导读
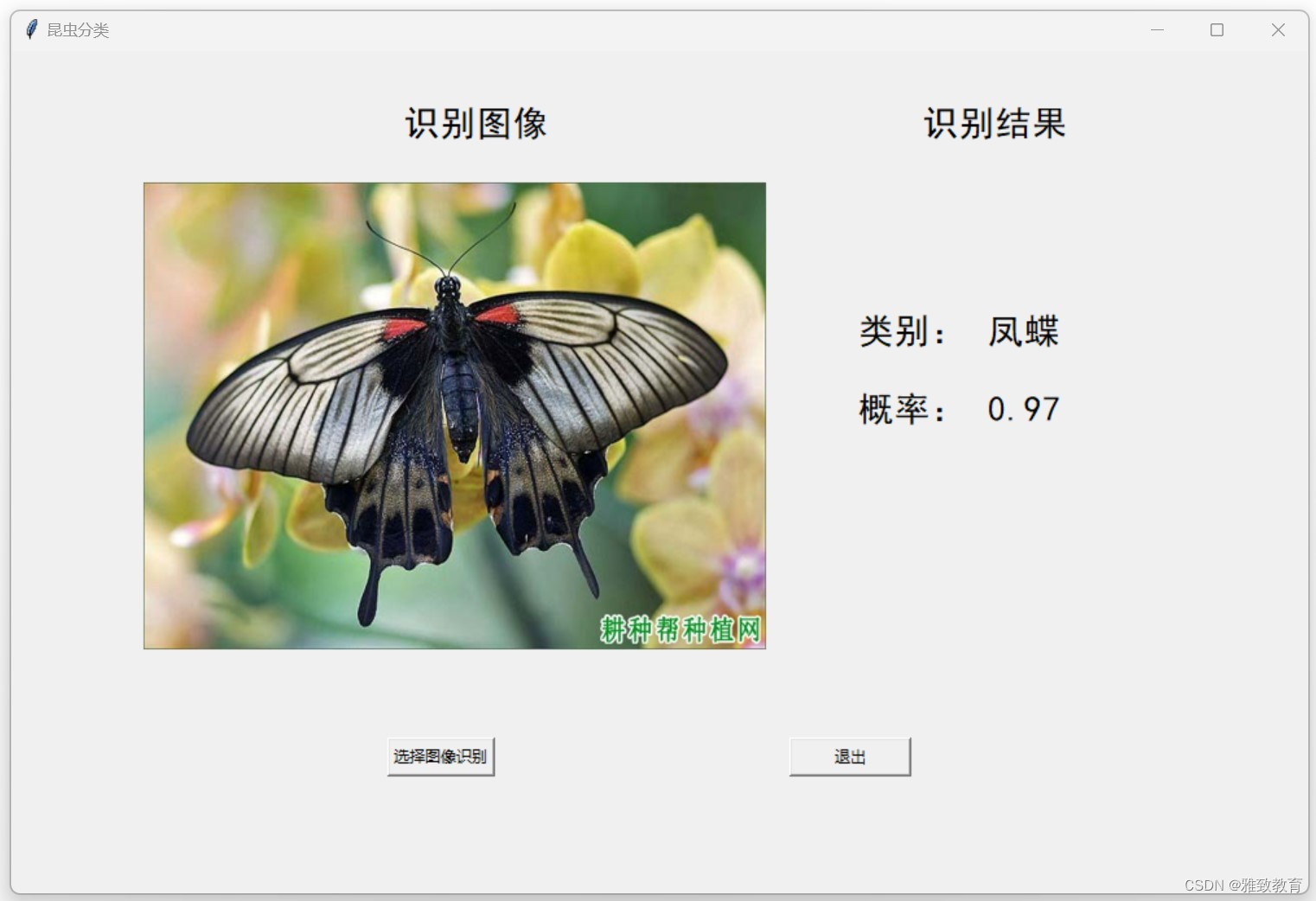
11月3日,智源研究院学术顾问委员会委员、机器学习泰斗Michael Jordan在以“新一代人工智能前沿”为主题的2023北京论坛 · 新工科专题论坛上,发表了题为Contracts, Uncertainty, and Incentives in Decentralized Machine Learning(去中心化机器学习中的契约、不确定性和激励)的主旨报告,该报告从统计学、经济学和博弈论等独特视角阐释了如何应对机器学习中的不确定性。

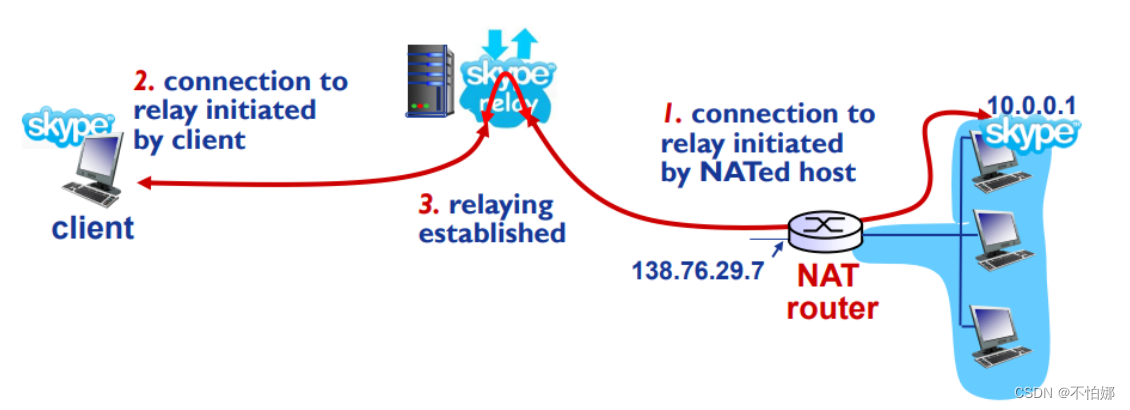
Michael I. Jordan
Michael I. Jordan是美国科学院、美国工程院、美国艺术与科学院三院院士,AI领域唯一一位获此成就的科学家,多个重要学术组织(AAAS、AAAI、ACM、ASA、CSS、IEEE、IMS、ISBA、SIAM)的会士。Michael I. Jordan教授现执教于加州大学伯克利分校,担任电机工程与计算机系和统计学系教授、实时智能决策计算平台实验室(RISELab)共同主任、统计人工智能实验室(SAIL)主任、统计系系主任。2016年,Jordan教授被Semantic Scholar评为计算机科学领域最具影响力学者,曾获2021年格林纳德随机理论与建模奖、IJCAI研究卓越奖(IJCAI Research Excellence Award)(2016)、David E.Rumelhart奖(2015),以及ACM/AAAI的Allen Newell奖(2009)等重要奖项。
要点速览
◆ 最好不要在个体层面上思考人工智能,而是在集体层面上思考它们。
◆ 我想讨论集体系统的设计目标,集体可以是人类和计算机的集合。
◆ 我可以通过超大规模的机器学习系统实现比以往好得多的效果。这绝对是进步,但它必须被纳入整个科学问题的范围内。如果用朴素的方式来做,可能会导致很大的错误。
◆ AI并不是我们现在所拥有,并试图监管的某种秘密的超级智能,而是一个新的工程领域,使我们能够以新的方式思考并构建有助于人类的新型系统。
