手写数字可视化
- 手写数字
- 流形学习
手写数字
手写数字无论是在数据可视化还是深度学习都是一个比较实用的案例。
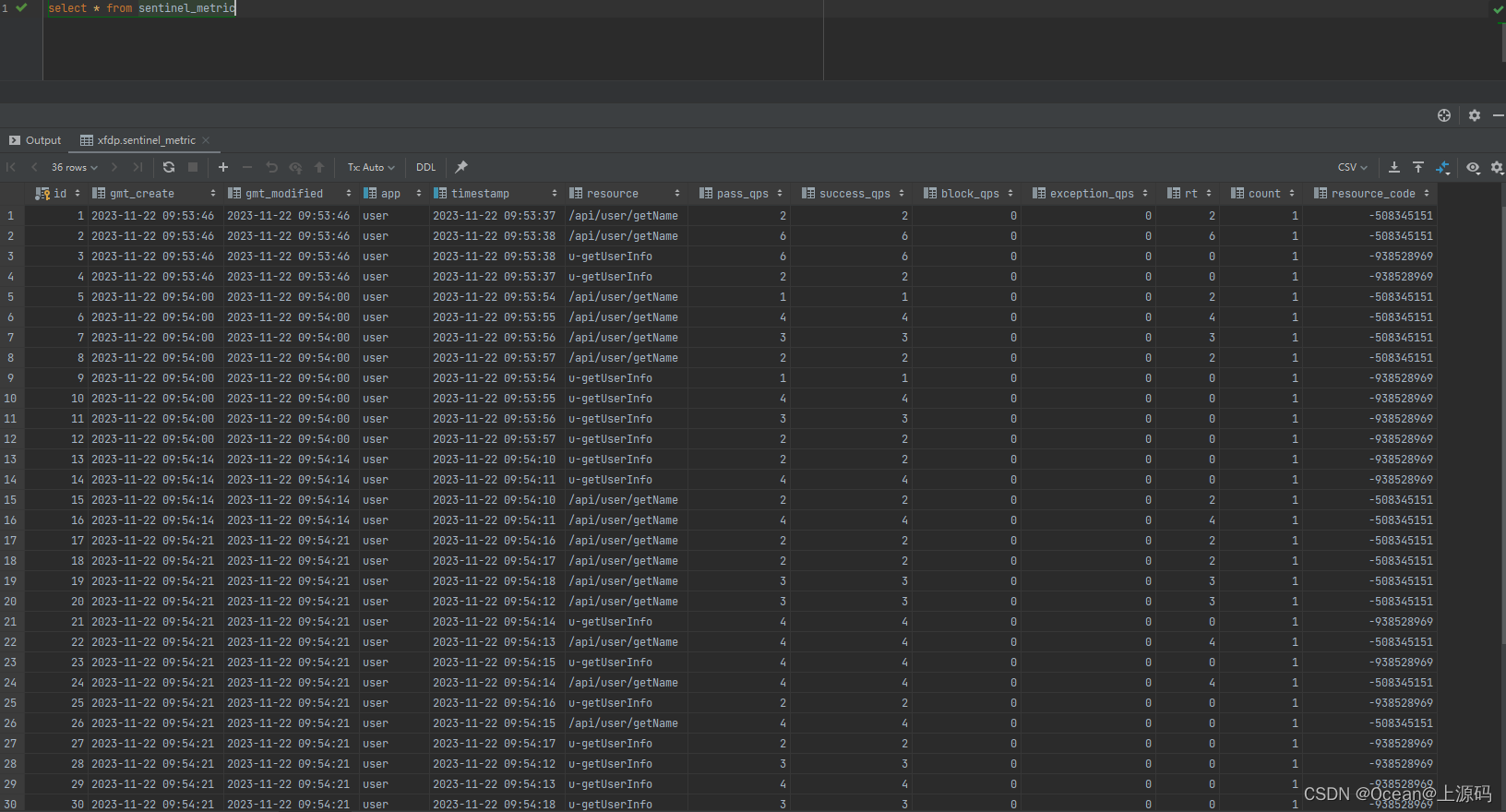
数据在sklearn中,包含近2000份8 x 8的手写数字缩略图。
首先需要先下载数据,然后使用plt.imshow()对一些图形进行可视化:
打开cmd命令窗口,输入pip install scikit-learn
(sklearn包被启用了,要用scikit-learn包)
然后在jupyter notebook中输入以下代码
from sklearn.datasets import load_digits
import matplotlib.pyplot as pltdigits = load_digits(n_class=6)
fig, ax = plt.subplots(8, 8, figsize=(6, 6))
