本文整理自Flink数据通道的Flink负责人、Flink CDC开源社区的负责人、Apache Flink社区的PMC成员徐榜江在云栖大会开源大数据专场的分享。本篇内容主要分为四部分:
- CDC 数据实时集成的挑战
- Flink CDC 核心技术解读
- 基于 Flink CDC 的企业级实时数据集成方案
- 实时数据集成 Demo 演示
CDC 数据实时集成的挑战
首先介绍一下CDC技术,CDC就是Change Data Capture的缩写,意思是变更数据捕获。如果有一个数据源的数据随着时间一直在变化,这种能够捕获变更数据的技术就称之为CDC。但是在真正的业务生产实践过程中,通常说的CDC都是指面向数据库的变更,用于捕获数据库中某一张表业务,不断地写入的新数据、更新的数据、甚至删除的数据。我们在谈到捕获变更数据的技术时,之所以主要面向数据库,主要是因为数据库里面的数据是业务价值最高的数据,数据库的变更数据也是业务里时效性最高、最宝贵的数据。

CDC技术应用是非常广泛,主要有三个方面。
第一,数据同步,比如数据备份、系统容灾会用到CDC。
第二,数据分发,比如把数据库里面变化的数据分发到Kafka里面,再一对多分发给多个下游。
第三,数据集成,不管是在数仓构建还是数据湖构建都需要做一个必要工作数据集成,也就是将数据入湖入仓,同时会有一些ETL加工,这个工作中CDC技术也是必不可少的应用场景。

从CDC底层的实现机制上可以将CDC技术分成两类:基于查询的CDC技术、基于日志的CDC技术。
基于查询的CDC技术。假设数据库有一张表在不断更新,我们可以每5分钟查询一次,查询里比如按照更新时间字段对比一下看看有哪些新的数据,这样就能获取到CDC数据。这种技术需要基于离线调度查询,是典型的批处理,没法保证保障数据的强一致性,也不能够保障实时性。一个离线调度从行业的实践来看到5分钟已经是极限了,很难做到分钟级甚至秒级的离线调度。
基于日志的CDC技术。这就是基于数据库的变更日志解析变更的技术,比兔大家都知道MySQL的数据库有Binlog的机制。基于数据库的变更日志的CDC技术可以做到实时消费日志做流处理,上游只要更新一条数据,下游马上就能感知到这一条数据,可以保障整个数据的强一致性,还可以提供实时的数据。基于日志的CDC技术通常实现复杂度上会比基于查询的方式更高一些。
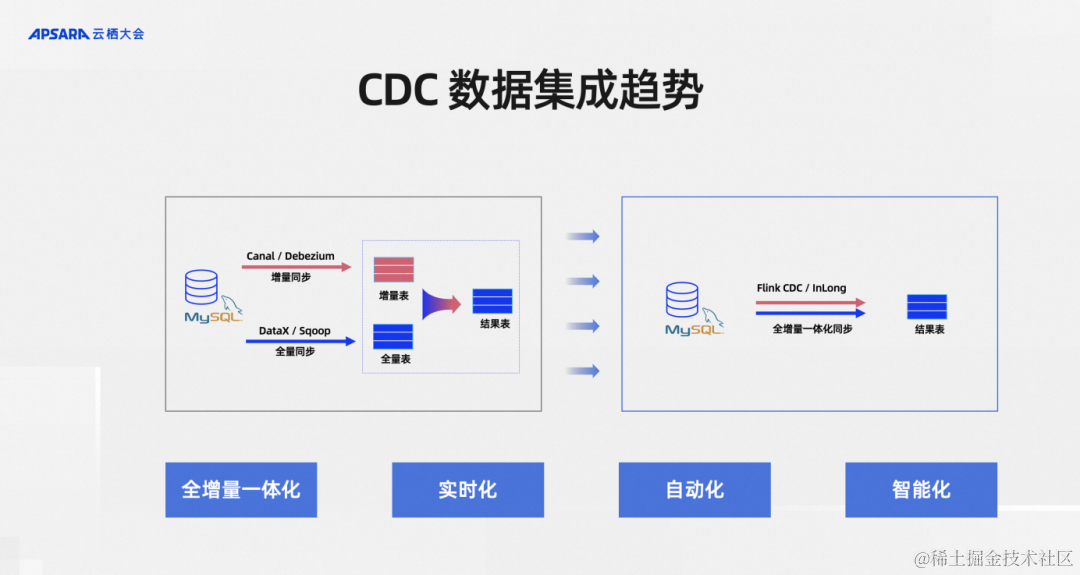
从CDC数据集成这个细分领域的发展趋势来看,总结了下大致四个方向:
第一,全增量一体化。
第二,实时化。
第三,自动化。
第四,智能化。
