作者 | 刘耀辉
审稿 | BBuf、许啸宇
1
背景
近年来,量化感知训练是一个较为热点的问题,可以大大优化量化后训练造成精度损失的问题,使得训练过程更加高效。
Torch.fx在这一问题上走在了前列,使用纯Python语言实现了对于Torch.nn.Module的解析和向IR的转换,也可以提供变换后的IR对应的Python代码,在外部则是提供了简洁易用的API,大大方便了量化感知训练过程的搭建。此外,Torch.fx也有助于消除动态图和静态图之间的Gap,可以比较方便地对图进行操作以及进行算子融合。
OneFlow紧随其后添加了针对OneFlow的fx,即One-fx,在安装One-fx之后,用户可以直接调用oneflow.fx,也可以直接通过import onefx as fx进行使用。
one-fx地址:
https://github.com/Oneflow-Inc/one-fx
One-fx实现代码中绝大部分是对于Torch.fx的fork,但根据OneFlow和PyTorch之间存在的差别进行了一些适配或优化。本文将围绕One-fx适配方式以及在OneFlow中的应用展开。
2
FX主要模块
-
Symbolioc Trace
-
Graph Module
-
Interpreter
-
Proxy
-
Passes
其中,前4个模块共同实现了fx的基本功能,Graph Module和Proxy又是Symbolic Trace的基础,Passes则是在此基础上的扩充。
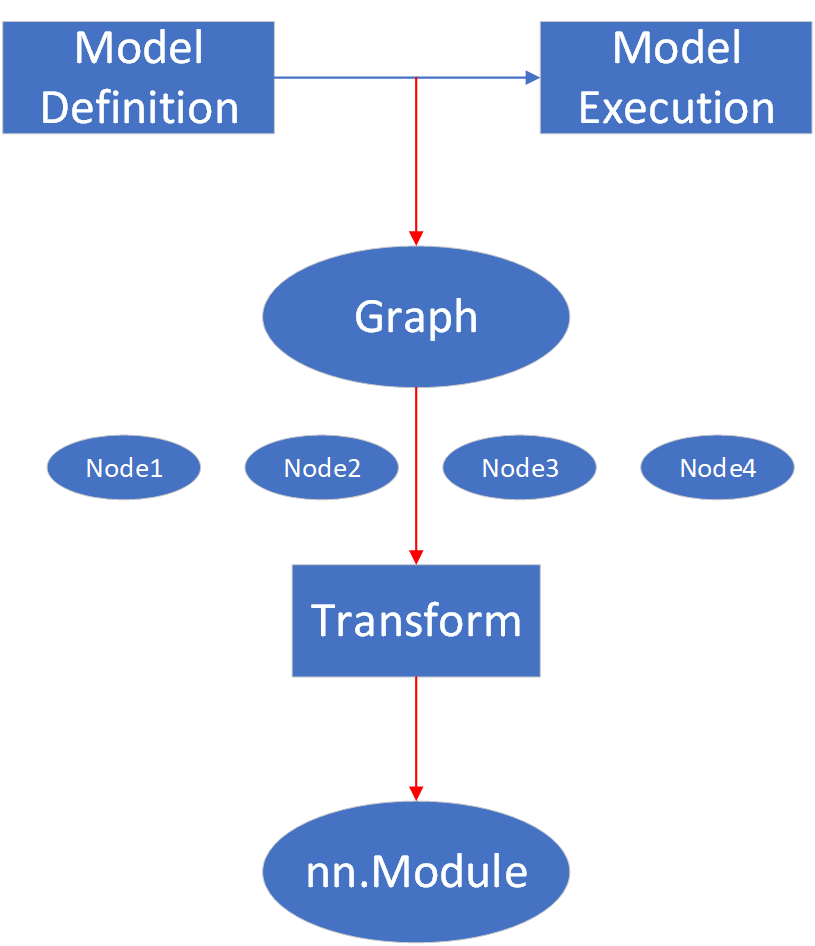
Symbolic Trace的基本概念如上图所示,最基本的模型运行过程就是从模型定义到模型执行这样一个流程。
fx则是进行了非侵入式的解析,将模型执行过程转成一张图,这张图中包含了很多个Node,每一个Node都包含了模型中的子模块或者函数调用信息,然后用户可以很方便地获取到所有的Node,并对其进行一些变换操作,最后通过GraphModule重新生成一个模型定义,并对其执行。
其中,在进行模型解析的时候,节点之间变量传递也均使用代理后的变量,如y = oneflow.relu(x),实际上x和y是Proxy(x)和Proxy(y)。
3
One-fx实现方式
这里给出一个Fx最简单的用例,以方便后续对于实现方式的介绍。
import oneflowclass MyModule(oneflow.nn.Module):def __init__(self):super().__init__()self.linear = oneflow.nn.Linear(512, 512)def forward(self, x):x = self.linear(x)y = oneflow.ones([2, 3])x = oneflow.relu(x)return ym = MyModule()traced = oneflow.fx.symbolic_trace(m)
print(traced.code)
"""
def forward(self, x):linear = self.linear(x); x = Nonerelu = oneflow.relu(linear); linear = None_tensor_constant0 = self._tensor_constant0return _tensor_constant0
"""函数代理
代理,即fx中的Proxy模块,目的是在每次进行函数或模块调用的时候添加一些额外操作,使得对模型的解析和重建得以进行,而包装则是适配代理的一种方式。
torch.fx中,对于nn.Module的包装比较易于理解,每当待解析Module中出现了继承自nn.Module的对象,那么就将其__call__函数替换成包装过的函数。然而,对于pytorch的函数的代理的实现要更“绕”一些,是借助了__torch_function__这一机制
(https://github.com/pytorch/pytorch/blob/c7c723897658eda6298bb74d92e4bb18ab4a5fe3/torch/overrides.py),限于篇幅原因这里不专门对其进行介绍。比较关键的点是,OneFlow中没有这一机制,如果需要添加,那么会是规模很大的、侵入性的,于是One-fx的实现就需要找其它路径。
我们使用的解决方式是搜索oneflow,oneflow.nn.functional,oneflow._C等模块中的Callable,并去除其中属于类的部分,然后对其余函数进行包装,在每次解析模型之前,会将这些模块的__dict__中对应项替换成包装后的函数,并且在解析模型之后重新将这些项进行还原。对于constructor类型的函数,如ones,randn等则不进行代理,直接运行,在最终构建图的时候作为constant来处理。
对于函数的包装部分源码实现如下,每次运行代理后的函数,会先判断该函数的入参中有没有Proxy变量,如果有,那么将会创建一个call_function类型的节点并返回Proxy包装后的节点,否则直接调用原函数并返回结果。
