欢迎来到zhooyu的游戏专栏。
主页网址:【zhooyu】
专栏网址:【C++和OpenGL实现3D游戏编程】
🌟🌟🌟这里将通过一个OpenGL实现3D游戏编程实例教程,带大家深入学习OpenGL知识。知识无穷而人力有穷,希望能对您有所帮助。
🌟🌟🌟该教程为系列教程,每一步都有详细的教学和实例,推荐大家通过下边的【思维导图】和【目录】系统性的了解开发过程,了解怎样一步一步从简单入手,借助C++和OpenGL实现强大的3D效果。
🌟🌟🌟同时您可以在QQ群(群号:739903792)中与大家进行沟通交流,共同解决编程过程中的困惑。

贝塞尔曲面演示:
贝塞尔曲面演示zhooyu
奇幻森林场景演示:
C++和Opengl森林景观
三维模型加载演示:
使用Assimp加载模型
一、本专栏内容
我们从游戏的角度出发,用C++和OpenGL去了解一下游戏中的功能都是怎么实现的。这一切还是要从自己玩游戏开始说起,此前就玩过一下3D游戏,当时就被游戏里的一些画面和设置深深的吸引了,同时游戏里还有很多很有趣的设定,比如,玩家的视角是怎么移动的?灵魂状态的世界怎么变成灰白色的?崎岖不平的地图是怎样制作的?人物和物体、地面的碰撞是怎样检测的?鼠标是怎样选中眼前的物体的?魔法技能是怎样释放的?不用加载进度条的无缝世界地图是怎么实现的?带着这些疑问,我们走进了一个OpenGL世界的3D世界。
二、专栏思维导图
本专栏思维导图:以下内容是本专题所涉及的部分问题,仅仅为内容概要展示,文章将根据需要会有顺序上的改变,后期也会继续补充、添加更多内容。

为了实现以上游戏丰富多彩的内容,我们需要对相应的游戏内容实现进行探索,从一开始的准备工作,游戏库文件的准备,第一个游戏窗口的创建,运用OpenGL画出基本的3D物体,文字的显示,贴图纹理的使用,视角的变化,点在三维世界的位置转换,三维世界顶点在二维屏幕的投影位置,鼠标怎样选中物体,贝塞尔曲线和曲面的应用,光照贴图,蒙皮动画等等一系列的问题进行研究,逐步模仿实现游戏世界的内容。虽然有很多内容网上都只言片语的提到过,但很少有系统来说的,这里我就我自己编程中遇到的问题和解决的办法汇总出来,仅供参考。
三、专栏文章内容目录
(一)、OpenGL基础功能的实现
🔥1.1、初探3D世界(附源码)
我们想制作一个游戏,首先必须得创建一个WINDOWS的窗口,我们先用VC创建一个最简单的窗口。就好比在学各种编程语言的时候都会创建一个基本的hello world示例程序一样,这样可以给我们的编程从感觉上带来简单容易上手的良好效果。

🔥1.2、了解并创建3D空间模型(附源码)
上一节我们创建一个简单的窗口,本节我们需要了解一下细节内容,同时为了方便观看,我们需要显示一个世界坐标轴,建立一个直观的三维空间。

