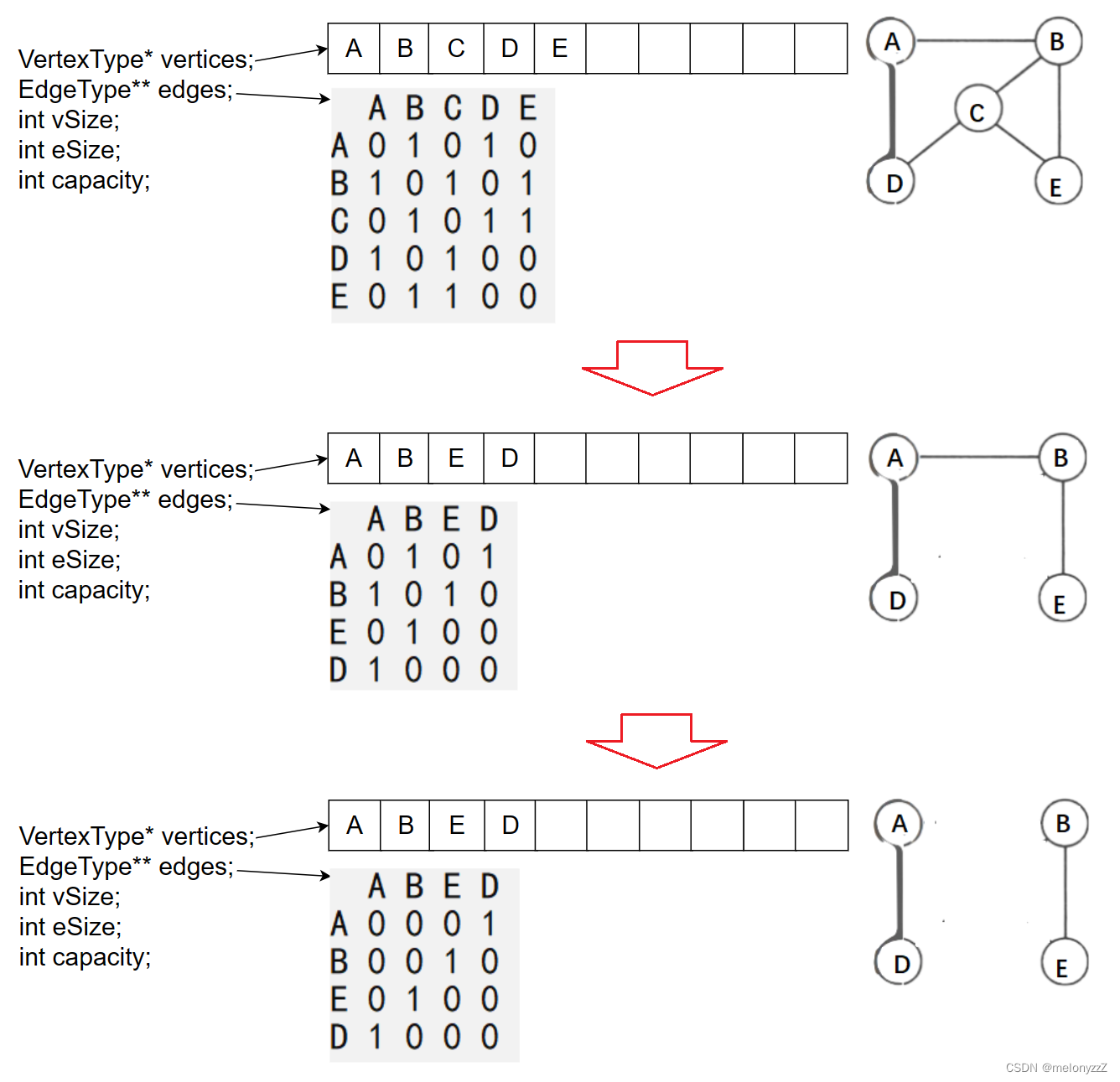
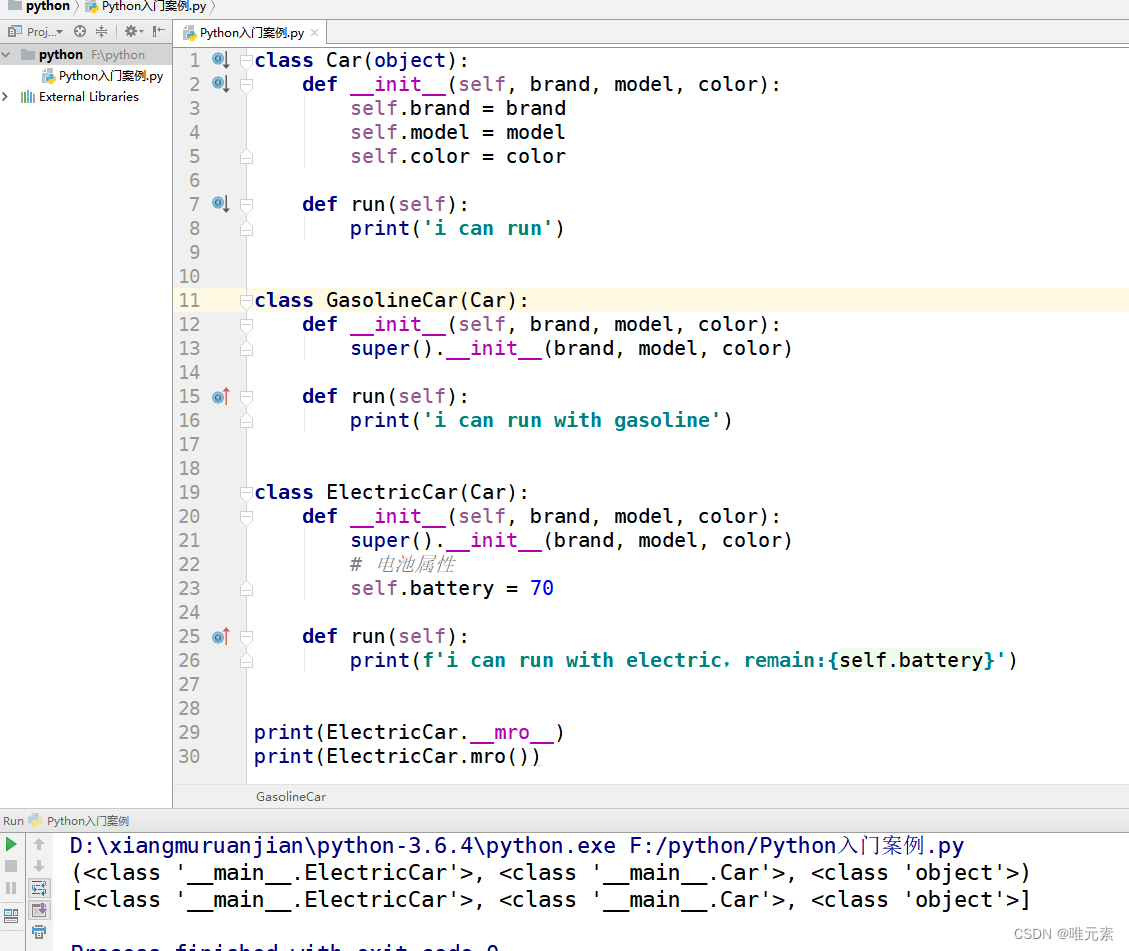
项目代码
https://github.com/yinhai1114/JavaWeb_LearningCode/tree/main/xml
零、在线文档
XML系列教程
一、XML引出
1.为什么需要XML
1.需求1 :两个程序间进行数据通信?