当我看待人工智能时,我倾向于认为它尚处于未完待续的状态,只是刚刚开始。英语中有个表达,杯子是半满还是半空(编者按:“Is the glass half empty or half full?”用于表达悲观主义者及乐观主义者面对同一件事时,会有不同的看法——根据传统观点,乐观主义者会看到“杯子是半满”,悲观主义者则会看到“杯子是半空”。部分人会以这一问题测试别人的世界观。)对我来说,杯子总是半空的。我希望将它填补完整。那么机器学习中缺少什么呢?人工智能中又缺少什么呢?我认为缺少很多东西。所以我要谈谈该领域研究中所欠缺的经济方面问题。
经济学和统计学一样,是一门要考虑不确定性的科学。我们当前的人工智能和机器学习技术在不确定性方面表现不佳。大家都知道 ChatGPT,它确实很神奇,但它不太擅长处理不确定性,比如说它不知道世界上正在发生什么。或者它可能会说它不知道,但它并不真正知道“它不知道”。
它无法定量评估对自己知识的匮乏程度。它不知道怎么说我想和你合作,因为你比我懂得多。它不知道如何成为事物集体的一部分。由于没有经过充分的训练,它不知道如何收集新数据。它不知道它是否已被损坏......有很多很多它不知道的事情。
虽然人类并不完美,但我们一直在应对大量的不确定性。这是人类特别擅长的。所以说,谈及人类智能,但却没有一个好的关于不确定性的模型,对我来说,那只杯子只满了一半。所以问题的重点在于不确定性。现在,不确定性不仅仅是噪声,随着我们测量的东西越来越多,不确定性就会消失。这是工程学中思考问题的一种经典方式。
不确定性是指你知道一些我不知道的事情,而你却不愿意告诉我(出于隐私、竞争等原因)。我们不公开分享所有知识的原因有很多,经济学家将此称为信息不对称。
我们最好不要在个体层面上思考人工智能,而最好在集体的层面上思考它们。我们需要通过一种社会化的方式来思考人工智能。仅仅将人类的智慧融入超级智能计算机中,并不能解决我们的问题。计算机需要能够在我们的世界中行动并识别出我们是智能体。我们有欲望。不是每个人都能完全拥有自己想要的东西。它必须能够在我们的世界中发挥作用。我们在人工智能领域对此思考得还不够。
因此我想讨论集体系统的设计目标,集体可以是人类和计算机的集合。人类可以在「不确定性」和「协作」这两件事上人类都做得很好。人类教育的目的正是削减不确定性。那么,我们如何激励利己主义的AI智能体做一些事情,比如贡献数据来帮助测试假设,并将其作为具有协作性的行为来完成,然后创造经济价值?
