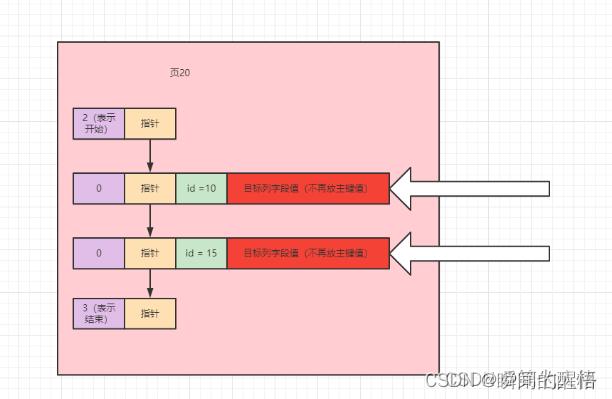
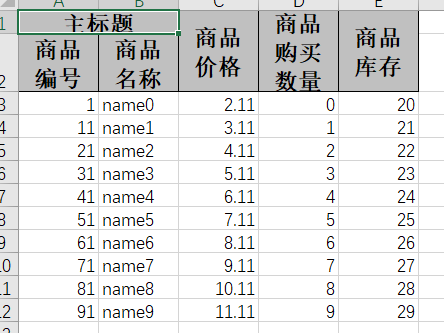
Redis 主从挂载后的内核数据结构分析
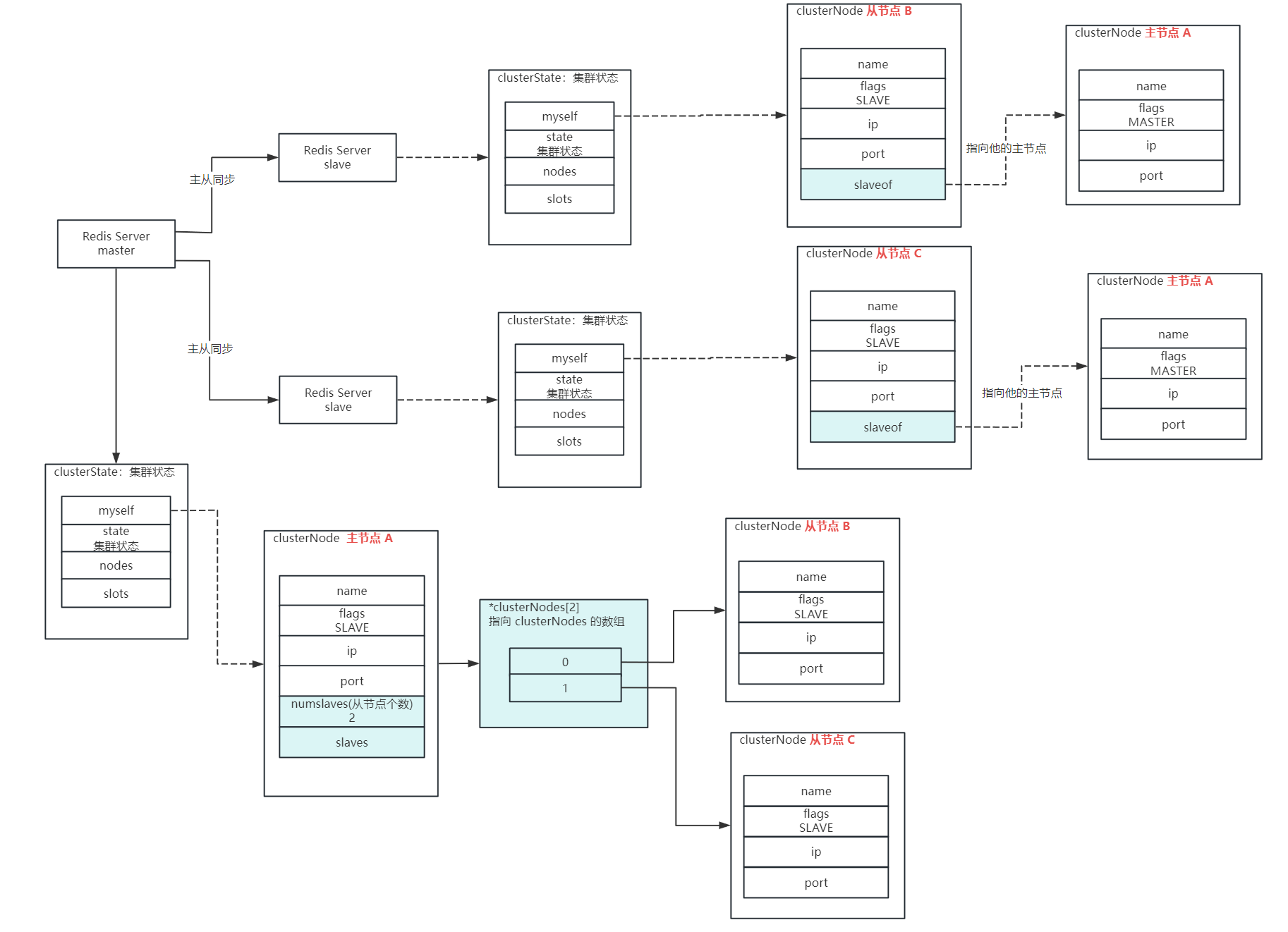
- 主节点中,会通过 clusteNode 中的
slaves来记录该主节点包含了哪些从节点,这个slaves是一个指向*clusterNode[]数组的数据结构 - 从节点中,会通过 clusterNode 中的
slaveof来记录该从节点属于哪个主节点,指向了主节点的 clusterNode
下图带颜色的为主从架构中的内核数据结构:
Redis SYNC 主从复制原理以及缺陷
Redis 的主从复制是在不断演进过程中的,那么主从复制的目的也就是将主节点上的数据传输给从节点
那么这个演进过程中的目的就是尽量加快主节点数据向从节点的同步速度
首先,需要考虑当从节点第一次连接上主节点后,如何同步主节点的数据呢?
其次要考虑如果从节点宕机或者重启之后,重新连接上主节点,此时又该如何同步主节点的数据呢?
从节点第一次连接上主节点,我们可以通过生成 RDB 快照,将数据全量同步给从节点,并将之后的命令通过缓冲区不断同步给从节点
如果从节点断线之后重连主节点,那么我们就要合理的设置缓冲区的大小,来保证尽量进行增量同步,而不是全量同步
因此主从复制演进过程中的目标就是能增量同步就增量同步,尽量避免全量同步
关于主从复制原理的演进过程以及百度智能云在主从复制上的优化实践,可以参考文章:Redis 主从复制原理以及痛点
Redis 定时 PING 与疑似下线分析
接下来我们来了解一下在 Redis 主从架构下,如何进行故障探测?
每个 redis 节点,都会定时发送 ping 消息给其他所有节点,探测其他节点是否存活,如果节点存活,则会返回 pong 消息,在规定时间没有收到 pong 消息的话,发送 ping 消息的节点就会将该节点标记为 pfail(疑似下线)
