GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以找到关于GPT/AIGC/LLM最新的研究论文、博客文章、实用的工具和预设指令(Prompts)。现为了更好地知悉近一周的贡献内容,现总结如下。
Security Papers
1. 我们在使用大型语言模型进行漏洞检测方面已经走了多远
简介:研究者发现,通过对16个LLM和6个最先进的(SOTA)基于深度学习的模型和静态分析器的实验,发现了一些LLM在漏洞检测方面优于传统的深度学习方法,揭示了LLM尚未开发的潜力。这项工作有助于理解和利用LLM来增强软件安全性。
链接:
https://arxiv.org/pdf/2311.12420.pdf
2. 对日志分析、安全性和解释的大型语言模型进行基准测试
简介:研究者部署了60个用于日志分析的微调语言模型并进行基准测试。由此产生的模型表明,它们可用于有效地执行日志分析,其中微调对于对特定日志类型进行适当的域适应尤其重要。性能最佳的微调序列分类模型(DistilRoBERTa)优于当前最先进的技术;来自Web应用程序和系统日志源的六个数据集的平均F1分数为0.998。为了实现这一目标,研究者提出并实施了一个新的实验管道 (LLM4Sec),它利用LLM进行日志分析实验、评估和分析。
链接:
https://arxiv.org/pdf/2311.14519v1.pdf
3. 披着羊皮的狼:通用嵌套越狱提示可以轻松欺骗大型语言模型
简介:在本文中,研究者将越狱提示攻击概括为两个方面:(1)提示重写和(2)场景嵌套。基于此,研究者提出了ReNeLLM,一个利用LLM本身生成有效越狱提示的自动框架。大量实验表明,与现有基线相比,ReNeLLM显著提高了攻击成功率,同时大大降低了时间成本。研究者希望通过研究能够促进学术界和法学硕士供应商提供更安全、更规范的大型语言模型。
链接:
https://arxiv.org/pdf/2311.08268.pdf
4. 通过系统提示的自我对抗攻击越狱 GPT-4V
简介:现有的越狱多模态大型语言模型(MLLM)工作主要集中在模型输入中的对抗性示例,较少关注模型API中的漏洞。为了填补研究空白,研究者开展了一系列工作。结果表明,设计适当的系统提示可以显著降低越狱成功率。总的来说,研究者的工作为增强MLLM安全性提供了新的见解,展示了系统提示在越狱中的重要作用,可以利用它来极大地提高越狱成功率,同时也具有防御越狱的潜力。
链接:
https://arxiv.org/pdf/2311.09127.pdf
开源大模型
1. SecGPT网络安全大模型
简介:探索使用网络安全知识训练大模型,能够达到怎样的能力边界。
链接:
https://github.com/Clouditera/secgpt/tree/main
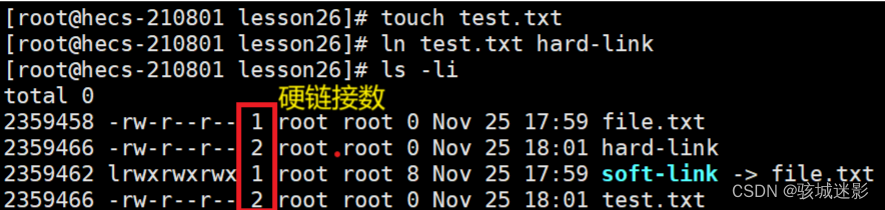

![web:[ZJCTF 2019]NiZhuanSiWei1](https://img-blog.csdnimg.cn/360a2fbfc1da43f5a7432d61805209b7.png)