对我来说,相较于大型数据集和大型语言模型和预测,这是更大的技术问题。
从 AlphaFold 看机器学习系统的不确定性
我在UC Berkley的四位优秀学生一直在与我一起从事这个项目,该项目称为“预测驱动的推理”(Prediction Powered Inference)。两年前,AlphaFold 是大家讨论的焦点。现在,大语言模型则站在了风口浪尖。它们都是非常大的机器学习系统,由大量工程师花费大量资金构建而成。 AlphaFold 可以预测蛋白质的结构。

我可以通过超大规模的机器学习系统实现比以往好得多的效果。这绝对是进步,但它必须被纳入整个科学问题的范围内。如果用朴素的方式来做,可能会导致很大的错误。
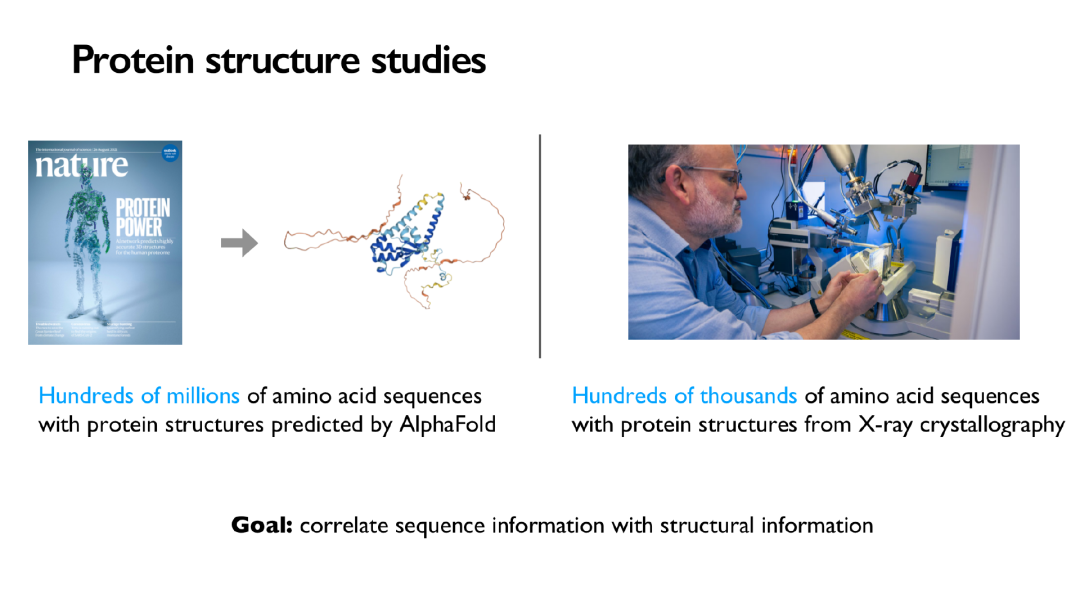
例如,蛋白质会折叠,形成结构或进行酶促反应。目前,存在数十万个已知结构的氨基酸序列。几十万看似很多,但对医学和生物学来说却是很小的数字。了解它们的功能十分重要。
这个数字一直在增长。20年前,有10,000种结构的蛋白质,而现在有10万了,它仍在增长。另一方面,AlphaFold 将产生数亿个这样的预测,而且它们非常准确。似乎,我们可以只获取 AlphaFold 的结果并使用 AlphaFold 进行科学研究,而不是使用实际的蛋白质进行科学研究。
事实上,这就是最近发生的事情,这是2004年生物学领域的一篇著名论文,这些作者正在研究蛋白质内在紊乱在生物学上具有重要意义的可能性。
这意味着什么?蛋白质会折叠。当它折叠时,它会在细胞中进行酶促反应等等。但有时蛋白质不会完全折叠。它可能有一根像这样垂下来的「细线」。过去人们认为这只是一种不完美的蛋白质。但事实证明,首先,它的发生是有原因的,某种量子涨落使其不会被折叠。
但事实证明,如果你有许多蛋白质,这些蛋白质带有「细线」,你就可以开始将它们放在一起,形成像这样的小图案,并将它们放入膜中,它们可以调节进出细胞的物质。
事实上,它看起来对生物学来说非常重要。去年在上海颁发的 WLA 生物学奖得主就是从事这一工作的。研究者认为应该测试这个假设,即内在紊乱是否与蛋白质活性相关(磷酸化)。
为了检验一个假设,我们要收集尽可能多的数据,并进行统计。在这种情况下,统计数据称为比值比,即内在紊乱的比例,活跃比上不活跃。如果该数字为 1,则不存在关联。如果该数字大于 1,则存在关联。
这些人利用 2004 年所有可用的数据完成了这项工作。即 10,000 个蛋白质结构。他们为比值比制定了一个置信区间,这个包含「1」的置信区间很大。我们必须等待更多数据,于是20 年后,现在有 100,000 个数据点。但研究者决定开始让AlphaFold 为我们提供数据,于是他们使用 2 亿个 AlphaFold 序列作为数据。