🔥1.3、3D空间模型光照初步(附源码)
上一节课,我们建立了简单的坐标系,同时也显示了一个正方体,但正方体的颜色为纯红色,好像一个平面物体一样,我们这节课就可以加一些光照,并创建更多的模型,使这些物体变得更加立体一些。
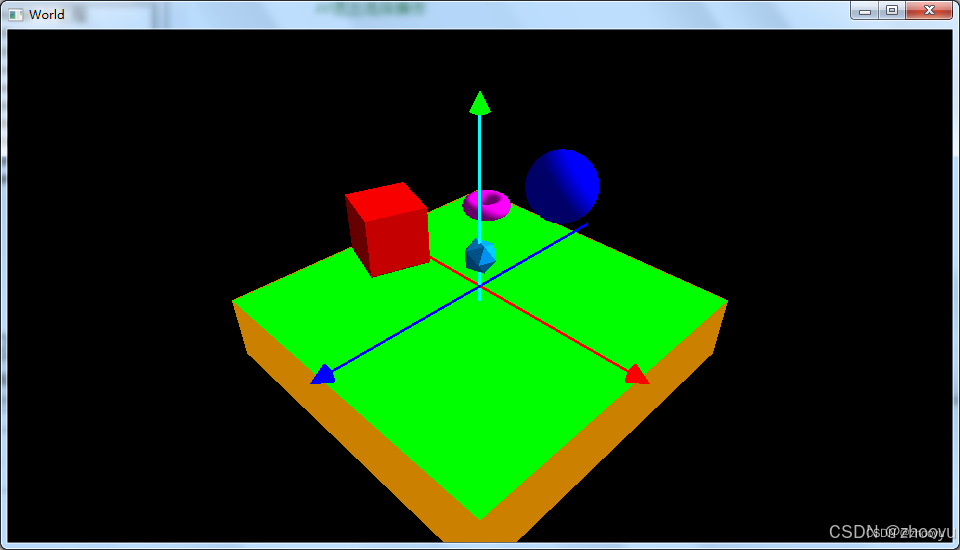
🔥1.4、纹理加载的三种方式(附源码)
如果我们想让物体更加真实,就得有足够多的顶点,且指定足够多的颜色,这样会产生很多额外开销,因为每个模型需要很多顶点,而每个顶点又需要颜色属性。为了方便且减少开销,我们更习惯使用纹理来绘制更多的模型,纹理就像一张2D的贴图,把它贴在图像或模型上来增加物体的细节。这样物体细节取决于设计师的美工,而程序员则不必指定更多的顶点。

