2022 IEEE TRANSACTIONS ON MULTIMEDIA
领域:异常检测
目标:图像输入数据
文章目录
- 1、模型
- 2、方法
- 2.1、random masking
- 2.2、restoration network
- 2.3、损失函数
- 2.4、推理时的渐进细化
- 3、实验
- 4、引用
- 5、想法
1、模型
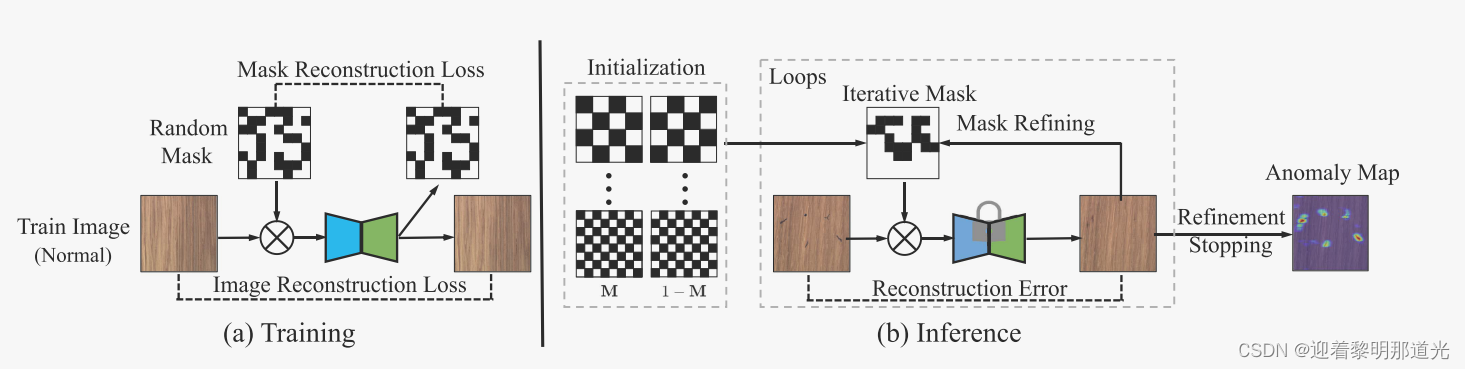
训练: 每个图像实时生成随机的掩码,然后将掩码输入到具有两个预测头的条件自动编码器,一个用于重建图像,一个用于重建掩码。通过随机掩码,每个图像都被增强为不同的训练三元组<增加掩码的图片,掩码,原始图片>。使得自动编码器能够学习使用各种形状的掩码进行重建。
推理: 提出新的渐进掩码细化方法。一组互补的掩码作为初始化掩码。然后基于重建误差,掩码被迭代的细化并收缩到可能的异常区域。同时使用多个尺度的初始掩码进行掩码细化,并使用他们的集合来检测异常。