2.需求2:给一台服务器,做一个配置文件,当服务器程序启动时,去读取它应当监听的端口号、还有连接数据库的用户名和密码
3.spring 中的ico配置文件,beans.xml mybatis XXXMapper.xml tomcat server.xml web.xml maven pom.xml
4.能存储复杂的数据关系
2.XML用于解决什么问题
1.解决程序间数据传输的问题:
比如qq之间的数据传送,用xmI格 式来传送数据,具有良好的可读性,可维护性。
2.xmI可以做配置文件(目前主要用法)
xmI文件做配置文件可以说非常的普遍,比如我们的tomcat服务器的server.xml,web.xml
3.xmI可以充当小型的数据库
xml文件做小型数据库,也是不错的选择,我们程序中可能用到的数据,如果放在数据库中读取不合适(因为你要增加维护数据库工作),可以考虑直接用xm来做小型数据库,而且直接读取文件显然要比读取数据库快
3.案例
1.需求:使用idea创建students.xml(可拓展标记语言)存储多个学生信息
<?xml version="1.0" encoding="UTF-8" ?>
<!--1 xml :表示该文件的类型 xml2 version="1.0"版本3 encoding="UTF-8" 文件编码4. students: root元素/根元素, 程序员自己来定5. <student></student> 表示students一个子元素, 可以有多个6. id就是属性 name, age, gender 是student元素的子元素
-->
<students><student id="100"><name>jack</name><age>10</age><gender>男</gender></student><student id="200"><name>mary</name><age>18</age><gender>女</gender></student>
</students>

二、XML基本语法
1.基本语法
1、文档声明
2、元素
3、属性
4、注释
5、CDATIA区、特殊字符
2.XML语法 - 文档说明
<?xmI version="1.0" encoding="utf-8"?>
1、XML声明放在XML文档的第一行
2、XML声明由以下几个部分组成:
3、version -- 文档符合XML1.0规范,我们学习1.0
4、encoding -- 文档字符编码,比如"utf-8"
3.XML语法 - 元素
1.元素语法要求
每个XML文档必须有且只有一一个根元素。
根元素是一个完全包括文档中其他所有元素的元素。
根元素的起始标记要放在所有其他元素的起始标记之前。
根元素的结束标记要放在所有其他元素的结束标记之后。
<?xml version="1.0" encoding="utf-8" ?>
<!--1.每个XML文档必须有且只有一个根元素。2.根元素是一个完全包括文档中其他所有元素的元素。3.根元素的起始标记要放在所有其他元素的起始标记之前。4.根元素的结束标记要放在所有其他元素的结束标记之后5.XML元素指XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式包含标签体:<a>www.sohu.cn</a>不含标签体的:<a></a>, 简写为:<a/>6.一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套7. 叫法student 元素,节点,标签
-->
<students><student id="100"><name>jack</name><age>10</age><gender>男</gender></student><student id="200"><name>mary</name><age>18</age><gender>女</gender></student><school>清华大学</school><city/>
</students>2. XML元素指XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式,例如:
包含标签体: <a>www.sohu.cn</a> >
不含标签体的: <a>< :/a>简写为: <a/>
一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套,例如: <a>welcome to<b>www.sohu.org</a></b>
3.在很多时候,说标签、元素、节点是相同的意思
4. XML元素命名规则
区分大小写,例如,<P>和<p>是两个不同的标记。
不能以数字开头。
不能包含空格。
名称中间不能包含冒号(:)。
如果标签单词需要间隔,建议使用下划线比如<book_title>hello< /book_ title>
4.XML语法 - 属性
1.属性介绍
<Student ID="100" >
< Name>TOM< / Name>
</Student>
2.属性值用双引号(") 或单引号(')分隔(如果属性值中有',用"分隔;有",用'分隔)
3.一个元素可以有多个属性,它的基本格式为: <元素名属性名="属性值">
4.特定的属性名称在同-一个元素标记中只能出现--次
5.属性值不能包括&字符
<?xml version="1.0" encoding="utf-8" ?>
<!--1.属性值用双引号(")或单引号(')分隔(如果属性值中有',用"分隔;有",用'分隔)2.一个元素可以有多个属性,它的基本格式为:<元素名 属性名="属性值">3.特定的属性名称在同一个元素标记中只能出现一次4.属性值不能包括& 字符
-->
<students><!--举例:id='01' 也是正确写法如果属性值有" 则使用' 包括属性 比如 id="xxx'yyy"如果属性值有' 则使用" 包括属性 比如 id='xxx"yyy'属性名在同一个元素标记只能出现一次 <stduent id="01" id="03"> 错误的属性值不能包括& 字符 比如: <stduent id="0&1"> 是错误的--><student id="100"><name>jack</name><age>10</age><gender>男</gender></student><student id="200"><name>mary</name><age>18</age><gender>女</gender></student>