🔥1.5、纹理坐标、纹理贴图(附源码)
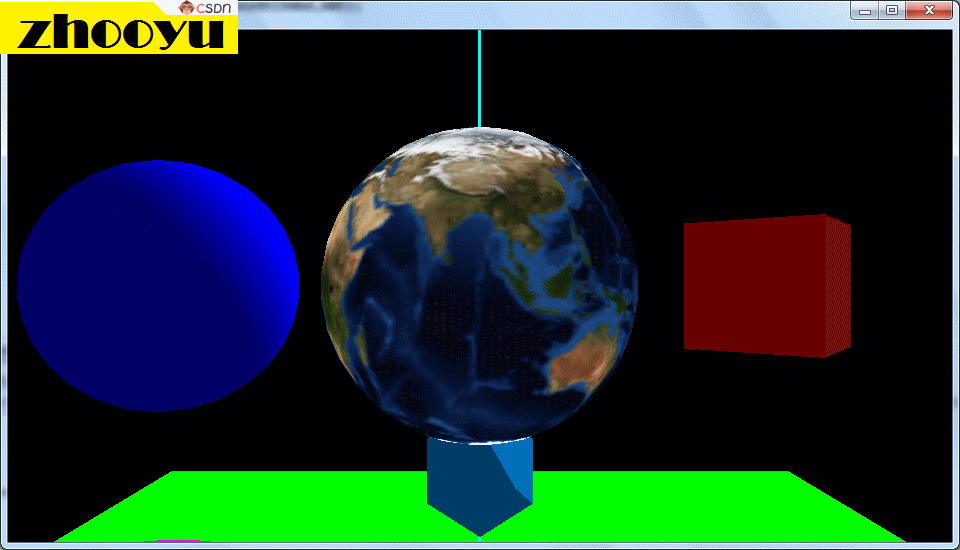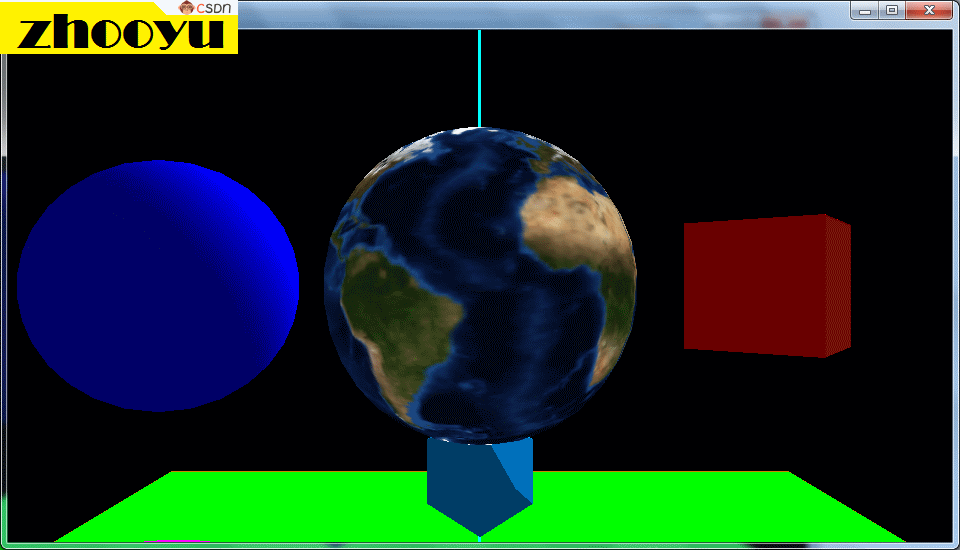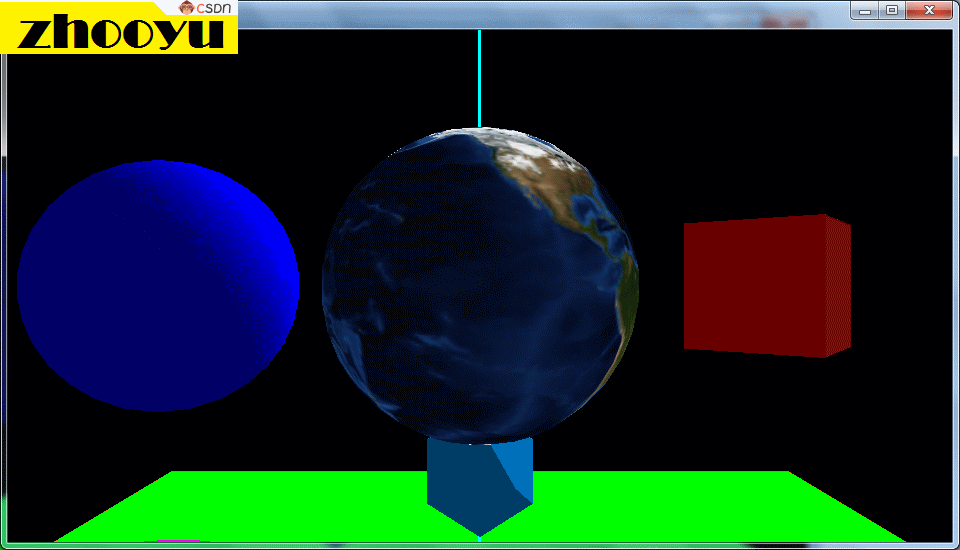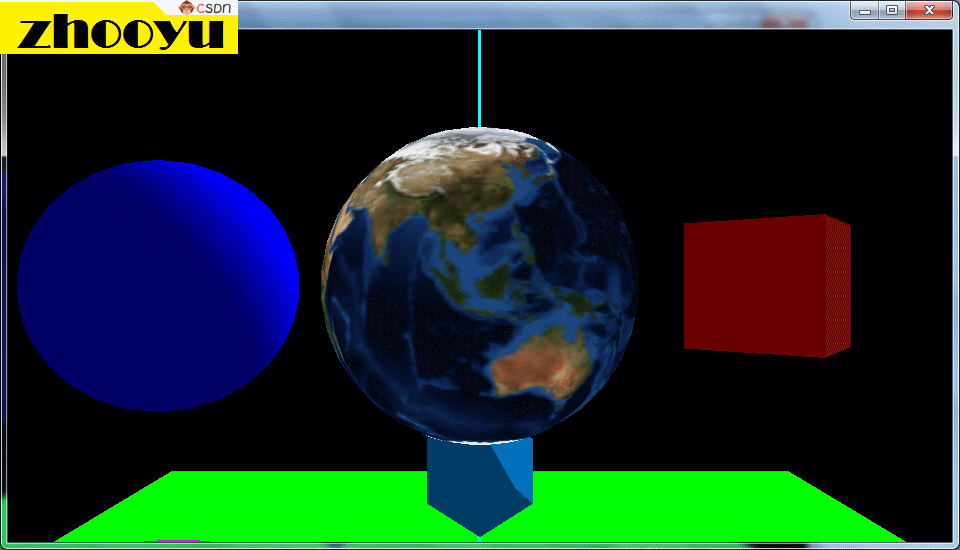
在OpenGL中,纹理是一种常用的技术,用于将图像或图案映射到3D模型的表面上,以增加图形的细节和真实感。那么我们上一节已经做好了纹理的准备工作,将需要的纹理图片加载并绑定到了纹理编号中,我们这一节就探讨一下怎样将对应的纹理图片显示到我们的程序中去,特别是将纹理映射到圆形或三维球体等复杂图形上,下图就是一个三维球体的纹理贴图实例。
🔥1.6、不规则图形的纹理贴图(附源码)
上一节我们讨论了纹理贴图的相关基础操作,但上一节的纹理贴图操作基本上都是规则图形,包括圆形和球形虽然复杂一点,但是它也是规则的。这一节课我们要讨论一下,怎么在不规则图形上纹理贴图,就比如文章下图的心形纹理贴图,以及纹理的平移、旋转、放大缩小功能。