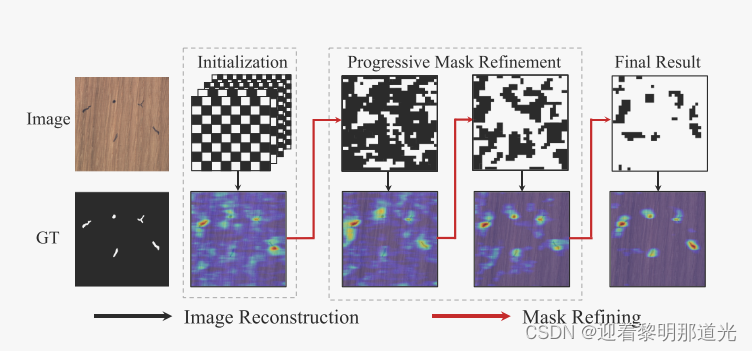
渐进细化的结果,随着不断迭代进行,掩码逐渐与异常区域重合。
训练时候的掩码,类似于异常图像的异常部分。训练这个模型的目的是,让模型学会将异常的图像重建,并分别重建出正常的图像和异常部分。而推理的目的是,找到异常的真实位置。
2、方法
2.1、random masking
每个图片被分解成多个块,每个块的大小是 k × k k \times k k×k个像素大小的正方形。掩码的大小也和这个正方形相同,在后面掩码细化的过程中,也是以这个掩码大小进行更新。
2.2、restoration network
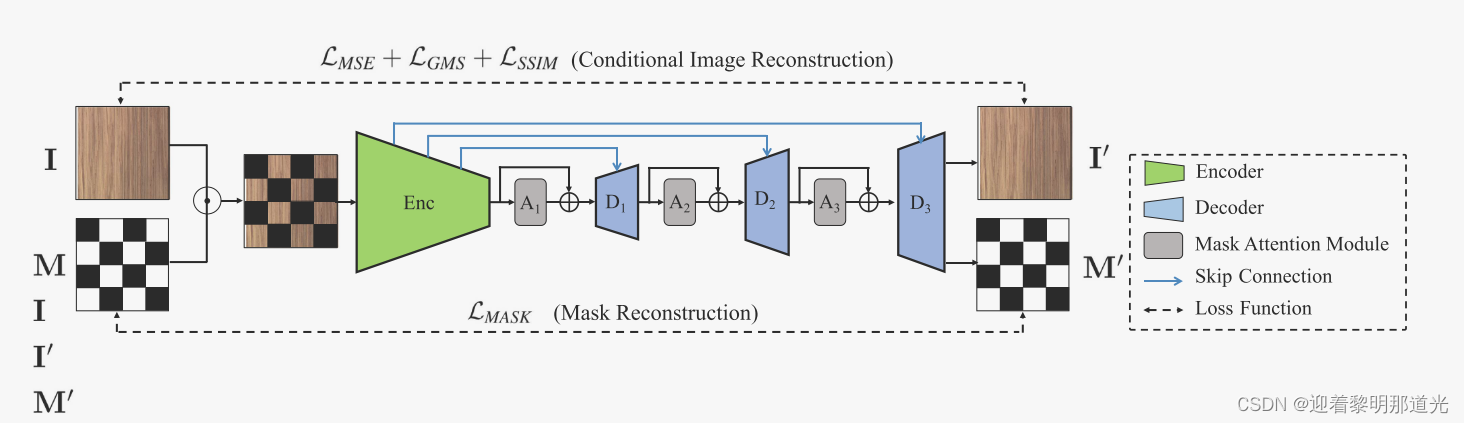
恢复网络的骨干是条件自动编码器。由掩码引导,而不是简单的重建图像。假设掩蔽区域与其对应的恢复之间的差异对于检测异常是重要的。
为了提高鲁棒性和重建能力,引入掩码注意模块
