GPT-Crawler一键爬虫构建GPTs知识库
- 写在最前面
- 安装node.js
- 安装GPT-Crawler
- 启动爬虫
- 结合 OpenAI
- 自定义 assistant
- 自定义 GPTs(笔者用的这个)
- 总结
写在最前面
GPT-Crawler一键爬虫构建GPTs知识库
能够爬取网站数据,构建GPTs的知识库,项目依赖node.js环境,接下来我们按步骤来安装,非常简单
参考:https://zhuanlan.zhihu.com/p/668700619
在信息爆炸的时代,数据成为了新的石油。但是,如何有效地从这无穷无尽的网络信息中提取有价值的知识,成为了技术人员面临的一大挑战。特别是对于GPTs这样的先进技术,构建一个强大且更新的知识库是至关重要的。这就是我们今天要介绍的GPT-Crawler一键爬虫工具的使命所在——一种强大的工具,旨在帮助开发者和数据科学家高效地构建和维护GPTs的知识库。
在这篇博客中,我们将深入探讨如何利用GPT-Crawler来捕获和处理网络数据,从而为GPTs模型提供丰富而精准的信息。从安装Node.js作为运行环境的基础开始,我们将一步步指导您如何安装和启动GPT-Crawler。此外,我们还会介绍如何将这个强大的爬虫工具与OpenAI的技术结合起来,以及如何自定义assistant和GPTs,以满足您特定的需求和偏好。