</students>
5.XML语法 - CDATA节
(注释同HTML)
有些内容不想让解析引擎执行,而是当作原始内容处理(即当做普通文本),可以使用CDATA包括起来,CDATA节中的所有字符都会被当作简单文本,而不是XML标记。
1.语法:
<![CDATA[
这里可以把你输入的字符原样显示,不会解析xmI
]]>
![]()
2.可以输入任意字符(除]]>外)
3.不能嵌套
<?xml version="1.0" encoding="utf-8"?>
<!--<![CDATA[这里可以把你输入的字符原样显示,不会解析 xml]]>
-->
<students><stduent id="01"><name>tom</name><gender>男</gender><age>18</age><!--举例说明:下面是一段js的代码片段. 直接放在<code></code>标签间,语法错误使用CDATA节来处理即可.<script data-compress=strip>function h(obj){obj.style.behavior='url(#default#homepage)';var a = obj.setHomePage('//www.baidu.com/');}</script>--></stduent><stduent id="02"><name>scott</name><gender>女</gender><age>17</age><code><!--如果希望把某些字符串,当做普通文本,使用CDATA包括 --><![CDATA[<script data-compress=strip>function h(obj){obj.style.behavior='url(#default#homepage)';var a = obj.setHomePage('//www.baidu.com/');}</script>]]><![CDATA[ 这里输入 ]]></code></stduent>
</students>
三、XML转义字符
1.对于一-些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理

<?xml version="1.0" encoding="utf-8" ?>
<!--对于一些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理比如 > < & ' ""
-->
<students><stduent id="01"><name>tom</name><gender>男</gender><age>28</age><!--使用转义字符表示一些特殊字符<resume>年龄<100 &版权</resume>--><resume>年龄<10 > &</resume></stduent><stduent id="02"><name>scott</name><gender>女</gender><age>17</age></stduent>
</students>
小结
遵循如下规则的XML文档称为格式正规的XML文档
1、XML声明语句<?xml version= "1.0" encoding= "utf-8"?>
2、必须有且仅有一一个根元素
3、标记大小,区分大小写的。
4、属性值用引号
5、标记成对
6、空标记关闭
7、元素正确嵌套
四、DOM4J
dom4j 1.6.1 API API文档
1.XML解析技术的原理
1.不管是html文件还是xmI文件它们都是标记型文档,都可以使用w3c组织制定的dom技术来解析
2. document对象表示的是整个文档( 可以是html文档,也可以是xmI文档)
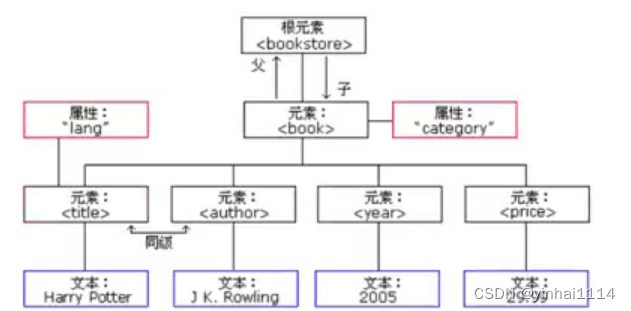
3.早期JDK为我们提供了两种xml解析技术DOM和Sax简介
1.dom解析技术是W3C组织制定的,而所有的编程语言都对这个解析技术使用了自己语言的特点进行实现。Java对dom技术解析也做了实现
2. sun公司在JDK5版本对dom解析技术进行升级: SAX ( Simple API for XML ) SAX 解析,它是以类似事件机制通过回调告诉用户当前正在解析的内容。是一行一-行的读取xml文件进行解析的。不会创建大量的dom对象。所以它在解析xmI的时候,在性能上优于Dom解析
3.这两种技术已经过时,知道有这两种技术即可
4.第三方的XML解析技术
1. jdom在dom基础上进行了封装
2. dom4j又对jdom进行了封装。

3. pull主要用在Android手机开发,是在跟sax非常类似都是事件机制解析xmIl文件
2.DOM4J介绍
1. Dom4j是一个简单、灵活的开放源代码的库(用于解析/处理XNL文件)。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。
2.与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些, 但它提供了比JDOM更好的灵活性。
3. Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j。
4.使用Dom4j开发,需下载dom4j相应的jar文件
3.获得Document对象的三种方式
开发dom4j要导入dom4j的包
1、读取XML文件,获得document对象
SAXReader reader = new SAXReader( );//创建一个解析器
Document document = reader.read(new File("src/ input.xml"));/ /XML Document
2、解析XML形式的文本,得到document对象。
String, text = "<members> </ members> ";
Document document = DocumentHelper.parseText(text);
3、主动创建document对象。
Document document = DocumentHelper.createDocument( );//创建根节点.