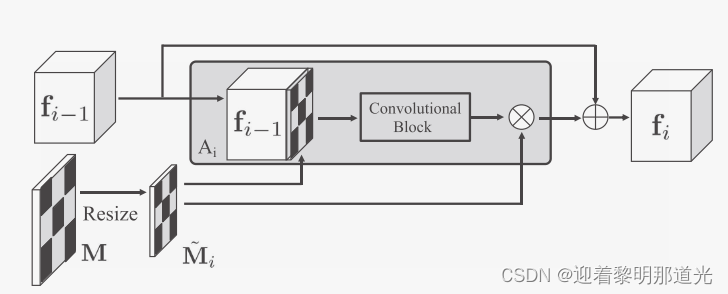
掩码注意模块被添加在每个子网络的前面。每个掩码注意模块,使用最近邻方法将掩码下采样,并匹配到相应输入特征映射的空间维度。输出为:
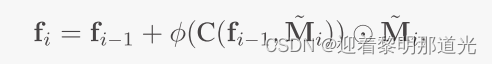
2.3、损失函数
注意重建的图像其实包含两个部分,未被掩蔽的区域用本来图像中复制,掩蔽的区域进行了恢复。

损失函数包括:均方误差、梯度幅度相似性损失、结构相似性指数和掩码重建的损失。
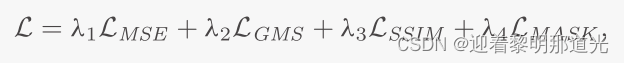
2.4、推理时的渐进细化
主要解决的是如何定位异常。分为两个阶段:掩码初始化和掩码细化。
根据给定输入图像和重建图像,引入误差函数。这个误差函数,用于计算每个像素的误差分数并将具有最大分数的区域视为潜在异常,渐进的细化并缩小的可能的异常区域。

初始化选择: 一组互补的掩码。共同覆盖所有像素,避免遗漏可能的异常。将不同掩码的分数图平均图平均为单个分数图,得到一个总体的初始化异常分数图。
