编者按:2023年是微软亚洲研究院建院25周年。借此机会,我们特别策划了“智启未来”系列文章,邀请到微软亚洲研究院不同研究领域的领军人物,以署名文章的形式分享他们对人工智能、计算机及其交叉学科领域的观点洞察及前沿展望。希望此举能为关注相关研究的同仁提供有价值的启发,激发新的智慧与灵感,推动行业发展。

“Transformer 网络架构、‘语言’模型(Next-Token Prediction,或自回归模型)学习范式,规模法则(Scaling Law),以及海量的数据和计算资源,共同构成了当前人工智能基础大模型范式迁移的核心技术要素,也将人工智能的基础创新推向了第一增长曲线的顶峰。在探索人工智能基础创新的第二增长曲线时,我们希望直击人工智能第一性原理,通过革新基础网络架构和学习范式,构建能够实现效率与性能十倍、百倍提升,且具备更强涌现能力的人工智能基础模型,为人工智能的未来发展奠定基础。”
——韦福如,微软亚洲研究院全球研究合伙人
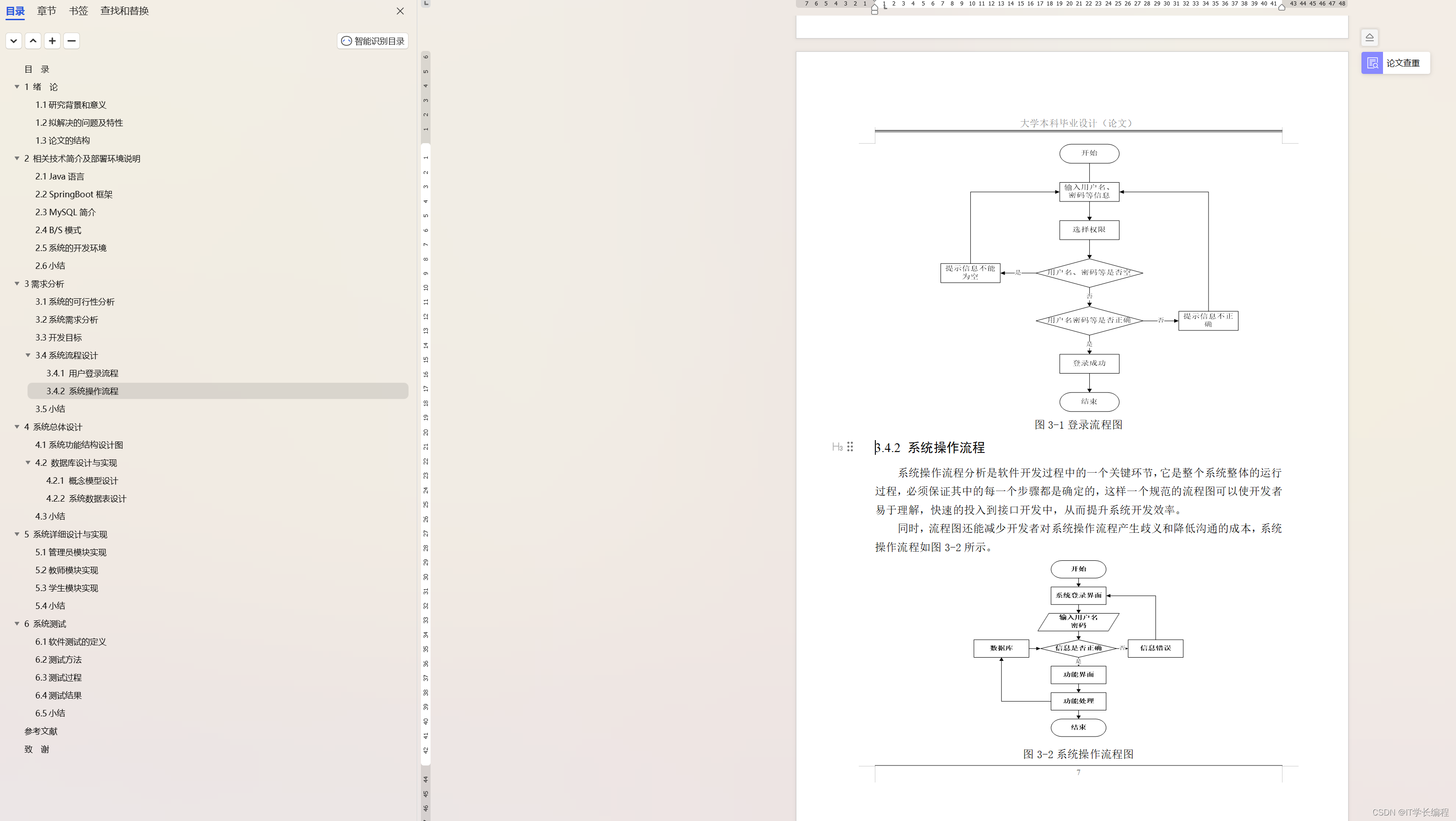
从人工智能的发展历程来看,GPT 系列模型(例如 ChatGPT 和 GPT-4)的问世无疑是一个重要的里程碑。由它所驱动的人工智能应用已经展现出高度的通用性和可用性,并且能够覆盖多个场景和行业——这在人工智能的历史上前所未有。
然而,人工智能的科研工作者们不会满足于此。从某种意义上来说,大模型只是人工智能漫长研究道路上一个精彩的“开局”。但当我们满怀雄心壮志迈向下一个里程碑时,却发现仅仅依赖现有的技术和模型已经难以应对新的挑战,我们需要新的突破和创新。
Transformer 网络架构、“语言”模型(Next-Token Prediction,或自回归模型)学习范式,规模法则(Scaling Law),以及海量的数据和计算资源,是构成当前人工智能基础大模型范式迁移的核心技术要素。在这套“黄金组合”的基础上,目前人工智能基础大模型的大部分工作都集中在继续增加训练数据量和扩大模型规模。但我们认为,这套范式并不足以支撑人工智能未来的发展。当我们被束缚在既有的架构中,只追求增量式的创新时,也就意味着我们已经看到了现有技术路径的局限性,人工智能基础创新的第一增长曲线的顶峰已然近在咫尺。
