事先声明
笔者最近需要查看一些数据,自己挨个找太麻烦了,于是简单的学了一下爬虫。笔者在这里声明,爬的数据只为学术用,没有其他用途,希望来这篇文章学习的同学能抱有同样的目的。
枪本身不坏,坏的是使用枪的人
效果
基于JAVA语言实现爬取js渲染后的页面,详细教程
- 下载ChromeDriver
- 下载ChromeDrive以及相对应的Chrome
- 禁止Chrome自动升级
- 第一步:禁用任务计划
- 第二步:禁用更新服务
- 第三步:重命名更新程序
- 使用IDEA实现爬取js渲染后的页面
- 所需依赖
- 修改maven的镜像地址
- 具体实现
- 建议
- WebMagic
- 一个简单的demo
- 实现思路
- 使用Selenium解析js渲染后的页面信息
- 重写自定义pageProcessor的process方法
- 项目代码
下载ChromeDriver
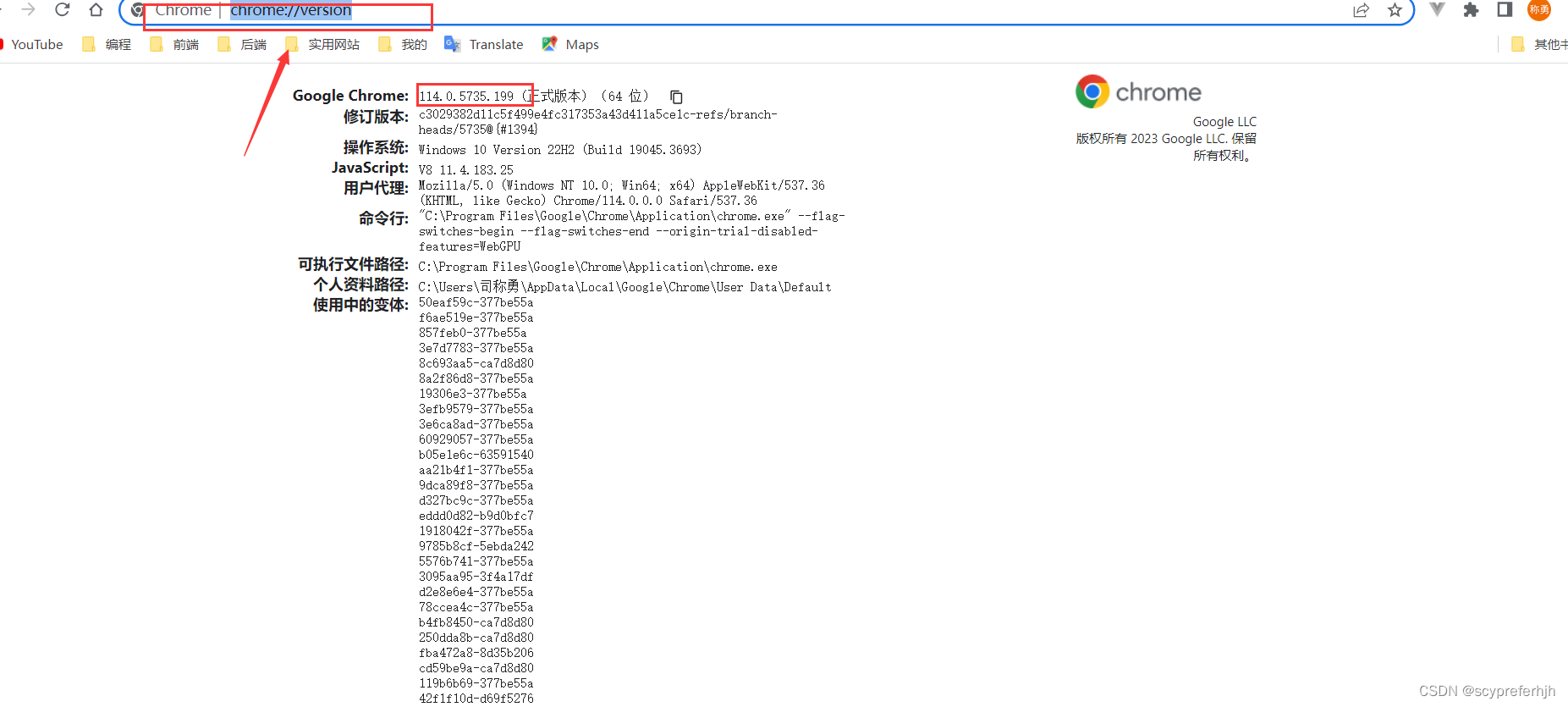
查看自己的Chrome版本,过高需要卸载再下载
在地址栏键入
chrome://version/
查看版本
下载ChromeDrive以及相对应的Chrome
ChromeDriver的版本需要仔细考究,一个ChromeDriver版本对应一个Chrome版本,由于Chrome版本更新太快,最近已经到119.xx了,ChromeDriver最高支持版本才115.xx, 因此我们要先把本地的Chrome卸载,然后下载相应的历史版本
Chrome历史版本1
Chrome历史版本2 版本更多更全面
ChromeDriver历史版本
笔者以114为例子
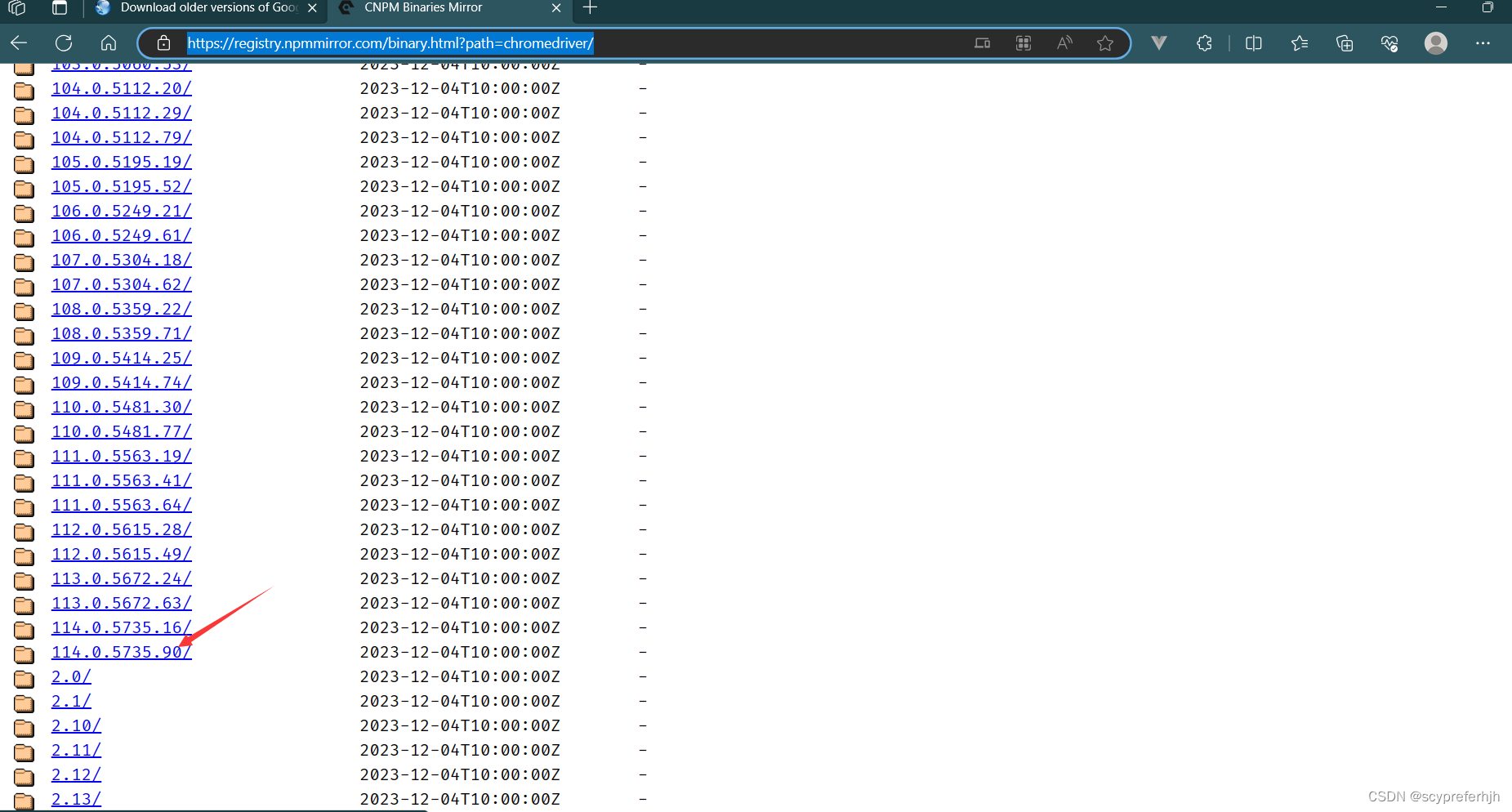
点击后会进入下载页,里面有windows版本以及note.txt,在txt文件中会写有支持哪个Chrome版本

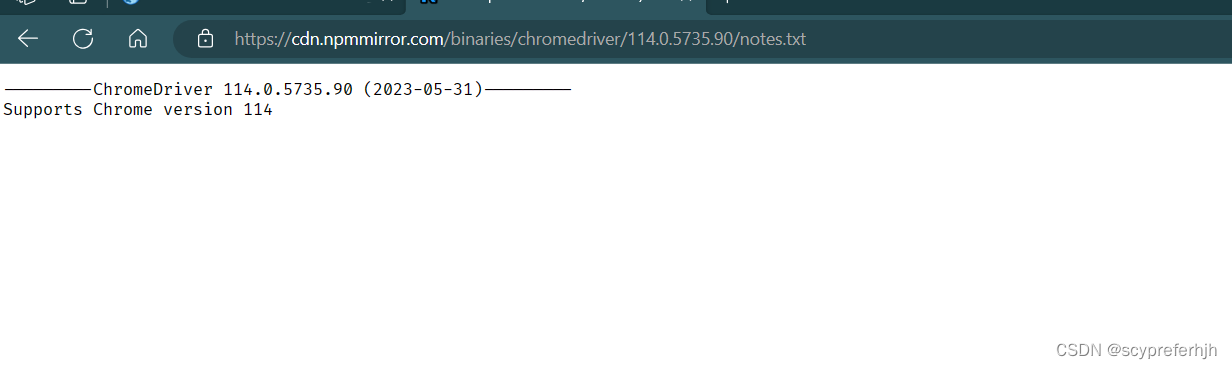
我上面给出的Chrome历史版本1中没有114版本,在历史版本2中有,可以自行去下载
禁止Chrome自动升级
由于Chrome更新太快,ChromeDriver跟不上,并且Chrome总是自动升级,这里给出禁止Chrome自动升级的解决办法1。
第一步:禁用任务计划
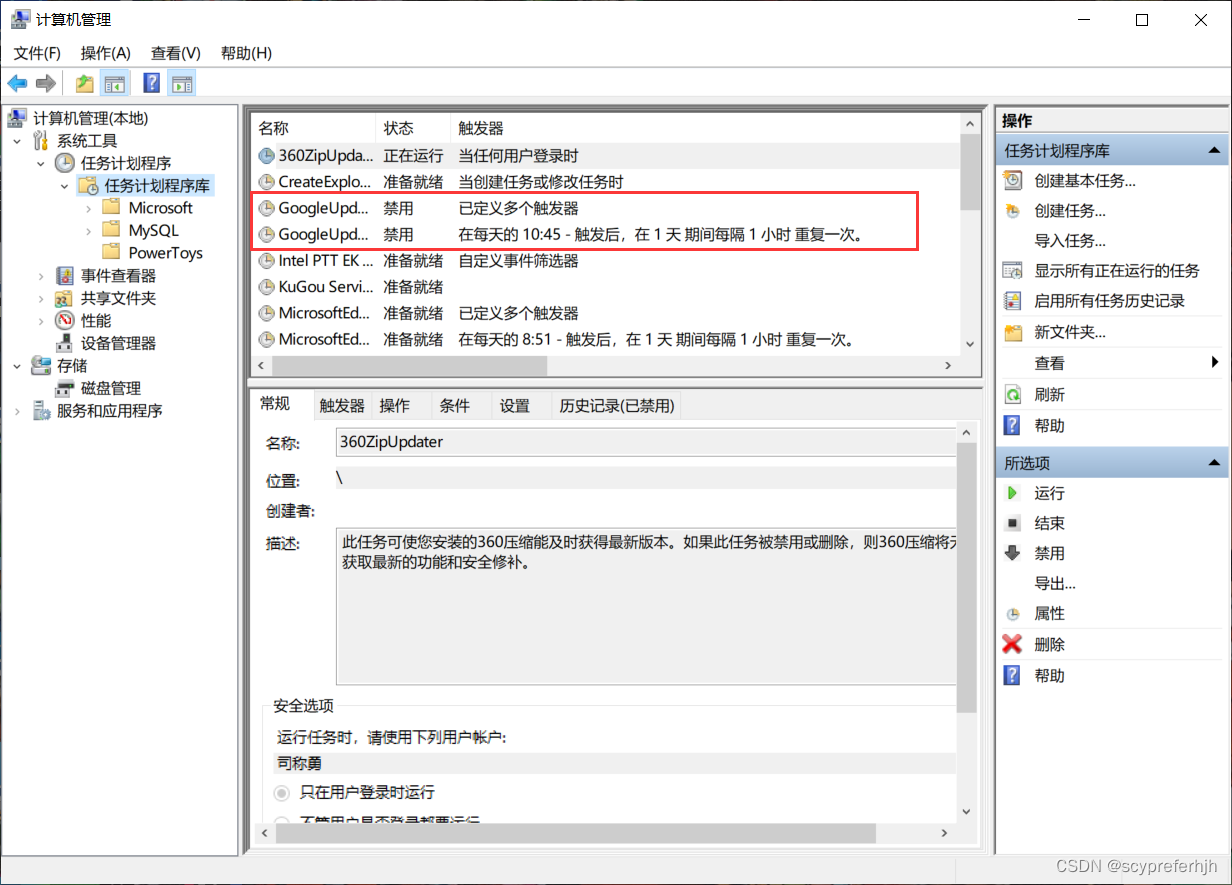
首先是【右键计算机->管理】,在【计算机管理(本地)->系统工具->任务计划程序->任务计划程序库】中找到两个和Google自动更新相关的任务计划【GoogleUpdateTaskMachineCore】与【GoogleUpdateTaskMachineUA】,并把它俩禁用掉。
第二步:禁用更新服务
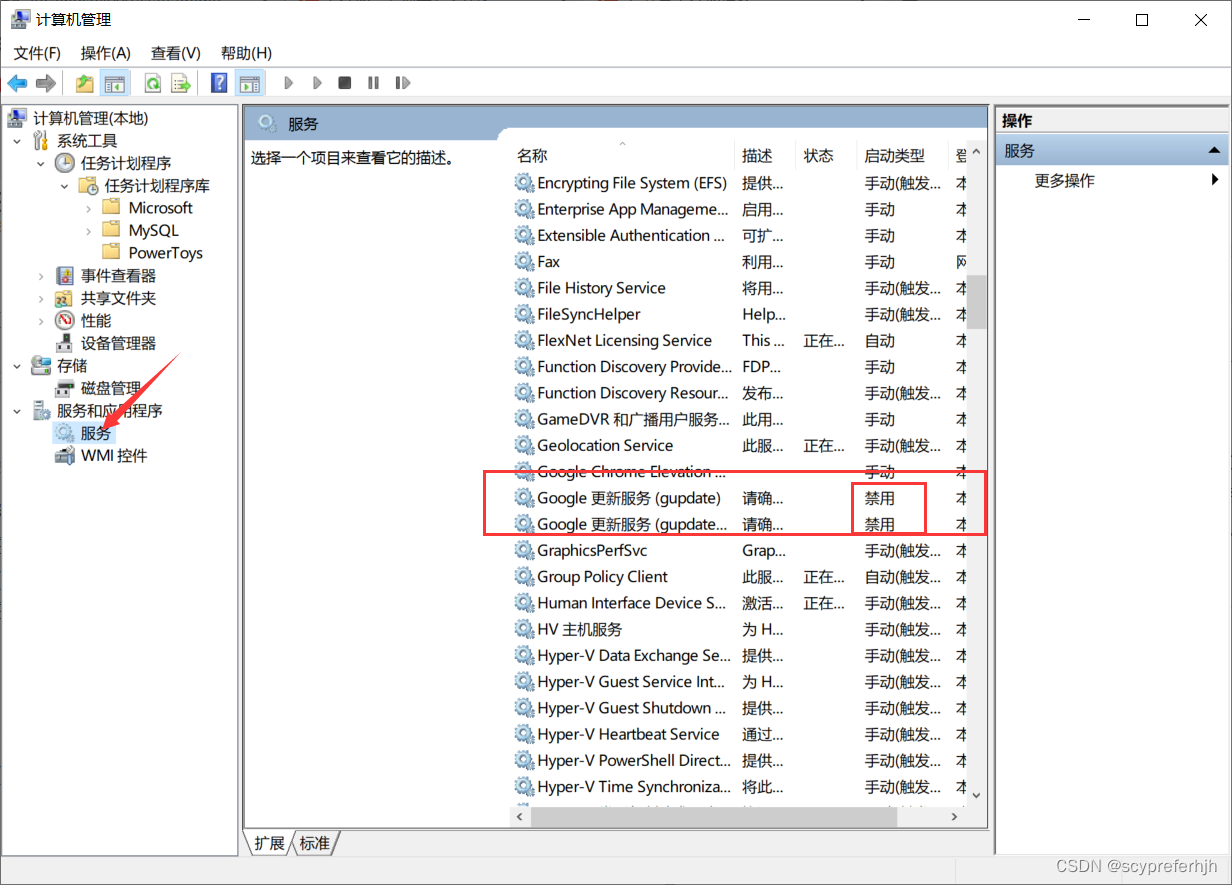
然后在下方的【服务和应用程序->服务】中,找到两个和Google更新相关的服务【Google更新服务(gupdate)】、【Google更新服务(gupdatem)】,并右键,选择属性,把启动类型改为禁用。如果没有找到的可以略过。
第三步:重命名更新程序
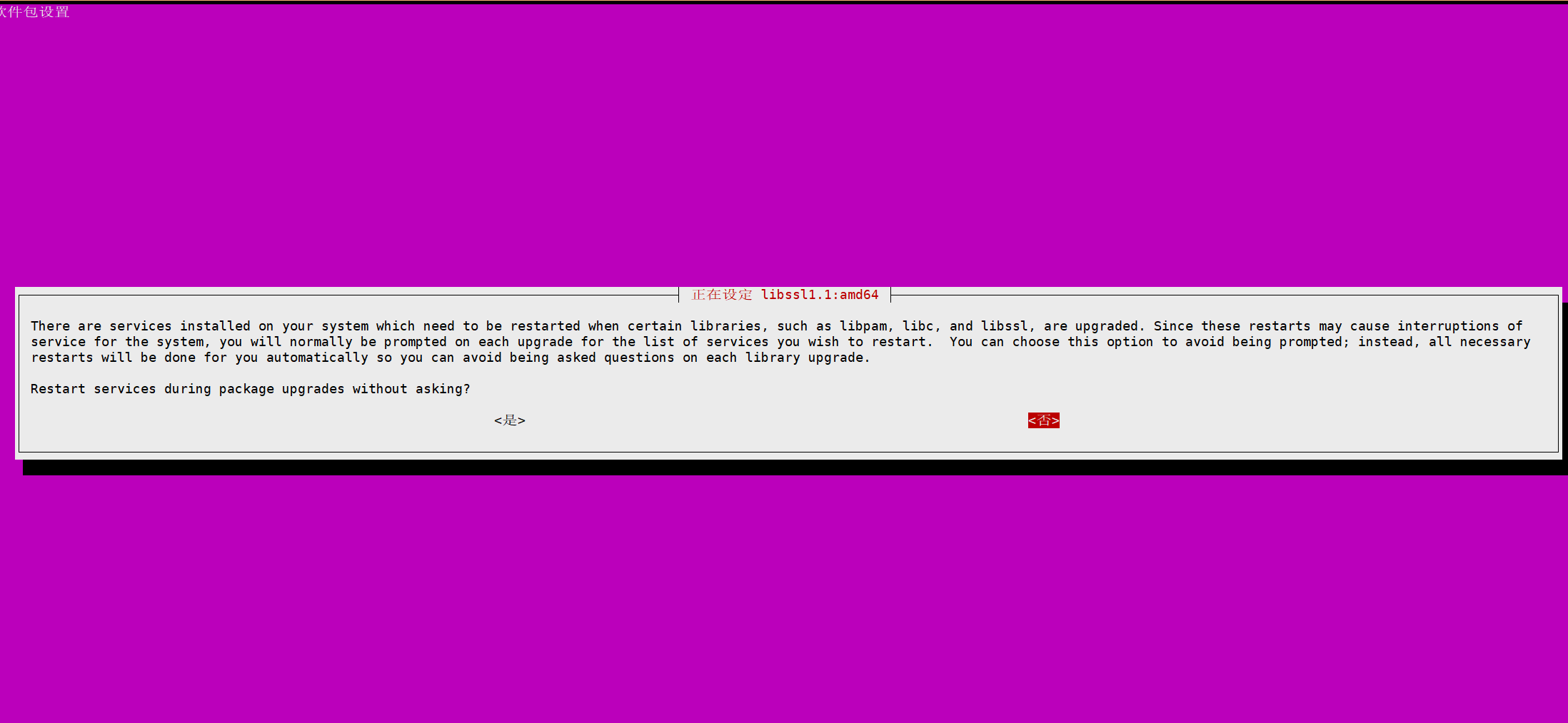
完成上面两步后理论上就可以停止Chrome的自动更新了,不过有网友说这么做之后,不要在Chrome中点击【帮助->关于Google Chrome】
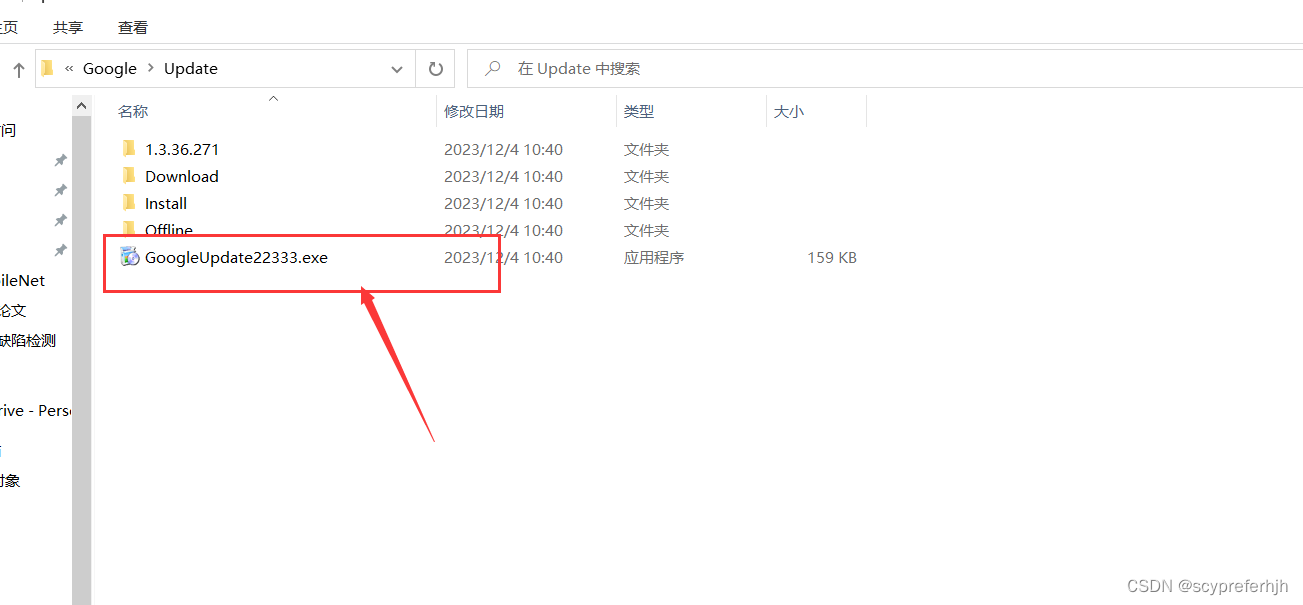
这里笔者尝试过,确实有这种情况,为了避免,我们可以修改他的update.exe的名字:
笔者给出自己电脑上update的地址:(没有修改Chrome默认安装地址)
C:\Program Files (x86)\Google\Update
修改这个名字,如果你在这个位置没有找到,可以参考资料1的位置
到这里就结束了,在地址栏键入
chrome://version/