def _create_wrapped_func(orig_fn):@functools.wraps(orig_fn)def wrapped(*args, **kwargs):# 判断参数中是否存在proxy变量proxy = _find_proxy(args, kwargs)if proxy is not None:# 如果参数中有Proxy变量,创建节点并返回Proxy包装后的节点return_proxy = proxy.tracer.create_proxy("call_function", orig_fn, args, kwargs)return_proxy.node.meta["is_wrapped"] = Truereturn return_proxy# 如果没有Proxy变量,直接调用原函数return orig_fn(*args, **kwargs)return wrapped其中,return_proxy = proxy.tracer.create_proxy("call_function", orig_fn, args, kwargs)这行代码指定了使用与入参相同的Tracer来创建节点并返回结果,create_proxy函数定义的主要部分如下,创建节点并在Proxy包装后返回。
def create_proxy(self, kind: str, target: Target, args: Tuple[Any, ...], kwargs: Dict[str, Any],name: Optional[str] = None, type_expr : Optional[Any] = None,proxy_factory_fn: Callable[[Node], 'Proxy'] = None):args_ = self.create_arg(args)kwargs_ = self.create_arg(kwargs)assert isinstance(args_, tuple)assert isinstance(kwargs_, dict)# 创建节点node = self.create_node(kind, target, args_, kwargs_, name, type_expr)if not proxy_factory_fn:proxy = self.proxy(node)else:proxy = proxy_factory_fn(node)return proxy而其中的create_node方法,实际上是调用了Tracer.graph.create_node,在图中创建节点,主要部分代码如下,其中op就是fx IR中的op,代表了节点类型,而target则是节点的操作主体,在上面的例子中就是orig_func。
因此,当我们自定义的Module中的forward函数中的所有调用都被包装之后,实际上再运行forward的时候,就会依次在Tracer.graph中创建节点,这也正是symbolic_trace的基本思路。
def create_node(self, op: str, target: 'Target',args: Optional[Tuple['Argument', ...]] = None,kwargs: Optional[Dict[str, 'Argument']] = None,name: Optional[str] = None,type_expr: Optional[Any] = None) -> Node:# 此处有一些assert# 创建一个节点名称,避免重复candidate = name if name is not None else self._target_to_str(target)name = self._graph_namespace.create_name(candidate, None)# 创建节点n = Node(self, name, op, target, args, kwargs, type_expr)# 建立名称与节点的映射关系self._graph_namespace.associate_name_with_obj(name, n)return n而对于symbolic_trace过程,其核心就是Tracer.trace。这个方法可以分为两部分,一个是预处理部分,一个是主干部分。其中预处理过程大致定义如下,主要任务是初始化Graph、确立模型以及forward函数和创建包装后的参数。
如前面所提及的,symbolic trace的基本思路是借助Proxy变量以及包装后的函数,在每次调用的时候都创建一个节点,因此,forward函数的输入也需要用Proxy进行包装,这一步定义在Tracer.create_args_for_root中。
def trace(self,root: Union[oneflow.nn.Module, Callable[..., Any]],concrete_args: Optional[Dict[str, Any]] = None,) -> Graph:# 确定模块主体以及forward函数,其中fn即forward函数if isinstance(root, oneflow.nn.Module):self.root = rootassert hasattr(type(root), self.traced_func_name), f"traced_func_name={self.traced_func_name} doesn't exist in {type(root).__name__}"fn = getattr(type(root), self.traced_func_name)self.submodule_paths = {mod: name for name, mod in root.named_modules()}else:self.root = oneflow.nn.Module()fn = roottracer_cls: Optional[Type["Tracer"]] = getattr(self, "__class__", None)# 在Tracer中初始化一张图self.graph = Graph(tracer_cls=tracer_cls)self.tensor_attrs: Dict[oneflow.Tensor, str] = {}# 这个子函数用于收集模型中所有Tensor类型的变量def collect_tensor_attrs(m: oneflow.nn.Module, prefix_atoms: List[str]):for k, v in m.