细化过程中: 将较小误差的区域视为正常区域,并在掩码中移除,之后进行下一次迭代。当掩码覆盖的区域大部分是异常区域时候,提供更多的图像信息并不能显著降低异常区域的重建误差,相应的掩码保持不变,这时候停止推理,获得最终的掩码。

根据阈值 η \eta η更新掩码,并且阈值是验证集中的最大误差,可以将验证集的最大误差认为是正常和异常之间的粗略边界。
3、实验
异常检测
RETINAL-OCT DATASET

MVTec AD DATASET
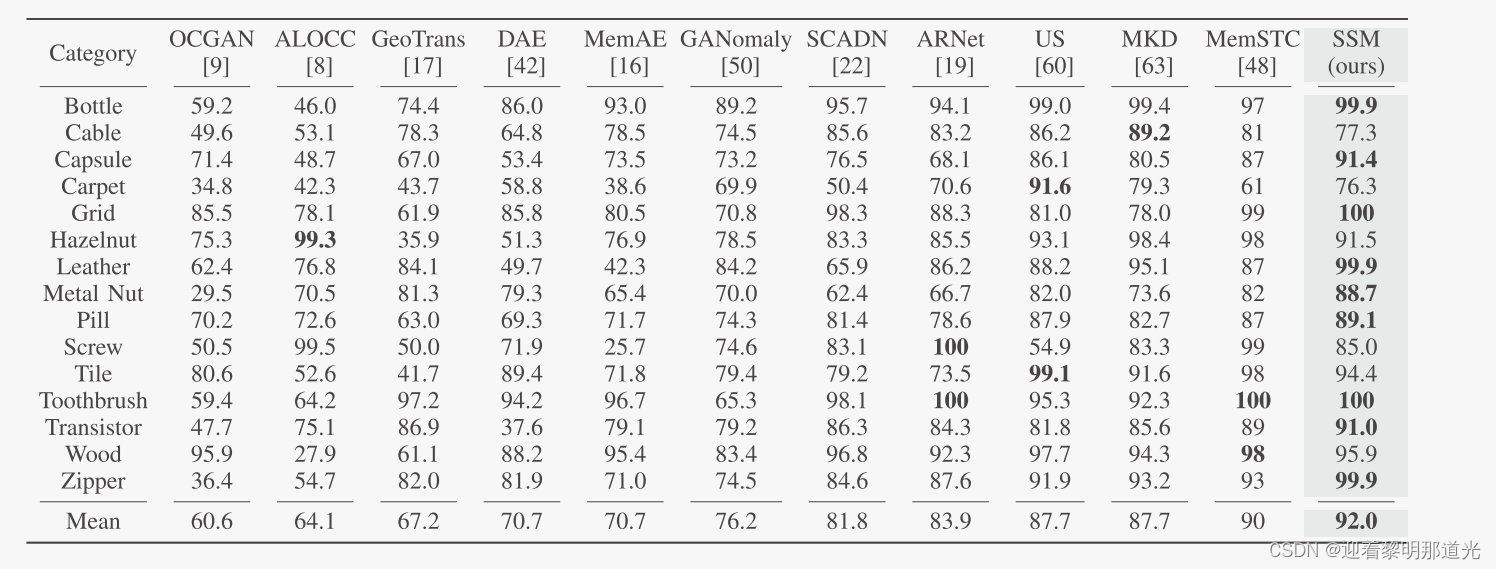
异常定位
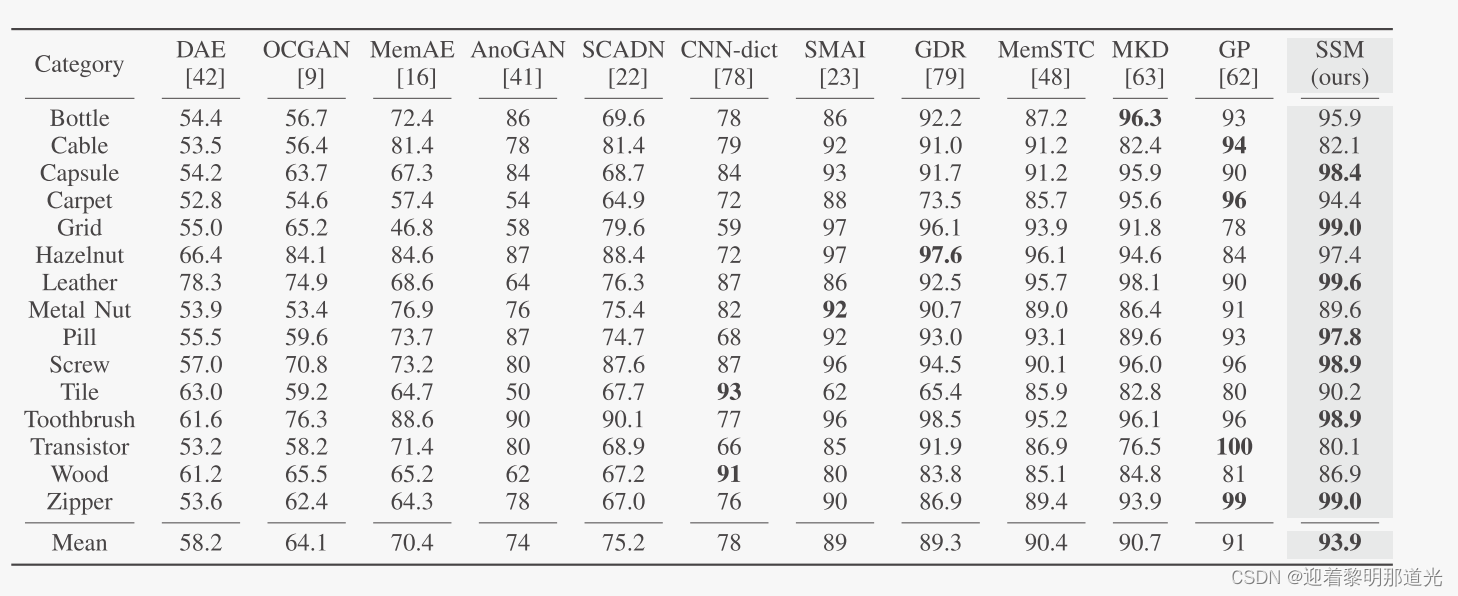
效率
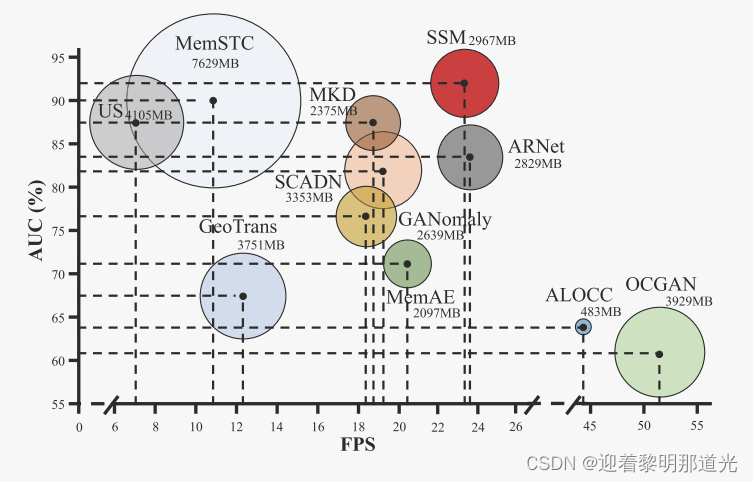
SSM具有更高的AUC,占用较小的内存,并具有较高的计算效率。