AlphaFold 是一个非常准确的系统,它可以很好地预测蛋白质结构。为什么不直接使用它作为数据呢?研究人员使用这个比值比进行了假设检验。
我认为这很可能是一件坏事。这种事一直如此,只是最近《自然》、《科学》和《Plos Biology》等杂志上的一些文章,比如电力供应、贫困预测、基因调控 DNA,出现完全相同的情况。他们采用机器学习模型来产生非常好的预测,一个生成式的人工智能系统,并将其用作数据,然后测试假设。

如下图所示,这是 AlphaFold 预测会折叠的蛋白质的实例,它存在内在的紊乱,真正的蛋白质不会是这样。AlphaFold 总体上是准确的,但在某些小子集中可能会出现糟糕的结果。
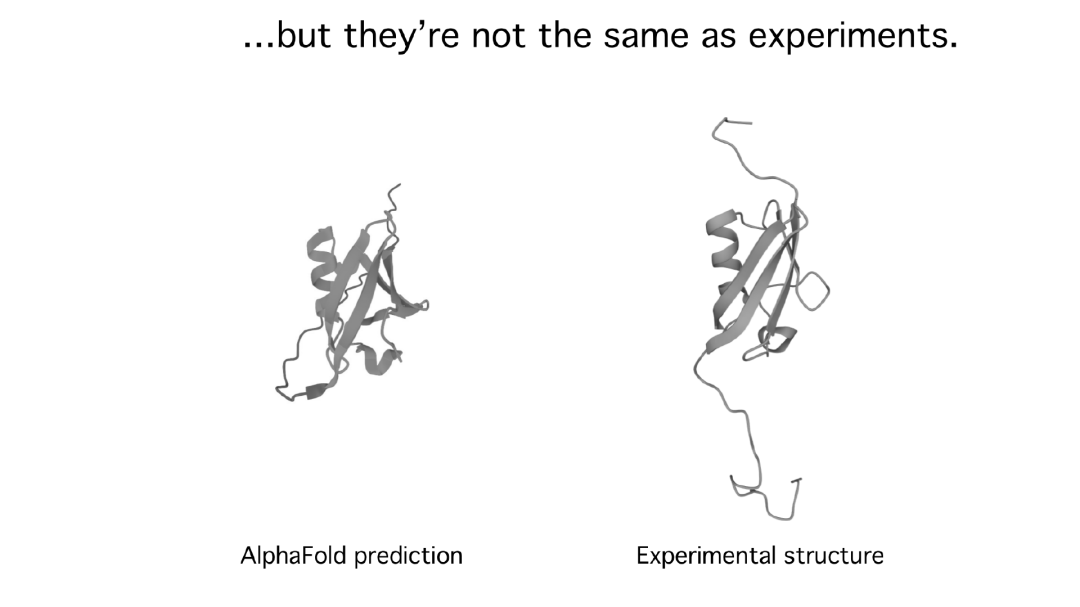
特别是,科学家很少对他们过去研究过的所有东西感兴趣。有一些前沿知识是 AlphaFold 从未见过的新事物,这些新事物正是 AlphaFold可能不擅长的。在无法判断先验知识对错时,只是运行 AlphaFold 并得到结果。
于是我们重新进行了所有这些实验。如下图所示,x 轴表示比值比,根据统计数据,如果结果是1,则没有关联。如果大于1,则存在关联。这些数据往往含有噪声,我们在统计数据上设置了置信区间,黄色区域指的是使用 AlphaFold 的置信区间。
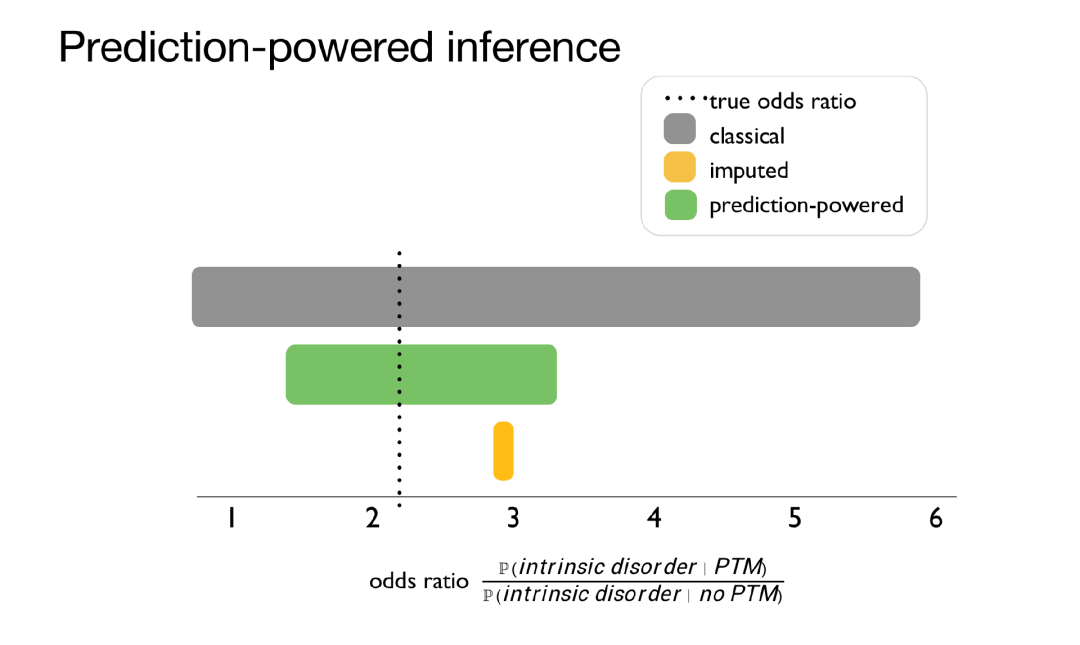
我们可以采用所有 2 亿个结构来计算比值比。这个数字约等于 3,置信区间分布在 3 附近。置信区间大概率将不包含 1。因此,我们认为,预测是有效的。
现在,我们尝试使用一半数据重新进行实验,通过大型蒙特卡罗实验找到另一半数据的真实值。
如上图所示,虚线代表真实值。黄色的区间根本没有包含真实值。因此,这个置信度很高的系统有很小的置信区间,但是它的预测基本是错误的。事实证明,系统正确地判断了存在关联,但原因是错误的。
你可能认为我们不应该实时使用预测,我们只会使用真实数据。所以,灰色置信区间是只使用 100,000个数据点的真实数据的情况。但这仍然不够,因为置信区间包含「1」。我们仍然无法得出任何科学结论。
现在我要展示的是一种新方法,称之为「预测驱动的推理」(Prediction Powered Inference)。 它使用纠正置信区间的机器学习系统来生成置信区间。即使机器学习系统在大多数情况下存在偏见,但我们会通过某种方式纠正实际的科学推理,这真的很重要。如上图所示,绿色的置信区间包含真实值且不包含「1」。它比根本不使用机器学习的灰色朴素区间要小得多。