查看当前版本
不过笔者没有再尝试在Chrome中点击【帮助->关于Google Chrome】是否会更新,大胆的小伙伴可以试试
使用IDEA实现爬取js渲染后的页面
爬取的页面: 国家统计局发布的数据
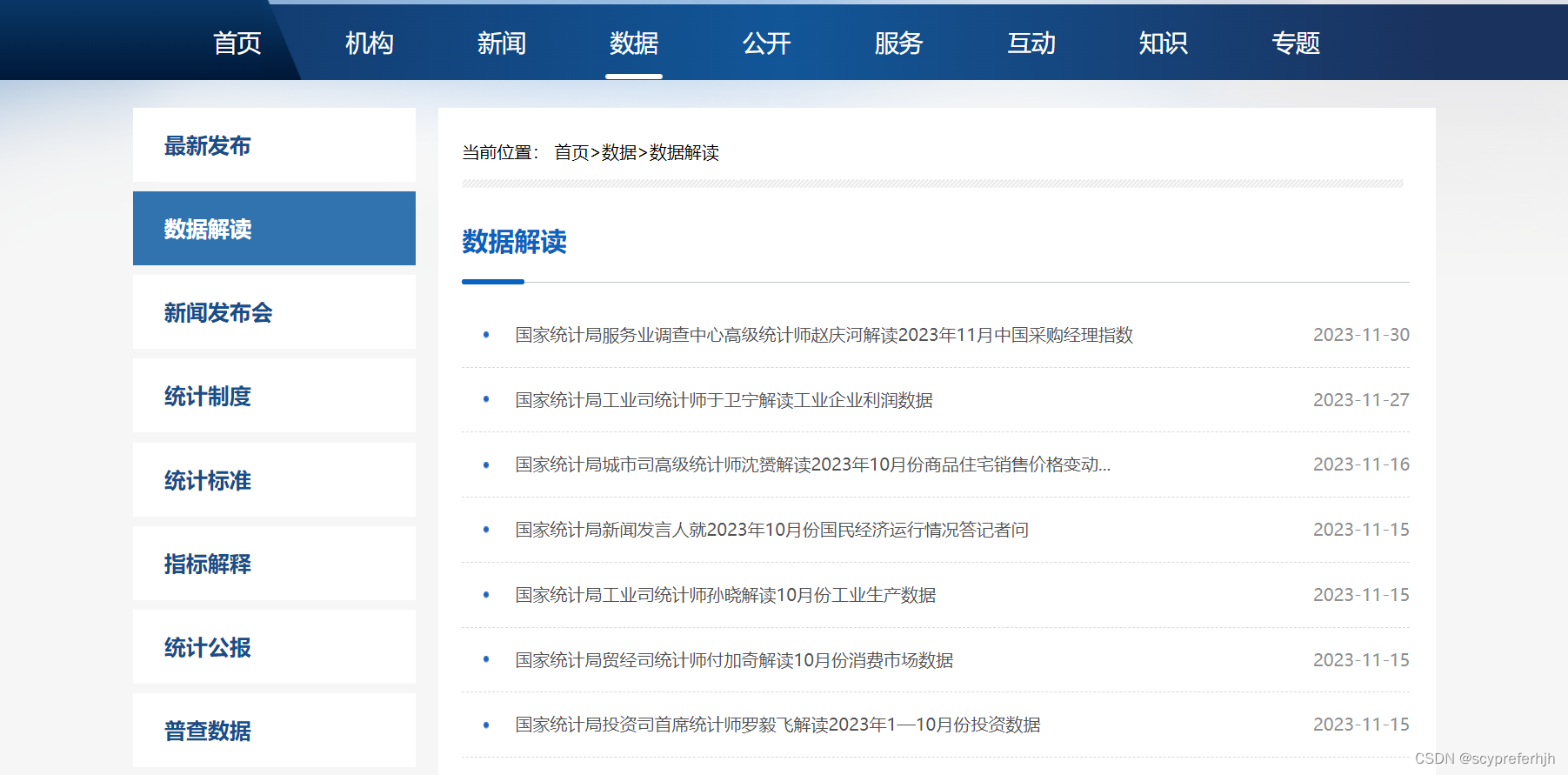
相应的版本
SpringBoot 2.6.13
Webmagic: 0.8.0
Selenium-java 3.141.59
现在SpringInitializer已经不支持SpringBoot2.x了,你可以升级使用SpringBoot3,再使用下面代码或者参考我另一篇文章使用SpringBoot2:Spring Initializer 已经不支持Java8,也就是SpringBoot2.x项目初始化
所需依赖
下面依赖有些你可能不需要 比如thymeleaf,不过都加上也不会报错
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--Mybatis-plus--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-generator</artifactId><version>3.3.2</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-extension</artifactId><version>3.3.2</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-extension</artifactId><version>3.5.1</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-extension --><dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions><version>0.8.0</version></dependency><!-- https://mvnrepository.com/artifact/com.google.guava/guava --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>32.1.3-jre</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--模拟浏览器行为--><!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java --><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId></dependency></dependencies>
修改maven的镜像地址
下载semenium的依赖需要的时间会比较长,而且下载webmagic依赖的时候有些包在阿里云Central镜像下找不到, 需要修改为all
打开配置文件
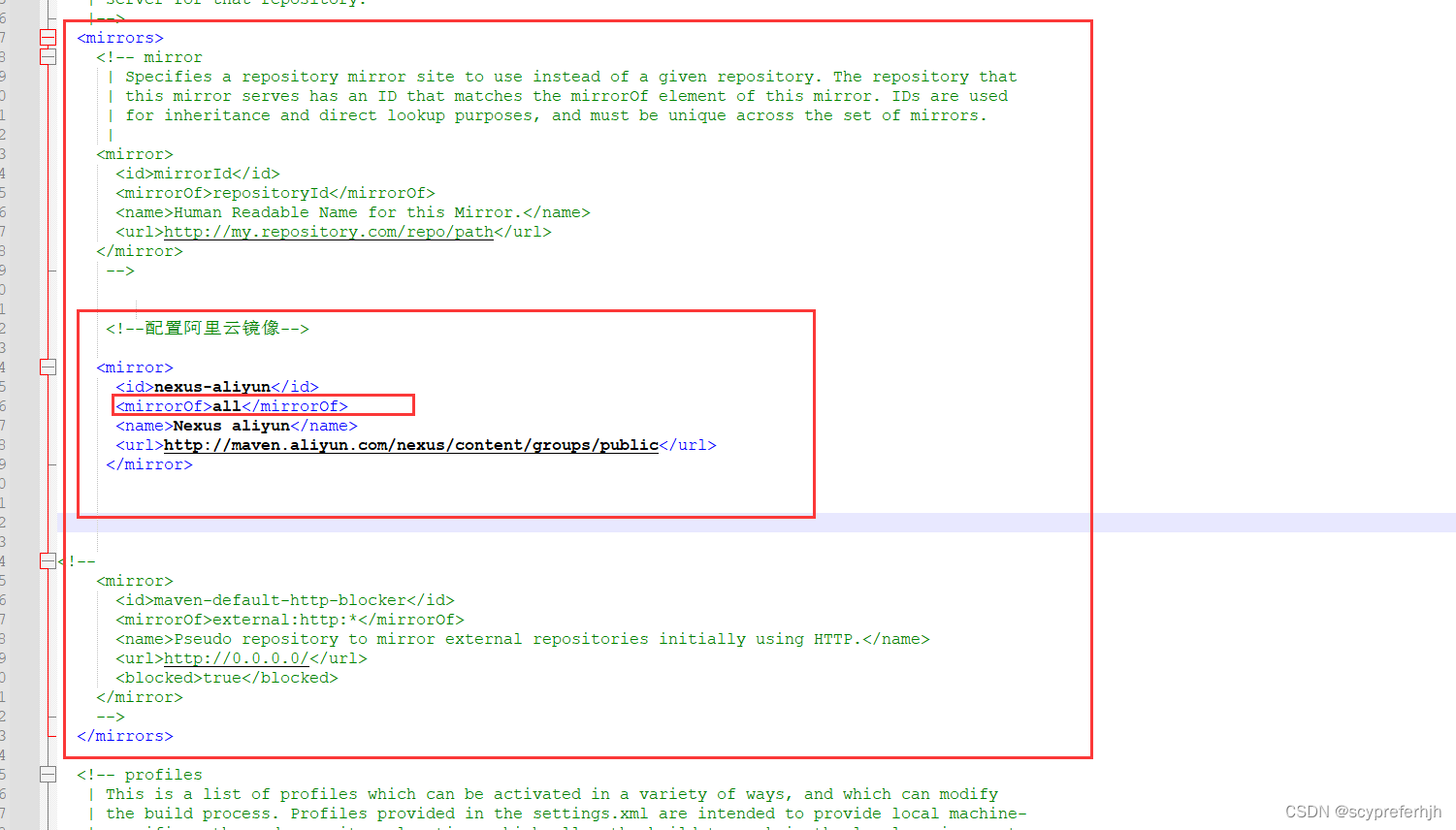
修改完保存即可
具体实现
建议
再看下面代码之前,还是要有一定的webmagic基础的,推荐BiliBili上一个教程,只需要两个多小时就能理解webmagic的工作流程Java爬虫案例实战-webmagic(第二话) 2021最新
WebMagic
WebMagic中文文档

从图中可以看到Spider是爬虫启动的关键入口。
我们要做的就是自定义一个xxPageProcessor,实现PageProcessor接口,重写两个方法
Site, process。
在process方法中将抓取到的url地址添加到scheduler队列中,图中一个request其实是一个url地址,并不是http的请求;