全增量一体化是相对于全量和增量分别做数据集成,所以全量很好的例子就是一张MySQL的表有海量的历史数据。但同时上游的业务系统源源不断地在往里面实时更新,实时更新的那部分就是增量数据,历史的那部分就是全量数据
往往这两部分数据在早期采用不同的工具,比如说全量有国内开源的DataX,海外有Apache Sqoop可以做全量的同步。增量部分比如说国内阿里巴巴开源的Canal、MySQL、Debezium、InLong等等开源项目。用户一般会结合这两种类型的工具分别做全量数据和增量数据集成,其代价是需要维护很多组件。全增量一体化就是把这些组件尽可能地减少,比如说采用Flink CDC、InLong这样的方式来做一个全增量一体化降低运维压力。
第二个就是实时化,大家都知道为什么我们要提实时化,因为业务数据的时效性越高代表价值越高。比如说一些风控业务、策略配置业务如果能做秒级的处理,和两天之后才能把数据准备好,其带来的业务效果是完全不一样的,所以实时化被日趋重视。
自动化是说我们在做全量和增量去结合的时候,全量完了之后需不需要人为干预,全量同步完了以后增量如何保障衔接,这是CDC框架提供的自动衔接能力还是需要运维人员手动操作,自动化就是将这类手动操作降低,自动化可以说是降低运维成本和产品体验提升方面的诉求。
智能化就是一张MySQL里面的业务表,随着业务的变化是不断在变的,不仅是数据在变,里面的表结构都会变。应对这些场景,数据集成的作业能不能保持健壮,进而能不能自动地、智能地处理上游的这些变更,这是一个智能化的诉求,这也是CDC数据集成的趋势。

分析了整个CDC数据集成这个细分领域的一些架构演进方向,从中也看到了很多问题,若想去解决,会有哪些技术挑战呢?大致梳理为四个方面:
第一,历史数据规模很大,一些MySQL单表能够达到上亿或者基几十亿的级别,在分库分表的场景,甚至有更大的历史数据规模。
第二,增量数据那部分实时性要求越来越高,比如说现在的湖仓场景都已经需要5分钟级的低延迟。在一些更极端的场景中,比如说风控、CEP规则引擎等等应用场景甚至需要秒级、亚秒级的延迟。
第三,CDC数据有一个重要的保序性,全量和增量能不能提供一个跟原始的MySQL库里面一致性的快照,这样的保序性需求对整个CDC的集成框架提出了很大的挑战。
第四,表结构变更,包括新增字段和已有字段的类型变更,比如一个字段业务开发长度升级了,这样的变更框架能不能自动地支持,这都是CDC数据集成的技术挑战。
针对这些挑战,我挑选业界现有的主流开源技术方案,也是几个大家比较常见进和应用比较广泛的进行分析,包括 Flink CDC、Debezium、Canal、Sqoop、Kettle,我们分别从一下几个维度来分析,首先是CDC的机制,就是底层的机制来看它是日志的还是查询的。

