1 赛题
问题A 采果机器人的图像识别技术
中国是世界上最大的苹果生产国,年产量约为3500万吨。与此同时,中国也是世 界上最大的苹果出口国,全球每两个苹果中就有一个,全球超过六分之一的苹果出口 自中国。中国提出了一带一路倡议(BRI),这是建立一个具有共同未来的全球社区的 关键支柱。由于这一倡议,越南、孟加拉国、菲律宾、印度尼西亚和沿线国家已成为
中国苹果的主要出口目的地。

图1。采采摘机器人的苹果图像识别图。
苹果的采摘主要依靠手工收割。当苹果成熟时,几天内苹果产区就需要大量的采 摘工人。但大多数当地农民都在自己的果园里种植苹果。此外,农业工人的老龄化和 年轻人离开村庄去上班的现象也导致了摘苹果季节的劳动力短缺。为了解决这个问题
, 中国自2011年左右就开始一直在研究能摘苹果的机器人,并取得了重大进展。
然而,由于果园环境不同于控制实验,在世界范围内各种采苹果机器人的普及和
应用还不够理想
镶嵌在复杂和非结构化的果园环境中,大多数现有的机器人无法准确识别“如叶遮挡 ”、“树枝遮挡 ”、“果实遮挡 ”、“混合遮挡 ”等障碍。如果直接摘苹果而没有根据 实际情况做出精确的判断,就有很高的危害风险,甚至对摘手和机械臂造成伤害。这将 对收获的效率和果实的质量产生不利影响,导致更大的损失。此外,对不同收获果实的 识别和分类也非常重要,如分类、加工、包装和运输的程序。然而,许多水果的颜色、
形状和大小与苹果非常相似,这给收获后的鉴定带来了很大的困难。
这个比赛旨在建立一个苹果图像识别模型与识别率高,速度快,和准确性通过分 析和提取特征标记水果图像,并执行数据分析图像,如自动计算数量,位置,成熟度
水平,估计大量的苹果的图像。具体任务如下:
问题1:计算苹果的数量
基于附件1中提供的可收获苹果的图像数据集,提取图像特征,建立数学模型,计算每幅图像中的苹果的数量,并绘制附件1中所有苹果的分布直方图。
问题2:估计苹果的位置
根据附件1中提供的可收获苹果的图像数据集,以图像左下角为坐标原点,确定每个图像中苹果的位置,并绘制附件1中所有苹果几何坐标的二维散点图。
问题3:估计苹果的成熟度状态
基于附件1中提供的可收获苹果的图像数据集,建立数学模型,计算每幅图像中苹果的成熟度,并绘制附件1中所有苹果成熟度分布的直方图。
问题4:估计苹果的数量
根据附件1中提供的可收获苹果的图像数据集,计算出每幅图像中苹果的二维面积, 图像的左下角为根据坐标原点,估计苹果的质量,并绘制出附件1中所有苹果的质量分布的直方图。
问题5:对苹果的认可
基于附件2中提供的收获果实图像数据集,提取图像特征,训练苹果识别模型,对
附件3中的苹果进行识别,并绘制附件3中所有苹果图像ID号的分布直方图。
附件:
附件。请下载到网站: https://share。魏云。com/T6FKbjLf
附件1:
该文件夹包含200张可收获苹果的图片,每张图片的大小为270 * 180像素。附件1
的部分屏幕截图如下:

附件2:
该文件夹包含20705张已知标签和分类的不同收获水果的图像,每张图像的大小为
270 * 180像素。附件2的部分屏幕截图如下:
苹果数据集:

卡兰博拉斯的数据集:

梨的数据集:

李子数据集:

番茄数据集:

附件3:
该文件夹包含20705张不同收获果实的图像,其标签和分类未知,每张图像的大小
为270 * 180像素。附件3的部分屏幕截图如下:

2 思路更新
数据准备
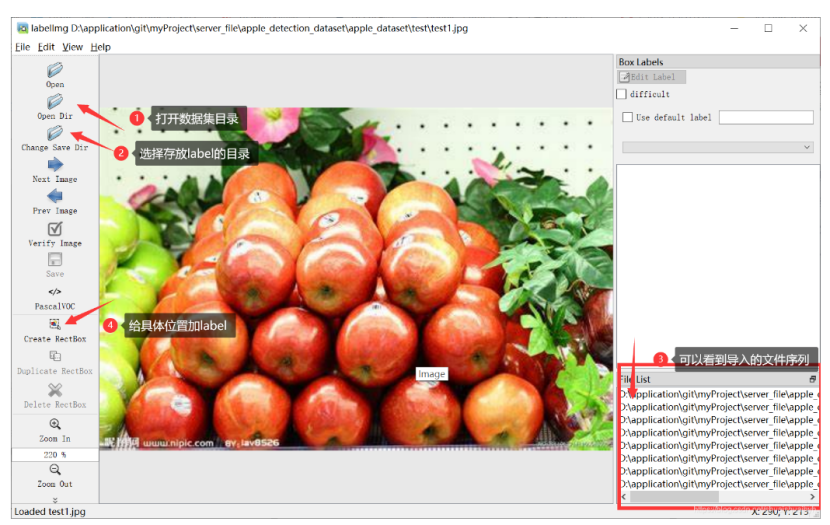
跑模型首先得有数据集,或者自己标注数据(A君会提供数据集给大家)
训练结果
识别结果