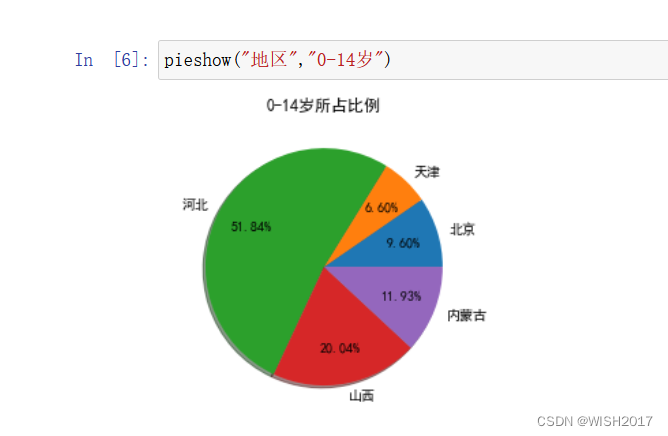
“无论把多少架马车连续相加,都不能造出一辆火车。只有从马车跳到火车的时候,才能取得十倍速的增长。”约瑟夫·熊彼特的经典名言表明,第二增长曲线从不会诞生于对现有成果的简单叠加,我们需要在人工智能基础模型的组成要素中,寻找撬动第二增长曲线的驱动力。
因此,在微软亚洲研究院,我们将目光聚焦到了人工智能的第一性原理,从根本出发,构建能实现人工智能效率与性能十倍甚至百倍提升,且具备更强涌现能力的基础模型,探索引领人工智能走向第二增长曲线的途径。
人工智能基础创新的第二增长曲线
基础模型是人工智能的第一性原理
如果对人工智能的“组件”进行一次“二维展开”,我们认为它将呈现出以下几个部分:处于最上层的是自主智能体(Autonomous Agent),它的目标是能通过自主学习和适应性调整来完成各种任务。最底层是“智能”本质的科学理论支撑,可以帮助我们理解“智能”(尤其是人工智能)的边界和机理。位于两者之间的部分,我们将其称为基础模型(Foundation Model)。在数据、算力和新的软硬件等基础设施的支持下,基础模型是将科学理论转化成智能体的实际行为。
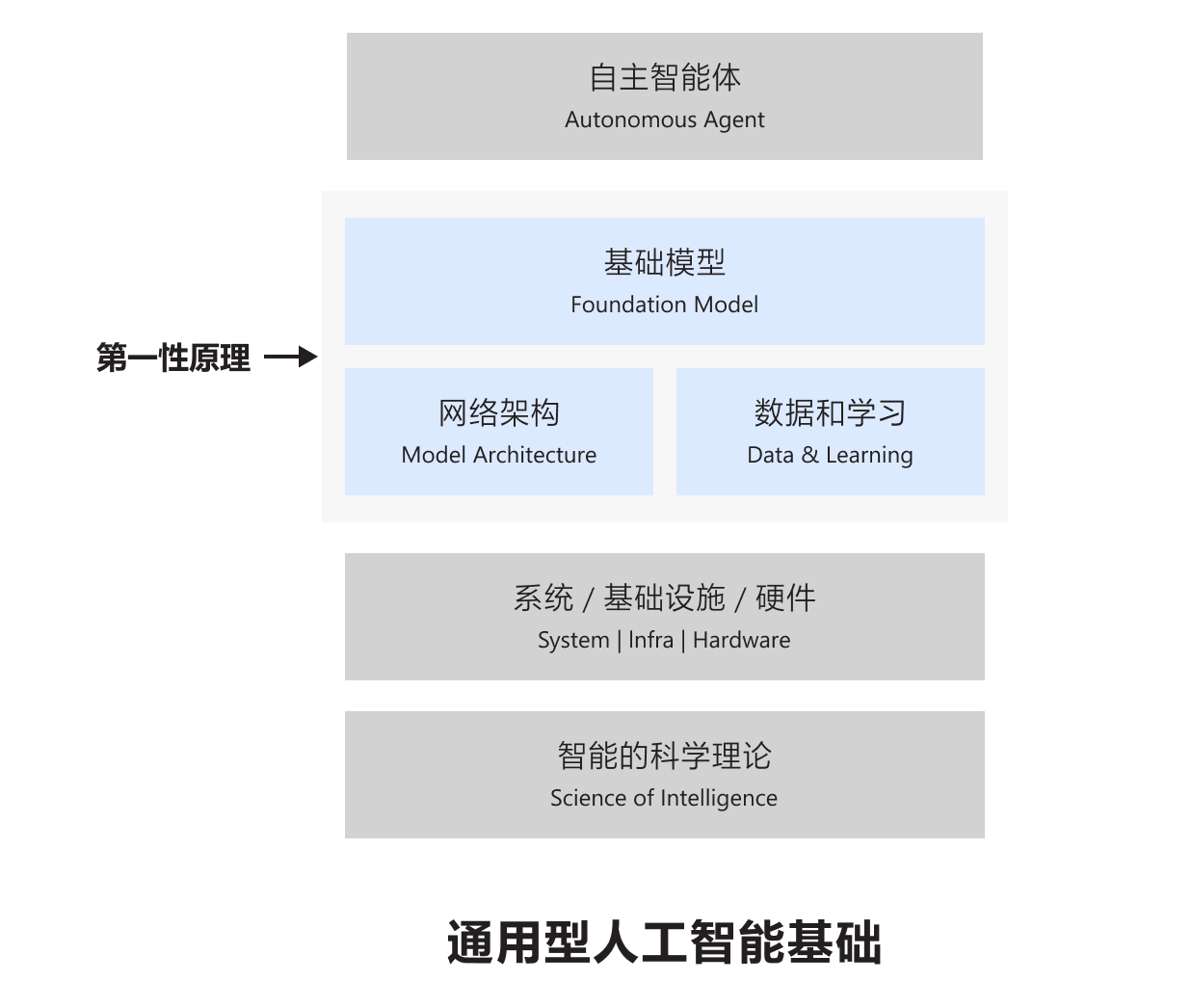
通用型人工智能基础研究的组成部分
在勾画人工智能的未来蓝图时,基础模型无疑是人工智能的第一性原理,其中,基础网络架构(Model Architecture)和学习范式(Learning Paradigm)是其两大核心基础。
对上层而言,基础模型驱动自主智能体的创建,为更多革命性的应用和场景提供动力,就像为上层应用持续供电的发电机。对下,基础模型则可以促进智能的科学理论(Science of Intelligence)的深入研究。事实上,无论是万亿级参数的大模型所展现出的“暴力”美学,还是通过扩展规律(Scaling Law)来寻找关键的物理指标,都应该成为科学研究的一部分。随着智能的科学理论的推进,未来我们或许可以仅通过简洁的公式就能描述和推导出人工智能的规律。