其次是断点续传,断点续传就是全量数据历史规模很大,同步到一半的时候能不能停下来再次恢复,而不是从头开始重刷数据。全量同步维度就是框架支不支持历史数据同步。全增量一体化维度泽是全量和增量过程是框架解决的还是要开发人员手动解决。架构维度则是评价 CDC框架是可扩展的分布式架构,还是单机版。转换维度衡量的是CDC数据在数据集成做ETL的时候往往要做一些数据清洗,比如说做一个大小写转换,这个框架能不能很好地支持,比如需要做一些数据的过滤,框架能不能很好地支持,以及另外一个就是这个工具的上下游生态,框架上游支持多少数据源,下游的计算引擎能支持哪些,支持写入的湖仓有哪些,因为在选择一个CDC数据集成框架或者工具的时候肯定是结合整个大数据团队其他产品的架构设计统一考虑的。从上述这几个维度分析,Flink CDC 在这几个维度下的表现都非常优秀。
Flink CDC 核心技术解读
刚刚我们说到,Flink CDC这个框架在全增量一体化、分布式架构上等维度下都有一些优势,我们接下来就来解析一下框架底层的核心技术实现,带着大家去理解Flink CDC如何具备这些优势,以及我们设计的一些初衷。
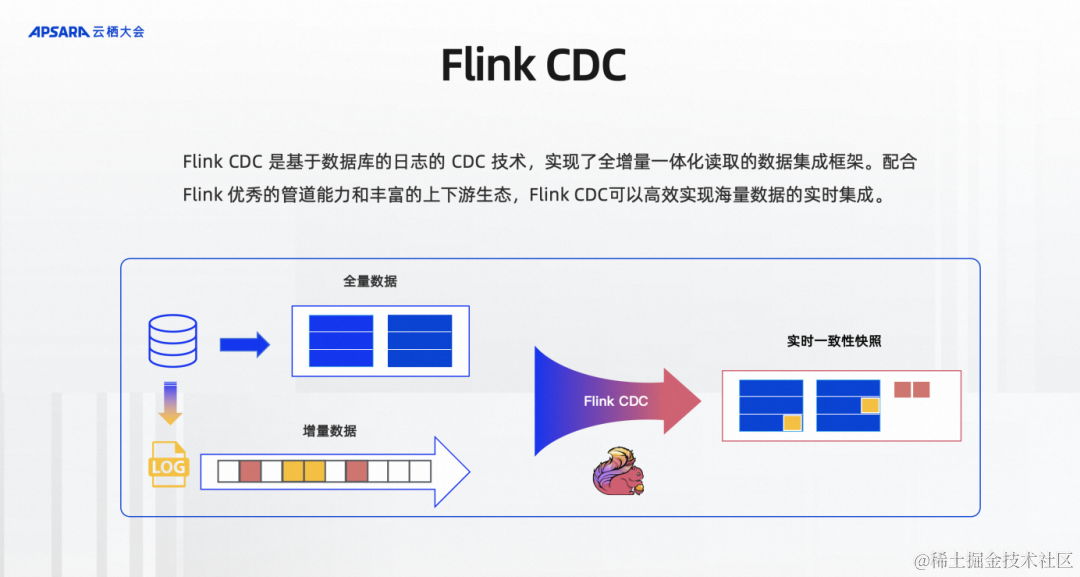
Flink CDC是基于数据库日志的CDC技术及实现了全增量一体化读取的数据集成框架,配合Flink优秀的管道能力和丰富的上下游生态,Flink CDC可以高效实现海量数据的实时集成。如图所示,比如说MySQL有一张表有历史的全量数据,也有源源不断写入的增量数据、业务更新的增量数据MySQL都会先存在自己的Log里面,Flink CDC既读取全量数据,又通过基于日志的CDC技术读取增量数据,并且给下游提供实时一致性的快照,框架提供了全量和增量的自动对接,保证了不丢不重的数据传输语义,开发者不用关心底层的细节。
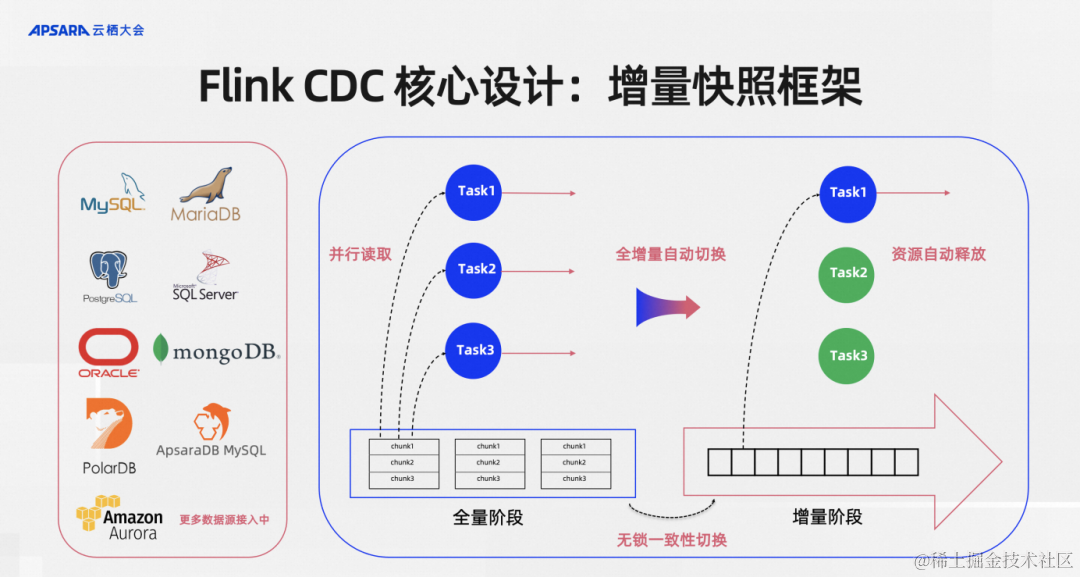
整体来说,Flink CDC有两个最为核心的设计;
第一个是增量快照框架。这是我在Flink CDC 2.0的时候提出的一个增量快照算法,后面演变成增量快照框架。左边的这些数据源是现在Flink CDC社区已经支持或者已经接入的增量快照框架。增量快照框架体现的是什么能力呢?在读取数据一张表到全量数据的时候可以做并行读取,这张表即使历史数据规模很大,只要增加并发、扩资源,这个框架是具备水平扩容的能力,通过并行读取可以达到扩容的需求。