假设有一些人为提供的标记数据,并且拥有 AlphaFold 等预测系统提供的大量数据。未来,通过生成式人工智能产生大量数据,通过人类标注小数据子集的标签将会成为常态。
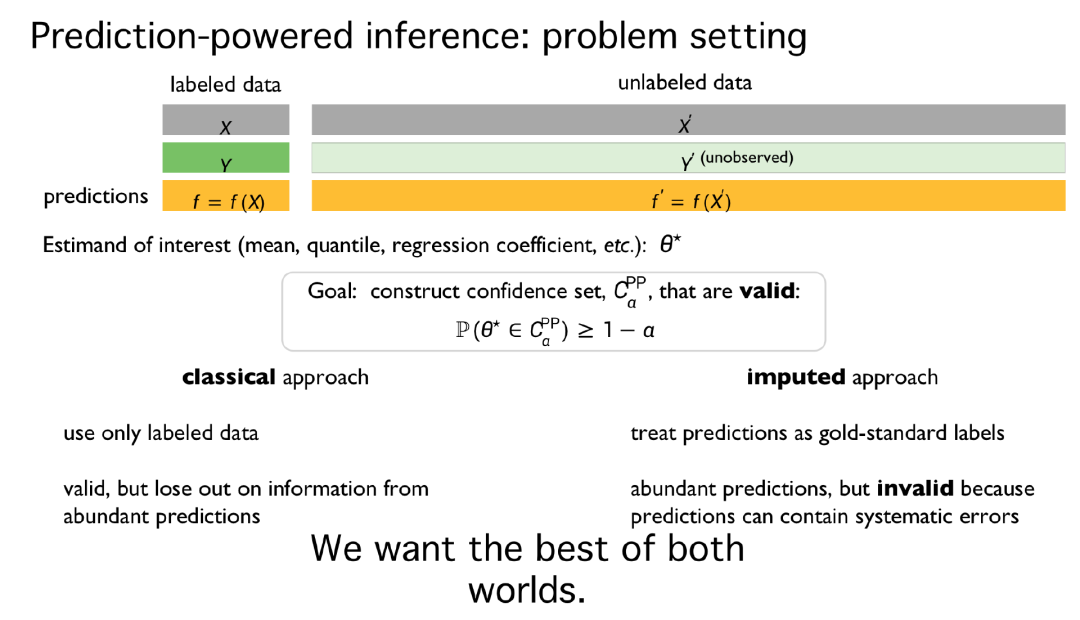
这看起来像是监督学习。尽管相似,但还是有所不同。如上图所示,X 为带标记的数据(例如,氨基酸序列), y 是实验室实验给出的蛋白质结构,即黄金标准。f 是 AlphaFold 的预测结果。
现在,我们有大量的生成式人工智能,它只接受输入序列 x,没有任何结构化标签,并根据 AlphaFold 进行预测。我们如何利用它们得到很小的良好置信区间?该置信区间 以大于 99% 的概率包含真实值。
以大于 99% 的概率包含真实值。
我们正在努力将这两个想法结合在一起,以获得两全其美的效果。
案例:基因表达预测
再举一例,在分子生物学中,如果你试图将一段 DNA 放入细胞中,基因是否会表达。然后,再设计一个新的 DNA,同样看看是否能表达。我们希望模型能够对基因的表达情况进行预测。
由于没有太多数据来测试表达,我们使用计算机机器学习算法来预测表达。通过这种方法,我们将得到黄色的较窄的置信区间,该置信区间并没有包含真实值。同时,灰色的朴素置信区间包含真实值,但是却太大(也包含了「1」)。绿色的新型置信区间获得了两全其美的效果。
案例:私人健康保险预测
在根据人口统计数据预测某人是否拥有私人健康保险时,需要估计收入的逻辑回归系数。我们使用机器学习模型对该系数进行预测。该模型存在极大的偏差,其置信区间非常窄,与真实值相差较远。
该结果的确定性很强,但错误程度也很大。如果这是像医学一样生死攸关的决定,就有很大风险。在此例中,经典的置信区间仍然很大,绿色的置信区间包含了真实值,但是并不太窄。这是因为他们使用了较差的机器学习算法。
我们希望的是,即使机器学习算法很糟糕,仍然可以给出一个并不精确,但是很诚实的答案。
那么我们该如何解决这个问题呢?这张幻灯片向您展示了一张幻灯片。这是一幅漂亮的图画。如果您真的想知道,请阅读我们的论文,该论文在档案中免费提供,并将在本周晚些时候发表在期刊上。
预测驱动的推理
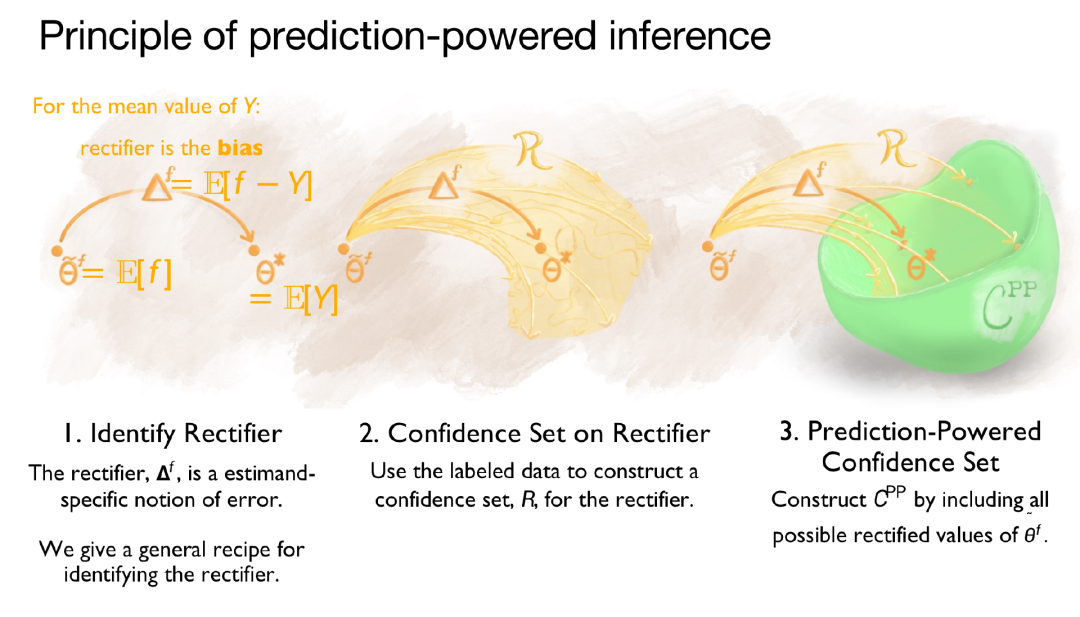
「预测驱动的推理」是一个较新的思想,涉及一定统计学知识。如上图所示,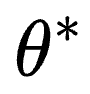 是真实参数。如果有无限的数据,就可以知道该参数。但是我们没有无限的数据。此外,
