一、什么是3D语义场景补全?
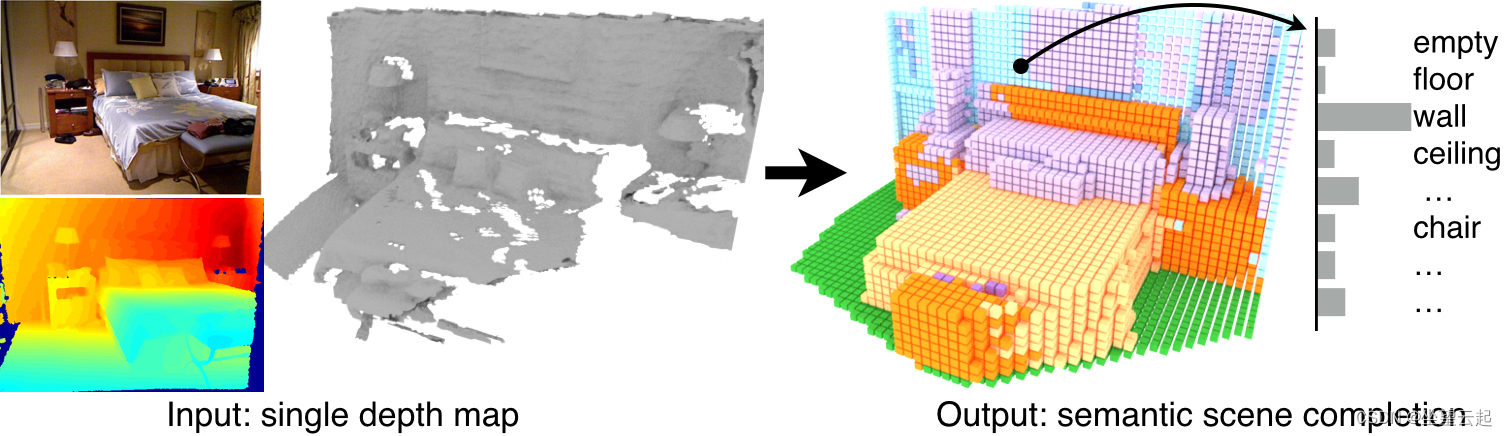
3D 语义场景完成(Semantic Scene Completion)是一种机器学习任务,涉及以体素化形式预测给定环境的完整3D场景(完成3D形状的同时推断场景的 3D 语义分割的任务)。这是通过使用深度图和为场景提供上下文的可选 RGB 图像来完成的。目标是以一种可轻松用于各种应用的方式提供环境的准确表示。
这项任务的关键是场景的语义方面。输出中的每个体素代表环境中的某个物体或障碍物,例如墙壁、椅子或人。这使得场景易于理解并在各种应用中使用。
二、3D语义场景补全的应用
3D 语义场景补全在机器人、增强现实和自动驾驶等领域具有许多潜在应用。在机器人技术中,完成的场景可用于规划机器人在环境中的路径和动作。例如,机器人可能需要在杂乱的房间中找到一条路径,同时避开家具和人等障碍物。
在增强现实中,完成的场景可以叠加到现实世界上,为用户提供更加身临其境的体验。这可用于室内设计等应用,用户可以在其中看到家具和装饰品在自己家中的外观。
在自动驾驶中,完整的场景可用于帮助车辆在复杂的环境中导航。这可能包括识别行人和其他车辆等障碍物,以及检测道路状况的变化并识别停车标志和交通灯等地标