第二个是全量和增量是通过无锁一致性算法来做到无锁一致性切换。这其实在生产环境非常重要,在很多CDC的实现里面是需要对MySQL的业务表加锁来获得数据一致性的,单这个加锁会直接影响到上游的生产业务库,一般DBA和业务同学是不会同意的,如果用增量快照框架是能够对数据库不加锁的,这是对业务非常友好的设计。
切换到增量阶段之后结合Flink框架可以做到资源自动释放的,一般来说全量阶段并发是需要很大的,因为数据量很多,增量阶段其实写入MySQL上游基本上都是一个单独的日志文件写入,所以一个并发往往就够了,多余的资源这个框架是可以支持自动释放的。
总结起来如图所示四个红色的关键短语突出的就是增量快照框架给Flink CDC提供的核心能力。
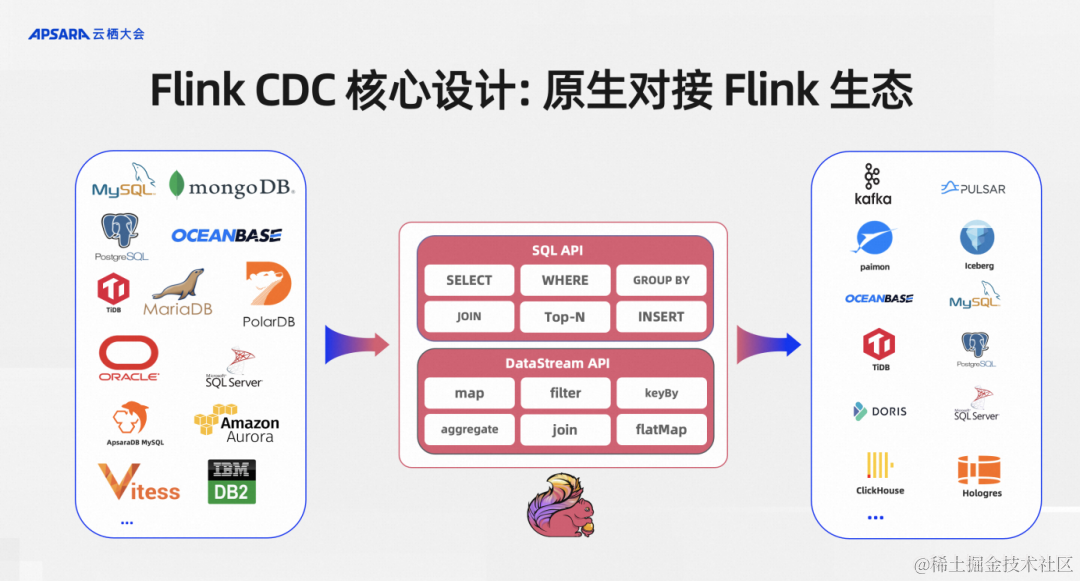
第二个核心设计就是原生对接Flink生态。对接Flink生态最关心的就是能否无缝使用Flink的SQL API、DataStream API以及下游。Flink CDC作为Flink作业的上游时,当前我们所有的connect都是支持SQL API和DataStream API。
支持 SQL API的好处是用户不需要有底层JAVA开发基础,会写SQL就行了,这其实把一个难度系数很高的CDC数据集成交给BI开发同学就可以搞定了。DataStream API则是面向一些更高级的开发者可能要实现一些更复杂、更高级的功能,我们同时提供了DataStream API,让更底层的开发者通过这种DataStream API 可以通过 Java编程的方式来实现整库同步、Schema Evolution等高级功能。
在原生对接到Flink的生态之后,Flink上支持的所有下游,比如说消息队列、Kafka、Pulsar,数据湖Paimon或者传统的数据库,Flink CDC 都可以直接写入。

借助这些核心设计,总体来讲:Flink CDC的技术优势有四个。
第一,并行读取。这个框架提供了分布式读取的能力,Flink CDC 这个框架可以支持水平扩容,只要资源够,读取的吞吐可以线性扩展。
第二,无锁读取。对线上的数据库和业务没有侵入。
第三,全增量一体化。全量和增量之间的一致性保障、自动衔接是框架给解决的,无需人工介入。
第四,生态支持。我们可以原生支持Flink现有生态,用户开发部署成本低。如果说开发者已经是一个Flink用户,那他不需要安转额外的组件,更不需要部署比如Kafka 集群,如果是SQL用户只需要将一个connector jar包放到Flink的lib目录下即可。