无论您是一名经验丰富的开发者,还是对数据科学和人工智能有浓厚兴趣的初学者,这篇博客都将为您提供宝贵的知识和实践指导。通过阅读本文,您不仅能够了解如何构建一个高效的GPTs知识库,还能够获得关于如何自定义和优化爬虫的实用技巧。那么,让我们一起开始这趟激动人心的技术之旅吧!
安装node.js
Node.js下载地址:https://nodejs.org/en
下载20.10.0版本即可,下载后一路默认安装

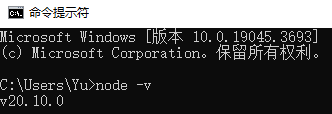
安装完成后在命令行输入node -v,显示版本则安装成功
安装GPT-Crawler
项目地址:https://github.com/BuilderIO/gpt-crawler
这个项目能爬取网站数据,生成用于创建GPTs的知识库文件
打开项目地址后,点击【Code】,下载压缩文件,保存到电脑本地解压
VSCode官网下载:https://code.visualstudio.com/Download
用VSCode编码工具打开,
或者点开VSCode,左上角文件,点击打开文件夹,地址选择解压的地址
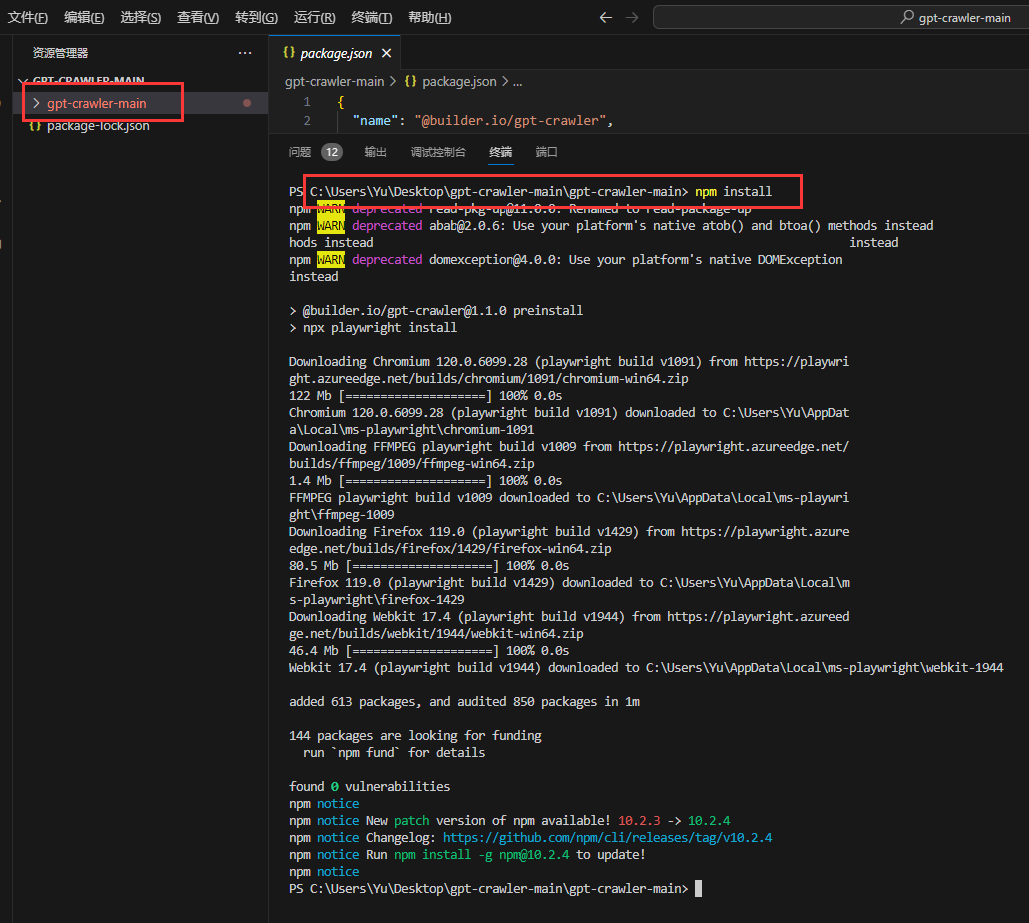
切换到项目目录(例如我的是C:\Users\Yu\Desktop\gpt-crawler-main\gpt-crawler-main>),右键,选择在集成终端中打开