🔥1.7、文字和汉字的显示(附源码)
上一节我们讨论了纹理在二维平面内不规则图形贴图的相关基础操作,本节我们开始了解游戏里文字以及汉字的显示方法。本节课我们将从基本的ASCII字符显示,拓展到中文字符的显示,最后再讲到纹理字符的显示,并对各种文字显示方法的优缺点和使用场景进行分析,这节课将使用到显示列表等操作,我们还将制作一个显示文字坠落的动画效果。

🔥1.8、纹理文字的实现与优化(附源码)
上一节课我们介绍了在opengl中文字的显示方法,但显示出来的文字无法旋转,在某些特定游戏要求下,文字是需要进行旋转的,那么这一节课我们介绍一下纹理文字的高级使用方法,将文字生成纹理,达到文字旋转的效果。

🔥1.9、镂空纹理的实现(附源码)
前面的课程中,我们学会了加载纹理并显示纹理图案,但是纹理的图案都是长方形的图片,图片就会有白色或黑色背景,那么在游戏设计过程中,我们经常不需要显示图片的背景部分,那么这节课我们就来讨论一下如何实现剔除白色或黑色背景后的镂空图像,下图就是将树的图片白色背景去除后显示的效果。

🔥1.10、纹理的半透明显示(附源码)
上一节课我们讲到了图片的镂空显示,它能在显示图片时去除指定颜色的背景,那么这节课我们来说一下图片的半透明显示效果,半透明效果能给画面带来更高质量的提升,使图片显示的更自然,产生更真实的效果。下面是一个气泡向上漂浮的效果。

🔥1.11、光照效果进阶(附源码)
我们在前面的章节里内容简单的介绍了一下光照,随着后期对纹理内容的增加,我们需要了解更多的光照知识,本节我们回顾一下光照相关内容,并了解一下怎样实现纹理的光照效果。下面这个图就是我们借助于纹理文字产生的半透明光照效果。

🔥1.12、声音的基本控制(附源码)
前面我们实现了图片纹理的显示功能,是不是感觉到非常的简单。那么今天我们就继续说下游戏声音的实现。音效也是游戏的灵魂,只有搭配了美妙动听的音效以后,游戏才能令人耳目一新,与玩家产生良好的效果。