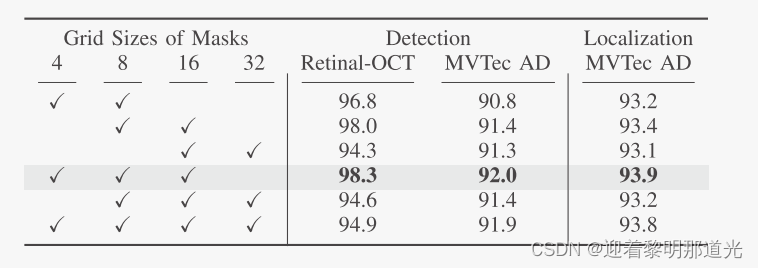
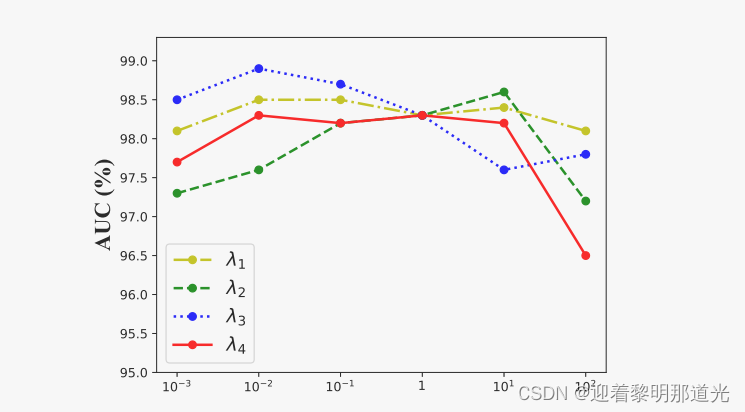
消融实验
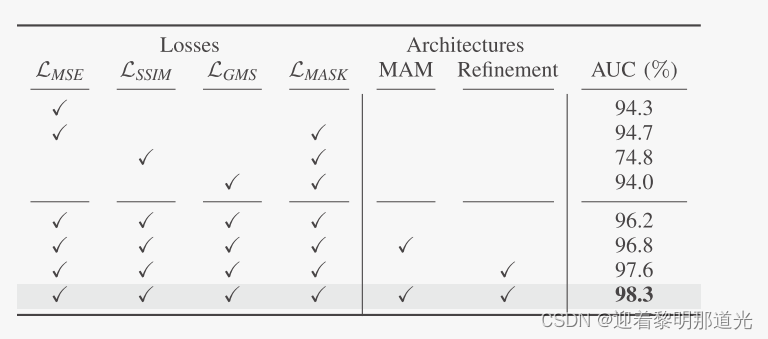
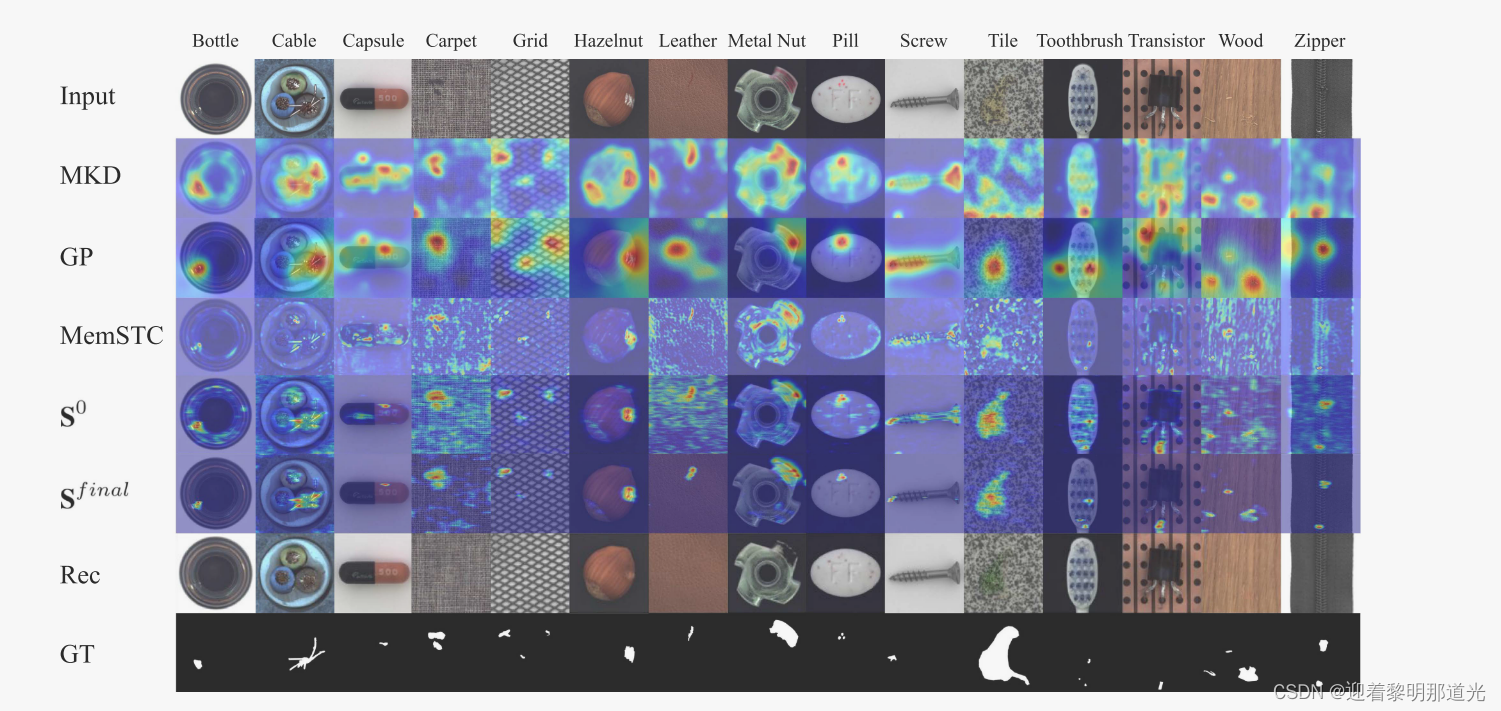
可视化结果
4、引用
C. Huang, Q. Xu, Y. Wang, Y. Wang and Y. Zhang, “Self-Supervised Masking for Unsupervised Anomaly Detection and Localization,” in IEEE Transactions on Multimedia, vol. 25, pp. 4426-4438, 2023, doi: 10.1109/TMM.2022.3175611.
5、想法
- 掩码的类型是不是可以与实际的异常更相似。
- 随机掩码和恢复的自监督学习。