目录
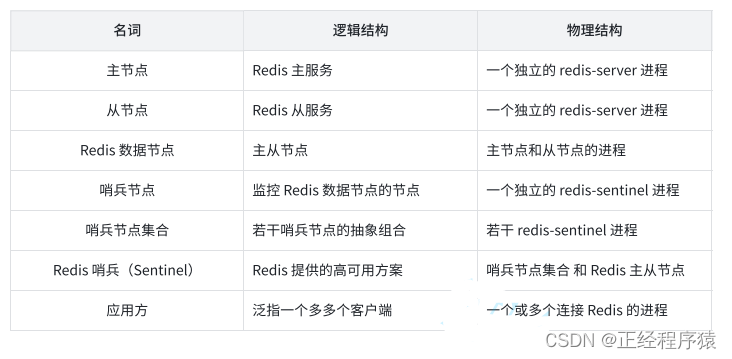
redis sentinel相关名词
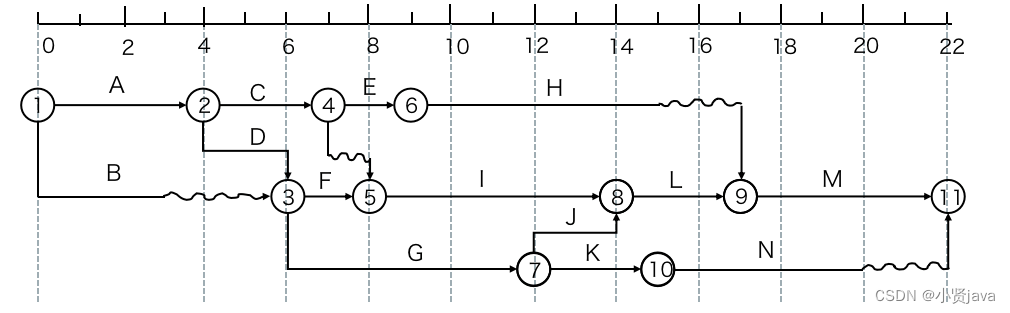
redis sentinel架构
故障转移流程
基于docker搭建redis哨兵
准备工作
搭建过程
模拟主节点宕机,观察哨兵节点的工作流程
哨兵重新选取主节点的流程
1.主观下线
2.客观下线
3.哨兵节点推举出一个leader节点
4.leader选举完毕,leader挑选出一个从节点,作为新的主节点.
关于哨兵的总结
主从模式下,当主节点挂了之后,从节点感知不到主节点之后,无法自动的晋升为主节点,此时就需要人工的干预.
人工如何恢复
1.先查看主节点还能不能恢复,短时间内能不能恢复好.
2.如果主节点不知道是什么原因挂的或者短时间内不好恢复,就需要挑一个从节点,设置为新的主节点.
3.把选中的从节点,通过slaveof no one,升为主节点.
4.把其他的从节点,修改slaveof的ip和port,连接上新的主节点.
5.告知客户端,让客户端能够连接新的主节点,用来完成数据修改的操作.
6.当之前挂掉的主节点恢复好之后,就可以作为一个新的从节点,加入到这组机器中.
显然上述过程是非常繁琐的,而且涉及到人工,不可控性大大提高,并且相对于程序控制来说很低效/
所以redis就引入了哨兵模式.
redis哨兵的核心功能有三个:监控,自动的故障转移和通知.
redis sentinel相关名词
redis sentinel架构
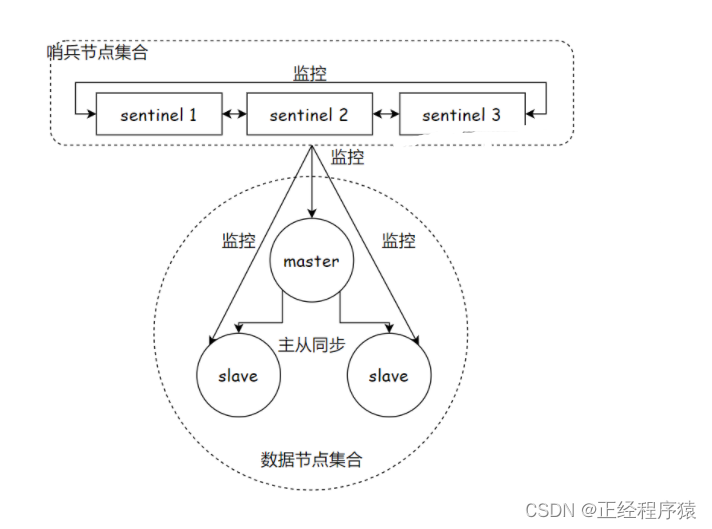
哨兵是单独的redis sentinel进程,并且提供了多个哨兵.