其中resultItems保存的是向pipeline中写入的数据,是一个linkedhash结构
pipeline是输出的关键,可以向控制台中输出,也可以自定义一个pipeline,向数据库中写入信息
Scheduler默认是内存队列,可以修改为redis队列(成本高)
Download我这里没有自定义,不过官网给出了自定义的方法,感兴趣的可以看看
一个简单的demo
/*** @Author:sichenyong* @Email: sichenyongwork@163.com* @Package:com.scy* @Project:crawer* @Date:2023/12/2 19:45* @description:使用css选择器解析*/
@Slf4j
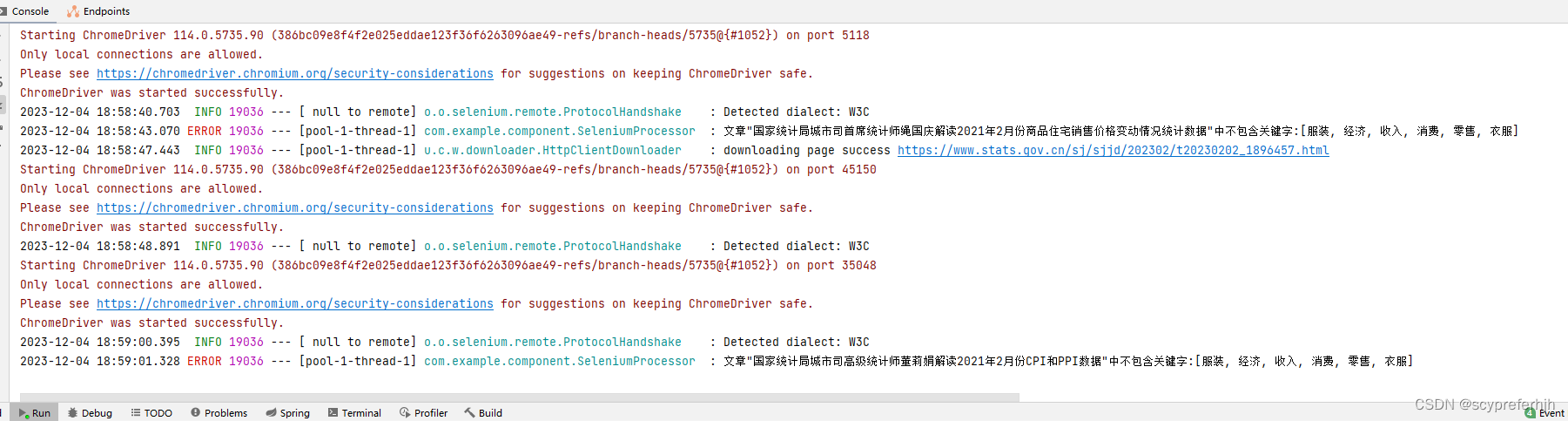
public class MyPageProcessor2 implements PageProcessor {public void process(Page page) {Html html = page.getHtml();String title = html.css("title", "text").get();log.info("title is {}", title);page.putField("title", title);String s = html.css("a", "href").get();// 向resultItems中写入数据page.putField("a", s);List<String> all = html.css("a", "href").all();page.putField("allLinks", all);page.putField("html",html);}public Site getSite() {return Site.me();}public static void main(String[] args) {MyPageProcessor2 myPageProcessor2 = new MyPageProcessor2();Spider.create(myPageProcessor2).addUrl("https://www.stats.gov.cn/sj/sjjd/202311/t20231115_1944598.html").start();}
}实现思路
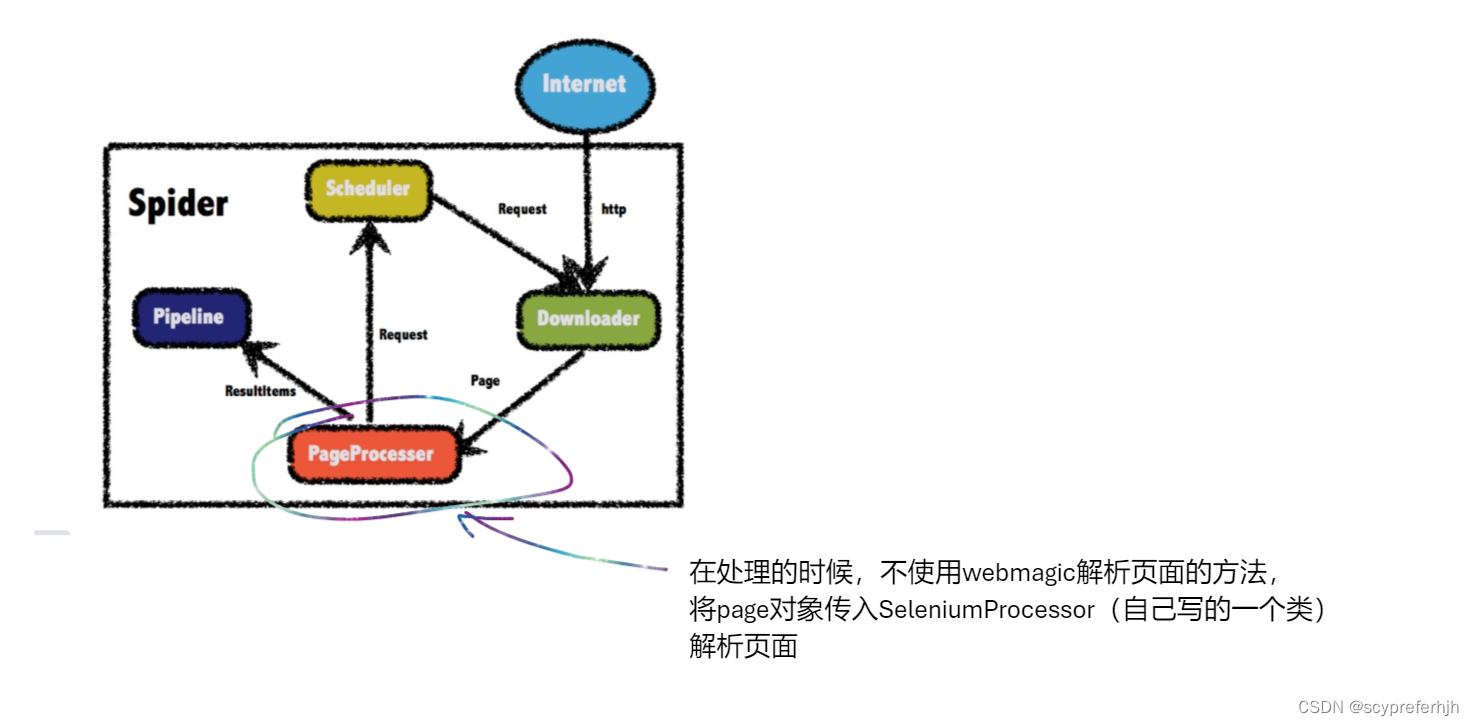
相较于webmagic的架构,我们只需要在process方法中使用selenium的解析方法获取js加载后的数据就可以
使用Selenium解析js渲染后的页面信息
-
首先定义初始化chromedriver的函数
private String devicePath = "D:\\SoftWare\\environemnt\\chromeDriver\\chromedriver.exe"; private ChromeDriver webDriver;void setUp(){System.getProperties().setProperty("webdriver.chrome.driver",devicePath);ChromeOptions options = new ChromeOptions();options.addArguments("--headless");webDriver = new ChromeDriver(options);webDriver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS); } -
实现解析函数
