1. 数据类型
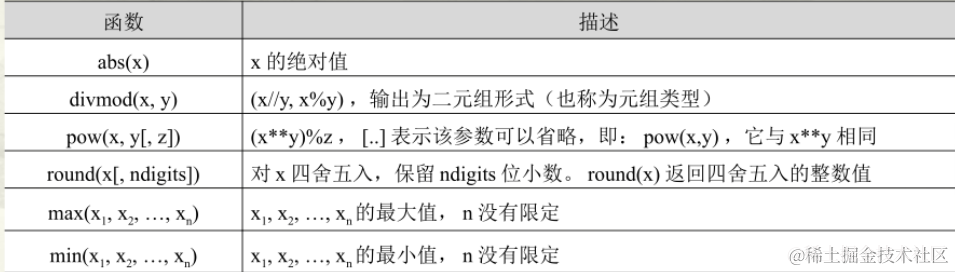
pow(a, b, c) # a^b % c
print("happy {}".format(name))
数字类型包括整数,浮点数,复数
0x9a表示十六进制数(0x,0X开头表示十六进制)
0b1010,-0B101表示二进制数(0b,0B开头表示二进制)
0o123,-0O334(0o,0O开头表示八进制)
执行 print(0xA+0xB) 将会输出结果 21。在这里,0xA 和 0xB 分别代表十六进制的值,0xA 等于十进制的 10,0xB 等于十进制的 11。所以,0xA + 0xB 相当于 10 + 11,结果为 21。
类型判断:type()
divmod(5, 2)函数将5除以2,并返回结果的商和余数。(2,1)
round(2345.67892, 3)函数将2345.67892四舍五入到小数点后3位。
// 和 / 的区别:
//是整数除法运算符,也称为“地板除”。它执行两个操作数的除法并返回一个整数结果,结果是向下取整的商。例如:
7 // 2 # 返回结果为3,因为 7 除以 2 的商是 3
/是浮点除法运算符,它执行两个操作数的除法并返回一个浮点数结果,结果可以是一个小数。例如:
7 / 2 # 返回结果为3.5,因为 7 除以 2 的结果是 3.5
所以,//和/的区别在于返回的结果类型和处理小数的方式。//得到的结果是整数类型(向下取整),而/得到的结果是浮点数类型(精确计算)。
max中比较字符串时按照字典序比较:
按字典序比较是一种字符串之间的比较方法,也称为字母顺序比较。
在按字典序比较中,字符串的每个字符按照它们在字母表中的顺序进行比较。比较是从左到右进行的,直到找到两个字符串中的第一个不同字符为止。
比较的规则如下:
- 首先比较字符串中的第一个字符,如果其中一个字符串的第一个字符在字母表中的位置更靠前,则该字符串被认为是更小的。
- 如果两个字符串的第一个字符相同,则继续比较下一个字符,直到找到第一个不同字符为止。
- 如果一个字符串的所有字符都与另一个字符串相同,则较短的字符串被认为是更小的。
例如,按字典序比较字符串’apple’和’banana’,首先比较第一个字符’a’和’b’,因为’a’在字母表中的位置更靠前,所以’apple’被认为是更小的。
not :取反
1 == 1.0 true
Python 输入默认字符串
执行 print(1, 2, 3, sep=':') 将会输出结果 1:2:3。在这里,print() 函数接受多个参数,并在输出它们时默认使用空格作为分隔符。但是,你可以使用 sep 参数来指定自定义的分隔符。在这个例子中,我们将分隔符设置为 :。因此,输出会将参数之间的分隔符替换为 :,结果为 1:2:3。
执行 int("123.45") 将会引发异常。int() 函数用于将一个字符串或数字转换为整数类型。然而,在这个例子中,字符串 “123.45” 包含一个小数点,无法直接转换为整数。因此,调用 int("123.45") 会引发 ValueError 异常。如果你想将字符串 “123.45” 转换为浮点数,你可以使用 float() 函数来实现,如 float("123.45")。这将返回浮点数值 123.45。
执行 path="C:\Windows\\notepad.exe" 会得到字符串 C:\Windows\notepad.exe 。然后执行 print(path) 将输出 C:\Windows\notepad.exe 。
然而,如果要在字符串中显示一个反斜杠本身,需要使用两个连续的反斜杠 \\ 来表示。因此,定义 path 为字符串 C:\Windows\\notepad.exe,实际上表示路径为 C:\Windows\notepad.exe,其中两个连续的反斜杠 \ 被解释为一个普通的反斜杠 \。当使用 print() 函数打印字符串时,Python会正确地显示转义字符和反斜杠,以显示字符串的实际内容。
在Python中,当你执行 a = b = c = 18 这样的赋值语句时,实际上是将这三个变量 a、b 和 c 都指向同一个整数对象 18。
这种情况下,Python解释器会在内存中创建一个名为 18 的整数对象,并让 a、b 和 c 这三个变量都指向该对象。
a=b=c=18,三个变量被分配到相同的内存空间上。由于整数对象是不可变的,因此没有必要为每个变量分配独立的内存空间来存储相同的整数对象。相反,将它们引用同一个对象是更高效的做法。因此,当你对其中一个变量进行更改时,例如 a = 20,实际上是将 a 变量重新指向一个新的整数对象 20,而 b 和 c 仍然指向原先的整数对象 18。
a = b = c = 10
print(id(a)) # 3108924031504
print(id(b)) # 3108924031504
print(id(c)) # 3108924031504
elif 0.9 > score >= 0.8: 这种写法是对的。
列表元素最大值 max(list)
2. 切片操作
当我们使用切片操作时,我们可以从一个序列(如字符串、列表或元组)中获取一个片段(子序列)。
切片操作的语法是sequence[start:end:step]:
sequence是要进行切片操作的序列(如字符串、列表或元组)。start是切片的起始索引,表示要截取的子序列的起始位置。end是切片的结束索引,表示要截取的子序列的结束位置(但不包括该位置的元素)。step是步长(可选参数),用于指定切片时的间隔,默认值为1。
切片操作返回一个新的序列,包含所选范围内的元素。
下面是切片操作的一些示例:
sequence = 'Hello, World!'
print(sequence[7:]) # 从索引7开始到末尾:'World!'
print(sequence[:5]) # 从开头到索引5之前:'Hello'
print(sequence[::2]) # 每隔一个字符取一个:'Hlo ol!'
print(sequence[3:9:2]) # 从索引3到索引9之间,每隔一个字符取一个:'l,W'
print(sequence[-6:]) # 从倒数第6个字符到末尾:'World!'
print(sequence[:-7]) # 从开头到倒数第7个字符之前:'Hello'
print(sequence[::-1]) # 反转整个序列:'!dlroW ,olleH'
print(sequence[:-5:-1]) # 从倒数第5个字符到开头,每隔一个字符取一个:'!roW'
切片操作是根据索引来截取序列的子序列,其中起始索引是包含的,而结束索引是不包含的。