这三个哨兵就会监控现有的主节点和从节点,这些进程之间,会建立tcp长连接,通过这样长连接,定期发送心跳包来实现监控.
借助上述的机制,就可以及时的发现,某个节点是不是挂掉了.
故障转移流程
1.如果是主节点挂了,此时哨兵就要发挥作用.如果一个哨兵节点发现主节点挂了,此时就需要多个哨兵节点来共同认同这件事情,主要是为了防止误判.
2.如果主节点确实是挂了,这些哨兵节点中,就会推举出一个leader,由这个leader负责从现有的从节点中挑选出一个作为新的主节点.
3.挑选出新的主节点之后,哨兵节点就会自动控制被选中的节点,执行slaveof no one命令,并且控制其他从节点修改slaveof到新的主节点上.
4.哨兵节点会自动通知客户端程序,告知对方新的主节点是谁,并且后续客户端进行写操作就是针对新的主节点进行了.
注意:redis哨兵节点只有一个也是可以的,但是只有一个哨兵节点,它自身也是容易出现问题的,如果哨兵节点挂了,就丧失了哨兵的功能;并且只有一个哨兵节点出现误判的概率也会更大.
总之,在分布式系统中应该尽量避免使用单点.
哨兵节点,最好是有奇数个,方便leader的推举.
基于docker搭建redis哨兵
正常来说,六个节点是要在6个不同的服务器主机上,但是此时就只有一个云服务器来使用.
就只能都搭建在一个云服务器上,在实际工作中,把上述节点都部署在一个服务器上,没有实际意义.
由于这些节点依赖的端口号/配置文件/数据文件很多,如果直接部署,很容易出冲突,所以我们使用docker来搭建.
docker可以认为是一个轻量级的虚拟机,它起到了虚拟机隔离环境的效果,并且没有消耗很多硬件资源.即使是配置比较低的云服务器,也可以构造出很多个虚拟的环境.
docker中有两个关键的概念,一个是容器,一个镜像.容器就可以看作是一个轻量级的虚拟机.
镜像和容易的关系就类似于可执行程序和进程之间的关系.
镜像可以自己创建,也可以直接拉取别人已经创建好的.在docker hub上就包含了很多已经创建好的镜像,其中就有redis镜像,我们可以直接拉取使用.
准备工作
1.安装docker和docker-compose
docker-compose是一个用于定义和运行多个Docker容器的工具。使用docker-compose,可以轻松地将复杂的应用程序拆分为多个独立的容器.
2.停止之前的redis服务
以service的方式启动就用service的方式停止,用命令直接的方式,就用kill停止.
3.使用docker获取到redis的镜像
docker pull redis:5.0.9
docker pull使用docker从中央仓库(默认是docker hub)来拉取镜像.
此处拉取的镜像里面就包含了一个精简的Linux操作系统,并且上面安装了redis.只要基于这个镜像创建一个容易跑起来,那么,redis服务器就搭建好了.

搭建过程
我们使用docker-compose来进行容器的编排,此处涉及到多个redis节点,3个数据节点,3个哨兵节点,每一个节点都是作为一个单独的容器,我们总共有6个容器.
通过一个配置文件,把具体要创建哪些容器,每个容器运行时的参数,都描述清楚.后续通过一个简单的命令,就能够批量的启动或者停止这些容器了.
docker-compose的配置文件的格式是yml,并且配置文件的名字固定为docker-compose.yml.
1.创建三个容器,来作为redis的数据节点.
这里包含一个主节点,两个从节点.所以我们要在配置文件中对这三个节点进行配置.

在redis-data目录下,进行配置文件的编写.