for i, axi in enumerate(ax.flat):axi.imshow(digits.images[i], cmap='binary')axi.set(xticks=[], yticks=[])plt.show()输出图

总体

流形学习
由于每个数字都由64像素的色相构成,因此可以将每个数字看成是一个位于64维空间的点,即每个维度表示一个像素的亮度。但是想通过可视化来描述如此高维度的空间是非常困难的。
一种解决方案是通过降维技术,在尽量保留数据内部重要关联性的同时降低数据的维度,例如流形学习。
下面展示如何用流形学习将这些数据投影到二维空间进行可视化:
from sklearn.datasets import load_digits
from sklearn.manifold import Isomap
iso = Isomap(n_components=2)
digits = load_digits(n_class=6)
projection = iso.fit_transform(digits.data)
plt.scatter(projection[:, 0], projection[:, 1], lw=0.1,
c=digits.target, cmap=plt.cm.get_cmap('cubehelix', 6))
plt.colorbar(ticks=range(6), label='digit value')
plt.clim(-0.5, 5.5)
输出结果
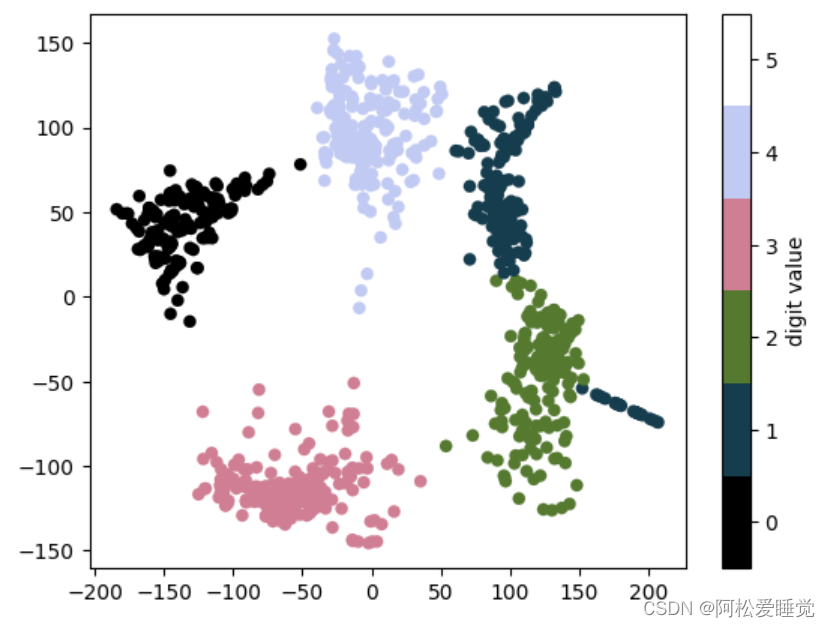
总体
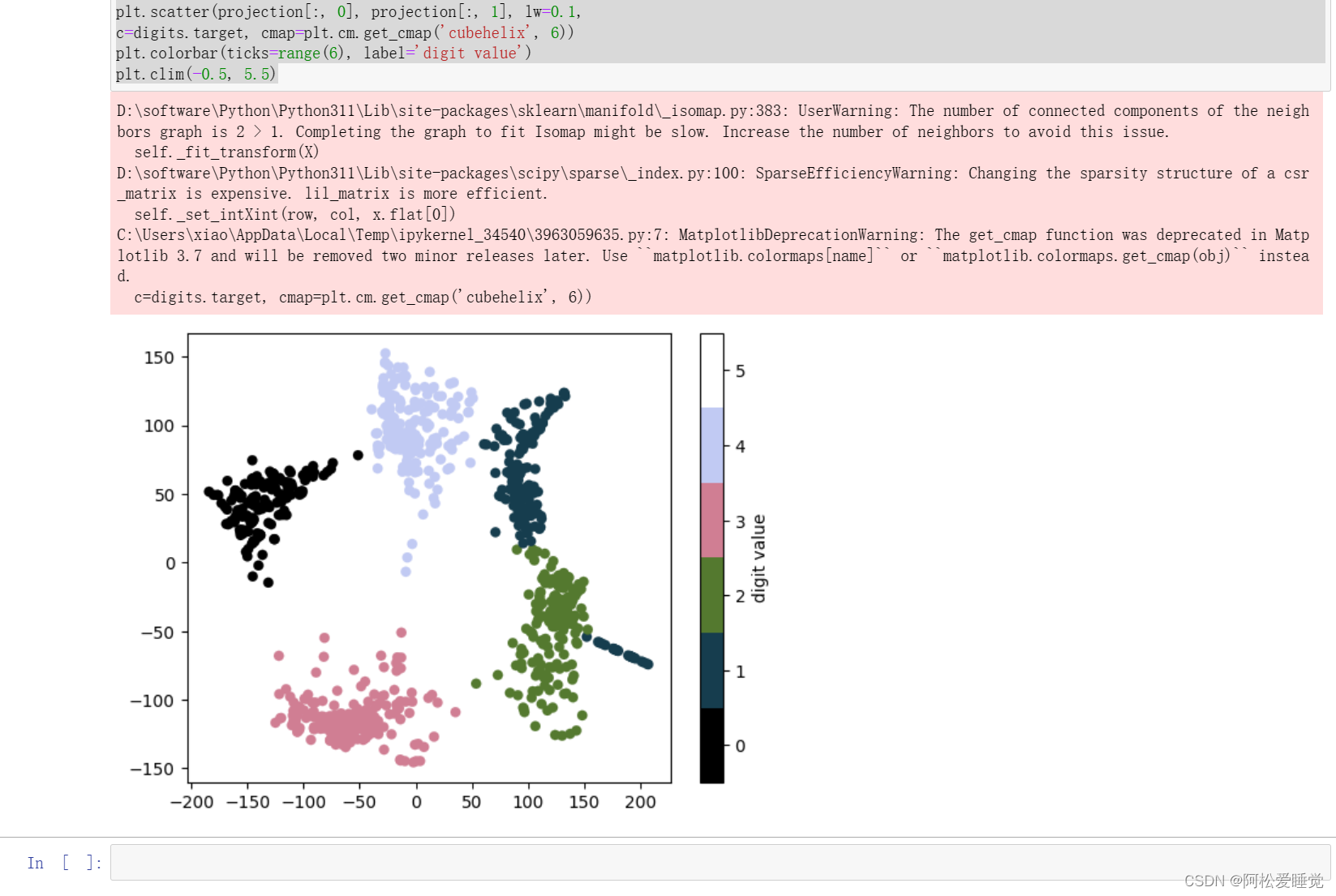
上面使用了离散型颜色条来显示结果,调整ticks和clim参数来改善颜色条。这个结果向我们展示了一些数据集的有趣特性。
例如数字5与数字3在投影中有大面积重叠,说明一些手写的5与3难以区分,因此自动分类算法也更容易搞混它们。其它的数字,像数字0与数字1,隔得特别远,说明两者不太可能出现混淆。