1. 性能:
lxml 通常比 xml.etree.ElementTree 更快。lxml 使用了 C 编写的底层解析器,因此在处理大型 XML 文档时可能更高效。
如果性能对你的应用很重要,特别是在处理大型 XML 文件时,选择 lxml 可能是一个更好的选择。2. 功能和灵活性:
lxml 提供了更多的功能和更灵活的 API,包括支持 XPath、XSLT 转换、XML Schema 验证等。
xml.etree.ElementTree 是 Python 的标准库的一部分,它提供了一组基本的 XML 处理工具,可以满足一般需求,但功能相对较简单。3. 标准库 vs. 第三方库:
xml.etree.ElementTree 是 Python 的标准库的一部分,因此无需安装额外的库。这可能使得它更方便在没有额外依赖的环境中使用。
lxml 是一个第三方库,需要安装。在许多项目中,特别是涉及到网络请求和外部库的项目中,这可能是个小小的考虑因素。4. API 的易用性:
xml.etree.ElementTree 提供了一个相对简单、易于学习和使用的 API。对于一些简单的 XML 处理任务,它可能足够了。
lxml 提供了更多的高级功能,但相应地也有更多的学习曲线。如果你不需要这些高级功能,可能会觉得 xml.etree.ElementTree 更轻量。
XPath 是一种用于在 XML 文档中定位元素的语言,而 lxml 是 Python 中一个常用的 XML 处理库,它使用 XPath 作为其中一种元素选择的方式。因此,XPath 表达式是一种通用的语言概念,它独立于任何具体的编程语言。在使用 lxml 这个库时,你会使用 XPath 表达式来选择 XML 文档中的元素
- tree.findall(“.ip”) 和 tree.xpath() 这两个函数的区别是
注意:
1. findall 方法用于查找当前元素的所有匹配子元素,
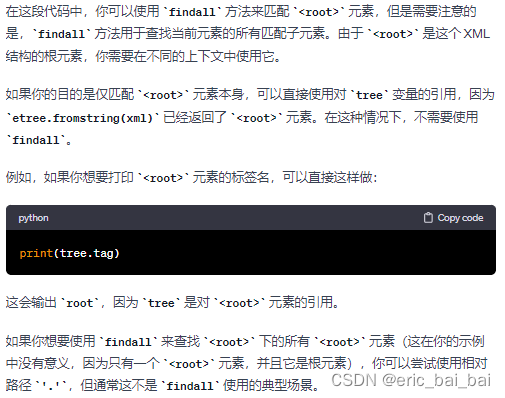
2. 如果你的目的是仅匹配 元素本身,可以直接使用对 tree 变量的引用,因为 etree.fromstring(xml) 已经返回了 元素。在这种情况下,不需要使用 findall。
3. 使用etree.fromstring构造文档树以后, 返回的就是树的根节点的引用, findall方法也是从当前节点开始查找,如果从 / 开始查找就会报错: SyntaxError: cannot use absolute path on element
4. tree.xpath 和 tree.findall 都支持xpath表达式,但是在findall方法中,xpath表达式不能以 / 根路径开始
1. findall 是 lxml 库的方法,用于查找所有匹配指定元素名称的子元素。
它接受一个简单的元素名称作为参数,例如 .findall('.//element'),这里的 .//element 表示查找所有名称为 element 的元素,无论它们在文档的哪个位置。
返回的是一个元素列表。2. xpath 方法是更强大的查询方法,使用 XPath 表达式来描述查询条件,因此更为灵活。
它接受一个 XPath 表达式作为参数,例如 .xpath('//element1'),这里的 //element1 表示查找文档中所有名称为 element1 的元素,无论它们在文档的哪个位置。
返回的同样是一个元素列表
lxml 中的 ElementTree 对象(通常通过 etree.fromstring() 或 etree.parse() 创建)有一些常用的方法和属性,以下是其中一些常见的 API:
1. Element 元素对象的方法和属性【tree本身就是元素对象,对应根元素】:tag: 返回元素的标签名称。
text: 返回元素的文本内容。
attrib: 返回一个包含元素所有属性的字典。
get('attribute_name'): 获取指定属性的值。
set('attribute_name', 'value'): 设置指定属性的值。
clear(): 清除元素的内容。2. 新建ElementTree 对象的方法:
etree.fromstring(xml_string): 从字符串中解析 XML 并返回 Element 对象。
etree.parse(file_path): 从文件中解析 XML 并返回 ElementTree 对象。eg: html = etree.parse(StringIO(test_html))3. XPath 相关的方法, tree.xx:
xpath(xpath_expression): 使用 XPath 表达式查询匹配的元素,返回元素列表。
find(xpath_expression): 查找匹配的第一个元素并返回,如果没有匹配的则返回 None。
findall(xpath_expression): 查找匹配的所有元素并返回列表。
iterfind(xpath_expression): 返回一个迭代器,用于按需查找匹配的元素。4. from lxml import etree,etree的相关方法
etree.tostring(element): 将 Element 对象转换为字符串 # etree.tostring(tree).decode()
etree.fromstring: 将字符串转换成 Element对象 # etree.fromstring(xml, parser=etree.XMLParser(huge_tree=True))
ips = tree.findall(".ip")
dhcp_range = tree.xpath("./ip[not(@family='ipv6')]/dhcp/range")
tree.xpath("./ip[@family='ipv6']/dhcp/range")
tree.xpath("/network/bandwidth")
tree.append(etree.fromstring(xml))
tree.xpath(f"/network/bandwidth/{direction}"):
tree.xpath("/domain/vcpus/vcpu")
tree.xpath("./devices/disk/target[@dev='{}']".format(target_dev))[0].getparent()
xml_disk = etree.tostring(disk_el).decode()
tree.set("secure", "ssss")
html = etree.parse(StringIO(test_html))
diskTree = doc.findall(f".//source[@file='{diskPath}']/..")[0]
diskTree2 = doc.xpath(f"//source[@file='{diskPath}']/..")
def get_xml_path(xml, path=None, func=None):doc_tree = etree.fromstring(xml, parser=etree.XMLParser(huge_tree=True))if path:result = get_xpath(doc_tree, path)elif func:result = func(doc_tree)else:raise ValueError("'path' or 'func' is required.")return resultdef get_xpath(doc_tree, path):result = Noneret = doc_tree.xpath(path)if ret is not None:if isinstance(ret, list):if len(ret) >= 1:if hasattr(ret[0], "text"):result = ret[0].textelse:result = ret[0]else:result = retreturn result
from lxml import etreexml = """
<root><ip>192.168.1.1</ip><ip>192.168.1.2</ip><ip>192.168.1.3</ip>
</root>
"""tree = etree.fromstring(xml)# 使用相对路径
ips = tree.findall(".//ip")for ip_element in ips:print(ip_element.text)








![[英语学习][6][Word Power Made Easy]的精读与翻译优化](https://img-blog.csdnimg.cn/direct/16c48dd5b27045869c59ac0c3d73561e.jpeg)