还有一个听众可能比较感兴趣的点,Flink CDC这个项目是完全开源的,并且从诞生的第一天就是从开源社区出来的,到现在已经从0.x 版本发到最新的2.4.2版本,在全体社区贡献者的维护下已经走过三年,作为个人兴趣项目逐步打磨起来的开源项目,三年的时间这个社区的发展是非常迅速的。我这里说的发展并不只是说Github Star 4500+ 的非常快速的发展,其实我们更看重的是代码Fork数和社区贡献者数量。Fork数指标表示了有多少组织、多少的开源社区贡献者在使用Flink CDC仓库,比如说Apache InLong这样的顶级项目都是集成了Flink CDC,
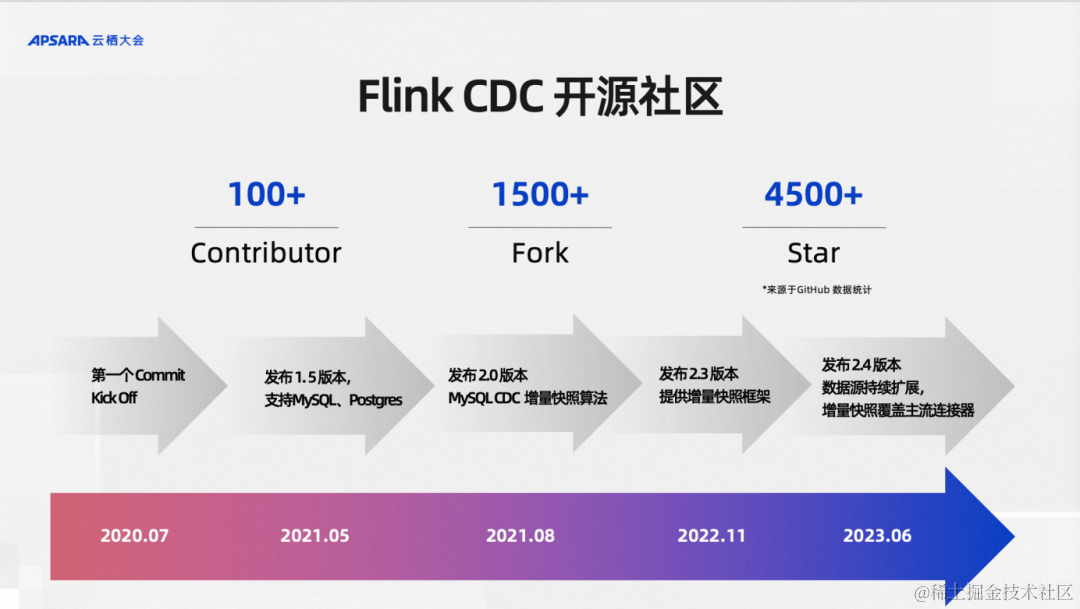
同时这里面不乏海外和国内一些顶级的公司也在用我们的项目。最近我们的开源社区来自国内和海外的贡献者数量超过100+,这说明我们的开源社区发展还是非常健康的。
讲完Flink CDC的开源社区,有一个点大家会关注到,就是它提供的能力还是偏底层引擎,是比较面向底层开发者,离我们最终的数据集成用户中间还有一层gap,这个gap就是引擎怎么形成产品给最终的用户。有一个事实需要注意到,数据集成的用户其实不一定懂Flink,不一定懂Java,甚至不一定懂SQL,那么如何能让他们使用这个框架?如何提面向用户的产品来服务好这些用户?其实很多参与开源的公司、组织都有一些最佳实践方案。
阿里云基于 Flink CDC 的企业级实时数据集成方案
今天分享的第三部分就是我今天要介绍的,在阿里云内部我们是怎么基于开源的Flink CDC数据集成框架来提供我们的实时数据集成方案,也就是将阿里云的一些实践方案和大家一起分享。
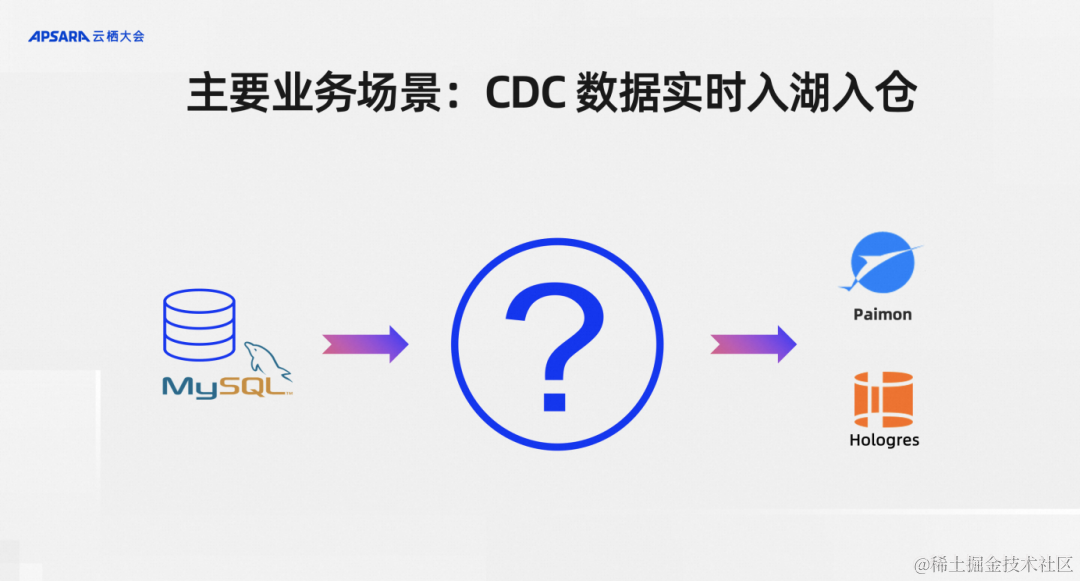
在阿里云上,我们Flink CDC最主要的业务场景就是CDC数据实时入湖入仓。比如说我的业务库是MySQL,当然其他数据库也一样,我其实就是要把MySQL里面的数据一键同步到湖仓里面,比如说Paimon、Hologres, 业务场景就是CDC数据实时入湖入仓,这个场景下用户的核心诉求什么?
我们大致整理了四个关键点:需要表结构自动发现,需要表结构的变更自动同步,需要支持整库同步,需要支持动态加表。
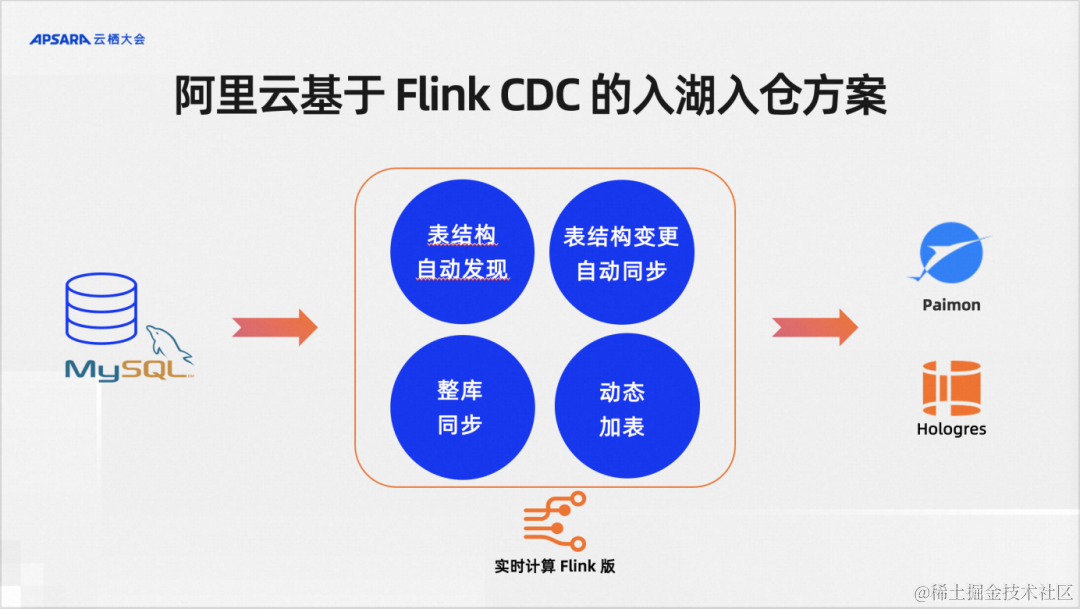
Flink CDC是一个数据集成框架,在阿里云上并没有单独的Flink CDC产品,它是在我们serverless Flink,也就是阿里云实时计算Flink版提供了上述的能力。除了在实时计算Flink版,在阿里云另一款产品Dataworks上也提供了基于Flink的CDC数据集成方案。
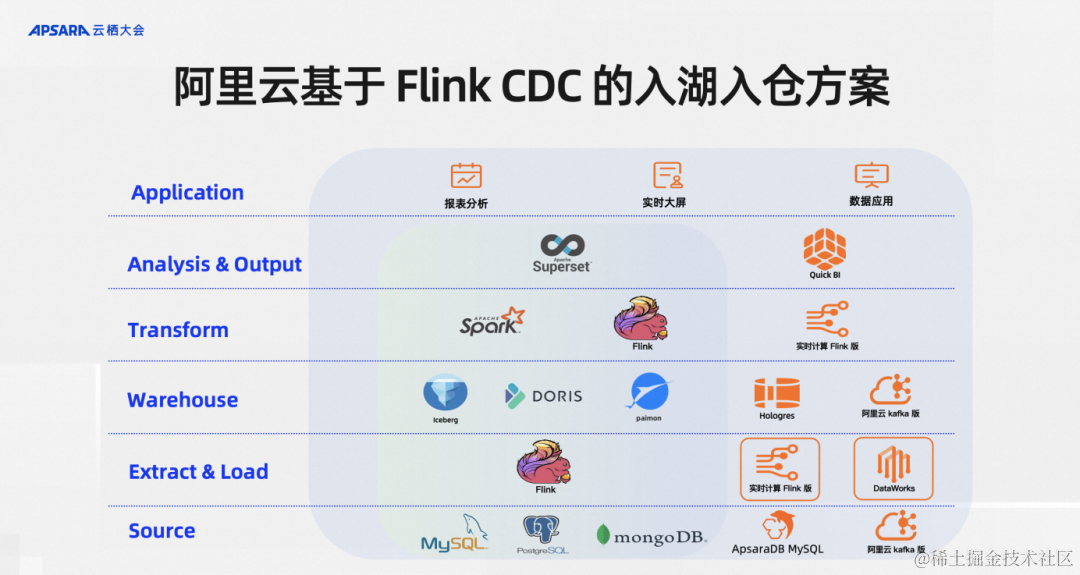