要实现这些目标,我们需要一个强大的基础模型作为核心。对基础模型的重构,为人工智能基础创新的第二发展曲线提供了关键的突破口。
接下来的问题是,我们应该如何改进基础模型?
正如之前所提到的,现有的“黄金组合”依旧是基础模型的技术根本,但是我们需要更加根本和基础的研究突破以引领未来的人工智能基础模型的构建和开发。我们期望通过对这一组合进行根本性的变革,使其成为引领未来人工智能训练范式的基石,让基础模型能真正成为人类社会的基础设施。而新一代的基础模型应当具备两大特质:强大且高效。其中,“强大”体现在其性能、泛化能力和抵抗幻觉能力等方面的出色表现,“高效”则是指低成本、高效率和低能耗。
目前已有的大模型通过不断增加数据量与算力规模,或者说规模法则已经在一定程度上解决了第一个问题,但这是以成本效率为代价来实现的。为了突破这些局限,我们推出了如 RetNet 和 BitNet 等旨在取代 Transformer 的新型网络架构。同时,我们也在持续推动多模态大语言模型(MLLMs)的演进,并探索新的学习范式,“三管齐下”来构建全新的基础模型,为人工智能的未来发展奠定坚实的基础。
推理效率是新一代基础模型网络架构革新的关键驱动力
基础网络架构是人工智能模型的骨干,只有基础架构足够完善,才能保证上层的学习算法和模型训练高效运行。目前,Transformer 架构被广泛应用于大语言模型,并且利用其并行训练的特点显著提高了模型的性能,成功解决了基于循环神经网络架构在长程依赖建模方面的不足。但与此同时,它也带来了提升推理效率的巨大挑战。
根据当前大模型的发展趋势,如果继续在 Transformer 架构上训练模型,我们很快就会发现,现有的计算能力将难以满足下一阶段人工智能发展的需求。
这就明确了一个问题——推理效率已经成为现有基础网络架构演进的瓶颈,也是推动未来基础网络架构变革的关键驱动力。提升推理效率不仅意味着降低成本,更代表着我们可以将基础模型真正变成像水和电一样的基础设施和资源,使每个人都能方便地获取和使用。
