一. 内容简介
python爬取robomaster论坛文章数据。
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
2.3代码
三.主要流程
3.1 接口分析,以及网页结构分析
# 这是文章链接,其实id就是文章的id
# https://bbs.robomaster.com/forum.php?mod=viewthread&tid=9234
# 文章结构
# 大疆这个文章,在访问网站时候,他会把文章内容在服务端拼接好,是没办法直接拿到接口数据的,
# 第一个方面就是,urllib访问时候,拿到整个网页结构,这个结构是不带js执行的,虽然数据都有,但是是和浏览器里面有些定位不太一样的,在用xpath解析时候,经常找不到,有点不太方便
# 第二个方面,就是因为里面有些内容需要登录,这个登录有两种验证方式,一种是token,一种是cookie,大疆是cookie,所以我们需要在请求头中假如cooke访问,分别用urllib和elenium实现
3.2 通过urllib携带cookie爬取网页结构
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetime
import ssl
import re
import urllib.request
def urllibRequest(url):headers = {'Cookie':'换成自己的,直接去网页请求里面复制','User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1'}# 创建一个不验证证书的上下文对象context = ssl._create_unverified_context()request = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request, context=context) # 在这里传入context参数content = response.read().decode('UTF-8')return contenturl = "https://bbs.robomaster.com/forum.php?mod=viewthread&tid=9234"
content = urllibRequest(url)
print(content)里面有一点需要注意的就是,这个网页结构如果不能解析的话,要加这个,里面xml会报错,替换一下就好
content_without_declaration = re.sub(r'^<\?xml.*\?>', '', content)
html_tree = etree.HTML(content_without_declaration)
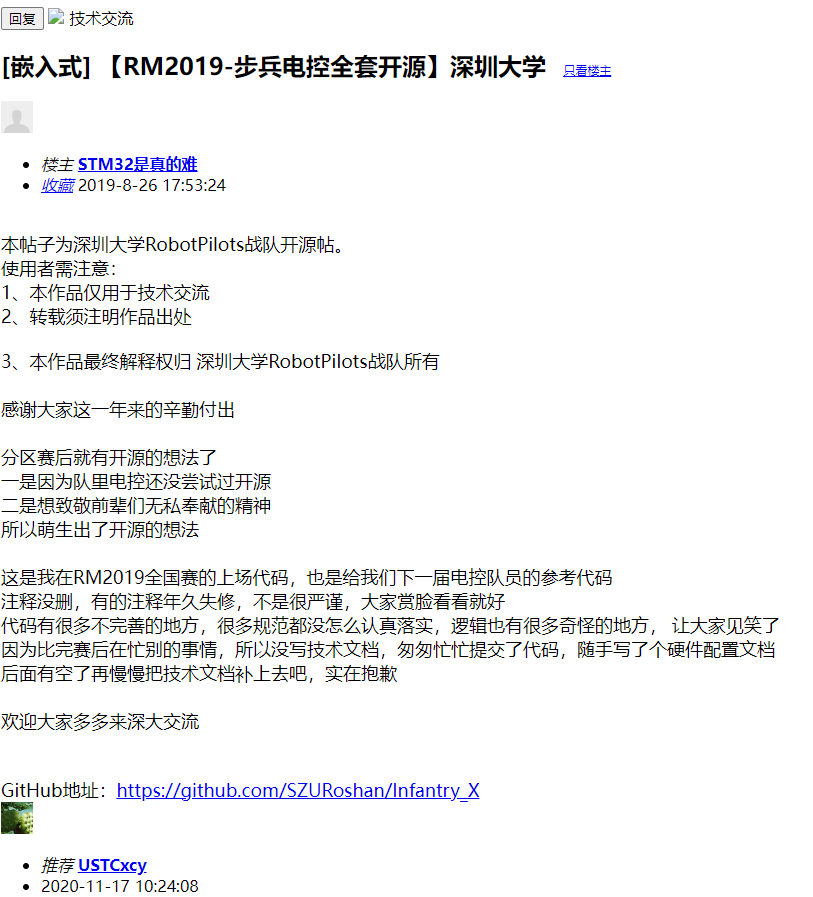
3.3 通过selenium携带cookie爬取网页结构
直接给selenium加个请求头
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetime
import randomdef seleniumRequest(url,chrome_path,waitTime): headers = {'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1''Cookie':'换自己的'}options = webdriver.ChromeOptions()# 添加cookie到浏览器中options.add_experimental_option('excludeSwitches', ['enable-automation'])options.add_experimental_option('useAutomationExtension', False)# 添加Header到options中options.add_argument(f'user-agent={headers["User-Agent"]}')options.add_argument(f'cookie={headers["Cookie"]}')# 谷歌浏览器exe位置options.binary_location = chrome_path# 是否要启动页面# options.add_argument("--headless") # 启用无头模式# GPU加速有时候会出bugoptions.add_argument("--disable-gpu") # 禁用GPU加速options.add_argument("--disable-blink-features=AutomationControlled")driver = webdriver.Chrome(options=options)driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})# 启动要填写的地址,这就启动浏览器driver.get(url)# 这是关闭浏览器# 等待页面加载,可以根据实际情况调整等待时间driver.implicitly_wait(waitTime)# 获取完整页面结构full_page_content = driver.page_source# 关闭浏览器driver.quit()return full_page_content
# # 处理完整页面结构
# print(full_page_content)
url = "https://bbs.robomaster.com/forum.php?mod=viewthread&tid=9234"
# print(url)chrome_path = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
waitTime = 8
# 获取网页结构
# 通过selenium调用浏览器访问
content = seleniumRequest(url,chrome_path,waitTime)
print(content)
3.4 网页结构定位
一般都是通过xpath语法,一个div下面如果有多个类,我xpath就选不到了,可以用下面这个
//div[contains(@class, 'example')]
还有一种方式,可以用谷歌浏览器里面的工具,就不用自己一个一个选了
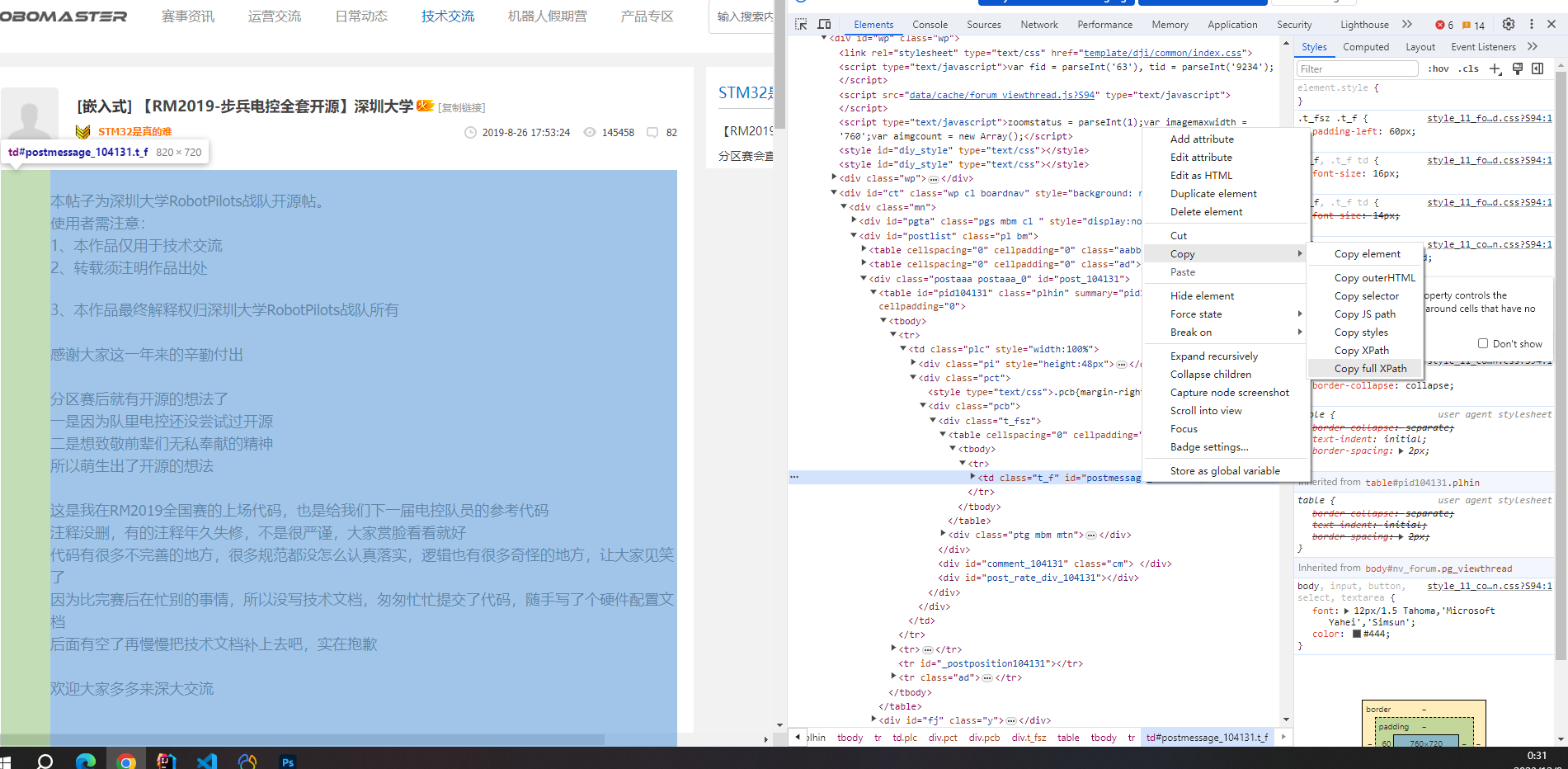
还有就是xpath选取得结构,用txt保存下来里面代码,包括结构
# # 解析对应数据
# contents = html_tree.xpath("//div[@class='message']")[0]
# print(contents)# # # 将选定的div元素转换为字符串
# div_html = etree.tostring(contents, encoding="unicode")# # print(div_html)
# # # 将HTML保存为文件
# with open('output.txt', 'w', encoding='utf-8') as f:
# f.write(div_html)