__dict__.items():if isinstance(v, oneflow.Tensor):self.tensor_attrs[v] = ".".join(prefix_atoms + [k])for k, v in m.named_children():collect_tensor_attrs(v, prefix_atoms + [k])collect_tensor_attrs(self.root, [])assert isinstance(fn, FunctionType)# 获取fn所在模块的所有可读变量fn_globals = fn.__globals__# 创建包装后的参数fn, args = self.create_args_for_root(fn, isinstance(root, oneflow.nn.Module), concrete_args)随后则是trace的主干部分,这一部分大致代码如下,主要任务是对函数、方法、模块进行必要的包装,然后在Graph中创建节点,完成整个图的信息。
其中,我们会创建一个Patcher环境并在其中进行这些过程,这是因为对于函数和方法的包装会直接改变掉某些包中对应函数或方法的行为,为了不让这种行为的改变溢出到trace的范围之外,在每次进行包装的时候会在Patcher中记录本次操作,然后在_Patcher.__exit__中根据记录的操作一一还原现场。
# 下面代码仍然是`trace`函数的一部分# 定义对于`nn.Module`的getattr方法的包装
@functools.wraps(_orig_module_getattr)
def module_getattr_wrapper(mod, attr):attr_val = _orig_module_getattr(mod, attr)return self.getattr(attr, attr_val, parameter_proxy_cache)# 定义对于`nn.Module`的forward方法的包装
@functools.wraps(_orig_module_call)
def module_call_wrapper(mod, *args, **kwargs):def forward(*args, **kwargs):return _orig_module_call(mod, *args, **kwargs)_autowrap_check(patcher,getattr(getattr(mod, "forward", mod), "__globals__", {}),self._autowrap_function_ids,)return self.call_module(mod, forward, args, kwargs)
# 这里Patcher的作用是在退出这一环境的时候恢复现场,避免包装函数、方法的影响溢出到`trace`之外。
with _Patcher() as patcher:# 对`__getattr__`和`nn.Module.__call__`这两个方法默认进行包装patcher.patch_method(oneflow.nn.Module,"__getattr__",module_getattr_wrapper,deduplicate=False,)patcher.patch_method(oneflow.nn.Module, "__call__", module_call_wrapper, deduplicate=False)# 对预定好需要进行包装的函数进行包装_patch_wrapped_functions(patcher)_autowrap_check(patcher, fn_globals, self._autowrap_function_ids)# 遍历所有需要对其中函数进行自动包装的packagefor module in self._autowrap_search:if module is oneflow:dict = {}# 当package为oneflow时,对此进行特殊处理,单独分出一个字典存放原本`oneflow.__dict__`中的内容for name, value in module.__dict__.items():if not isinstance(value, oneflow.nn.Module) and not value in _oneflow_no_wrapped_functions:dict[name] = value_autowrap_check_oneflow(patcher, dict, module.__dict__, self._autowrap_function_ids)else:_autowrap_check(patcher, module.__dict__, self._autowrap_function_ids)# 创建节点,这里的`create_node`调用实际上只是创建了最后一个节点,即输出节点。# 但是这里`fn`就是forward函数,在运行这一函数的时候,就会如前面所说依次创建节点。self.create_node("output","output",(self.create_arg(fn(*args)),),{},type_expr=fn.__annotations__.get("return", None),)其中,_patch_wrapped_functions的实现如下:
def _patch_wrapped_functions(patcher: _Patcher):# `_wrapped_fns_to_patch`中包含了所有需要自动包装的函数for frame_dict, name in _wrapped_fns_to_patch:if name not in frame_dict:if hasattr(builtins, name):# 对于built-in函数,不存在于frame_dict中,单独进行处理来根据名称获取函数本身orig_fn = getattr(builtins, name)else:# 如果是oneflow中指定需要包装的函数,那么就进行获取,否则抛出名称无法识别的异常is_oneflow_wrapped_function, func = is_oneflow_wrapped_function_and_try_get(name)if is_oneflow_wrapped_function:orig_fn = funcelse:raise NameError("Cannot deal with the function %s."%name)else:# 如果函数名称已经存在于frame_dict中,直接通过字典查询来获得函数orig_fn = frame_dict[name]# 创建包装后的函数并进行`patch`,即定义当trace过程结束的时候,如何还原现场patcher.patch(frame_dict, name, _create_wrapped_func(orig_fn))# 对于类中的方法,直接包装并patch。for cls, name in _wrapped_methods_to_patch:patcher.patch_method(cls, name, _create_wrapped_method(cls, name))
全局包装
在模型的forward函数中,我们有时不仅会用到框架自带的模块或者函数,有点时候还需要用到自定义的函数或者built-in函数,对于这种情况如果不进行处理,那么自然无法接受Proxy(x)的入参。fx中提供了fx.wrap这一API,当用户需要调用这部分函数的时候,可以实现使用fx.wrap(func)使其被包装。
例如:
import oneflowoneflow.fx.wrap(len)
class MyModule(oneflow.nn.Module):def __init__(self):super().__init__()self.linear = oneflow.nn.Linear(512, 512)def forward(self, x):x = self.linear(x) + len(x.shape)return xtraced = oneflow.fx.symbolic_trace(MyModule())
print(traced.code)
"""
def forward(self, x):linear = self.linear(x)getattr_1 = x.shape; x = Nonelen_1 = len(getattr_1); getattr_1 = Noneadd = linear + len_1; linear = len_1 = Nonereturn add
"""但是其局限性在于,如果Module的源代码是来自其它库,那么在调用的地方使用fx.wrap是不起作用的,在oneflow和torch中都会有这一问题。然而flowvision中有多处使用了built-in function,因此我们添加了一个API,即global_wrap,原理比较简单,就是直接对某个函数所在的包的__dict__进行修改,用法如下:
# MyModule来自其它包
with oneflow.fx.global_wrap(len):m = MyModule()traced = oneflow.fx.symbolic_trace(m)print(traced.code)"""def forward(self, x):linear = self.linear(x); x = Nonegetattr_1 = linear.shapelen_1 = len(getattr_1); getattr_1 = Nonerelu = oneflow.relu(linear); linear = Noneadd = relu + len_1; relu = len_1 = Nonereturn add"""使用with关键字的原因是这种实现方式是直接修改了某个包的__dict__,对于其它地方的调用也会产生影响,因此需要将其限制在一定范围内。此外,包装后的函数包含了对类型的判定等一系列操作,也会极大影响built-in函数的性能。
其它适配
其它地方的处理都比较简单,不需要对实现方式做修改,只需要将细节部分对齐即可,这也体现出oneflow和pytorch在前端部分的高度兼容性。
4
IR设计
fx的IR设计遵循以下几个原则:
-
避免支持长尾分布,复杂的样例。主要关注经典模型的程序捕获和变换。
-
使用机器学习从业者已经熟悉的工具和概念,例如Python的数据结构和 PyTorch 中公开记录的算子 。
-
使程序捕获过程具有高度可配置性,以便用户可以为长尾需求实现自己的解决方案。
fx的IR主要由几个部分组成;
-
opcode:即当前操作的类型,可以是placeholder, get_attr, call_function, call_method, call_module, output
-
name:即给当前操作的命名。
-
target:当前操作的实体,例如对于call_function类型的操作,可能这一属性会是
<built-in function len>
。