而近期,我们推出的一种新型基础网络架构 Retentive Network(RetNet),成功突破了所谓的“不可能三角”难题,实现了帕累托(Pareto)优化。也就是说,RetNet 在保持良好的扩展性能和并行训练的同时,实现了低成本部署和高效率推理。我们的实验还证实,RetNet 的推理成本与模型序列长度无关,这表示无论是处理长文本序列,还是长图像序列,亦或是未来更长的音视频序列,RetNet 都可以保持稳定的高效推理。这些优势让 RetNet 成为继 Transformer 之后大语言模型网络架构的有力继承者。
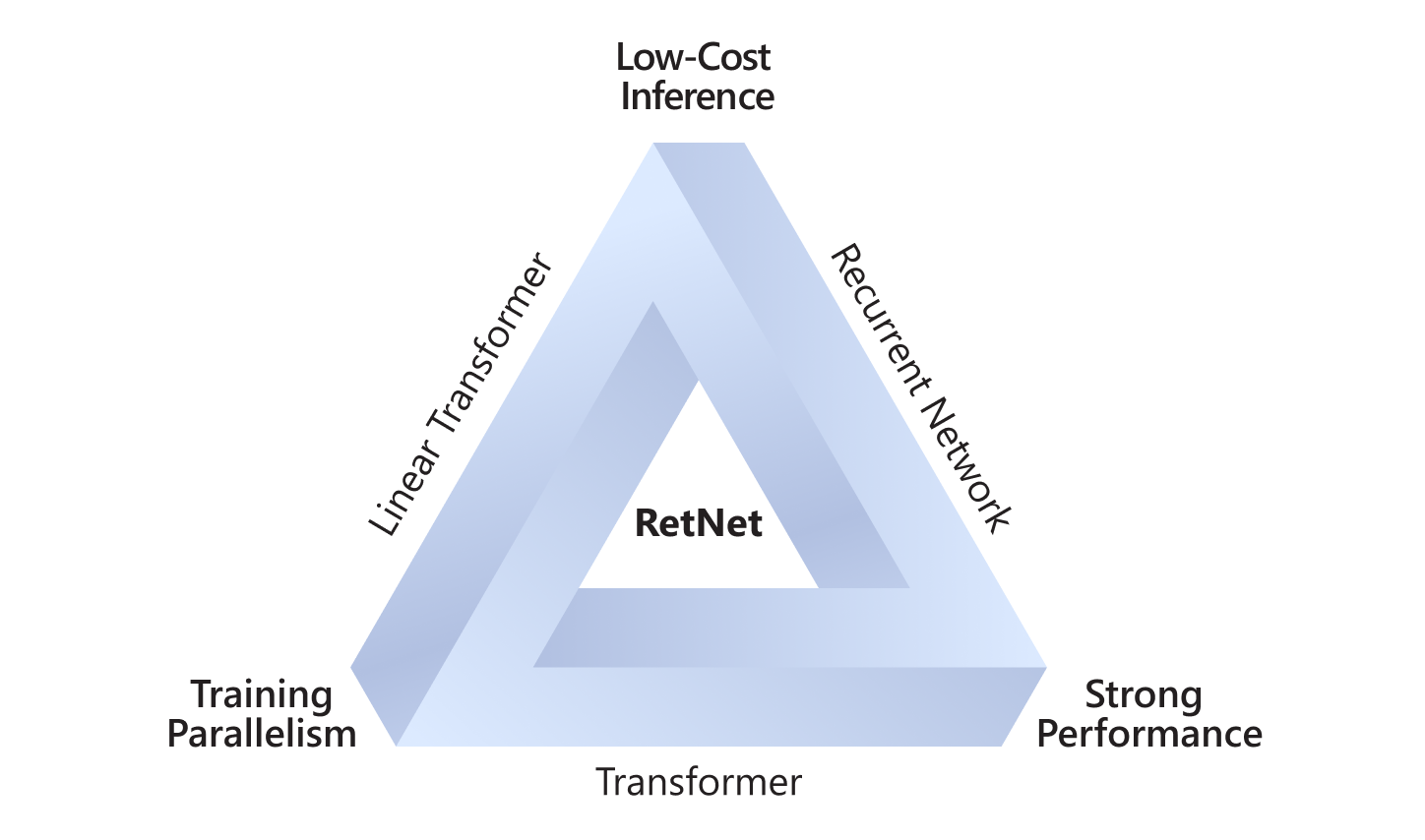
模型网络架构之“不可能三角”问题
另外,随着模型规模的不断扩展,计算能耗问题也日益凸显,成为当前网络架构中限制人工智能发展的另一大障碍。我们推出的 BitNet 则有效缓解了这一问题。
BitNet 是第一个支持训练1比特大语言模型的新型网络结构,具有强大的可扩展性和稳定性,能够显著减少大语言模型的训练和推理成本。与最先进的8比特量化方法和全精度 Transformer 基线相比,BitNet 在大幅降低内存占用和计算能耗的同时,表现出了极具竞争力的性能。此外,BitNet 拥有与全精度 Transformer 相似的规模法则(Scaling Law),在保持效率和性能优势的同时,还可以更加高效地将其能力扩展到更大的语言模型上,从而让1比特大语言模型(1-bit LLM)成为可能。
如果说 RetNet 是从平行推理效能的角度革新了网络架构,那么 BitNet 则从正交的角度提升了推理效率。这两者的结合,以及融合其他提升模型效率的技术比如混合专家模型(MoE)和稀疏注意力机制(Sparse Attention),将成为未来基础模型网络架构的基础。
推动多模态大语言模型演进,迈向多模态原生
未来基础模型的一个重要特征就是拥有多模态能力,即融合文本、图像、语音、视频等多种不同的输入和输出,让基础模型能够像人类一样能听会看、能说会画。而这也是构建未来人工智能的必然方向。