🔥1.13、多重纹理混合详解(附源码)
前面说过纹理贴图能够大幅提升游戏画面质量,但纹理贴图是没有叠加的。在一些游戏场景中,要求将非常不同的多个纹理(如泥泞的褐色地面、绿草植密布的地面、碎石遍布的地面)叠加(混合)起来显示,实现纹理间能够自然过渡,产生看不出明显的边缘的连续场景,由此多纹理混合技术应运而生,在地形渲染中用得非常广泛。例如,你可以用3个纹理来渲染一片庄园的地面,有的地方长满了绿草、有的地方裸露着泥土、而有的地方还存在砂石,各个场景之间没有明显的过渡痕迹,带来更加逼真的环境效果。

🔥1.14、VBO、VAO和EBO应用(附源码)
我们从一开始学OpenGL到现在,OpenGL的图形绘图必须在glBegin()和glEnd()函数之间完成,在此基础之上,才能进行后续操作功能。但是我们今天要讨论一下OpenGL图形绘制的模式,从之前的立即渲染模式,开始转向核心模式,从而大幅提升显示性能。下图就是通过VBO、VAO和EBO应用画出的矩形,矩形虽然简单,但它的意义却不凡。

🔥1.15、着色器初步(附源码)
上一节我们介绍了通过VBO、VAO和EBO怎样将顶点发送到GPU显存,利用GPU与显存之间的高效处理速度,来提高我们的图形渲染效率。那么在此过程中,我们又可以通过着色器(shader)进行可编程管线操作,极大的增加了编程自由度,那么我们就来了解一下相关知识,并通过模型视图矩阵以及投影矩阵进行顶点变换,完成首次MVP操作。下图就是一个通过着色器(shader)显示的立方体。

🔥1.16、详解三维坐标转二维屏幕坐标(向量和矩阵操作实战)(附源码)
在上一课我们了解了着色器,了解了部分核心模式编程内容,从中接触到了线性代数中向量和矩阵相关知识,我们已经能够感受到向量和矩阵在OpenGL编程中的重要性。特别是后期用去了解融合、光照效果,构建自己的三维世界,都需要大量向量和矩阵的相关知识。本节会就一些线性代数的基础知识进行了解和应用,并实现三维坐标向二维屏幕坐标的转换,这是后期实现鼠标选中物体功能的铺垫。但本文并非对线性代数进行专业的介绍,而是学习计算机图形学必备知识的了解及实战应用。

🔥1.17、着色器进阶(附源码)
在前面着色器初步一节我们了解了着色器的一些初步知识,通过顶点着色器和片段着色器显示出了一个彩色的立方体。我们这节课就来了解一些在着色器中显示纹理等一系列实用操作,同时了解一些进阶的图像渲染技术,比如图像的灰度化处理,像游戏中灵魂状态下世界进行灰度化处理后的效果。使用GLSL渲染纹理是一种非常有用的技术,可以实现高效的图形处理和渲染,并且可以根据具体的应用场景和需求进行更复杂的渲染操作。

🔥1.18、建模模型OBJ文件的加载应用
以前我们加载过立方体木箱,立方体的顶点数据都是在程序运行时临时定义的。但后期如果模型数量增多,模型逐步复杂,我们就必须加载外部模型文件。这节课我们就先了解一下加载OBJ模型文件的方法,这样可以让编程和设计进行分工合作,极大丰富我们游戏效果,下边是我们通过OBJ文件加载的一个模型。

🔥1.19、着色器光照初步(平行光)
我们在前期的教程中,讨论了在即时渲染模式下的光照内容。那么在我们后期使用着色器的核心模式下,会经常在着色器中使光照,我们这里就讨论一下着色期光照,同时为后期的阴影效果做一些知识铺垫。我们首先讨论定向光(directional light)的使用,光照包括环境光、漫反射光和镜面反射光,在下边这个例子中,我们可以直观地感受到这些光的合成效果。

