什么是组件化?
为什么要用组件化?在项目的开发过程中,随着开发人员的增多及功能的增加,如果提前没有使用合理的开发架构,那么代码会越来臃肿,功能间代码耦合也会越来越严重,这时候为了保证项目代码的质量,我们就必须进行重构
组件化的介绍
组件化是指解耦复杂系统时将多个功能模块拆分,重组的过程。在Android工程上表现上就是把app按照其业务的不同,划分为不同的Module

组件化的优点
- 编译速度 :我们可以按需测试单一模块极大的提升了我们的开发速度
- 超级解耦 :极度的降低了模块之间的耦合,便于后期维护与更新
- 功能重用 : 某一块的功能在另外的组件化项目中使用只需要单独依赖这一模块即可
- 便于团队开发 : 组件化架构是团队开发必然会选择的一种开发方式,它能有效的使团队更好的协作 组件化的框架 先看一下整体的结构
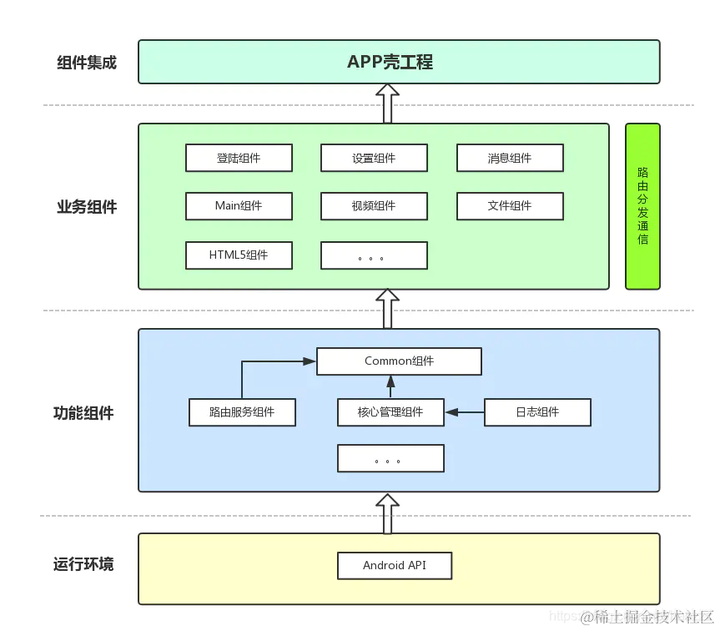
举个例子:以某个直播平台为例(没有画完整),

- 基础层:包含的是一些基础库以及对基础库的封装,比如常用的图片加载,网络请求,数据存储操作等等,其他模块或者组件都可以引用同一套基础库,这样不但只需要开发一套代码,还解耦了基础功能和业务功能的耦合,在基础库变更时更加容易操作。
- 功能组件层:包含一些简单的功能组件,比如视频,支付等等
- 业务组件层:这是通过模块化划分出来的,即根据业务的不同划分为不同的模块,一个具体的业务模块会按需引用不同的组件,最终实现业务功能,如上有三个业务组件
- app层:多个业务模块,各自按需引用组件,最后将各个模块统筹输出 APP。
开始创建
启动Android Studio创建一个Android项目,在项目里new Module,弹出的Create New Module中选择Android Libary或Phone & Tablet,配置完成Module name等参数后点击finish完成创建。
在上图中,创建了common与order组件,common组件推荐作为一个基础库,第三方的一些都在该库进行依赖,其它组件库使用第三方库直接引用common组件即可,一定程度上避免了组件库重复引用的问题。
创建好的Module文件目录下都有一个属于自己的build.gradle文件,Gradle文件执行顺序:settings.gradle > Project build.gradle > Module build.gradle。
在Module build.gradle中可以通过plugins修改当前Model为application或library,如下:
plugins {id 'com.android.application' // application,可以作为app独立运行id 'com.android.library' // library,可作为aar包引入application包使用
}
com.android.application与com.android.library无法共存,同一个Model只能存在一个。不同的Model可以相互使用implementation引入到Model中,使得Model里的方法可以相互调用。
创建配置共享文件
在Android项目中,每个Module都有自己的.gradle文件,Gradle是一个使用Groovy语言(核心代码是 Java )编写的构建工具,具体使用教程可参考:来自Gradle开发团队的Gradle入门教程
使用组件化的项目一般会有多个 Module ,为了使不同 Module 的版本库配置使用相同的参数,需要在项目根目录创建一个app_config.gradle,用以共享组件间相同的配置,避免过度碎片化。
app_config.gradle:ext {app_android = [compileSdk : 32,minSdk : 21,targetSdk : 32,versionCode: 1,versionName: "1.0"]
}
app_config.gradle 要想使其它 Module 都可以引用,需要在 Project 的 build.gradle 中对其进行全局引用。
apply from: 'app_config.gradle'
这样一来,所有 Module 的 build.gradle 就可以使用 app_config.gradle 的共享参数了
android {compileSdk app_android.compileSdkdefaultConfig {minSdk app_android.minSdktargetSdk app_android.targetSdkversionCode app_android.versionCodeversionName app_android.versionName}
}
打包模式配置
组件化的优点中有一个加快编译速度、提升开发效率的功能。
上面说到:在 Module 的 build.gradle 可以通过修改 application 或 library 控制当前组件为打包或集成模式。为了方便后续修改打包模式,app_config.gradle 增加了一个 isRelease 的打包配置参数。
ext {// 控制打包的模式isRelease = true
}
通过控制 isRelease 的布尔值,即可实现自动配置对应的 build.gradle 值,当然,前提是自动配置的代码提前写好。
// 公用的插件
plugins {id 'org.jetbrains.kotlin.android'
}
// 根据打包模式使用的插件
if (isRelease){apply plugin : 'com.android.library'
} else {apply plugin : 'com.android.application'
}
当模块处于打包模式时,为避免安装一次出现两个应用图标的问题,整个App工程的所有 AndroidManifest.xml 只能出现一个带android.intent.action.MAIN 的 intent-filter。
针对这种情况需要额外对不同打包模式下的 AndroidManifest.xml 文件做处理。
为此,我们可以在除主工程以外,需要在 debug 期间作为 application 工程独立运行项目的 build.gradle 文件添加以下配置。
android {// 源集 —— 用来设置Java目录或者资源目录sourceSets {main {if (!isRelease) {// 如果是组件化模式,需要单独运行时使用该文件manifest.srcFile 'src/main/debug/AndroidManifest.xml'} else {// 集成化模式,整个项目打包时使用该文件manifest.srcFile 'src/main/AndroidManifest.xml'java {// release 时 debug 目录下的Java文件不需要合并到主工程exclude '**/debug/**'}}}}
}
接着在main文件夹添加debug文件,将用到的 AndroidManifest.xml 文件放入里面,并将 src/main/AndroidManifest.xml 文件的配置设置为集成模式,可参考如下代码:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"><application><activityandroid:name=".MainActivity"android:exported="true" ></activity></application>
</manifest>
到这里基本上就结束了,更多的Android组件化进阶或者Android开发高级进阶学习,可以参考《Android核心技术手册》点击可以查看详细类目。