在这一背景下,我们针对多模态大语言模型 Kosmos 展开了一系列研究。其中,Kosmos-1 能够按照人类的推理模式,处理文本、图像、语音和视频等任务,构建了全能型人工智能的雏形。Kosmos-2 则进一步加强了感知与语言之间的对齐,它不仅能够用语言描述图像,还能识别图像中的实体,解锁了多模态大语言模型的细粒度对齐(Grounding)能力。这种能力为具身智能(Embodied AI)奠定了基础,展示出了多模态模型在语言、感知、行动和物理世界中大规模融合的可能性。
在 Kosmos-2 的基础上,我们又推出了 Kosmos-2.5。这一版本为多模态大语言模型赋予了通用的识字能力,使其能够解读文本密集的图像,为智能文档处理和机器人流程自动化等应用提供技术基础。在接下来的 Kosmos-3 中,我们将在基础网络架构革新和创新学习范式的双重驱动下,进一步推动人工智能基础模型的发展。


Kosmos 系列整体架构图:Kosmos-1和2多模态大语言模型支持多模态输入输出,细粒度的对齐,遵循用户指示,并可针对多模态任务(包括自然语言任务)进行上下文学习
此外,语音无疑是未来多模态大语言模型的核心能力之一。因此,我们还推出了语音多模态大语言模型 VALL-E,并支持零样本文本的语音合成。只需短短三秒的语音提示样本,VALL-E 就能将输入的文本用与输入的提示语音相似的声音朗读出来。与传统的非基于回归任务训练的语音模型不同,VALL-E 是直接基于语言模型训练而成的。通过直接将语音合成转化为一个语言模型任务,这一探索进一步加强了语言和语音两种模态的融合。
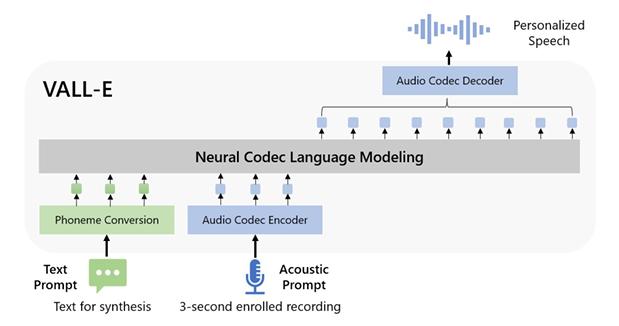
VALL-E 首先通过语音 codec 模型把连续的语音输入转化为离散的 token,从而可以进行统一的语音-文本语言模型训练
Kosmos 系列模型和 VALL-E 都是我们在多模态大语言模型方面的早期探索,我们让大语言模型具备了基本的多模态感知和生成的能力。但是,这还远远不够,我们认为未来的多模态大语言模型和人工智能基础模型要能够多模态原生(Multimodal Native),以实现真正的多模态推理,跨模态迁移以及新的涌现能力。
专注颠覆式创新,持续推进通用型人工智能基础研究第二增长曲线