(二)、游戏基础控制和组织结构
2.1、游戏基类Object的构建
前面的章节中我们已经介绍了OpenGL中的一些基本操作,但都是一些各自独立的知识或代码。我们在游戏设计时,需要设计一个游戏的框架,能够有效的管理或组织各个游戏元素,来体现我们的设计思路和游戏流程,我们就需要从Object基类开始,深入的思考并抽象出一种游戏逻辑,达到我们的需求。下面例子中的木箱我们尝试从Object中派生一个Box类来实现,由类来负责管理加载、显示、运动等效果,从以前的面向过程转变为面向对象编程。

2.2、游戏子物体的实现(子物体的添加和删除)
上节课我们已经创建了一个基础Object类,以后所有的游戏元素都可以从这个基类中派生出来。同时为了操作方便,我们可以为任意两个Object类(及其派生类)的实例对象添加一种父子关系,后期通过父物体与子物体关系,能够轻松的实现游戏物体的操控,方便我们在游戏中对所有游戏元素的组织和管理。再比如后期加父子关系后,就可以同步控制父子物体在三维空间的位置、旋转和缩放操作。
 )
)
2.3、父物体与子物体的消息处理机制
上一节我们了解了父子物体模式,方便我们快捷、控制游戏元素。这一节我们去了解怎样通过父子模式去处理系统消息,系统消息是我们和游戏之间互动的纽带,确定了游戏的用户体验。同时我们还将添加一些预制体,比如说立方体、球体、锥体、胶囊体等,方便我们今后的操作。另外我们此前的模型加载的较为单调,而且我们将加入一些游戏的模型元素,这个视频加载了各式各样的树木,构造出一个奇幻的森林雏形。

2.4、几何着色器和法线可视化
上一节课,我们在Blend软件中导出经纬球模型时,遇到了经纬球法线导致我们在游戏中模型光照显示问题,我们在Blender软件中可以通过显示法线的方式找到问题的原因所在。但在后期我们游戏元素逐步增多时,每个都重新到Blender软件中去查看会增加游戏调试的复杂度和难度,我们这节课就来了解一下法线可视化问题,同时学习一下几何着色器知识。

2.5、游戏层的控制
2.6、半透明显示与视角距离的控制
(三)、二维界面控制
3.1、二维界面的实现
3.2、按键的实现
3.3、窗口的实现
3.4、窗口滚动条的实现
3.5、进度条的实现
3.6、文字锚点的实现
(四)、视角的基本控制
4.1、自由视角的实现
4.2、上帝视角的实现
4.3、玩家视角的实现
4.4、鼠标左键旋转玩家视角(不改变玩家方向)
4.5、鼠标右键旋转玩家视角(改变玩家方向)
4.6、通过视角获取三维点在二维屏幕的坐标
4.7、鼠标选择物体(设置选中模型和范围)
4.8、鼠标选择物体(判断鼠标是否选中模型)
(五)、空间转换
5.1、空间控制(点点距离、点面距离)
5.2、子物体与父物体之间的坐标和角度转换
5.3、获取子物体在世界坐标下的空间位置
(六)、地图模拟实现
6.1、地图的存储方式
6.2、贝塞尔曲线和曲面的应用
6.3、柏林噪音
6.4、无缝地图实现原理
6.5、地面检查和碰撞检查
(七)、游戏机制的应用
7.1、纹理和模型池机制
7.2、使用Assimp加载更多三维模型
7.3、音效池机制
7.4、骨骼系统实现
7.5、物品背包窗口的实现
7.6、技能书窗口的实现
7.7、物品、技能拖拽功能实现
7.8、光源池机制
(八)、网络通信及数据库相关
8.1、网络通信Tcp创建服务器和客户端
8.2、从读取数据库读取游戏信息
8.3、服务器与客户端的网络通信
四、终章
更多内容持续更新中……

更多专栏:
1、C++和OpenGL实现3D游戏编程【目录】