是真实参数。如果有无限的数据,就可以知道该参数。但是我们没有无限的数据。此外,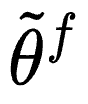 是 AlphaFold 看过无限数据后的输出。现在,AlphaFold 存在偏见,偏差值为
是 AlphaFold 看过无限数据后的输出。现在,AlphaFold 存在偏见,偏差值为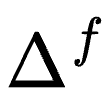 ,即校正项。
,即校正项。
统计学家可以收集数据,获得校正项的置信区间。这样一来,就可以获得从有偏的实体到无偏的实体转变的置信区间。有了置信区间(我们称之为 R),现在要做的就是获取 AlphaFold 的样本,用所有可能的方式在置信区间内进行合理的校正。我们将校正项应用到 AlphaFold 输出,得到一个新的绿色置信区间。这样的校正可以在任何代码的输出中实现,只需大约 5 行代码。希望广大科学家能够这样做。他们应该去获取一些黄金标准。不应该简单地使用生成式人工智能来开展科学研究。
凸估计问题

通过简单的加减法,我们可以得到一个估计值和一个校正项。根据估计器的定义,期望为零。只需对其余部分进行统计,就可以得到这个置信区间。
联邦学习场景
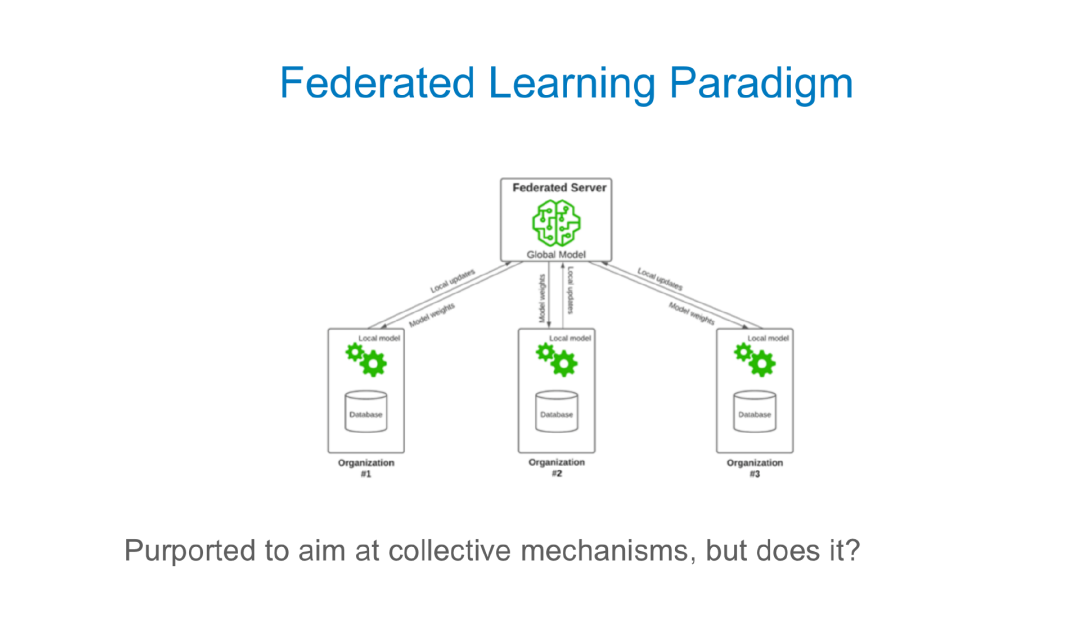
考虑多智能体环境下,智能体间机器学习算法交互的情况。在联邦学习中,我们有一个试图从手机等边缘设备收集大量数据的中央服务器。 例如,如果我们在没有大量数据的情况下他们为什么要这么做? 好吧,也许他们正在尝试构建一个大模型,就需要利用联邦学习。我们要在不需要太多带宽、保护隐私的前提下做到数据的收集和利用。在我看来,我们不仅要考虑边缘设备,还需要考虑人类。在这个集体世界中,人们出于各种自身的目的收集数据。
现在人们在手机上做各种有创意的事情。从某种程度上说,中央实体不应该承担这些功能。它需要保护隐私,应该更多地保证重视用户的数据,为用户的贡献支付费用,认可创造性行为。
事实上,大语言模型不仅在技术上不完善。从社会学上说,维基百科这样的平台包含大量的知识,人们投入了大量的工作。像 ChatGPT 这样的大型语言模型直接利用了这些知识。现在人们去 ChatGPT 提出问题并获得实际上来自维基百科的答案,而创建维基百科的人却得不到认可,也没有得到金钱回报。从经济学上说,这是很糟糕的,不会激励人们做更多这样的事情。
我们必须考虑在边缘提供信用、资金、传播财富和利益。我们需要一个机器学习的集体模型。如上图所示,各个节点将重视他们的数据。我们需要经济意义上的与学习算法良好交互的机制。这一问题仍有待解决。
统计契约理论