Element root = document.addElement("members");
4.应用实例 - 增删改查(主要是查)
DEBUG底层

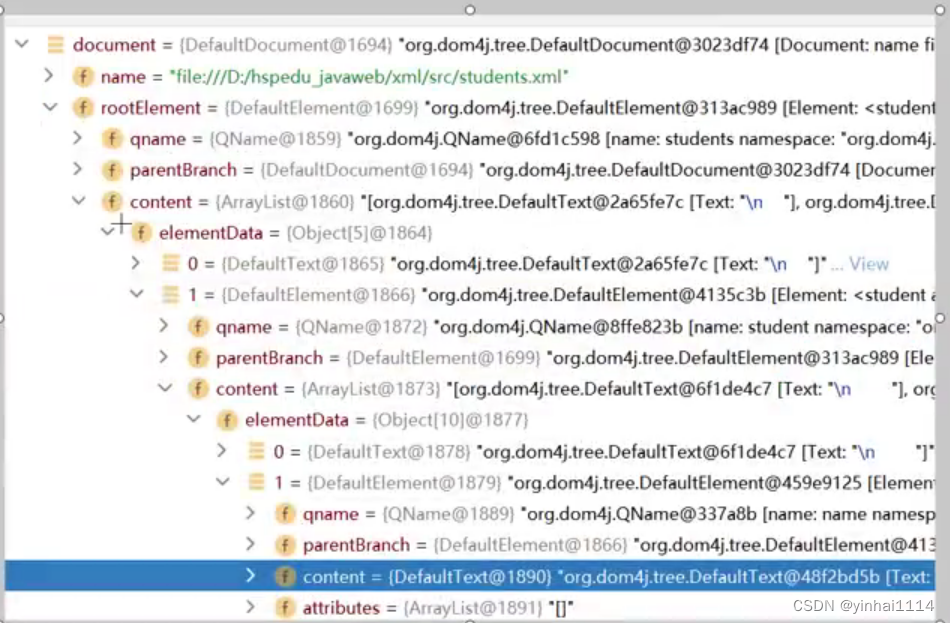
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.jupiter.api.Test;import java.io.File;
import java.io.FileOutputStream;
import java.util.List;/*** @author 韩顺平* @version 1.0*/
public class Dom4j_ {/*** 演示如何加载xml文件*/@Testpublic void loadXML() throws DocumentException {//得到一个解析器SAXReader reader = new SAXReader();//老师的代码技巧->debug 看看document对象的属性//分析了document对象的底层结构Document document = reader.read(new File("src/students.xml"));System.out.println(document);}/*** 遍历所有的student信息*/@Testpublic void listStus() throws DocumentException {//得到一个解析器SAXReader reader = new SAXReader();//老师的代码技巧->debug 看看document对象的属性//分析了document对象的底层结构Document document = reader.read(new File("src/students.xml"));//1. 得到rootElement, 你是OOPElement rootElement = document.getRootElement();//2. 得到rootElement的student ElementsList<Element> students = rootElement.elements("student");//System.out.println(student.size());//2for (Element student : students) {//element就是Student元素/节点//获取Student元素 的name ElementElement name = student.element("name");Element age = student.element("age");Element resume = student.element("resume");Element gender = student.element("gender");System.out.println("学生信息= " + name.getText() + " " + age.getText() +" " + resume.getText() + " " + gender.getText());}}/*** 指定读取第一个学生的信息 更好的方式就是 dom4j+xpath*/@Testpublic void readOne() throws DocumentException {//得到一个解析器SAXReader reader = new SAXReader();//老师的代码技巧->debug 看看document对象的属性//分析了document对象的底层结构Document document = reader.read(new File("src/students.xml"));//1. 得到rootElementElement rootElement = document.getRootElement();//2. 获取第一个学生Element student = (Element) rootElement.elements("student").get(1);//3. 输出该信息System.out.println("该学生的信息= " + student.element("name").getText() + " " +student.element("age").getText() + " " + student.element("resume").getText() +student.element("gender").getText());//4. 获取student元素的属性System.out.println("id= " + student.attributeValue("id"));}/*** 加元素(要求: 添加一个学生到xml中) [不要求,使用少,了解]* @throws Exception*/@Testpublic void add() throws Exception {//1.得到解析器SAXReader saxReader = new SAXReader();//2.指定解析哪个xml文件Document document = saxReader.read(new File("src/students.xml"));//首先我们来创建一个学生节点对象Element newStu = DocumentHelper.createElement("student");Element newStu_name = DocumentHelper.createElement("name");//如何给元素添加属性newStu.addAttribute("id", "04");newStu_name.setText("宋江");//创建age元素Element newStu_age = DocumentHelper.createElement("age");newStu_age.setText("23");//创建resume元素Element newStu_intro = DocumentHelper.createElement("resume");newStu_intro.setText("梁山老大");//把三个子元素(节点)加到 newStu下newStu.add(newStu_name);newStu.add(newStu_age);newStu.add(newStu_intro);//再把newStu节点加到根元素document.getRootElement().add(newStu);//直接输出会出现中文乱码:OutputFormat output = OutputFormat.createPrettyPrint();output.setEncoding("utf-8");//输出的编码utf-8//把我们的xml文件更新// lets write to a file//new FileOutputStream(new File("src/myClass.xml"))//使用到io编程 FileOutputStream 就是文件字节输出流XMLWriter writer = new XMLWriter(new FileOutputStream(new File("src/students.xml")), output);writer.write(document);writer.close();}/*** //删除元素(要求:删除第一个学生) 使用少,了解* @throws Exception*/@Testpublic void del() throws Exception {//1.