-
args和kwargs:指定当前操作的参数。
通过print_tabular这一API可以很方便美观地打印出fx中的IR,例如对于以下的MyModule模型,我们可以打印出其IR:
import oneflowclass MyModule(oneflow.nn.Module):def __init__(self, do_activation : bool = False):super().__init__()self.do_activation = do_activationself.linear = oneflow.nn.Linear(512, 512)def forward(self, x):x = self.linear(x)y = oneflow.ones([2, 3])x = oneflow.topk(x, 10)return x.relu() + ytraced = oneflow.fx.symbolic_trace(MyModule())
traced.graph.print_tabular()"""
opcode name target args kwargs
------------- ----------------- ------------------------ ------------------------- --------
placeholder x x () {}
call_module linear linear (x,) {}
call_function topk <built-in function topk> (linear, 10) {}
call_method relu relu (topk,) {}
get_attr _tensor_constant0 _tensor_constant0 () {}
call_function add <built-in function add> (relu, _tensor_constant0) {}
output output output (add,) {}
"""尽管fx的IR不算强大(例如不能处理动态控制流),但是定义非常简洁,实现简单,对于用户来讲上手门槛相对低很多。
5
One-fx应用举例
OP替换
下面的例子展示了如何将add操作全部替换成mul操作。
import oneflow
from oneflow.fx import symbolic_trace
import operatorclass M(oneflow.nn.Module):def forward(self, x, y):return x + y, oneflow.add(x, y), x.add(y)if __name__ == '__main__':traced = symbolic_trace(M())patterns = set([operator.add, oneflow.add, "add"])for n in traced.graph.nodes:if any(n.target == pattern for pattern in patterns):with traced.graph.inserting_after(n):new_node = traced.graph.call_function(oneflow.mul, n.args, n.kwargs)n.replace_all_uses_with(new_node)traced.graph.erase_node(n)traced.recompile()traced.graph.print_tabular()print(traced.code)
性能分析
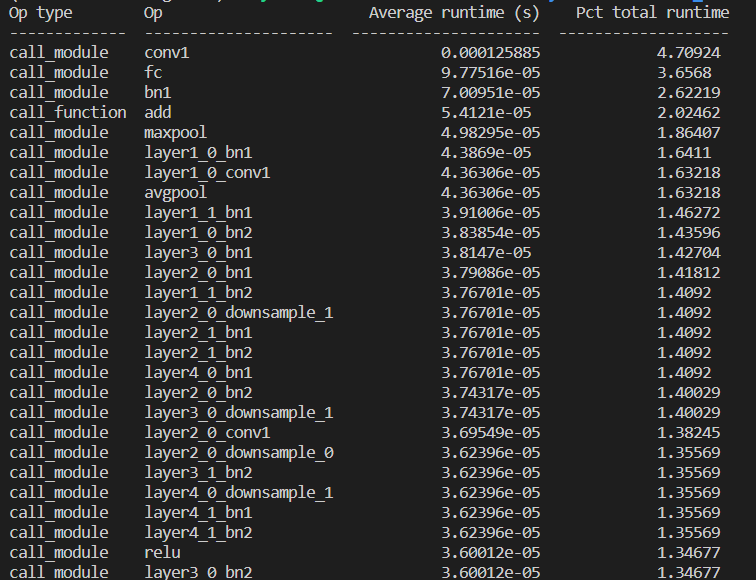
以下代码展示如何使用fx进行模型的性能分析,将原本的模型通过symbolic_trace解析成各个节点,再在其中插入测试性能的操作。
import oneflow
import flowvision.models as models
import statistics, tabulate, time
from typing import Any, Dict, Listclass ProfilingInterpreter(oneflow.fx.Interpreter):def __init__(self, mod : oneflow.nn.Module):gm = oneflow.fx.symbolic_trace(mod)super().__init__(gm)# 记录总运行时间self.total_runtime_sec : List[float] = []# 记录各个节点运行时间self.runtimes_sec : Dict[oneflow.fx.Node, List[float]] = {}# 重写`run`方法,本质上是对基类`run`方法的简单封装,在运行前后记录时间点。# 这一方法是Graph整体运行的入口。def run(self, *args) -> Any:t_start = time.time()return_val = super().run(*args)t_end = time.time()self.total_runtime_sec.append(t_end - t_start)return return_val# 同上,重写`run_node`方法,不需要自己写细节实现,只需要在对基类的`run_node`调用前后记录时间点即可# 这一方法是Graph中运行每个Node的入口。