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379

为什么不写ip而要写容器名,因为容器启动之后,被分配的ip是不固定的(当然也可以配置静态ip),容器名就类似于域名一样,docker自动的进行域名解析,就能得到对应的ip.
端口映射:在docker容器里,端口号和外面的端口号是两个体系,如果容器外面使用了某个端口号,在容器内部依然可以使用此端口号,不会产生冲突.
端口映射就是为了能在容器外访问到容器内的端口,就可以把容器内的端口映射成为宿主机的端口.
配置文件编写好后,运行这些容器.
docker-compose up -d
使用此命令,-d表示后台运行.

启动之后,可以使用docker ps -a查看所有的容器的运行状况.

使用docker-compose logs命令,获取容器运行日志.
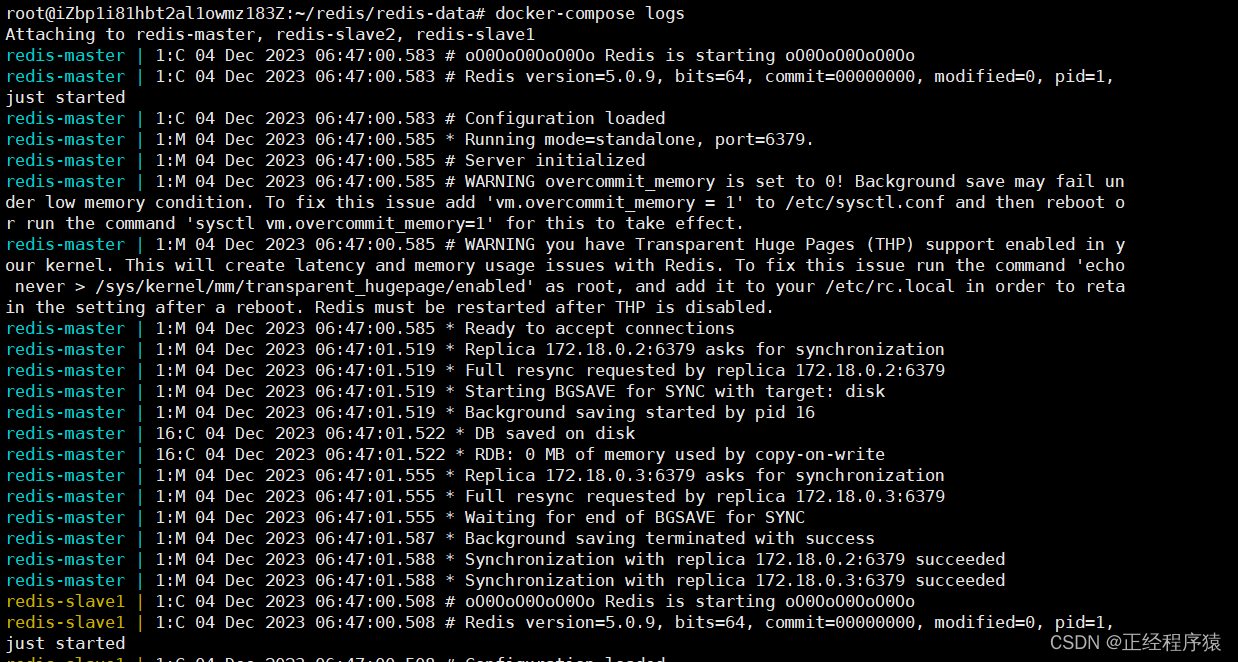
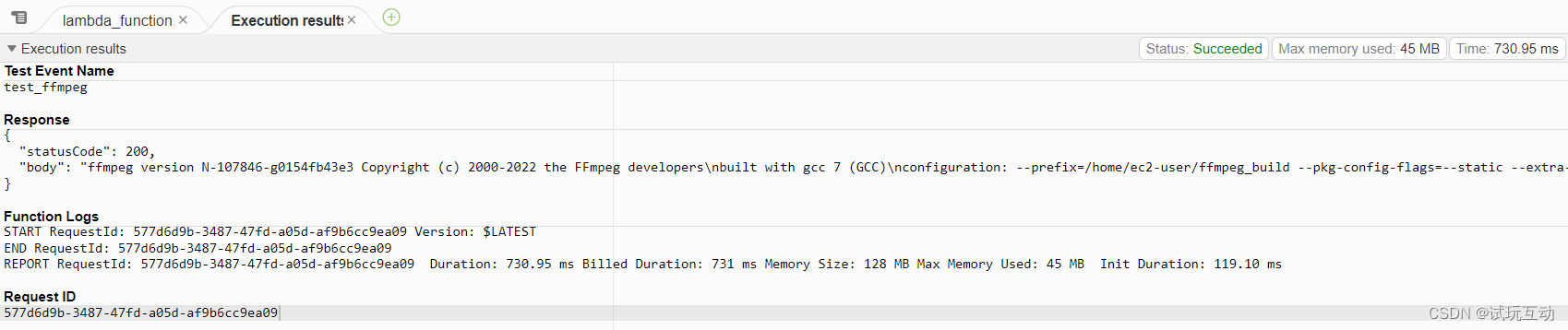
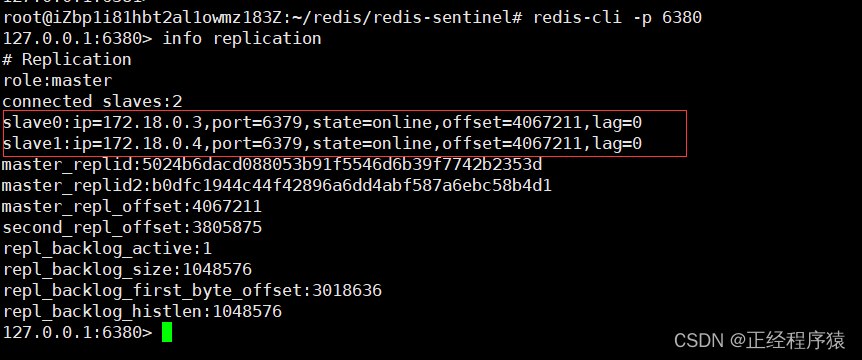
没有问题之后,我们就可以连上客户端通过info replication来查看复制信息.
主节点
从节点的ip都是docker自动分配的,在一个配置文件里的,都会被分配在同一个局域网内,以便它们之间实现网络传输.
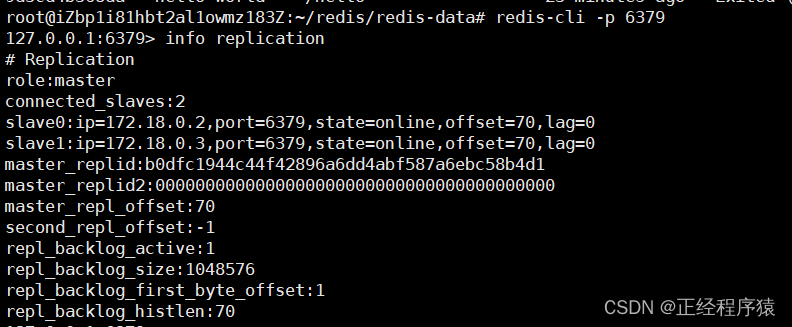
从节点
2.创建3个节点,作为redis的哨兵节点.
redis哨兵节点是单独的redis服务器进程.
在redis-sentinel目录下,编写docker-compose.yml配置文件.