得到解析器SAXReader saxReader = new SAXReader();//2.指定解析哪个xml文件Document document = saxReader.read(new File("src/students.xml"));//找到该元素第一个学生Element stu = (Element) document.getRootElement().elements("student").get(2);//删除元素stu.getParent().remove(stu);
// //删除元素的某个属性
// stu.remove(stu.attribute("id"));//更新xml//直接输出会出现中文乱码:OutputFormat output = OutputFormat.createPrettyPrint();output.setEncoding("utf-8");//输出的编码utf-8//把我们的xml文件更新XMLWriter writer = new XMLWriter(new FileOutputStream(new File("src/students.xml")), output);writer.write(document);writer.close();System.out.println("删除成功~");}/*** //更新元素(要求把所有学生的年龄+3) 使用少,了解* @throws Exception*/@Testpublic void update() throws Exception {//1.得到解析器SAXReader saxReader = new SAXReader();//2.指定解析哪个xml文件Document document = saxReader.read(new File("src/students.xml"));//得到所有学生的年龄List<Element> students = document.getRootElement().elements("student");//遍历, 所有的学生元素的age+3for (Element student : students) {//取出年龄Element age = student.element("age");age.setText((Integer.parseInt(age.getText()) + 3) + "");}//更新//直接输出会出现中文乱码:OutputFormat output = OutputFormat.createPrettyPrint();output.setEncoding("utf-8");//输出的编码utf-8//把我们的xml文件更新XMLWriter writer = new XMLWriter(new FileOutputStream(new File("src/students.xml")), output);writer.write(document);writer.close();System.out.println("更新成功~");}
}
对应的XML文件
<?xml version="1.0" encoding="utf-8"?><students> <student id="01"> <name>小龙女</name> <gender>女</gender> <age>19</age> <resume>古墓派掌门人</resume> </student> <student id="02"> <name>欧阳锋</name> <gender>男</gender> <age>21</age> <resume>白驼山,蛤蟆神功</resume> </student>
</students>
5.课后作业
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;import java.io.File;
import java.util.List;/*** @author 韩顺平* @version 1.0*/
public class Homework {public static void main(String[] args) throws DocumentException {//1.得到解析器SAXReader saxReader = new SAXReader();//2.指定解析哪个xml文件Document document = saxReader.read(new File("src/books.xml"));//3.遍历所有的book元素List<Element> books = document.getRootElement().elements("book");for (Element book : books) {//取出book元素的所有信息Element name = book.element("name");Element author = book.element("author");Element price = book.element("price");String id = book.attributeValue("id");//创建成Book对象Book book1 = new Book();book1.setId(Integer.parseInt(id));book1.setName(name.getText());book1.setPrice(Double.parseDouble(price.getText()));book1.setAuthor(author.getText());System.out.println("book1对象信息= " + book1);}}
}