def run_node(self, n : oneflow.fx.Node) -> Any:t_start = time.time()return_val = super().run_node(n)t_end = time.time()self.runtimes_sec.setdefault(n, [])self.runtimes_sec[n].append(t_end - t_start)return return_val# 定义如何打印性能测试结果def summary(self, should_sort : bool = False) -> str:# 存储每个节点的打印信息node_summaries : List[List[Any]] = []# 由于模块会被调用多次,所以这里计算一下平均的运行总时长mean_total_runtime = statistics.mean(self.total_runtime_sec)for node, runtimes in self.runtimes_sec.items():mean_runtime = statistics.mean(runtimes)# 计算节点运行时间占总时间的比例pct_total = mean_runtime / mean_total_runtime * 100# 记录节点信息、节点平均运行时长和节点运行时间占总时间的比例node_summaries.append([node.op, str(node), mean_runtime, pct_total])# 如果需要,安按照运行时间进行排序if should_sort:node_summaries.sort(key=lambda s: s[2], reverse=True)# 以下是借助tabulate库进行格式化来美化显示效果headers : List[str] = ['Op type', 'Op', 'Average runtime (s)', 'Pct total runtime']return tabulate.tabulate(node_summaries, headers=headers)if __name__ == '__main__':rn18 = models.resnet18()rn18.eval()input = oneflow.randn(5, 3, 224, 224)output = rn18(input)interp = ProfilingInterpreter(rn18)interp.run(input)print(interp.summary(True))效果如下:
算子融合
以下代码演示如何借助fx将模型中的卷积层和BN层进行融合,对于这种组合,并不需要引入新的算子,只需要对原本conv的权重进行操作即可。可以参考:https://nenadmarkus.com/p/fusing-batchnorm-and-conv/。
import sys
import oneflow
import oneflow.nn as nn
import numpy as np
import copy
from typing import Dict, Any, Tuple# 通过直接对权重进行运算的方式进行Conv和BN的融合
def fuse_conv_bn_eval(conv, bn):assert(not (conv.training or bn.training)), "Fusion only for eval!"fused_conv = copy.deepcopy(conv)fused_conv.weight, fused_conv.bias = \fuse_conv_bn_weights(fused_conv.weight, fused_conv.bias,bn.running_mean, bn.running_var, bn.eps, bn.weight, bn.bias)return fused_conv# 权重融合方式
def fuse_conv_bn_weights(conv_w, conv_b, bn_rm, bn_rv, bn_eps, bn_w, bn_b):if conv_b is None:conv_b = oneflow.zeros_like(bn_rm)if bn_w is None:bn_w = oneflow.ones_like(bn_rm)if bn_b is None:bn_b = oneflow.zeros_like(bn_rm)bn_var_rsqrt = oneflow.rsqrt(bn_rv + bn_eps)conv_w = conv_w * (bn_w * bn_var_rsqrt).reshape([-1] + [1] * (len(conv_w.shape) - 1))conv_b = (conv_b - bn_rm) * bn_var_rsqrt * bn_w + bn_breturn oneflow.nn.Parameter(conv_w), oneflow.nn.Parameter(conv_b)# 根据字符串对名称进行分割,比如`foo.bar.baz` -> (`foo.bar`, `baz`)
def _parent_name(target : str) -> Tuple[str, str]:*parent, name = target.rsplit('.', 1)return parent[0] if parent else '', namedef replace_node_module(node: oneflow.fx.Node, modules: Dict[str, Any], new_module: oneflow.nn.Module):assert(isinstance(node.target, str))parent_name, name = _parent_name(node.target)setattr(modules[parent_name], name, new_module)# 定义对模型进行融合操作的过程