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis-data_default
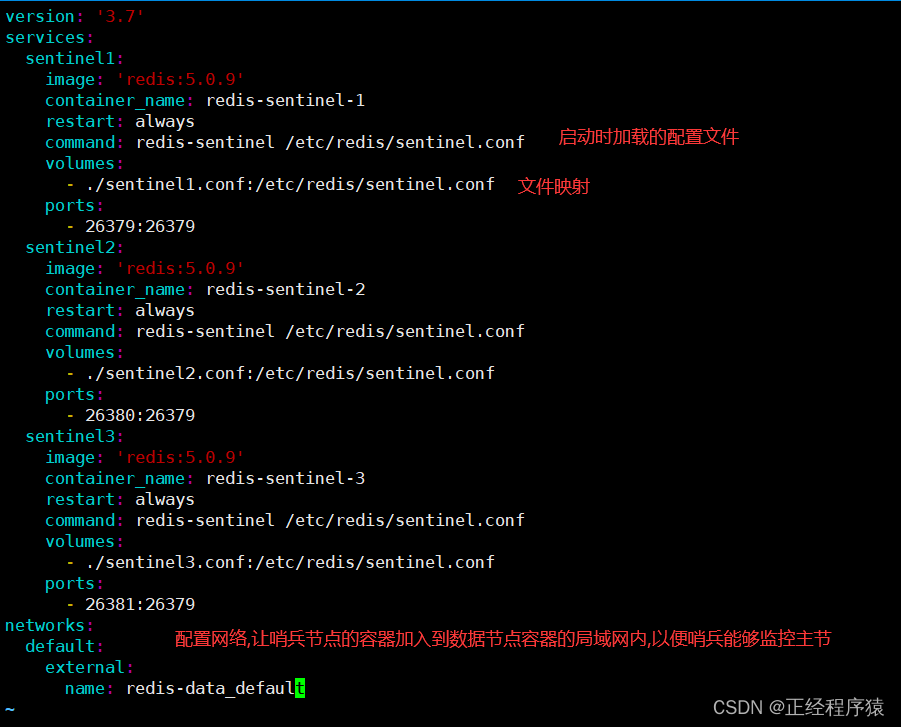
使用docker network ls列出docker创建出的局域网.

上面的配置文件中的局域网名字要和这里的一致才可以.
这里为什么会创建三个文件的映射:因为哨兵节点会在运行过程中,对配置文件进行修改,因此不能拿一个哨兵的配置文件来给三个容器映射.
所以接下来,我们还要创建三个哨兵节点的配置文件,初始内容可以是一样的.

配置文件内容
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000
sentinel monitor 主节点名 主节点ip 主节点端⼝ 法定票数
这里的主节点ip我们依然写成是主节点的容器名,端口号写作容器外的端口号,法定票数为2.
关于法定票数
法定票数,哨兵需要判定主节点是否挂了.但是有的时候可能因为特殊情况,⽐如主节点仍然⼯作正常,但是哨兵节点⾃⼰⽹络出问题了,⽆法访问到主节点了.此时就可能会使该哨兵节点认为主节点下线,出现误判.使⽤投票的⽅式来确定主节点是否真的挂了是更稳妥的做法.需要多个哨兵都认为主节点挂了,票数>=法定票数之后,才会真的认为主节点是挂了.
sentinel down-after-milliseconds心跳包的超时时间.
主节点和哨兵之间通过心跳包来进行沟通,如果心跳包在指定的时间内还没回来,就视为是主节点出现故障了.
配置完成之后,启动所有容器.
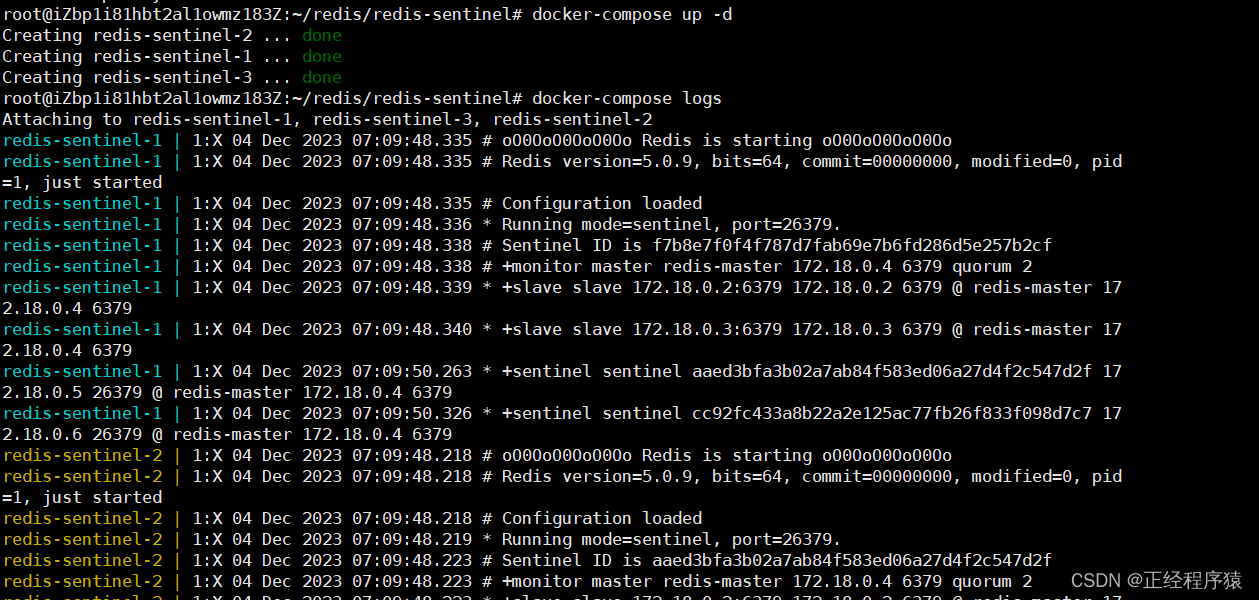

上述操作必须保证工作目录在yml的统计目录中才能工作.
