
using PropertyInfo2 = System.Reflection.PropertyInfo;
class Program
{PropertyInfo2 p;
}
下面代码为整个命名空间创建别名:
using R = System.Reflection;
class Program2
{R.PropertyInfo p;
}
2.13.5 高级命名空间
2.13.5.1 外部别名
使用外部别名就可以引用两个完全限定的名称相同的类型(例如,命名空间和类型名称都相同)。这种情况只在两种类型来自不同的程序集时才会出现。
程序库1:
// csc target:library / out:Widgets1.dll widgetsv1.cs
namespace widgets
{public class Widget{}
}
程序库2:
// csc target:library / out:Widgets2.dll widgetsv2.cs
namespace widgets
{public class Widget{}
}
应用程序:
// csc r:Widgets1.dll / r:Widgets2.dll application.cs
using widgets;
class Test
{static void Main{Widget w = new Widget();}
}
这个应用程序无法编译,因为Widget类型具有二义性。外部别名可以消除应用程序中的二义性:
// csc r:Widgets1.dll / r:Widgets2.dll application.cs
extern alias W1;
extern alias W2;
class Test
{static void Main{Widget w = new Widget();Widget w = new Widget();}
}
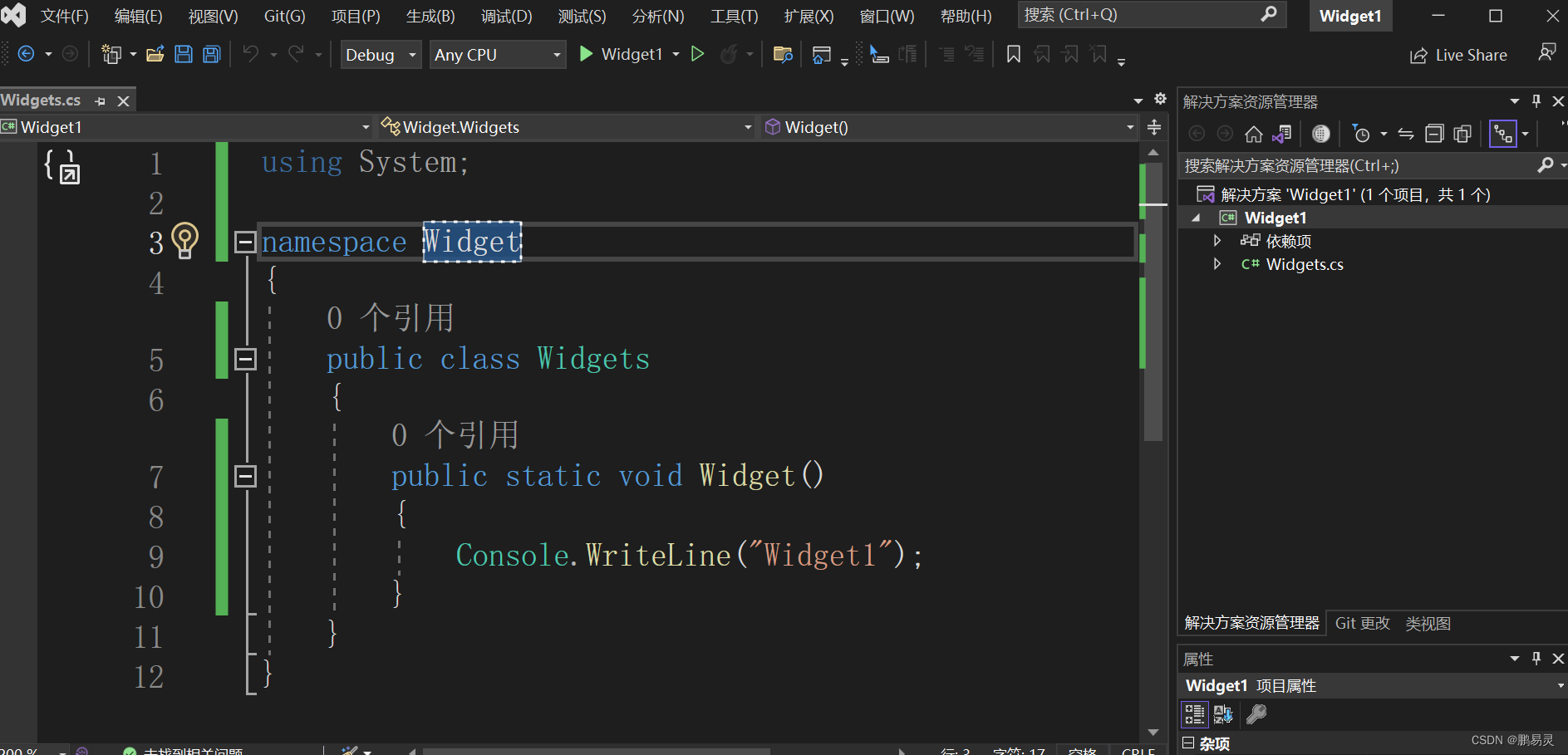
补:
1.首先新建两个类库Widget1,Widget2
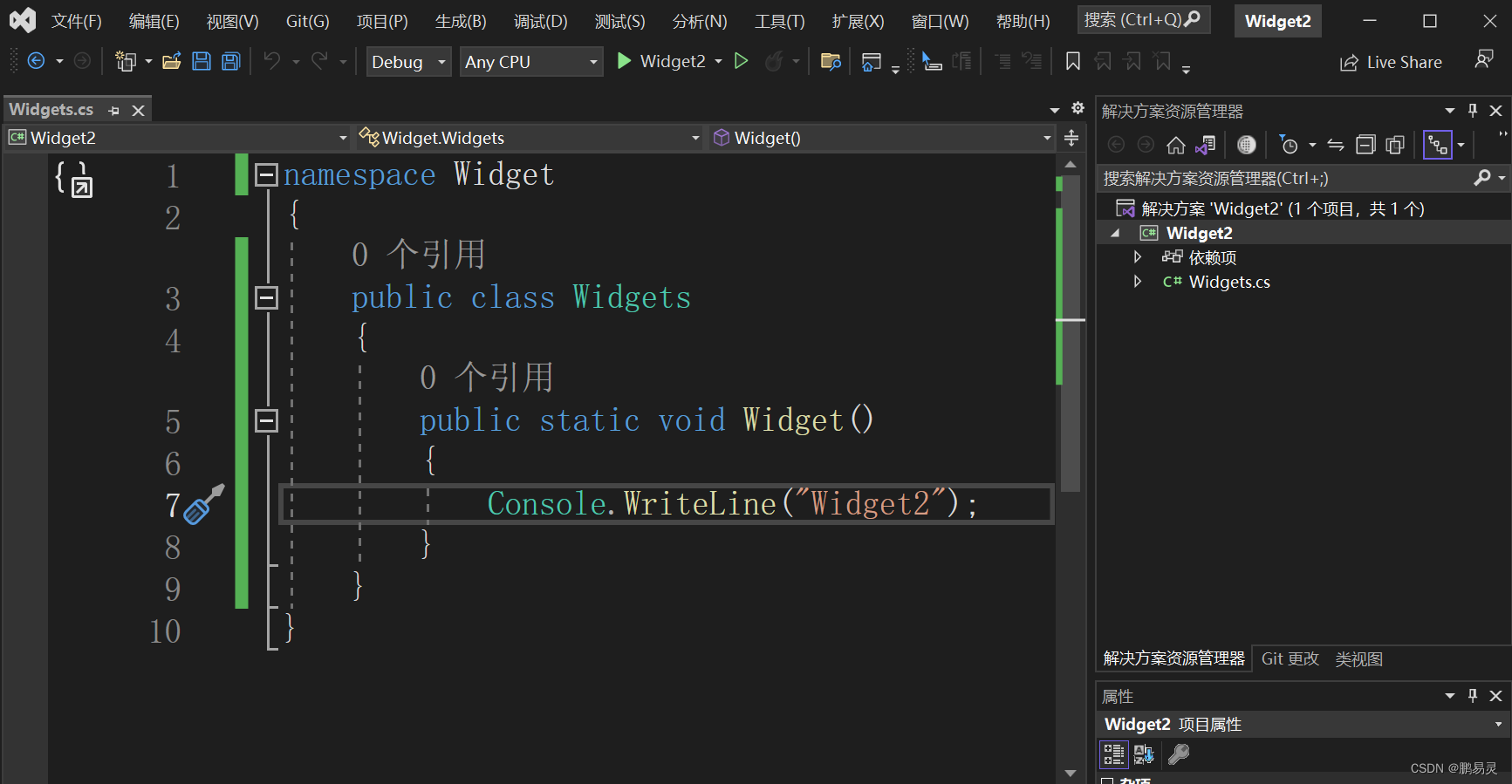
2.项目引入
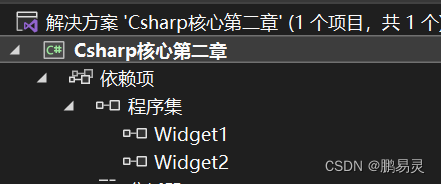
3.更改别名(以W1为例)
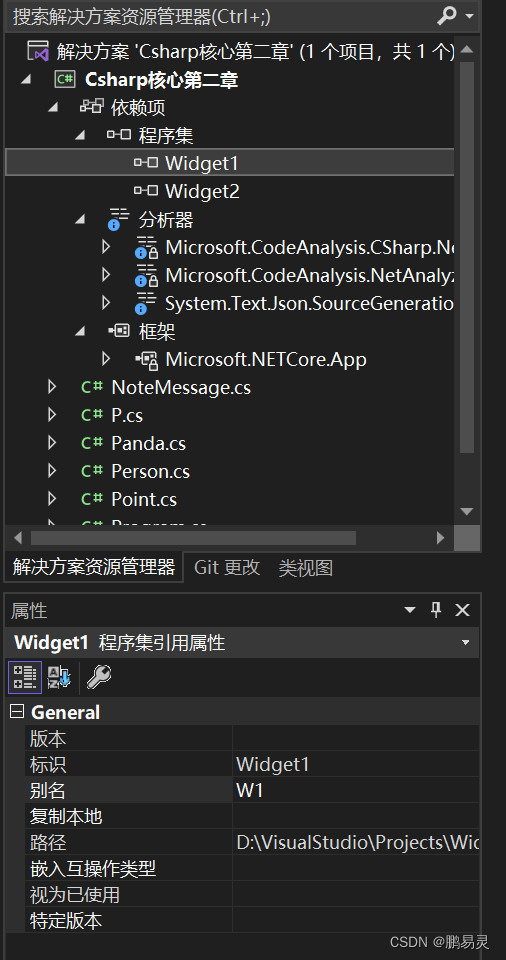
4.上代码
extern alias W1;
extern alias W2;
W1.Widget.Widgets.Widget();//Widget1
W2.Widget.Widgets.Widget();//Widget2
2.13.5.2 命名空间别名限定符
之前提到的,内层命名空间中的名称隐藏外层命名空间中的名称。但是,有时即使使用类型的完全限定名也无法解决冲突。请考虑下面的例子:
namespace N
{class A{public class B{}static void main(){new A.B();}}
}namespace A
{class B{}
}
Main方法会实例化嵌套类B或命名空间A中的类B。编译器总是给当前命名空间中的标识符以更高的优先级;在这种情况下,将会实例化嵌套类B。
要解决这样的冲突,可以使用如下的发式限定命名空间的名称:
1.全局命名空间,即所有命名空间的根命名空间(由上下文关键字global指定)
2.一系列外部别名
“ :: ”用于限定命名空间别名。下面的例子中,我们使用了全局命名空间(这通常出现在自动生成的代码中,以避免冲突)
新建一个A.cs文件,代码如下:
namespace N
{public class A{public class B{public B(){Console.WriteLine("N.A.B");}}public static void main(){new A.B();new global::A.B();}}
}namespace A
{public class B {public B(){Console.WriteLine("A.B");}}
}
main方法调用:
N.A.main();
以下例子使用了别名限定符:
extern alias W1;
extern alias W2;
W1::Widget.Widgets.Widget();//Widget1
W2::Widget.Widgets.Widget();//Widget2
上一篇: C#核心笔记——(一)C#和.NET Framework