契约理论是经济学中的一个主题,曾多次获得诺贝尔奖。这是一个重要的话题,但它根本不是基于数据的。它以经济学家给出的一些方程为基础,设计一系列契约。我们则试图使其成为一个自适应系统。
关于激励理论,经济学中有各种与之相关的数学方法,大量的微分方程和随机过程等。这也涉及到博弈论。博弈论是描述具有策略的智能体的数学方法,参与博弈的各方要么合作,要么竞争,并且有自己的利益。博弈中不只有一种最佳方案,存在某种合作或平衡。
通过博弈论,我们试图描述智能体交互时会发生什么。与物理学类似,博弈也存在反问题。物理学中的反问题被称为机械工程。我们想建立一个物理系统,按照我们希望的方式运作。
同样,对于经济学,假设有一个期望的结果,例如,某种市场被创造出来,人们以某种方式获得报酬,财富以某种方式传播。我想弄清楚我可以设计怎样的博弈过程。这就是博弈论的逆过程,在经济学中被称为机制设计。
在对称博弈中,博弈各方都是相同的,可以实现所谓的纳什均衡。反过来,就需要进行拍卖。然而,世界很少是对称的,有些人比其他人了解更多。
经济学中还有另一种均衡,称为斯塔克尔伯格均衡。合约是一种在没有统一价格的情况下考虑定价的方法。例如,当您乘坐飞机时,不同座位具有不同的价格。如果定价方式不公平,人们不会喜欢它。你需要给人们一堆选择,指出服务和相应的价格。
给每个人提供同样的服务和价格, 这是合法的。实际上,你试图让一些人购买价格更高的商品。例如,花更多的钱坐商务舱,你会得到一小杯酒,一个更大的座位,感觉非常好。
一些人选择走过商务舱,回到经济舱,他们没有小红酒或大座位,但他们付的钱少得多,他们也很高兴。航空公司同样很高兴,因为他们把飞机装满了,获得了经济收益。实际上,这是一种经济模型,可以让产品发挥作用。模型知道我们在不同的时间对不同的东西有不同的支付意愿。这就是契约理论,你可以用它来进行数学计算。
在美国,FDA,即联邦药物管理局决定什么药物可以进入市场。进行临床试验来做出这些决定需要花费大量资金。 临床试验大约有 30,000 人参加,其中一半接受药物,另一半不接受药物。 疫苗就是这样开发的。 每个国家每年要做这件事要花费几千万美元、几亿人民币。

而现有机制缺乏激励措施。首先,FDA 并不是这里唯一的参与者,FDA 只负责测试,他们不产生候选人。他们不关注新药。通常情况下,有些制药公司有能力生产新的候选药物。

制药公司知道药物的优势,但FDA根本不知道。FDA 无法要求制药公司告知药物的所有优点。这是因为制药公司想要获得有利的许可条款,他们想赚钱但不想向其他人透露他们的秘密。这是一个不对称的问题。这种不对称性并不会因为获得更多数据而消失。
而如果药物不好,FDA保证批准的概率只有5%。这就是所谓的误报率。另一方面,如果药物效果好,他们的测试批准的概率为 80%。