除了不断推进基础模型架构和多模态大语言模型的创新,我们还需要更多在基础研究上的颠覆式突破。我们相信目前大模型应用中的很多问题,比如成本问题、长序列建模/长期记忆(Long-term Memory)、幻觉问题以及安全问题等也需要从根本性的角度得到解决。
首先是大语言模型学习的理论框架和根本原理,现有的工作基本都是以实验和经验为主,未来的基础创新需要从更加根本和理论的角度推进。目前已经有一些基于压缩的工作,我们相信在不远的未来就有可能看到很大的突破性进展。
另外,大模型的发展使得我们可以实现在很多任务上达到或者超过人类(如数据生产者或标注员)的能力,这就需要我们探索一种在模型比人类强的前提下的新一代人工智能研究范式,包括且不限于基本的学习框架、数据和监督信号来源以及评测等等。比如合成数据(Synthetic Data)会变得越来越重要,一方面是数据会变得不够用,另一方面是模型自动生成的数据质量也越来越高了。还有一个机会是小数据大模型的学习,我们可以通过模型的自动探索与学习,结合强化学习,从而让人工智能可以更接近人类从少量数据中就能高效学习的学习方式。这也是进一步通过规模化算力(Scaling Compute)提升智能的可行方向之一。
最后,越来越多的研究工作表明,未来人工智能的模型、系统基础设施和硬件的发展会有更多联合创新、共同演进的机会。
在对人工智能的漫长探索中,我们正站在一个前所未有的历史节点。现在我们可能正处于人工智能领域的“牛顿前夜(Pre-Newton)”,面临着诸多未知和挑战,同样也有很多的机会,每一次的探索和突破都预示着未来无限的可能性。希望藉由我们的研究,人们能够更深入地洞悉基础模型和通用型人工智能的理论和技术的发展趋势,揭示关于未来人工智能的“真理”。
我们相信,人工智能今后必将更加全面地融入我们的日常生活,改变我们工作、生活和交流的方式,并为人类解决最有挑战和最为重要的难题,甚至对人类社会带来深刻的影响。接下来的5到10年是人工智能最值得期待和激动人心的时刻,我和我的同事们也将继续专注于推动人工智能基础研究的突破和创新应用的普及,让其成为促进人类社会发展和进步的强大动力。