输入npm install,把项目依赖包进行安装
启动爬虫
npm start
日志输出下面这些为正常:
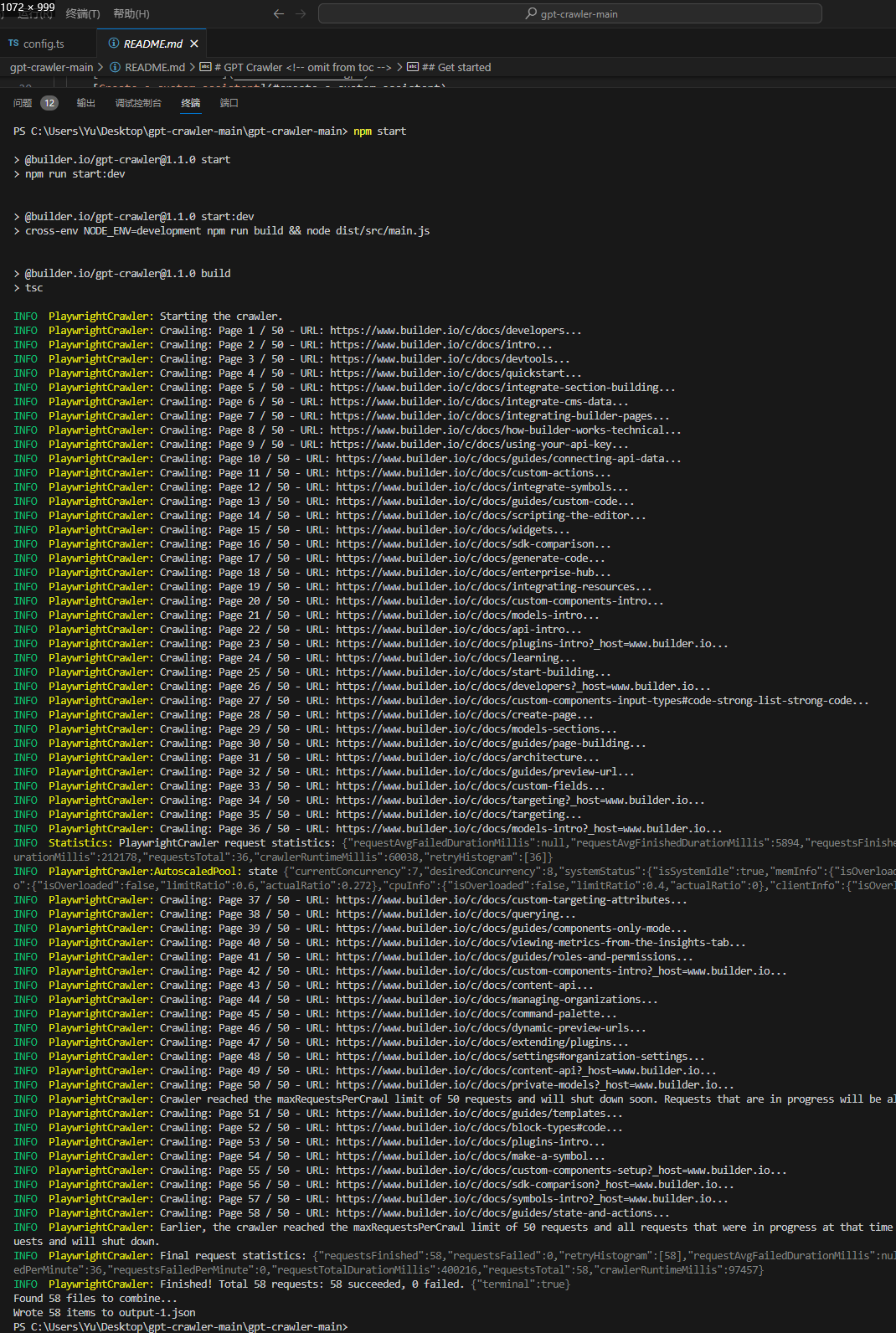
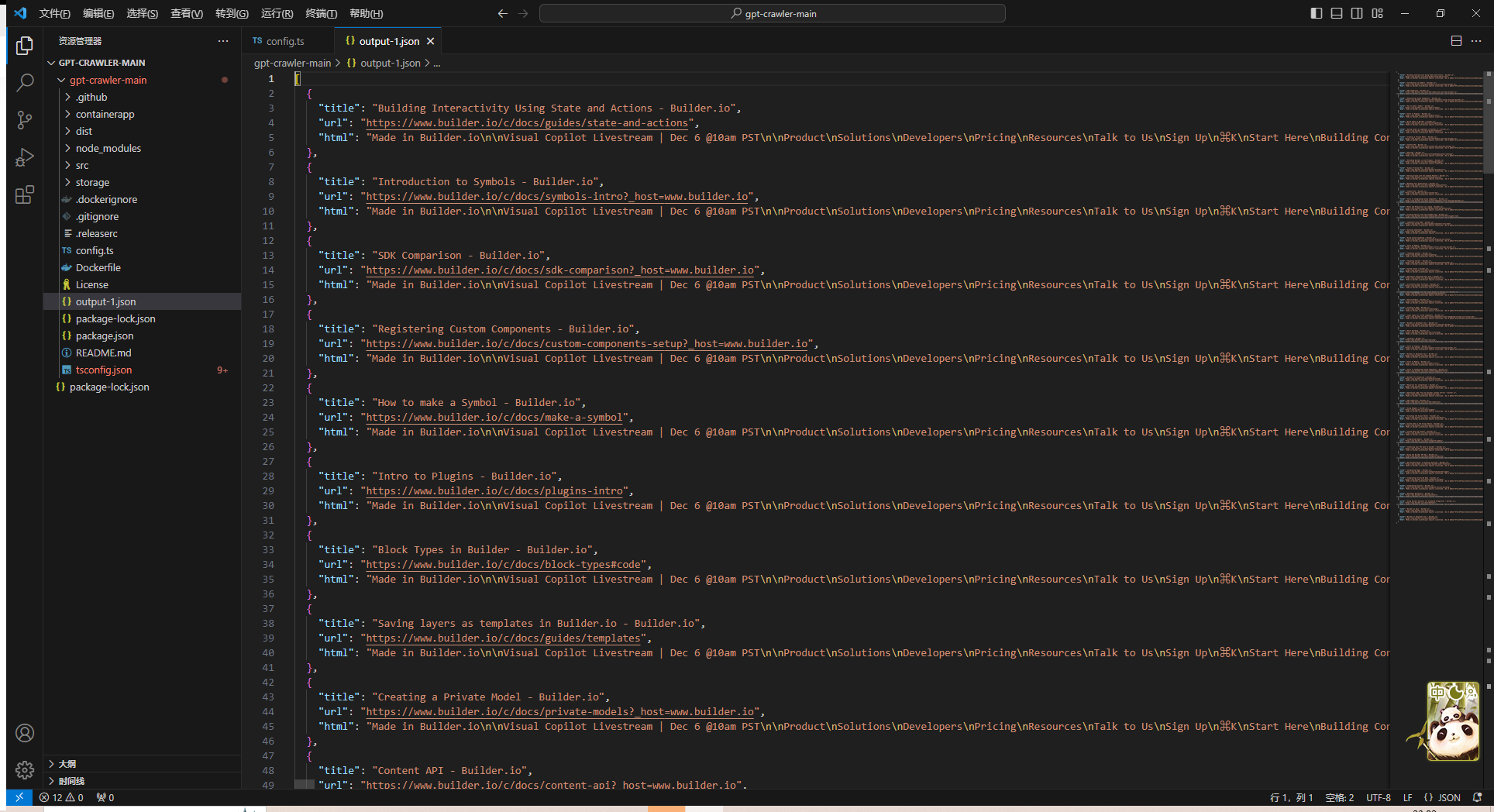
最后程序会在项目根目录输出文件output.json,这就是我们需要的文件。
输出的文件就在该目录下
点开看一下,很完美
结合 OpenAI
这步需要一个 OpenAI 账户,我们需要将生成的文件上传给 OpenAI。
自定义 assistant
选择 assistant 的优势是,我们可以使用 OpenAI 提供的 assistant API,集成到自己的系统中。
操作步骤:
1、进入自定义 Assistants 页面https://platform.openai.com/assistants
2、创建一个 Assistant
3、添加上面生成的output.json文件
4、配置其他选项
上传配置完点击保存,然后开始测试:
自定义 GPTs(笔者用的这个)
自定义 GPTs 和上面的操作类似,大家自行体验。GPTs 需要大家付费 Plus,并且官方似乎还没有提供 GPTs 的 API 可用。
总结
GPT Crawler 项目能让我们只做简单的配置,即可自定义自己的知识库。结合 OpenAI 的 API,能够做很多的事情。大家自行体验。