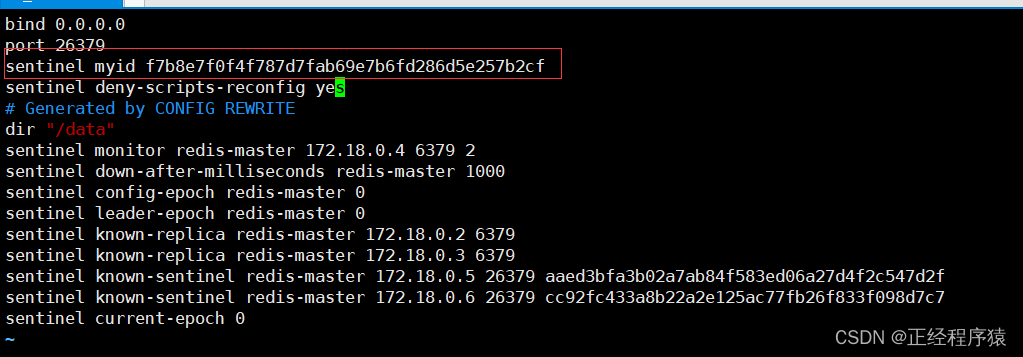
观察哨兵节点的配置文件

已经被重写了!!!而且三个配置文件重写的内容不同.
模拟主节点宕机,观察哨兵节点的工作流程
哨兵存在的意义就是能够在redis主从结构出现问题的时候(比如主节点宕机),哨兵节点能都自动的帮助我们重新选举出一个主节点,并代替挂了的主节点,保证整个redis仍然是可用的状态.
我们使用docker stop redis-master来停掉主节点的容器.

主节点挂了之后,查看哨兵节点的日志,来了解哨兵节点的工作流程.
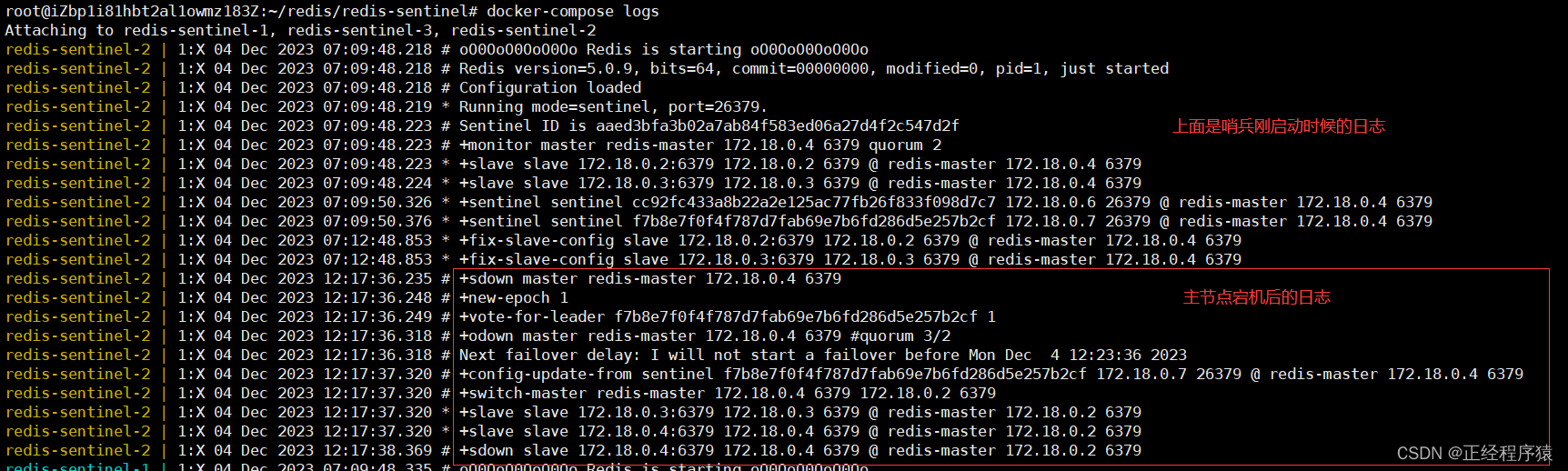
sdown主观下线:此哨兵节点,认为该主节点挂了.