按照现代数据栈的分层理念,Flink CDC 所在处的是EL层,分工特别明确。最下面一层是数据源,Flink CDC专注于做数据集成,在ELT数据集成的模型里里面负责做E和L,当然实践里面也会支持一些轻量级的T,就是Transform 操作。

在阿里云实时计算Flink版我们设计两个语法糖,分别是CDAS(Create Database As Database)和CTAS(Create Table As Table)。CDAS就是通过一行SQL实现整库同步,比如说MySQL里面有一个TPS DS库同步至Paimon的ODS库就可以搞定。同时我也提供CTAS,比如说在应对分库分表的重点业务时,可能对单表要做一些分库分表的合并,合并到Paimon里面做一个大宽表等等,多个表合成一个表的逻辑。这个表还会做一些事情,比如要推导最宽的表结构,以及分表的表结构变化了之后,在下游最宽的表里面也要看到对应表结构的同步,这些是通过CTAS实现的。

最终的效果是,用户只需要在实时计算Flink里面写一行SQL,当这行SQL下面其实做了很多的工作,最终的效果是拉起来了一个Flink数据集成作业。大家可以看到上图中,作业的拓扑里有四个节点,最前置的一个节点就是读MySQL的source节点,后面三个节点就是对应我们红框里面的三张表,自动生成了三个 sink 节点。对于用户来说就是写一行SQL,便可以实现全增量一体化的CDC数据集成。
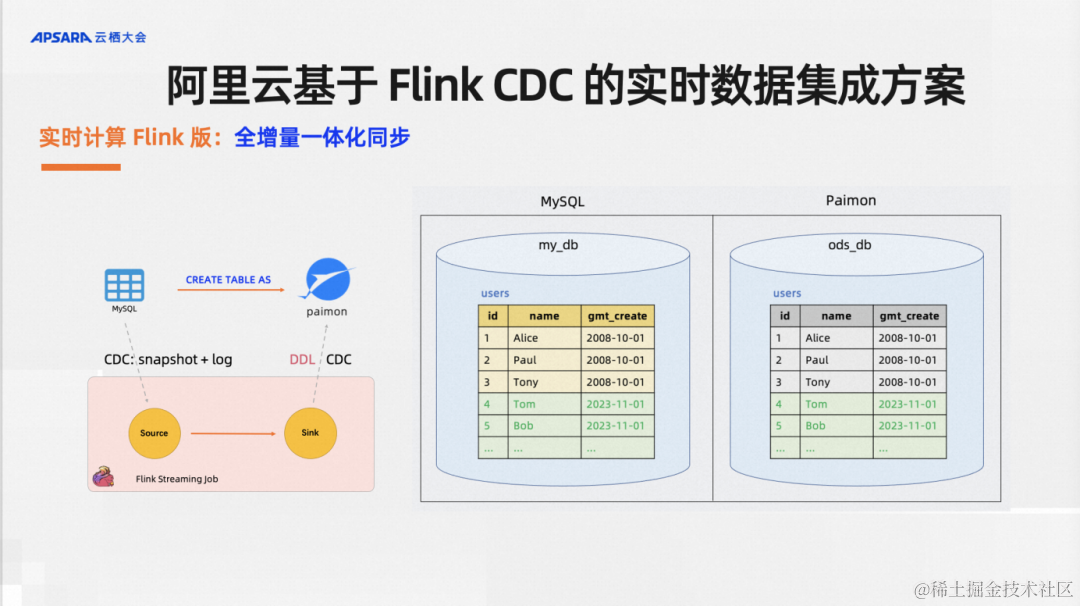
实时计算Flink版里面提供了默认支持全增量一体化同步。举一个例子,我有一些历史全量数据和增量数据,一个CTAS语法默认支持全量和增量的数据同步,当然你也可以选择通过配置不同的参数选择只同步全量或者只全部增量。
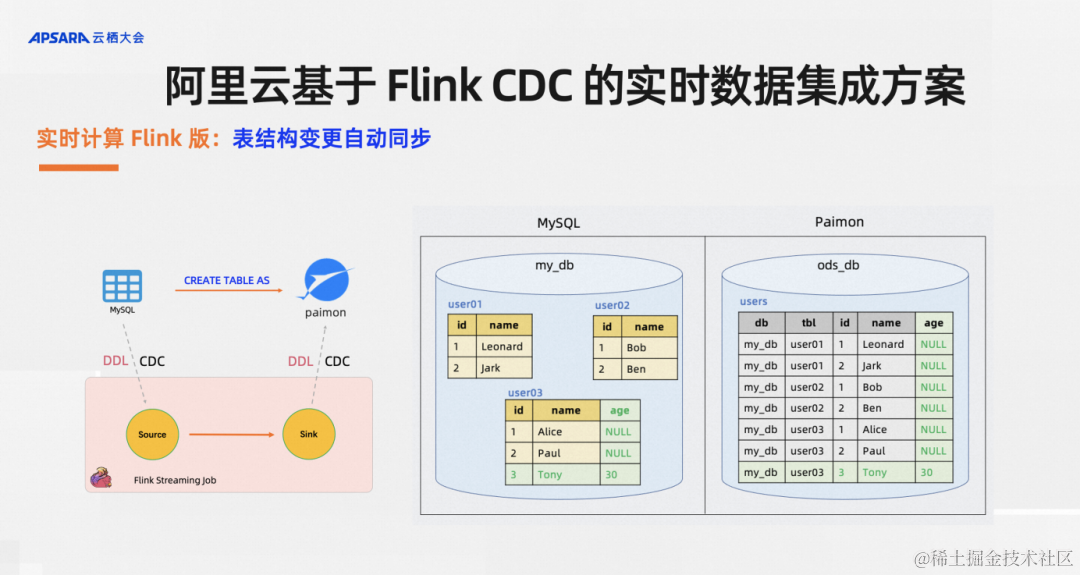
实时计算Flink版还支持表同步变更,比如说有一个分库分表的场景,库里有一张名为user03的表,业务同学新加了一个字段age,后续插入的记录里面也多个了一个age的字段,用户想要的效果是在下游的湖仓里中自动加列,新的数据能够自动写入。对于这样的需求,CTAS/CDAS语法均默认就支持。
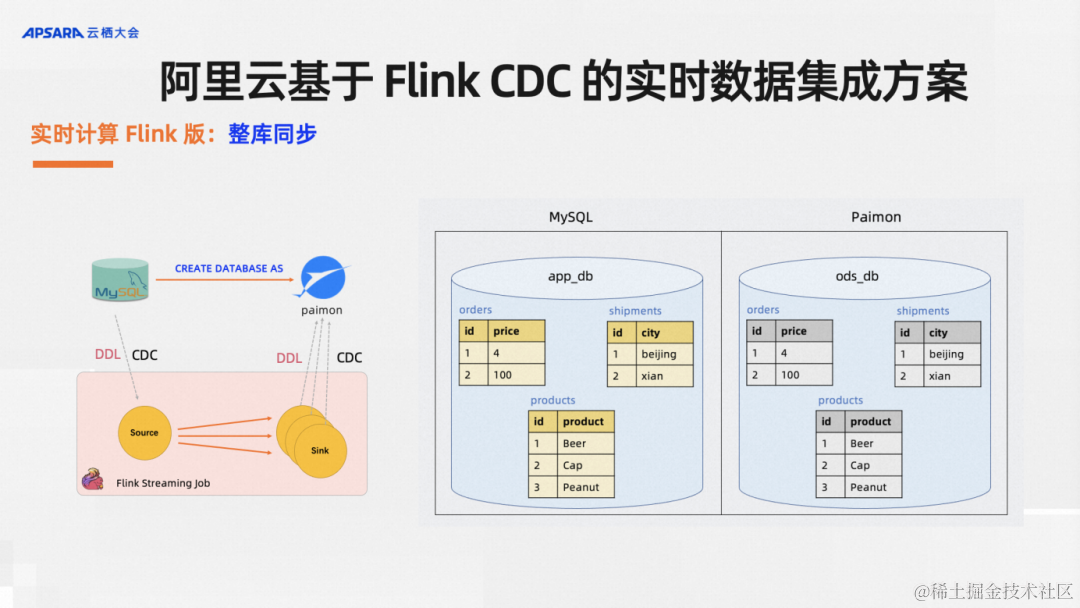
实时计算Flink版支持整库同步,对于单表同步,每一个表同步都需要写一行SQL对用户来说还是太费劲,用户想要的就是尽可能简单,功能尽可能强大,CDAS语法糖就是帮用户干这件事。比如说原库里面有若干张表,只需要写一行SQL,我通过捕获库里面所有的表,自动改写多个CTAS语句,然后同步到下游,并且每一张表都支持表结构变更自动同步,源头这三张表可以各自加列删列,下游Paimon里的数据自动加列删列同步。