/*** @description:解析js加载后的页面,获取相关信息* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/4 16:43* @param: [page]* @return: com.example.entity.UsefulMessage**/UsefulMessage parseJS(Page page) {UsefulMessage usefulMessage = new UsefulMessage();String url = page.getUrl().get();webDriver.get(url);// 获取所有的a标签地址List<WebElement> aElements = webDriver.findElements(By.cssSelector("div.list-content > ul > li > a.fl.mhide.pc1200"));if (aElements.size() > 0) {List<String> hrefValue = new ArrayList<>();for (WebElement aElement : aElements) {hrefValue.add(aElement.getAttribute("href"));}// 设置列表地址usefulMessage.setHrefs(hrefValue);// 设置是否是列表页usefulMessage.setListPage(true);// 获取下一页的地址WebElement element = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.wrapper-list-right > div.list-pager.mhide > a.next"));String nextUrl = element.getAttribute("href");//设置下一页的url地址usefulMessage.setNextPageUrl(nextUrl);log.info("===下一页地址===" + nextUrl);String column = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.wrapper-list-left.mhide > div > ul > li.active")).getText();// 设置栏目usefulMessage.setColumn(column);}webDriver.quit();return usefulMessage;} -
完整代码
/** * @Author:sichenyong * @Email: sichenyongwork@163.com * @Package:com.example.component * @Project:selenium * @Date:2023/12/3 22:02 * @description:使用selenium解析js加载之后的页面信息 * @Version:1.0 由于笔者没有学过设计模式,因此写的代码有些冗余,见谅。 */ @Slf4j public class SeleniumProcessor {//下载的ChromeDriver地址private String devicePath = "D:\\SoftWare\\environemnt\\chromeDriver\\chromedriver.exe";private ChromeDriver webDriver;void setUp(){System.getProperties().setProperty("webdriver.chrome.driver",devicePath);ChromeOptions options = new ChromeOptions();options.addArguments("--headless");webDriver = new