odown客观下线:多个哨兵节点都认为主节点挂了,大于等于法定票数.法定票数我们规定在了哨兵节点的配置文件里面,这里是2.
从日志中我们可以看出,新的主节点已经是172.18.0.2这个节点了.

如果此时在启动原先的主节点,那么此节点会作为新的主节点的从节点,来继续后面的工作.
哨兵重新选取主节点的流程
当客观下线之后,主节点挂了就成为事实了.此时就需要哨兵节点选出一个从节点来作为新的主节点,那么此处就需要提拔出一个新的主节点.
1.主观下线
哨兵节点通过心跳包,判定redis服务器是否正常工作.如果心跳包没有如约而至,就说明redis服务器挂了.
但是此时,还不能排除网络波动的影响,因此只能是当前哨兵节点单方面认为此redis服务器挂了.
2.客观下线
哨兵sentenal1,sentenal2,sentenal3均会对主节点故障这件事情进⾏投票,当多个哨兵都认为主节点挂了.(认为主节点挂了的哨兵数目达到了法定票数),哨兵们就认为这个主节点是客观下线.
3.哨兵节点推举出一个leader节点
选举出一个哨兵的leader后,由这个leader选一个从节点作为新的主节点.



每个哨兵手里只有一票.这里的一长串数字是哨兵的id,在哨兵的配置文件中可以查看.
当哨兵1第一个发现当前是客观下线之后,就立即给自己投了一票,并且向2,3拉票.2和3收到拉票请求之后,就给1投出自己的一票,如果总的票数超过哨兵总数的一半,选举就完成了,此时1就成了leader.
当2和3没有投出自己的票的时候,收到拉票请求,就会投出去,如果收到多个拉票请求,就会投给拉票请求最先到达的那个哨兵节点.
上面的投票过程,就是看哪个哨兵节点的网络延时小.谁率先发出了投票请求,谁就有更大的概率成为leader.
具体选出哪个节点是leader不重要,只要能选出一个节点即可.
4.leader选举完毕,leader挑选出一个从节点,作为新的主节点.
挑选规则
a)比较优先级.优先级高的(数值小的)先上位.优先级是配置文件中的配置项(slave-priority).
b)比较offset,谁复制的数据多,谁就上位.
c)比较run id,谁的id小,谁上位.run id是每个reids节点启动的时候随机生成的一串数字,相当于随机挑选.
当把新的主节点指定好了之后,leader就会控制这个节点,执行slaveof no one,成为master,再控制其他的节点,执行slaveof命令,让这些其他的节点,以新的master作为主节点.
关于哨兵的总结
哨兵节点不能只有⼀个.否则哨兵节点挂了也会影响系统可⽤性.
哨兵节点最好是奇数个.⽅便选举leader,得票更容易超过半数.
哨兵节点不负责存储数据.仍然是redis主从节点负责存储.
哨兵+主从复制解决的问题是"提⾼可⽤性",不能解决"数据极端情况下写丢失"的问题(主节点还没来得及向从节点同步就挂了).
哨兵+主从复制不能提⾼数据的存储容量.当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了.