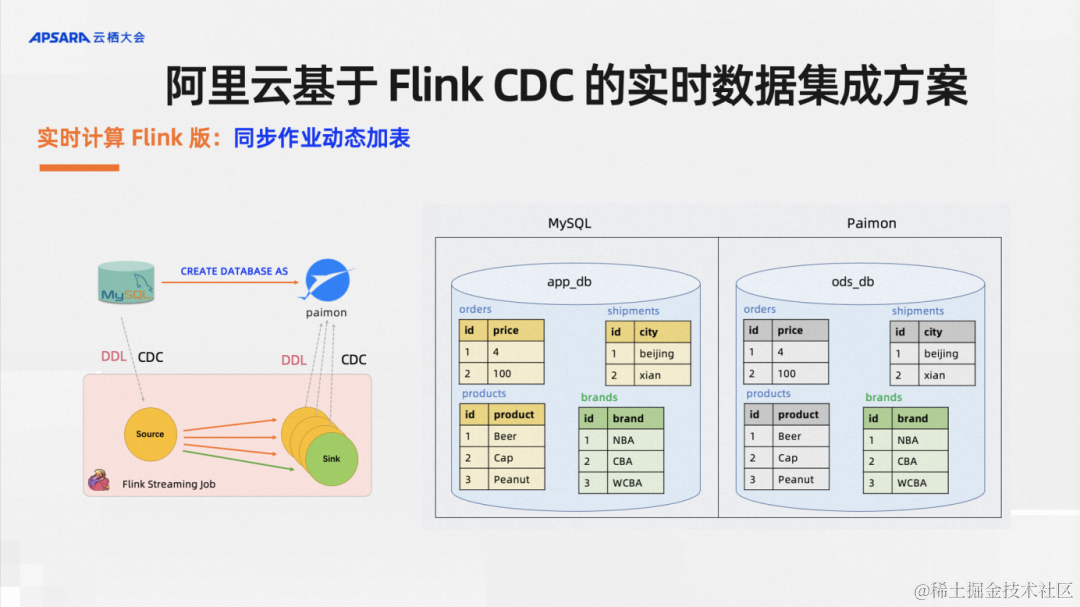
实时计算Flink版还支持同步作业动态加表,在当下IT行业降本增效的背景下,尽可能节省资源能大幅降低业务成本。在CDC数据集成的场景中,比如说我之前的一个作业里面、业务库里面有1000张表,我用了5CU资源的作业来同步数据。如果说现在业务库加了两张表,这个时候我是新起一个作业还是在原有作业里面加表呢?这就是我们开发的动态加表功能,它可以直接复用原有作业的state和资源,不用新开作业的资源,实现动态地给历史作业加表。这个功能的效果如上图所示:MySQL库里面之前有三张表,现在加了一张表,这个历史同步作业支持把新加的这一张表同步过去,这就是同步作业的动态加表。
上述这个功能是我们在阿里云内部实践下来业务效果不错,数据集成的用户反馈也比较好的一些企业级CDC数据实时集成的方案,分享出来希望可以和同行朋友交流,希望大家可以有收获。
实时数据集成 Demo 演示
Demo 演示观看地址:
https://yunqi.aliyun.com/2023/subforum/YQ-Club-0044开源大数据专场回放视频 02:28:30 - 02:34:00 时间段
在这里,我录制了一个Demo来演示上述功能,这个Demo 展示了从MySQL到刚刚介绍的Streaming Lakehouse Paimon的CDC数据集成,为大家演示一下怎么在实时计算Flink版里面高效地实现整库同步、Schema evolution、以及复用历史作业来实现动态加表。
首先我们创建一个MySQL的Catalog,这在页面点击就可以创建,再创建一个Paimon的Catalog。创建好这个Catalog之后就可以写SQL了,其实有几个参数设置不设置也可以,这里设置是为了演示时速度更快,我们先写一个CDAS语句。第一个语句是同步两张表,订单表和产品表,把作业提交一下,我只想把库里面的订单和产品同步到Paimon里面,这个作业提交稍微等一下,同步两张表的Flink 作业就生成了。我们可以在控制台这边再起一个作业,这个作业可以把Paimon里面的数据捞出来给大家看一下,比如说订单表里面的数据跟我们上游MySQL的数据是一样的,并且是实时同步的。MySQL里面马上插入一行数据,我现在去Paimon里面看一下插入的数据,其实就已经可以看得到了。这个端到端的延迟是非常低的,同时可以演示一个表结构变更功能,从源头的表中新加一列,用户不需要做任何操作,在下游Paimon在数据湖里面对应表结构的变更,会自动到Paimon目标表。上游创建加了一个列,现在再插入一列,比如说插入一条数据,后面有一个值新增的列,我把这行数据给插入,接下来我们就看一下我们Paimon里面对应的这张表,大家可以看最后一行这个带着新增列的数据已经插入了。