第二问,最后把检测到的苹果目标中心点汇集起来,用python画图就行
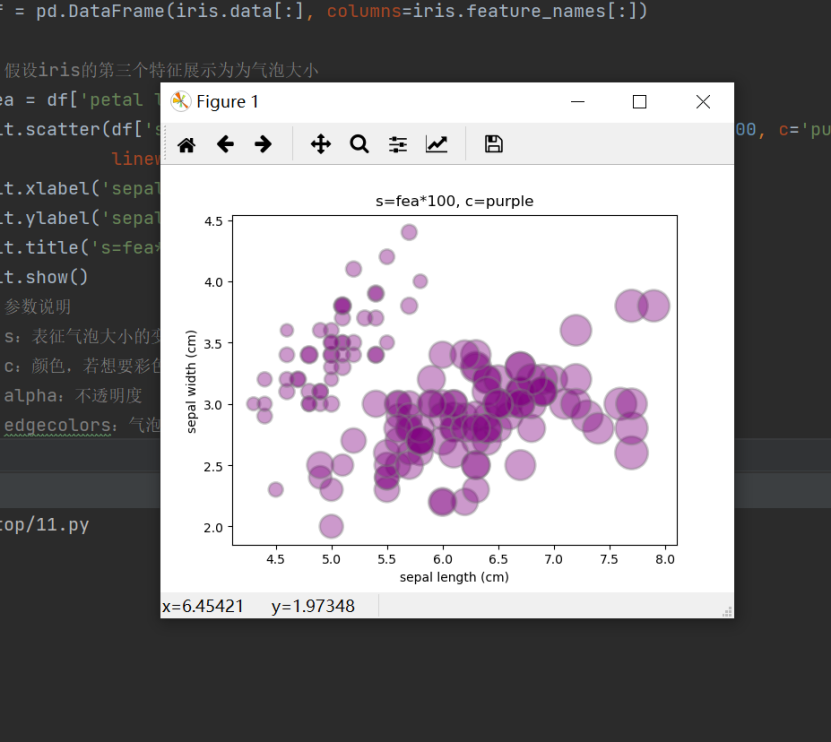
A题思路更新,大家注意一个问题,题目给的数据并不是可以直接用来做苹果目标检测训练的数据,训练数据得自己标注或者找数据集,题目的算是验证数据,基础差的同学容易混淆这点,A君上传了目标检测数据给大家使用。
第二次更新:详细思路全更新
1 2 问我们做出了苹果端到端目标检测,但是我们无法分辨好苹果还是烂苹果。所以这一步我们需要做一个苹果图像的特征提取器,提取了特征之后,只要对特征进行分类就能识别好苹果还是烂苹果。
这时候我们需要把目标检测的结果保存到本地,手动的分类出好苹果和差苹果,或者你想细分,分成N个类别都可以。
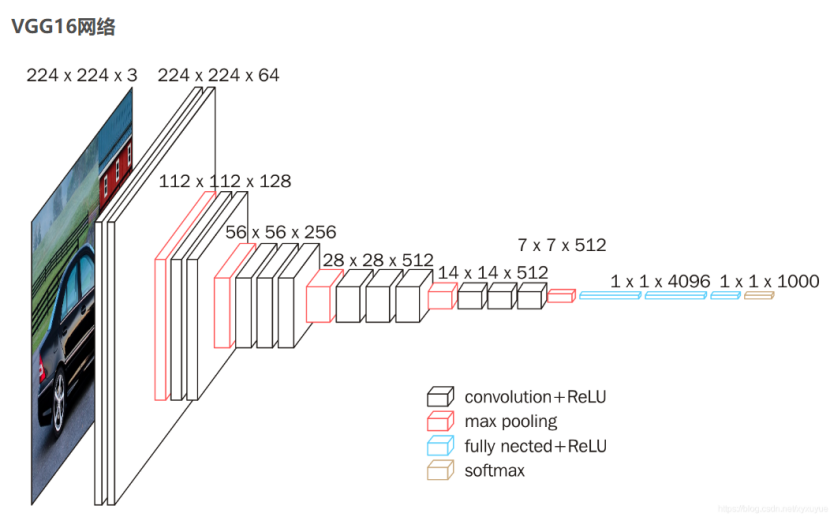
接下来,选择一深度学习特征提取网络,这里A君推荐大家使用vgg16, 或者MobileNet网络。
完整内容放在文档中,自取即可