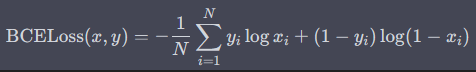11期:GPT系列算法与实现(chatGPT前世今生之前世)

***** 文章正常结构分三部分 *****
***** 日常感悟*****
***** 股市瞎聊*****
***** 技术分享****
(文末加餐:深度学习的基础系列课程来啦,一步一步走进人工智能,欢迎关注!)验证
验 关注该公众号 证
GPT系列算法与实战
首先,我们先来看看openai2022的时候在做什么?

2022年生成的一篇博客轰动整个AI领域,结果是机器人生成的。这个就是openai做的,主要呢,也是为了搞噱头,吸引大家注意力。
openai一直在研究聊天机器人,每天新生成450亿词。
那么问题来了,Nlp不像cv,检测是猫就是猫,是狗就是狗,生成语言就会带有偏见。比如说一个男人,可以说他是大英雄,也可以说他是个罪犯。可能是好坏不分。所以GPT3不对外开源,只开放了API.那么如果想训练只能基于GPT-2来训练,但哪怕GPT-3开源,也训练不起,参数太大,电费都不够扛!
GPT只是冰山一角,2022年每4天就产生一个大模型,甚至比GPT3还大。
一、看看GPT的历史时刻:
1.2018年6月GPT-1, 约5GB文本,1.17亿参数量
2.2019年2月GPT-2,约40GB文本,15亿参数量
3.2020年52月GPT-3,约45TB文本,1750亿参数量
2018年8月Bert产生。
二、接着来看看bert与GPT的区别:
有句话说:Bert看到希望,GPT-3看到未来。
都是基于transformer算法展开,bert采用的是编码器,GPT采用的是解码器,bert属于完形填空(已知上下文),gpt预测下一句(预测以后的事),chatGPT出来前,bert被引用数量巨大,难度相对简单,GPT难度大。
bert gpt1都需要微调,都需要标注数据,都需要人工。
三、万物皆可GPT
GPT1算法:
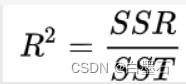
损失函数:
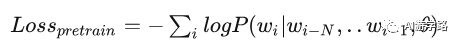
GPT1采用的是transformer的解码器,也需要打标监督学习。
GPT-2算法:zero-shot
以不变应万变,没有下游任务,不需要微调。也就是根据内容输出所有想要的内容。举例如下:
输入一句话预测自己的心情。
通过一句话取出里面的名词。
通过一句话提取主谓宾。
支持多个任务直接输出,不再是一对一的模型任务。
GPT-2算法:采样策略加温度值:

针对输入内容获取结果,如果结果都采用概率最大的,就太僵硬了,并且无趣。所以预测怎么选,多样性,温度就来了:
T<1 拉大差距
T=1 维持softmax结果
T> 1 缩小差距,,多样性,雨露均沾,就可能会胡说八道,啥都往外说。
但是GPT-2话说的太大了,而且实际说话的时候,谁会暗示你呢,所以没特别惊艳,没引起太大关注。
GPT-3算法:
GPT3在2的基础上进行优化,如果GPT2没有专门暗示,那么输出就太多样性,也相对不准确,因此GPT3专门训练下如何暗示,让你理解暗示是啥。
GPT3功能强大,目前实现加法任务,纠错任务等等,可谓上知天文,下知地理。
那什么叫做暗示训练呢?比如我们想去酒吧,没去过,不知道怎么办,就叫个已经有这方面经验的人,先给我们打个样。
这就是GPT-3的暗示效果,就是模仿。
Zero-shot就是GPT2版本的方法,输入一句话,直接输出结果,不进行提示。
One-shot:先打个样,先让他知道你会怎么做 。
Few-shot:输入多个例子
GPT3不需要微调,没有标签,没有下游任务
OPENAI还做了件事,就是基于GITHUB上编程,通过github上的代码数据进行GPT3训练,实现可以输入内容,直接编程,链接如下:
CODEX:https://openai.com/blog/openai-codex/#spacegame
GPT2代码:
GPT2Tokenizer一般在代码里面,以下面情况出现:
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
而GPT2LMHeadModel一般在代码里面,以下面情况出现:
model = GPT2LMHeadModel.from_pretrained('gpt2')
这很明显GPT2Tokenizer是编码器,GPT2LMHeadModel是加载训练好的模型。
(下期再来讲讲chatGPT前世今生之今生)