接下来给大家演示一下我们动态加表的功能,这是是我们最近在阿里云上刚刚推出的一个重磅功能。一个作业里,之前只同步了订单表和产品表,现在用户想添加一张物流表,对于用户来说只需要改一下之前的SQL,多加一个表名。我们先看一下MySQL上游的这张物流表里的数据,对于用户来只需要把作业做一个Savepoint停一下,增加下物流表名,重启一下作业就可以了。我们为什么要从Savepoint重启,是因为Savepoint保留了一些必要的元数据信息,之前同步两张表,现在加了一张表,框架会去做一些校验,把新的表加进去做一个自动的同步,值得注意的是,在这个功能里,我们可以能够保证原有两张表的同步数据不断流继续同步,新的表支持全增量一体化同步。现在的作业有第三张表了,就是新增的物流表的同步。我们也可以在Paimon里面通过Flink查一下,可以看到表里面的数据都已经同步了,不仅是全量数据,如果有新增的表的增量数据也可以做实时的同步,这个延迟也是非常低的,这是得益于CDC的框架和Flink整体框架提供的一个端到端低延迟。
整体demo就到这里,从这个Demo大家可以看到我们在阿里云这个数据集成的实践方案上,是比较面向用户,从最终端的数据集成用户出发尽量为用户屏蔽掉Flink、DataStream或者说Java API甚至是SQL的概念,让用户的操作尽可能地简单,比如说他可以在页面点击创建一个Catalog,后面再写几行简单的SQL即可实现CDC数据集成。此外,我们也有一些同步作业模板,对于同步模板来说,用户都不需要写SQL,直接在页面点击就能够编辑出一个CDC数据集成作业。整体来说,我们在产品的设计上,一个核心理念就是面向数据集成的终端用户,而不是面向于社区的贡献者和开发者,这样更利于我们这个方案推广到更多的用户。



![[oeasy]python001_先跑起来_python_三大系统选择_windows_mac_linux](https://img-blog.csdnimg.cn/img_convert/f8a356f9bd35227eda97ec6b1151e81e.png)





![2023年中国宠物清洁用品分类、市场规模及发展特征分析[图]](https://img-blog.csdnimg.cn/img_convert/c98b948fcd445fa5c73bbadb65db6e88.png)