ChromeDriver(options);webDriver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);}/*** @description:解析js加载后的页面,获取相关信息* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/4 16:43* @param: [page]* @return: com.example.entity.UsefulMessage**/UsefulMessage parseJS(Page page) {// 自定义的实体类,保存自己向要的js生成的信息UsefulMessage usefulMessage = new UsefulMessage();String url = page.getUrl().get();webDriver.get(url);// 获取所有的a标签地址List<WebElement> aElements = webDriver.findElements(By.cssSelector("div.list-content > ul > li > a.fl.mhide.pc1200"));if (aElements.size() > 0) {List<String> hrefValue = new ArrayList<>();for (WebElement aElement : aElements) {hrefValue.add(aElement.getAttribute("href"));}// 设置列表地址usefulMessage.setHrefs(hrefValue);// 设置是否是列表页usefulMessage.setListPage(true);// 获取下一页的地址WebElement element = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.wrapper-list-right > div.list-pager.mhide > a.next"));String nextUrl = element.getAttribute("href");//设置下一页的url地址usefulMessage.setNextPageUrl(nextUrl);log.info("===下一页地址===" + nextUrl);String column = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.wrapper-list-left.mhide > div > ul > li.active")).getText();// 设置栏目usefulMessage.setColumn(column);}webDriver.quit();return usefulMessage;}/*** @description: 解析网页的数据* parse可以根据需要进行修改,爬取你想要的* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/4 14:20* @param: [page, filterTitle]* @return: void**/void parse(Page page, String filterTitle, String column) {try {// 获取urlString url = page.getUrl().get();webDriver.get(url);// 获取标题String title = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > h1")).getText();if (title.contains(filterTitle)) {// 创建数据库实体Stats stats = new Stats();// 