实际上,这种方法在某些情况下会失败。有时,利润非常微博。假设您花费了 2000 万美元进行一项试验。如果获得批准,你将赚取 2 亿美元,因此对于小市场来说,这将是一种非常小的药物。如果我不知道我的药实际上不好,那么我的预期利润将是 - 1000 万,因为大多数情况下我会被拒绝,而我仍然要为每项测试支付 2000 万美元。
所以我不会向监管机构 FDA 发送很多药物。因此,监管机构只会找到好的候选药物,并且他们有良好的统计协议。
现在,CEO可以做同样的计算,如果theta等于0,我的利润期望为 8000 万,即使这个药物在现实中没有效果,如果我将其送审至 FDA,我也会赚8000万美元。因为 5% 虽然很小,但也有成功的可能。
这是统计学与经济学的结合,涉及微观经济学、激励措施。我们必须找到一种方法将它们放入统计问题中。
为此,我们设计所谓的统计契约。博弈各方将收到这份包含四项内容的清单,并询问他们是否想参与博弈。如果你想参与博弈,首先要做的就是支付预订费,比如2000万。

统计试验从自然界中获取随机变量 z。指的是看看这个药到底有没有作用。Z 是随机的,但你有一些证据。现在,将随机变量放入支付函数中,然后向博弈一方支付。
然后监管者、政府收到为许可证支付的费用,它也依赖于的真实值。随着时间的推移,人们会意识到监管机构做得好不好。我们拥有让监管机构真正进行机器学习并做出受激励的良好决策的所有要素。如果没有所有这些要素,我不知道如何解决统计世界的监管问题。
无论如何,我们可以基于已有的公式进行数学计算,计算选择列表、最佳选项、预期收入,市场故障的概率。我们可以在这里取得良好的经济效益。
在这里,激励对齐意味着在零假设下,药物根本不起作用,期望收入减去必须支付的金额小于或等于零。
我们所做的工作表明,统计与微观经济学中的契约密切相关。我们可以将其应用到联邦学习的一系列问题上,设计一些机制来激励用户提供数据。

除了监管,授权问题同样值得研究。Scale、亚马逊、Appen 和 Upwork等公司正在这样做。他们考虑制定合约,并营造一个健康的市场。
我认为人工智能应该被视为一个新兴的工程领域。与任何工程领域一样,它确实需要大量的工作。这并不是说我们现在有了一些可以用来做事的魔法。深度学习,大型语言模型可以做一些简单形式的推理,但我坚信人类在其他重要的方面更加聪明。人类和机器在社会环境中的整合才是有趣的,这是一项工程任务。

总结,AI不是我们现在所拥有,并试图监管的某种秘密的超级智能,而是一个新的工程领域,使我们能够以新的方式思考并构建有助于人类的新型系统。
更多内容 尽在智源社区