def fuse(model: oneflow.nn.Module) -> oneflow.nn.Module:model = copy.deepcopy(model)# 先通过fx.symbolic_trace获取一个GraphModulefx_model: oneflow.fx.GraphModule = oneflow.fx.symbolic_trace(model)modules = dict(fx_model.named_modules())# 遍历GraphModule中的所有节点,分别进行操作for node in fx_model.graph.nodes:# 跳过所有不是module的节点if node.op != 'call_module':continue# 检测到conv+bn的结构后进行融合操作if type(modules[node.target]) is nn.BatchNorm2d and type(modules[node.args[0].target]) is nn.Conv2d:# conv的输出同时被其它节点使用,即conv后连接两个节点时无法融合if len(node.args[0].users) > 1:continueconv = modules[node.args[0].target]bn = modules[node.target]fused_conv = fuse_conv_bn_eval(conv, bn)replace_node_module(node.args[0], modules, fused_conv)# 对图中的边进行置换,对于用到bn输出的节点,要更改它们的输入node.replace_all_uses_with(node.args[0])# 移除旧的节点fx_model.graph.erase_node(node)fx_model.graph.lint()# 重新建图(构造模型)fx_model.recompile()return fx_modelif __name__ == '__main__':# 以下引入flowvision中的resnet 18模型,并进行融合前后的benchmark比较import flowvision.models as modelsimport timern18 = models.resnet18().cuda()rn18.eval()inp = oneflow.randn(10, 3, 224, 224).cuda()output = rn18(inp)def benchmark(model, iters=20):for _ in range(10):model(inp)oneflow.cuda.synchronize()begin = time.time()for _ in range(iters):model(inp)return str(time.time()-begin)fused_rn18 = fuse(rn18)unfused_time = benchmark(rn18)fused_time = benchmark(fused_rn18)print("Unfused time: ", benchmark(rn18))print("Fused time: ", benchmark(fused_rn18))assert unfused_time > fused_time6
未来计划
-
基于fx进行8bit量化感知训练和部署
-
基于fx进行算子融合
-
eager模式下基于fx获得模型更精确的FLOPs和MACs结果
参考文献
1.https://pytorch.org/docs/stable/fx.html
2.https://github.com/Oneflow-Inc/one-fx
3.https://pytorch.org/tutorials/intermediate/fx_conv_bn_fuser.html
4.https://pytorch.org/tutorials/intermediate/fx_profiling_tutorial.html
5.https://zhuanlan.zhihu.com/p/449908382
其他人都在看
-
深度学习框架量化感知训练的思考
-
GPT-3/ChatGPT复现的经验教训
-
超越ChatGPT:大模型的智能极限
-
Jasper狂飙:AIGC现象级应用的增长秘笈
-
比快更快,开源Stable Diffusion刷新作图速度
-
OneEmbedding:单卡训练TB级推荐模型不是梦
-
GLM训练加速:性能最高提升3倍,显存节省1/3
欢迎Star、试用OneFlow最新版本:GitHub - Oneflow-Inc/oneflow: OneFlow is a deep learning framework designed to be user-friendly, scalable and efficient.OneFlow is a deep learning framework designed to be user-friendly, scalable and efficient. - GitHub - Oneflow-Inc/oneflow: OneFlow is a deep learning framework designed to be user-friendly, scalable and efficient. https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/