读入当前页的urlstats.setPubUrl(url);// 读入titlestats.setWebTitle(title);// 读入栏目stats.setPubColumn(column);// 获取数据来源WebElement source = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > div > h2:nth-child(1) > span"));String pubSources = source.getText();String regex = ":";if (pubSources.contains(":")) {regex = ":";}String[] strings = pubSources.split(regex);String pubSource = strings[strings.length-1];stats.setPubSource(pubSource);// 获取发布时间String pubTime = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > div > h2:nth-child(1) > p")).getText();pubTime = pubTime.replaceAll("/","-");stats.setPubTime(pubTime);// 存入数据库page.putField("stats",stats);}else {log.error("文章\"" + title + "\"中不包含关键字:{}", filterTitle);page.getResultItems().setSkip(true);}} catch (Exception e) {e.printStackTrace();}finally {webDriver.quit();}}/*** @description: 需要过滤的数据有多个* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/4 14:21* @param: [page, filterTitles]* @return: void**/void parse(Page page, List<String> filterTitles,String column) {try {// 获取urlString url = page.getUrl().get();webDriver.get(url);// 获取标题String title = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > h1")).getText();if (support(title, filterTitles)) {// 创建数据库实体Stats stats = new Stats();// 读入当前页的urlstats.setPubUrl(url);// 读入titlestats.setWebTitle(title);// 读入栏目stats.setPubColumn(column);// 获取数据来源WebElement source = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > div > h2:nth-child(1) > span"));String pubSources = source.getText();String regex = ":";if (pubSources.contains(":")) {regex = ":";}String[] strings = pubSources.split(regex);String pubSource = strings[strings.length-1];stats.setPubSource(pubSource);// 