如果在集群中有半数以上的节点认为一个节点疑似下线,那么此时就可以将该节点标记为 fail(正式下线)
那么这就是故障探测的原理,就是通过 ping+pong 消息进行探测,当集群半数以上节点认为某个节点疑似下线,那么就将该节点标记为正式下线,并且将该节点正式下线的消息同步给其他所有节点
Redis 主节点选举算法以及故障转移
在 Redis 主从架构中,master 挂掉之后,该 master 下的 slave 会感知到主节点的下线状态,就会尝试向其他主节点发送投票请求,表示自己想要当 master 节点,那么其他 master 会投票给收到的第一个请求的 slave 节点
如果一个 slave 收到了半数以上 master 的投票,那么该 slave 就被选举成为了新的 master,他再去通知所有的节点,并且将之前下线的 master 的槽位转移到自己这里,之后所有的 slave 都从新的主节点中同步数据
那么这个主节点选举的流程原理可以参考文章:Redis切片集群以及主节点选举机制
总结
通过 Redis 深入理解,可以从总体上了解到 Redis 单体架构下,server 端是如何运行起来的,以及他是如何客户端建立连接并且接收客户端时间进行处理这样一个流程
以及在 Redis 集群模式下,Redis 主从节点的内核数据结构是怎样的,集群之间槽位的转移,集群节点之间通信,集群故障探测原理,主从同步数据原理以及主节点选举原理
如果需要进一步了解 Redis 内核,可以从以下几个方面入手:
- Redis 内核数据结构
- 持久化机制
- pub/sub、事务、lua、慢查询




![[带余除法寻找公共节点]二叉树](https://img-blog.csdnimg.cn/img_convert/40d54c205cdf778ec2b3fa27704219ff.png)