本文作者
韦福如博士现任微软亚洲研究院全球研究合伙人,领导团队从事基础模型、自然语言处理、语音处理和多模态人工智能等领域的研究。最近,他还致力于推进通用型人工智能的基础研究和创新。韦博士还担任西安交通大学兼职博士生导师,香港中文大学教育部-微软重点实验室联合主任。
韦博士在顶级会议和期刊上发表了200多篇研究论文(引用超过30000次,H-Index 84),并获得 AAAI 2021 年最佳论文提名奖以及 KDD 2018 最佳学生论文奖。
韦博士分别于2004年和2009年获得武汉大学学士学位和博士学位。2017年,他因对自然语言处理的贡献入选《麻省理工技术评论》中国35岁以下创新者年度榜单(MIT TR35 China)。
相关链接
微软亚洲研究院通用型人工智能研究项目页面:
aka.ms/GeneralAI
Retentive Network: A Successor to Transformer for Large Language Models
https://arxiv.org/abs/2307.08621
BitNet: Scaling 1-bit Transformers for Large Language Models
https://arxiv.org/abs/2310.11453
(Kosmos-1) Language Is Not All You Need: Aligning Perception with Language Models
https://arxiv.org/abs/2302.14045
Kosmos-2: Grounding Multimodal Large Language Models to the World
https://arxiv.org/abs/2306.14824
Kosmos-2.5: A Multimodal Literate Model
https://arxiv.org/abs/2309.11419
VALL-E
https://www.microsoft.com/en-us/research/project/vall-e-x/