获取发布时间String pubTime = webDriver.findElement(By.cssSelector("body > div > div.wrapper-content > div > div.detail-title > div > h2:nth-child(1) > p")).getText();pubTime = pubTime.replaceAll("/","-");stats.setPubTime(pubTime);// 存入数据库page.putField("stats",stats);}else {log.error("文章\"" + title + "\"中不包含关键字:{}", filterTitles);page.getResultItems().setSkip(true);}} catch (Exception e) {e.printStackTrace();}finally {webDriver.quit();}}/*** @description:判断title是否在想要的列表中* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/4 14:28* @param: [title, filterTitles]* @return: boolean**/boolean support(String title, @NotNull List<String> filterTitles) {for (String filterTitle : filterTitles) {if (title.contains(filterTitle)) {return true;}}return false;} }
重写自定义pageProcessor的process方法
/*** @Author:sichenyong* @Email: sichenyongwork@163.com* @Package:com.scy.component* @Project:stats* @Date:2023/12/3 13:25* @description:*/
@AllArgsConstructor
@NoArgsConstructor
@Data
@Slf4j
public class StatsPageProcessor implements PageProcessor {/*** @description: 过滤标题文章,保存含有filterTitle的文章* demo: filterTitle = "Java"* 函数会自动保存所有含有Java的文章,将不含有java的文章过滤掉* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/3 14:03**/protected String filterTitle="";protected List<String> filterTitles;private String column;@Overridepublic void process(Page page) {SeleniumProcessor seleniumProcessor1 = new SeleniumProcessor();seleniumProcessor1.setUp();// 获取解析js后的网页信息UsefulMessage usefulMessage = seleniumProcessor1.parseJS(page);// 是列表页if (usefulMessage.isListPage()) {// 获取所有的链接List<String> links = usefulMessage.getHrefs();// 传给Schedulerpage.addTargetRequests(links);// 解析下一页String nextPage = usefulMessage.getNextPageUrl();page.addTargetRequest(nextPage);column = usefulMessage.getColumn();// 列表页面的数据不写入数据库page.getResultItems().setSkip(true);}else {// 详情页面写入数据库
// parseStats(page);SeleniumProcessor seleniumProcessor = new SeleniumProcessor();seleniumProcessor.setUp();if (filterTitles == null) {seleniumProcessor.parse(page, filterTitle, column);}else {seleniumProcessor.parse(page, filterTitles, column);}}}/*** @description: 解析详情页面 - 无法解析js加载的页面* @Deprecated* @param: page* @return: void* @author: sichenyong* @email: sichenyongwork@163.com* @date: 2023/12/3 14:04**/@Deprecatedprivate void parseStats(Page page) {Html html = page.getHtml();// 获取页面的标题String title = html.css("body > div > div.wrapper-content > div > div.detail-title > h1","text").get();// 如果文章中包含filterTitle,则保存文章if (title.contains(filterTitle)) {Stats stats = new Stats();//获取当前页面的urlString currentUrl = page.getUrl().get();// 获取当前页面的pubtimeString pubTime = html.css("body > div > div.wrapper-content > div > div.detail-title > div > h2:nth-child(1) > p", "text").get();// 获取页面的来源String pubSources = html.xpath("/html/body/div/div[3]/div/div[1]/div/h2[1]/span/text()").get();String regex = ":";if (pubSources.contains(":")) {regex = ":";}String[] strings = pubSources.split(regex);String pubSource = strings[strings.length-1];stats.setWebTitle(title);stats.setPubUrl(currentUrl);stats.setPubSource(pubSource);stats.setPubTime(pubTime);// 写入数据库page.putField("stats",stats);}}@Overridepublic Site getSite() {Site site = new Site();// 设置重试间隔时间site.setRetryTimes(3);site.setRetrySleepTime(3000);site.setSleepTime(3000);return site;}
}
项目代码
这里笔者使用的是阿里云云效Code代码托管平台,项目地址
三步彻底关闭chrome谷歌浏览
器自动更新; ↩︎ ↩︎